 夜雨聆风
夜雨聆风
OpenAI 又出手了。
就在刚刚,GPT-5.4 正式发布。
如果只用一句话总结这次更新,那就是:
OpenAI 把推理、编程、Agent、工具调用、电脑操作、视觉理解、办公能力,几乎全部塞进了同一个模型里。
而且,还第一次把百万级上下文窗口带进了 GPT 主力模型。
这不是一次常规升级。
这更像是 OpenAI 对外释放的一个明确信号:
大模型的竞争,已经不再只是“会不会聊天”,而是正式进入“能不能真正干活”的阶段。
从这个角度看,GPT-5.4 很可能会成为未来很长一段时间里,企业级 AI、开发者 Agent、以及生产力工作流的一个新基准。
01|GPT-5.4 到底是什么?一句话看懂
这次 OpenAI 一共给出了三个版本:
ChatGPT 里:GPT-5.4 Thinking
API / Codex 里:GPT-5.4
追求极限性能的版本:GPT-5.4 Pro
表面上看只是一次版本更新,但实际上,它做了一件非常关键的事:
把 GPT-5.2 的通用推理能力,和 GPT-5.3-Codex 的顶级编程能力,合并成了一个模型。
这意味着什么?
意味着过去你可能需要:
一个模型负责推理
一个模型负责写代码
一个模型负责调用工具
一个 Agent 框架负责串流程
而现在,OpenAI 想做的是:
尽量让一个模型,直接把复杂任务做完。
官方原话的核心意思其实非常直接:
用更少的来回,更准确地完成复杂的实际工作。
说白了,就是让 AI 不只是“回答问题”,而是“真的把事办了”。

02|最炸裂的更新:百万上下文,Agent 终于不再“失忆”
这次最震撼的一个点,是 GPT-5.4 在 Codex 和 API 中,实验性支持100 万 token 上下文窗口。
100 万 token 是什么概念?
大概相当于:
5000 页文档
一个大型代码仓库
超长任务链中的完整历史记录
过去做长任务时,很多人最大的痛点都不是模型不聪明,而是:
它记不住。
前面分析了一大堆,后面一长轮思考下来,模型开始忘上下文;
多工具调用几轮之后,前面约束丢了;
长代码仓库一塞进去,成本直接爆炸。
而百万上下文窗口,解决的正是这个根问题。
它的意义不是“能塞更多字”,而是让 Agent 在超长工作链里真正具备:
持续规划能力
长程依赖理解能力
多阶段执行和验证能力
不轻易半途“失忆”的稳定性
以后做复杂项目,可能真的会少一个经典焦虑:
上下文恐慌。
更关键的是,OpenAI 还特别强调:GPT-5.4 在长时间思考时,对早期上下文的保持能力也更强。
也就是说,它不只是“窗口更大”,而是“记性也更稳”。
这对开发者、研究员、法务、咨询、金融分析、长文档处理来说,几乎都是质变。

03|可以中途打断:ChatGPT 从“回合制”变成“实时协作”
如果说百万上下文是开发者最兴奋的点,那么普通用户最能直观感受到的升级,可能是这个:
GPT-5.4 Thinking 现在支持中途打断。
这个功能看起来像个小优化,但其实非常重要。
以前的 ChatGPT 使用体验更像“回合制对话”:
你提问,它开始输出;
如果方向跑偏了,你只能等它说完;
然后重新提问,再来一轮。
但现在不一样了。
GPT-5.4 Thinking 会先给出一个思考计划,而在它执行和回答的过程中,你可以随时插话:
补充新的信息
改变任务方向
修正它的理解
中途重新约束目标
它会把这些新指令直接融进去,继续往下做。
这意味着什么?
意味着和 AI 的交互方式,第一次真正开始接近“协作”而不是“问答”。
比如你让它做旅行规划,它正在帮你查机票,这时你突然决定不要坐飞机,改成自驾游。以前你得整轮推倒重来;现在你只需要中途更新,它就能马上转向。
这对长链路任务尤其重要。
因为越复杂的任务,越不可能在一开始就把所有条件想清楚。
现实世界里的工作,本来就是一边做一边修正。
GPT-5.4 的这个能力,本质上是在让 AI 更贴近真实工作流。
这不是“模型更聪明一点”的问题,而是:
交互范式变了。
04|会操作电脑了:OpenAI 第一个原生支持 Computer Use 的通用模型
这次另一个重磅升级,是 GPT-5.4 成为 OpenAI 第一个原生支持 Computer Use 的通用模型。
什么叫 Computer Use?
简单理解就是:
模型可以像人一样操作电脑。
它可以:
看屏幕截图
识别界面元素
点击按钮
输入文字
跨应用完成任务
配合代码执行自动化流程
也就是说,AI 不再只是“会说怎么做”,而是开始“自己动手做”。
这背后对应的是 Agent 能力的一次大跃迁。
过去很多自动化流程,其实卡在最后一步:
模型能理解任务,也能制定计划,但无法真正进入界面执行。
现在,GPT-5.4 把这一步补上了。
而且性能非常夸张。
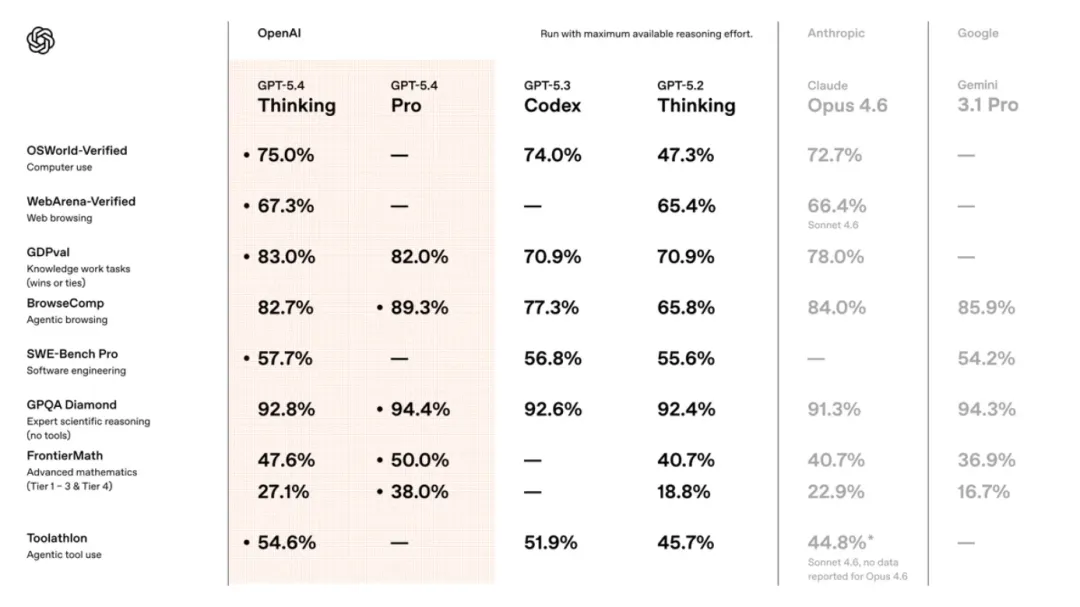
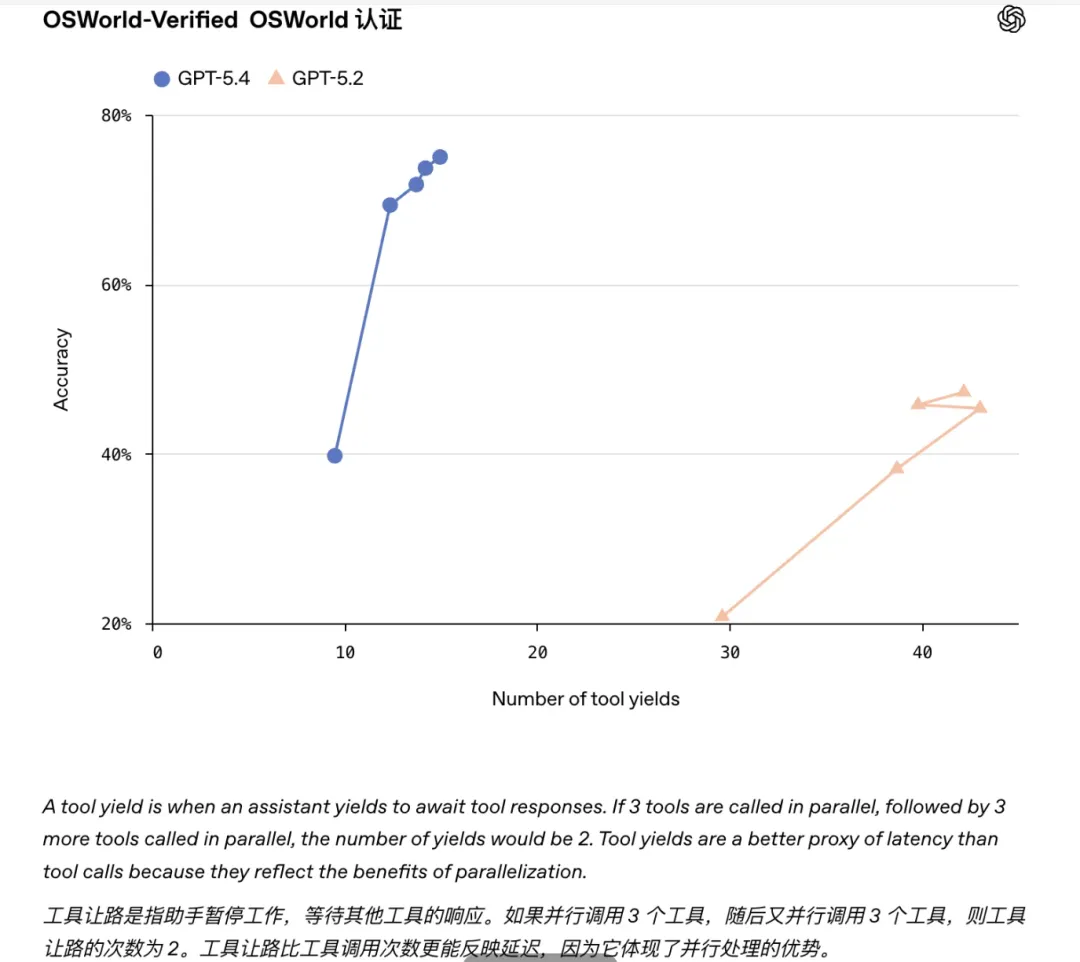
在模拟桌面操作的 OSWorld 测试中,GPT-5.4 成功率达到 75.0%。
对比一下:
GPT-5.2:47.3%
人类水平:72.4%
也就是说,在这个基准上,GPT-5.4 已经超过了人类。
同时,它在浏览器任务测试 WebArena 上拿到 67.3%,在 Online-Mind2Web 上达到 92.8%。
这说明什么?
说明 AI 从“会回答”走向“会执行”的速度,比很多人预期得更快。
未来很多重复性的电脑工作,可能真的会先被 Agent 吃掉。
05|视觉能力全面升级,AI 不只是看得见,而是看得更准了
Computer Use 背后的核心,其实是视觉能力的升级。
GPT-5.4 这次新增了 original 图片输入模式,支持超高分辨率图像输入,最高可达 1024 万像素,而 high 模式也升级到了 256 万像素。
这意味着它处理复杂界面、高清截图、文档页面、图表细节时,会更精确。
直白点说:
以前模型“看图”,很多时候是模糊理解;
现在它开始接近真正意义上的“视觉解析”。
这带来的变化非常直接:
点按钮更准了
看图理解更稳了
文档结构识别更强了
图像定位能力更好了
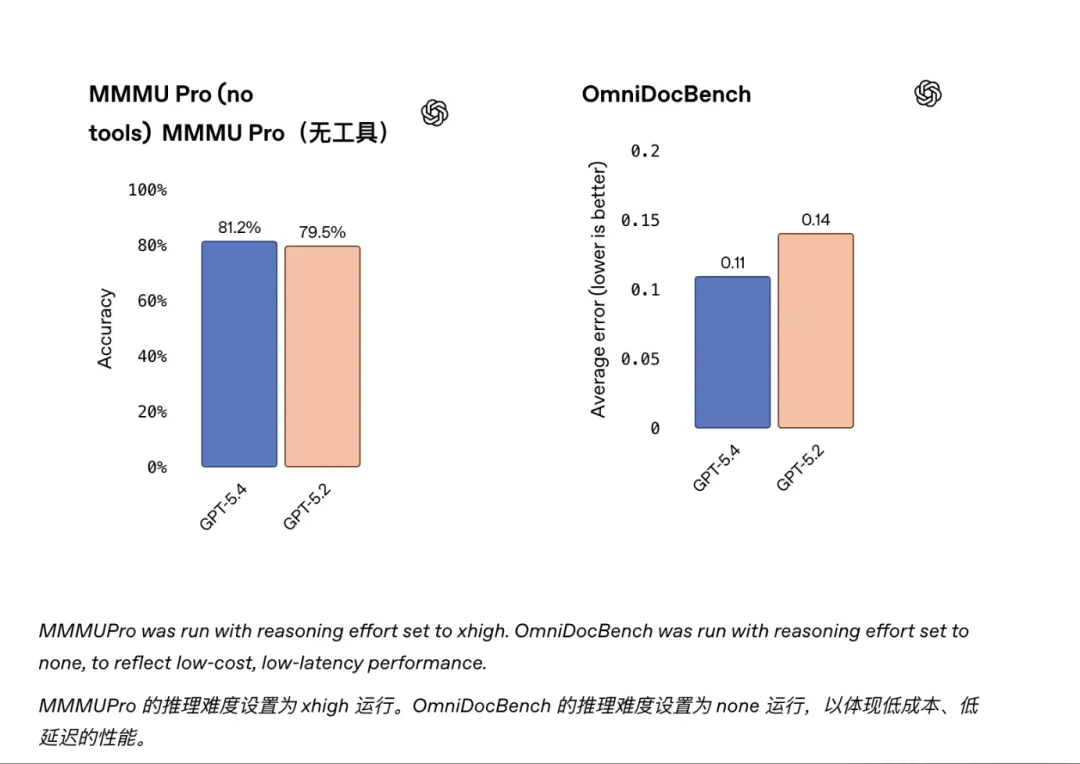
在 MMMU-Pro 视觉理解测试中,GPT-5.4 的成绩进一步提升。
文档解析方面,在 OmniDocBench 上,它的平均错误率也明显下降。
这意味着:
以后 AI 不只是能读文字,还能更可靠地读截图、读表格、读 PDF、读复杂版面。
而这正是办公自动化和电脑操作能力成立的基础。
06|编程更强,但更可怕的是:它开始“边写边干”
GPT-5.4 还整合了 GPT-5.3-Codex 的前沿编程能力。
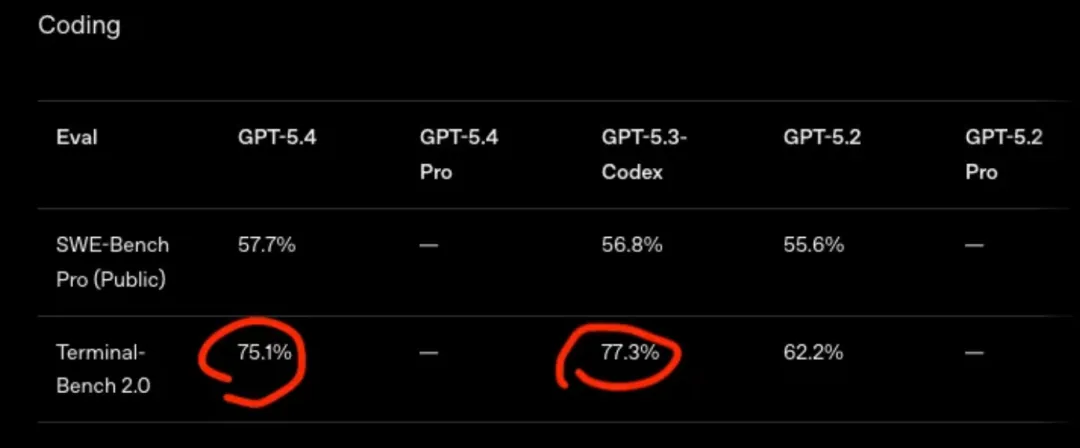
在 SWE-Bench Pro 上,它达到 57.7%;
在 Terminal-Bench 2.0 上得分 75.1%;
而且延迟更低。
这意味着对开发者来说,它不只是“写代码更好”,而是整体工作流更顺了:
理解项目上下文更强
多文件改动更稳定
工具调用更准确
终端任务完成度更高
前端界面生成更美观
OpenAI 还特别提到,GPT-5.4 在复杂前端任务上表现尤其突出,生成的 UI 比以往所有模型都更美观、更可用。
这件事很值得重视。
因为写代码的上半场,是“能不能写出来”;
而下半场,是“能不能写得像能上线的东西”。
显然,OpenAI 正在把模型往第二阶段推。
更有意思的是,它还发布了一个实验性的 Codex Skill:Playwright (Interactive)。
什么意思?
就是模型可以在构建 Web 或 Electron 应用时,一边写,一边测,一边调。
本质上,它开始拥有“自测 + 自修”的能力。
这个方向一旦成熟,对软件开发流程的冲击会非常大。

07|最省 token 的推理模型,贵一点,但可能反而更便宜
看价格,GPT-5.4 比 GPT-5.2 确实更贵了一点:
输入:从 $1.75/M 提升到 $2.50/M
输出:从 $14/M 提升到 $15/M
Pro 版本也同步上涨。
但这次 OpenAI 强调了一个核心点:
GPT-5.4 是目前最省 token 的推理模型。
什么意思?
就是它虽然单价更高,但完成同样任务所消耗的推理 token 更少,整体速度更快。
对于很多真实业务场景来说,最终看的不是“单 token 单价”,而是:
完成一个任务总共要花多少钱。
如果它能用更少的轮次、更少的 token、更少的错误返工把任务做完,那总成本很可能反而下降。
这也是为什么 OpenAI 这次一直在强调:
效率,已经开始比参数和跑分更重要。

08|工具调用终于没那么“烧 token”了
这次还有个非常容易被低估的升级:Tool Search。
以前给模型配工具时,有个非常头疼的问题:
你得把所有工具定义都塞进 prompt 里。
工具少还好,一旦工具多起来,提示词会膨胀得非常夸张。
几万 token 可能还没开始做事,先被工具说明吃掉了。
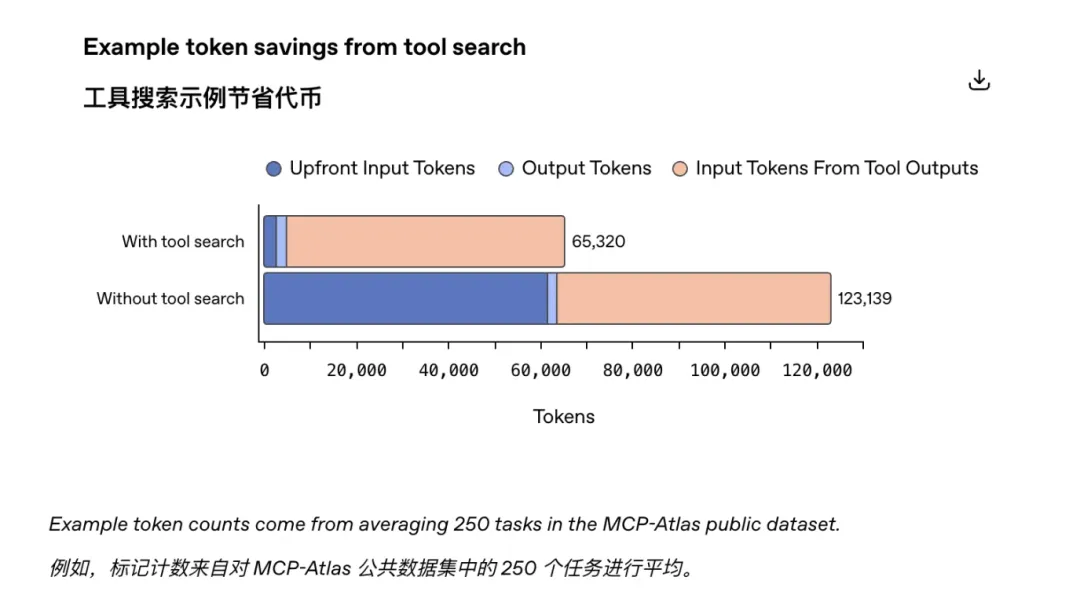
而 GPT-5.4 引入的 Tool Search 机制,本质是:
先只给模型一个轻量级工具列表,真正需要某个工具时,再去查那个工具的定义并临时加载。
这个设计的价值非常大:
更省 token
更快
更便宜
缓存更友好
多工具系统可扩展性更强
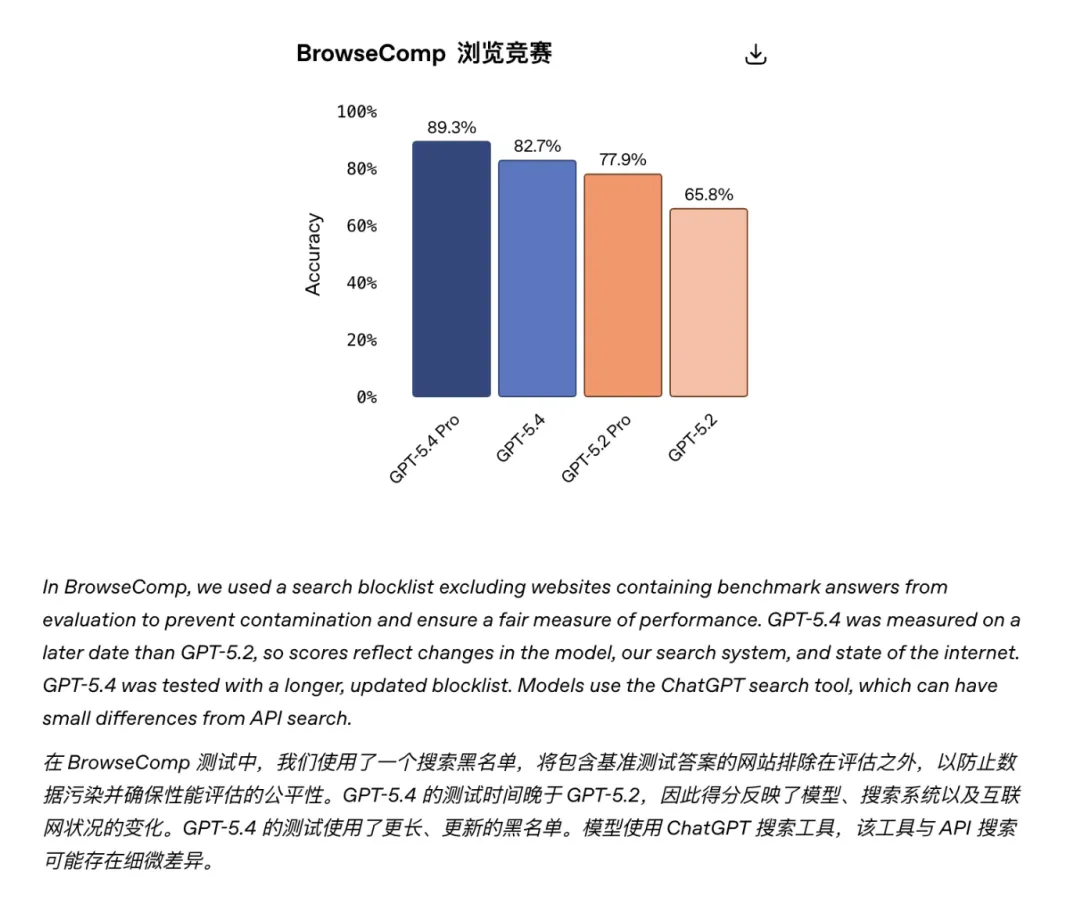
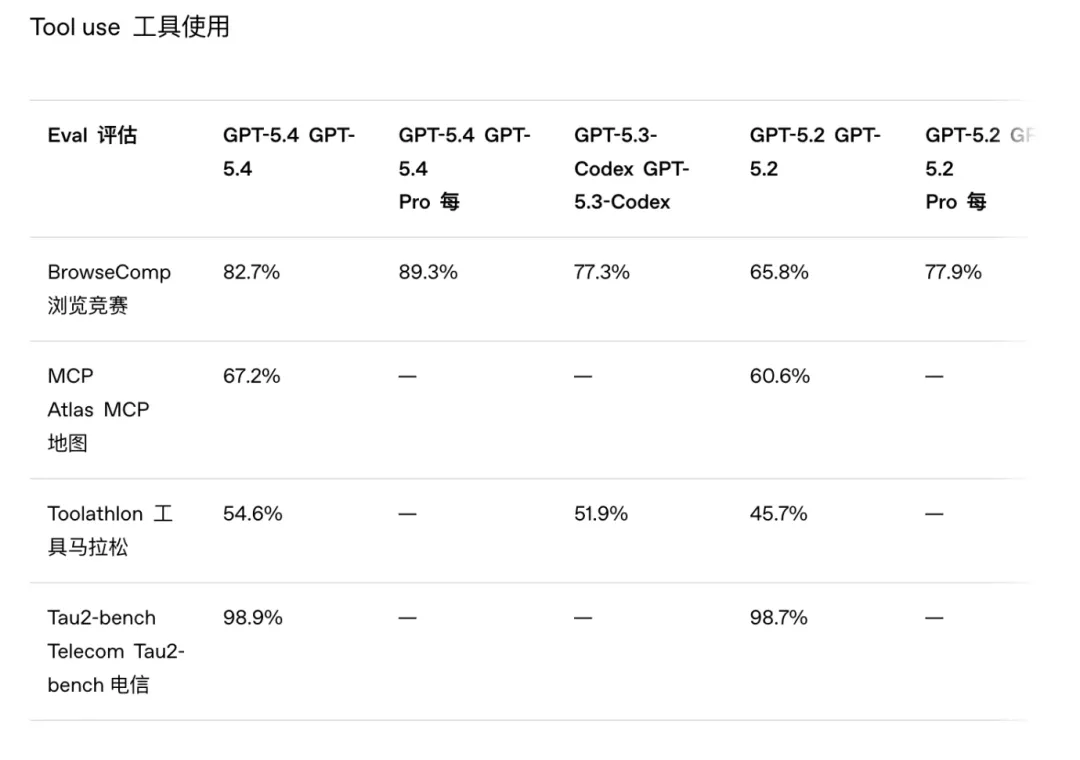
在 MCP Atlas 测试中,36 个 MCP 服务器同时开启时,Tool Search 比传统模式减少了 47% token 消耗,而准确率不变。
这对真正做 Agent、MCP、企业工具编排的人来说,几乎是实打实的生产力升级。
因为很多时候,限制 Agent 落地的不是模型智商,而是:
调用成本太高,系统太重,工具一多就失控。
GPT-5.4 正在试图把这件事变得更可用。
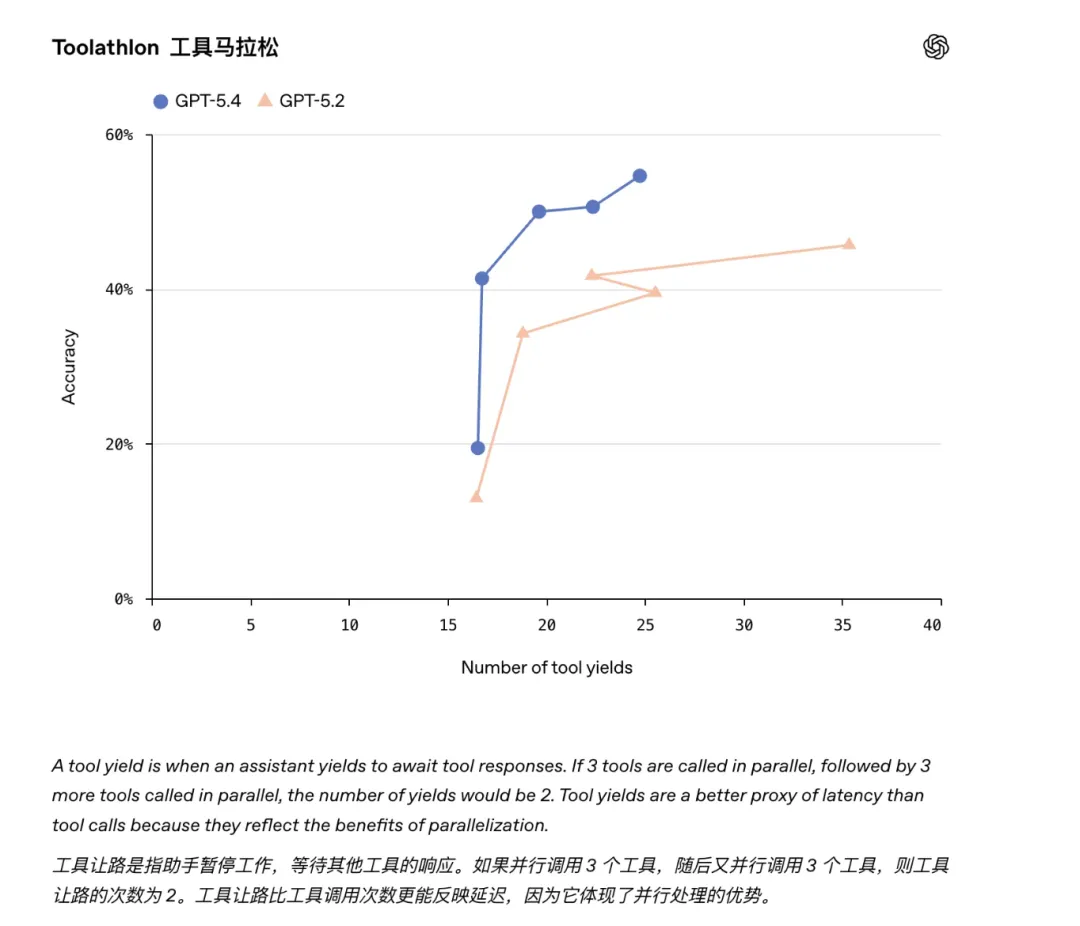
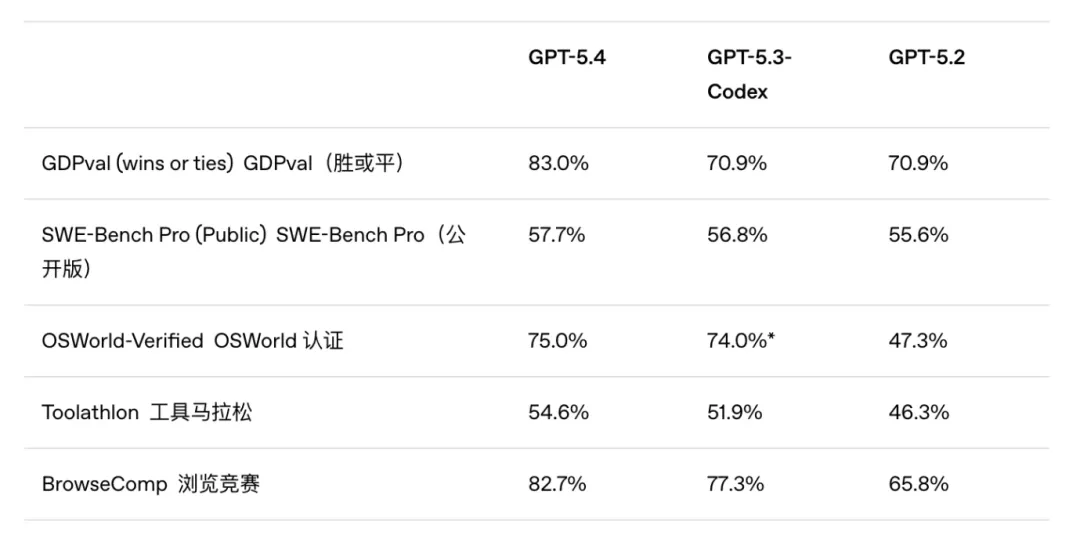
09|更少幻觉,才是企业真正关心的能力
对普通用户来说,模型“更聪明”很重要;
但对企业来说,另一个能力更关键:
少胡说。
OpenAI 这次非常明确地说,GPT-5.4 是目前最不容易产生幻觉的模型。
与 GPT-5.2 相比:
单条回答中的错误声明减少 33%
整条回答包含任何错误的概率降低 18%
这件事的重要性,怎么强调都不过分。
因为大模型真正进入知识工作场景时,最怕的不是“不会”,而是“很自信地说错”。
尤其在这些场景里:
金融分析
法务辅助
研究咨询
企业文档处理
商业汇报
表格建模
幻灯片制作
如果幻觉率降不下来,模型再强也很难真正进入核心流程。
而从 OpenAI 给出的测试结果看,GPT-5.4 在知识工作和办公任务上的能力,已经有了明显上台阶的趋势。
比如在 GDPval 这类知识工作测试中,它在 44 个职业的实际任务中,83.0% 的情况下达到或超过行业专业人员水平。
在投行分析师电子表格建模任务上,也从 GPT-5.2 的 68.4% 提升到 87.3%。
甚至 PPT 制作,人类评审也更偏好 GPT-5.4 生成的版本。
这说明它的价值正在从“写个草稿”走向“产出像样交付物”。
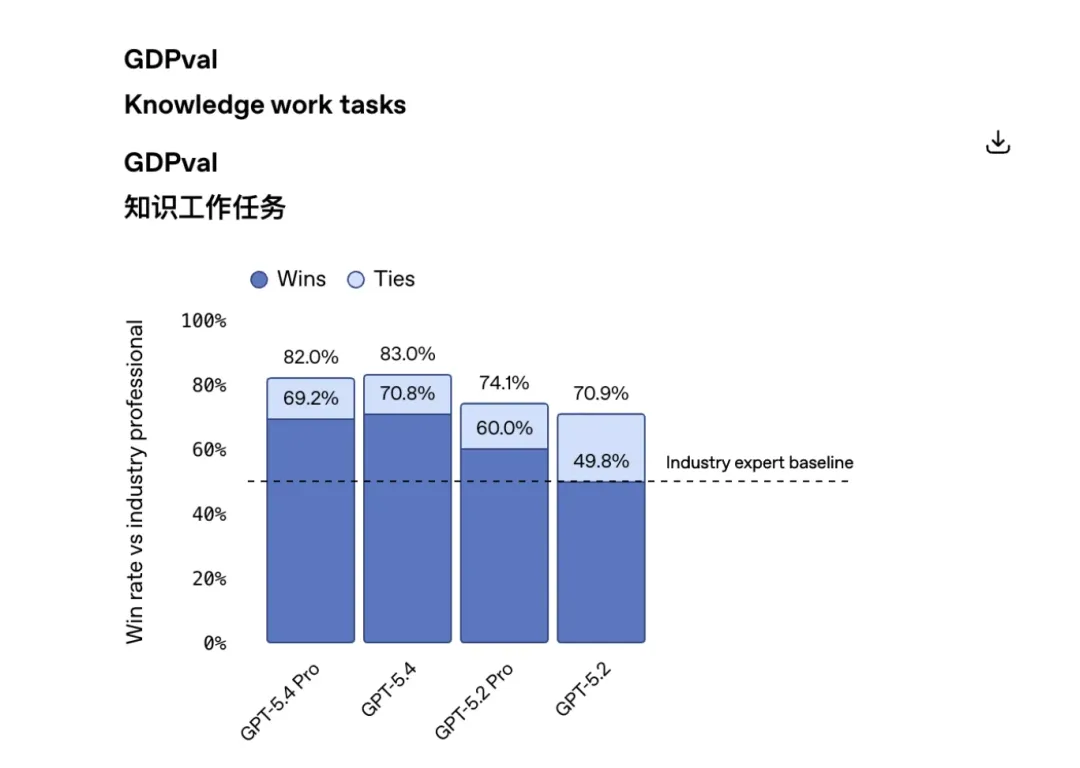
10|一组跑分看明白:GPT-5.4 到底强在哪
如果把这次的关键成绩浓缩来看,你会发现 GPT-5.4 的提升并不是某一个点特别突出,而是几乎全面增强:
编程
SWE-Bench Pro:57.7%
Terminal-Bench 2.0:75.1%
电脑操作与视觉
OSWorld:75.0%
MMMU-Pro:81.2%
工具与搜索
BrowseComp:82.7%
Toolathlon:54.6%
MCP Atlas:67.2%
学术与推理
ARC-AGI-2:73.3%
FrontierMath Tier 4:27.1%
Humanity’s Last Exam(带工具):52.1%
GPQA Diamond:92.8%
而 GPT-5.4 Pro 还进一步拉高了多项上限。
这说明一个问题:
OpenAI 这次不是只想做一个“更强的聊天模型”,而是在做一个真正面向复杂现实任务的通用执行模型。

11|谁能用?哪些人会最先受益?
根据目前的信息:
在 ChatGPT 里,GPT-5.4 Thinking 已向 Plus、Team、Pro 用户开放,替代 GPT-5.2 Thinking。
Enterprise 和 Edu 用户可通过管理员开启早期访问。
API 方面,模型 ID 分别是:
gpt-5.4gpt-5.4-pro
那么,谁会最先感受到这次升级的价值?
我觉得会是这几类人:
第一类,开发者。
长上下文、强编程、工具调用优化、Computer Use、边写边测,这些几乎全是开发效率利好。
第二类,重度知识工作者。
研究、咨询、金融、法务、战略、运营、内容策划,都会明显受益于更稳的长链路推理和更低的幻觉率。
第三类,AI Agent 创业者。
过去很多 Agent 项目卡在“能 demo,不能落地”,而 GPT-5.4 正在补这些最痛的短板。
第四类,高频使用 ChatGPT 的高级用户。
尤其是复杂任务场景,中途打断、深度搜索、长任务协作,会显著改善体验。
12|真正值得关注的,不是 GPT-5.4 有多强,而是一个时代变了
如果只把 GPT-5.4 看成“跑分更高的新模型”,那就低估它了。
这次最值得关注的,其实不是某一项 benchmark 多了几个点,而是 OpenAI 展现出来的产品方向:
未来的大模型,不再只是回答问题,而是围绕“真实工作”来设计。
你会发现 GPT-5.4 的所有升级,都指向同一件事:
更长记忆
更强推理
更好编程
更会用工具
更少幻觉
更能操作电脑
更适合中途协作
更能处理办公交付物
这已经不是一个“聊天机器人”的升级逻辑了。
这是一个“数字工作者”的升级逻辑。
换句话说:
AI 的下一个阶段,已经不是陪你聊天,而是开始接手工作。
而 GPT-5.4,正在把这个未来往前推一大步。

结语:这次又轮到 OpenAI 了
过去一段时间,外界一直在问:
大模型还有没有“下一次明显跃迁”?
现在看,OpenAI 给出的答案是:
有,而且不只是一点点。
百万上下文、实时打断、电脑操作、视觉升级、编程增强、工具调用优化、幻觉下降、办公能力提升……
这些能力单独拿出来一个,都足够成为卖点;
而这次,它们被整合进了同一代模型。
这意味着,大模型正在从“能力演示”走向“生产系统”。
所以,GPT-5.4 最值得记住的一句话,不是它有多强,而是:
AI 开始真正像一个能协作、能执行、能交付的工作搭档了。
而这一次,OpenAI 又一次把节奏带了起来。
如下图所示:https://chat.aishare.icu

点这里👇关注我,记得点赞和推荐哦~
