 夜雨聆风
夜雨聆风Mathmatical Foundation of Reinforcement Learning强化学习的数学基础·免费书稿
https://github.com/MathFoundationRL/Book-Mathmatical-Foundation-of-Reinforcement-Learning
下载方式
后台回复:强化学习
这是新书『强化学习的数学基础』的书稿,作者赵世钰,现任西湖大学工学院智能无人系统实验室主任。2022年秋季是作者第四次教授强化学习的研究生课程,撰写这份资料是为了弥补已有教材的不足,具有以下特点:
从数学角度介绍强化学习各主题,帮助读者更好地理解算法的数学根源、设计初衷与作用机制。 数学的呈现方式也经过精心设计,深度也被仔细地控制在适当的水平。 书中大量示例均基于网格世界任务,非常易于理解,且有助于说明新概念和算法。 将算法核心思想与可能分散读者注意力的复杂问题进行了区分,帮助读者更好地掌握算法心思想。 章末有问答部分,汇总整理自网络上的常见问题,并给出了明确的参考答案。

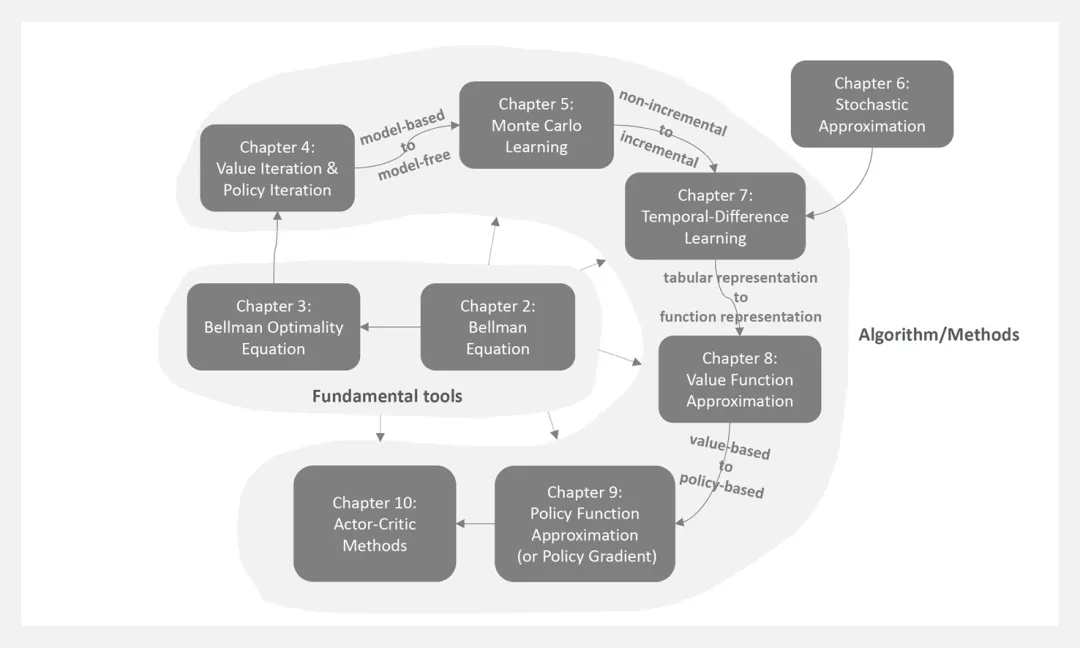
本书的每一章都在前一章的基础上构建,并为后续章节奠定了必要的基础。不同章节内容主题与彼此之间的关系如图所示。
第2章:贝尔曼方程,是分析状态值的基本工具 第3章:贝尔曼最优方程,是一个特殊的贝尔曼方程 第4章:值迭代算法,是一种求解贝尔曼最优方程的算法 第5章:蒙特卡罗学习,是第4章策略迭代算法的扩展 第6章:随机逼近的基础知识 第7章:时差学习,第6章是本章的基础 第8章:扩展了表格时间对价值函数逼近情况的差分学习方法 第9章:策略迭代 第10章:actor-critic 方法
下载方式
后台回复:强化学习
