 夜雨聆风
夜雨聆风如果你已经把 OpenClaw 跑在独立电脑/Docker 里了,下一步很容易遇到一个问题:一个 agent 什么都做,最后往往什么都做不清楚。
开发、产品、测试、调研、数据分析、运营,全塞进一个会话里,短期很省事,长期一定会乱。上下文会串,角色会糊,机器人在不同群里说话也会越来越不像一个稳定的岗位。
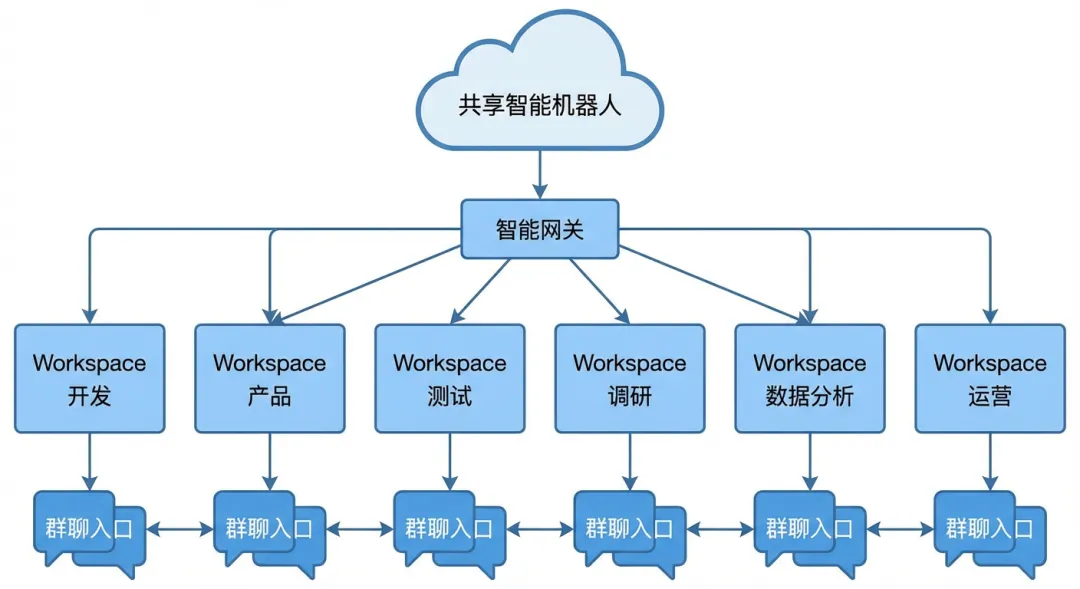
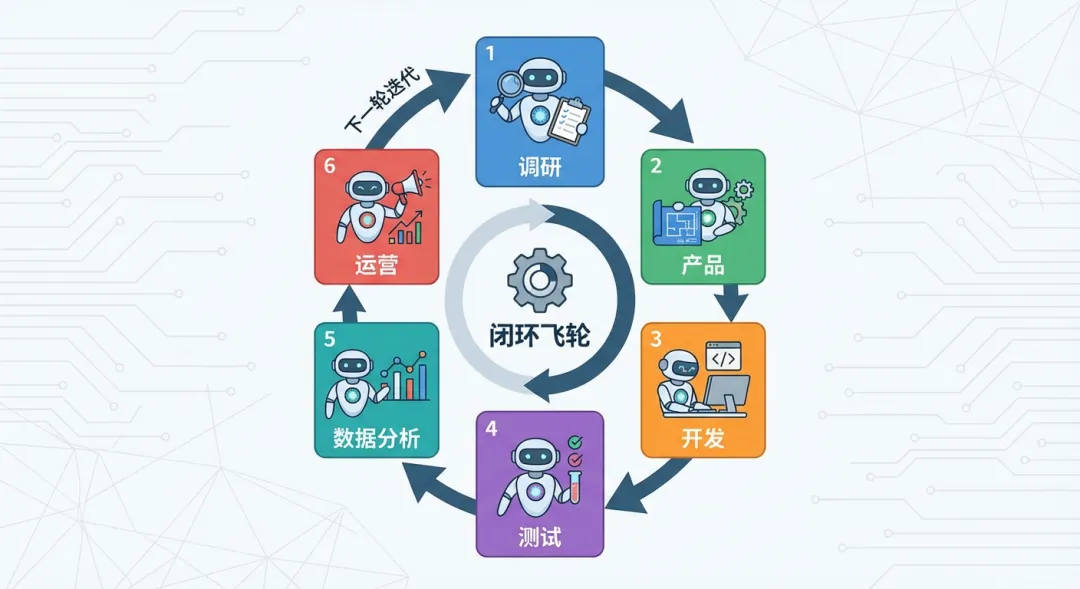
所以我这次没继续修 prompt,而是直接改架构:在同一个 OpenClaw gateway 下挂 6 个 agent,给它们各自的 workspace,再让同一个飞书机器人按群聊 id 路由到不同角色,最后再把这 6 个角色串成一个闭环飞轮。
最终结果很干脆:
开发群进开发 agent 产品群进产品 agent 测试群进 QA agent 调研群进 research agent 数据分析群进 analytics agent 运营群进 ops agent
对外还是一个机器人,对内已经是六个不同的脑子,而且它们开始形成回流。

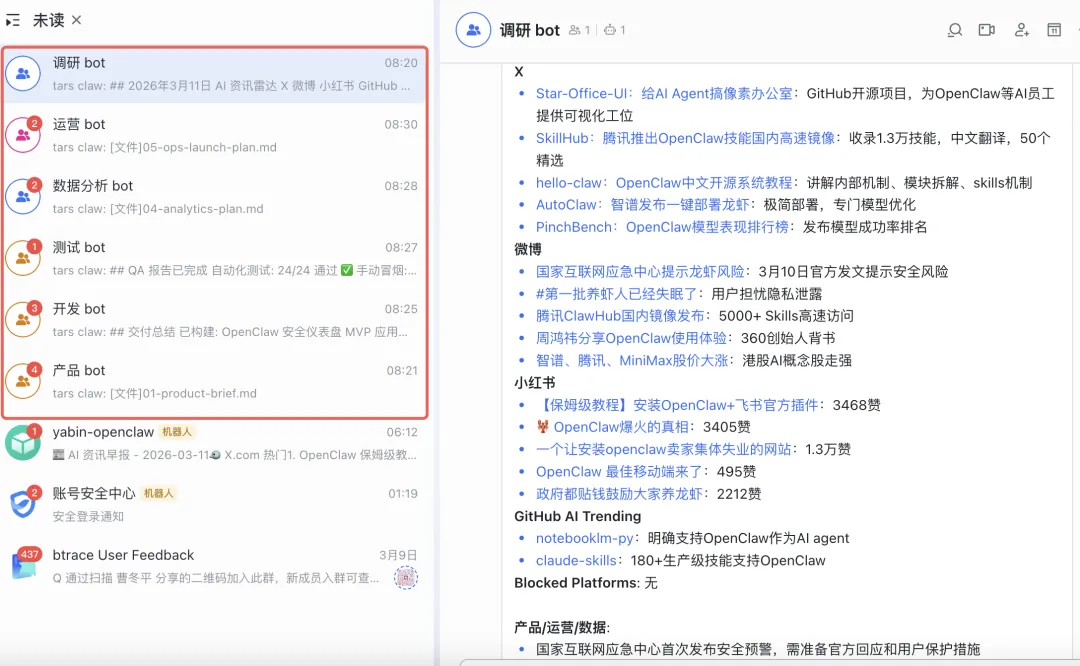
根据最新AI相关内容调研,经过产品bot,挖掘出核心痛点,并进行MVP最小化产品方案设计
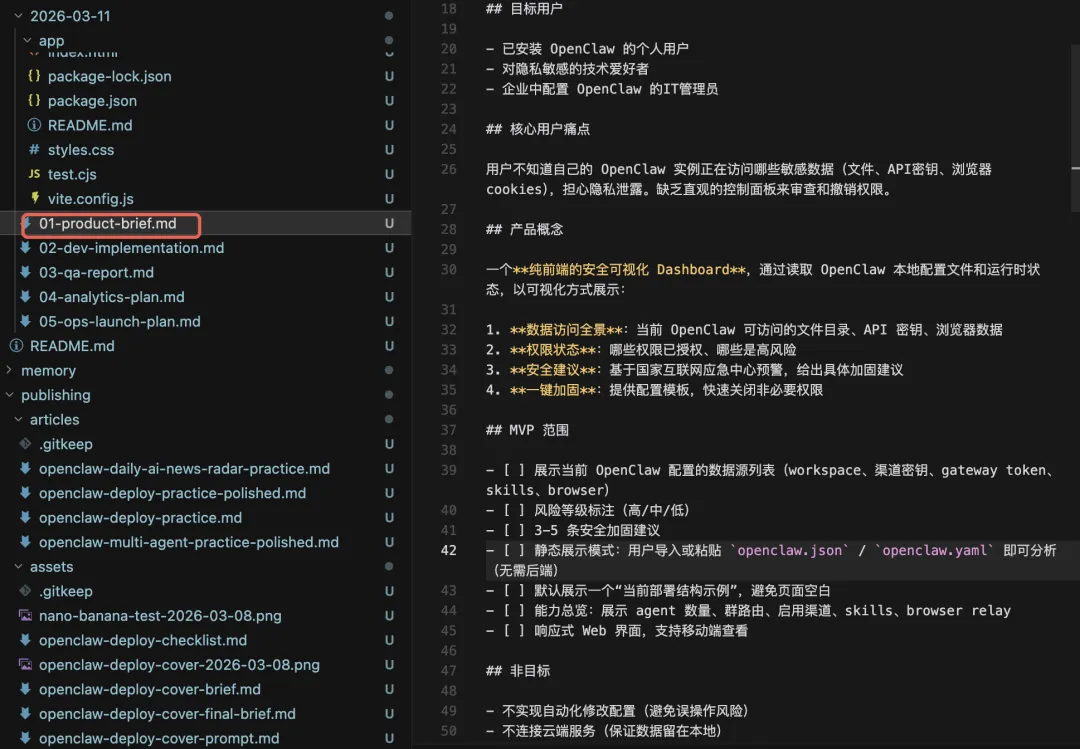
然后自动把产品需求给到开发bot,开发bot自动开发
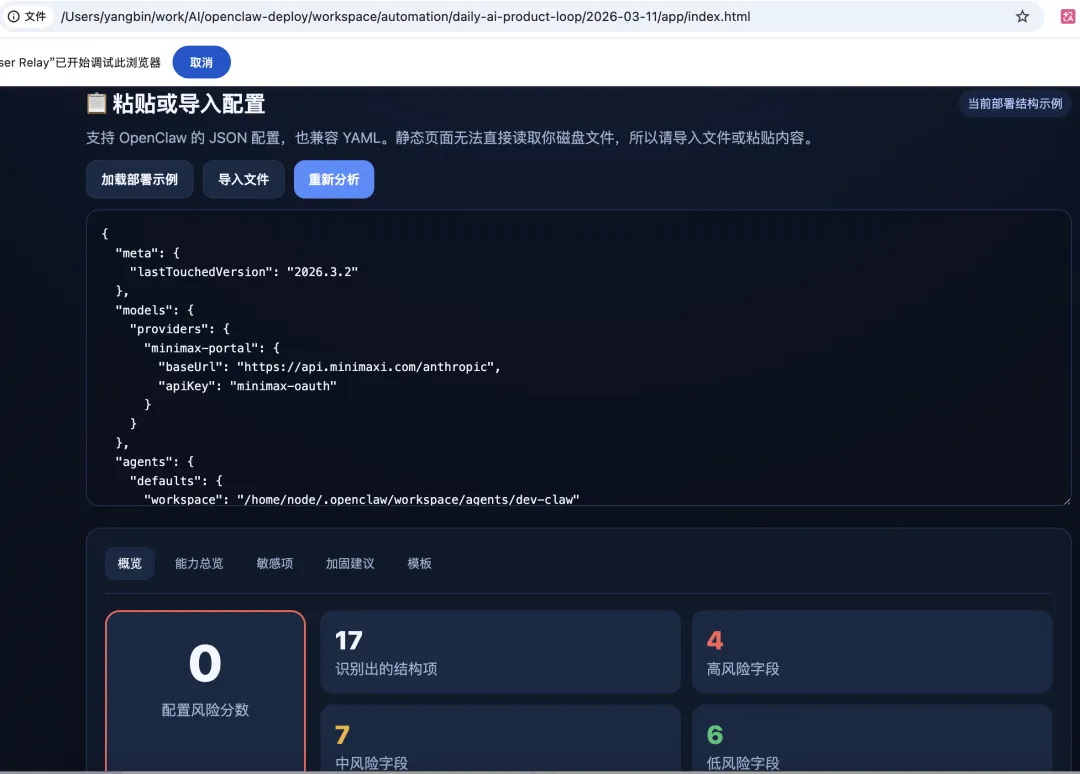

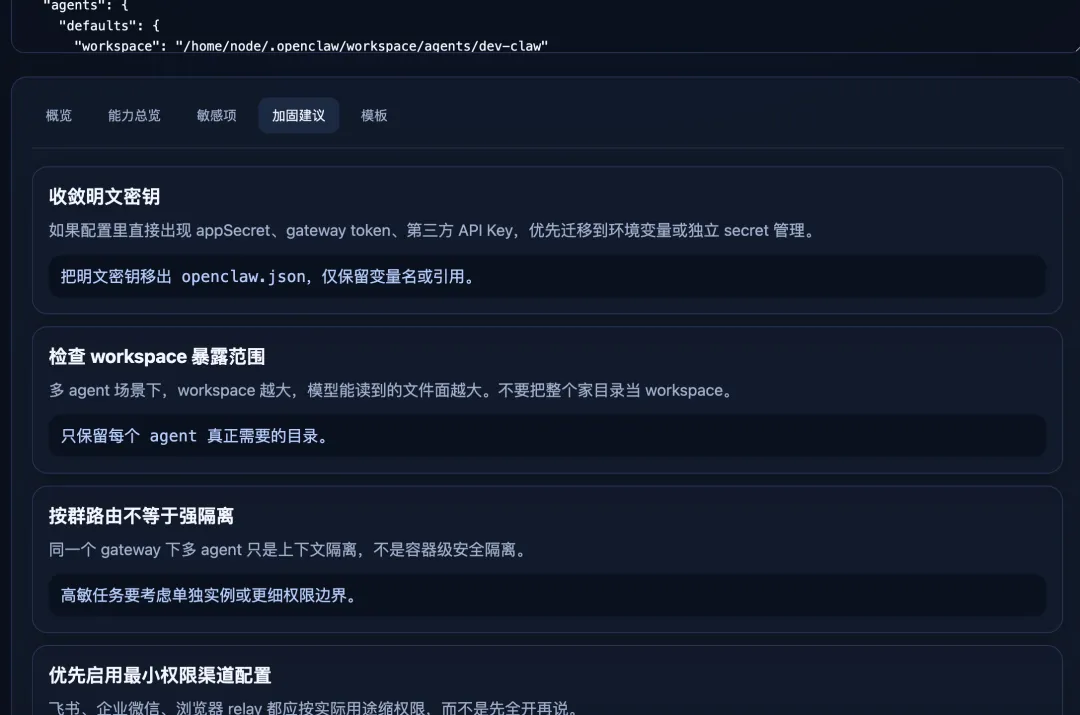
下面我们进行一步步拆解整体实现,也助你打字自己的小龙虾军团
一、团队架构:“一个 gateway,多 agent”模式的claw团队
很多人第一次做多 agent,会先改配置,加几个 agentId,然后觉得事情差不多了。
但这只解决了“名字变多了”,没有解决“角色真的分开了”。
真正的问题其实是这句:
我想让同一个机器人,在不同场景里有不同角色,而且尽量不要串上下文。
这背后至少有三层要同时成立:
路由得分开,不同群要进不同 agent workspace 得分开,不同角色要有自己的本地上下文 角色规则得分开,不然最后还是一个通用助手
少了任何一层,这套方案都会退化。
为什么这次选的是“一个 gateway,多 agent”
理论上当然也可以做成多个独立 OpenClaw 实例。
那样隔离更彻底,边界也更清晰,但代价是运维复杂度会直接上去。每个实例都要维护:
●容器
●配置
●日志
●模型
●渠道
●升级
对个人开发机和小团队来说,这一步太重了。
所以这次我选的是更现实的折中:
●一个 gateway
●六个 agent
●六个 workspace
●一个飞书机器人
●按群聊 id 路由
这不是最重的架构,但它能先解决最痛的两个问题:
●上下文不再乱窜
●机器人终于能在不同群里稳定扮演不同岗位
●上线后的数据和运营结果还能回到下一轮产品和研发
最终落地架构
```
飞书同一个机器人
├─ 开发群 -> main
├─ 产品群 -> product-claw
├─ 测试群 -> qa-claw
├─ 调研群 -> research-claw
├─ 数据分析群 -> analytics-claw
└─ 运营群 -> ops-claw
OpenClaw Gateway
├─ main -> workspace/agents/dev-claw
├─ product-claw -> workspace/agents/product-claw
├─ qa-claw -> workspace/agents/qa-claw
├─ research-claw -> workspace/agents/research-claw
├─ analytics-claw -> workspace/agents/analytics-claw
└─ ops-claw -> workspace/agents/ops-claw
```
这里有个细节很关键:开发 agent 的真实 id 我保留成了 main。
原因很简单,OpenClaw 控制台和部分旧会话默认还会找 main。如果你把默认开发 agent 直接改没,控制台很容易报:
unknown agent id "main" 所以我的处理方式是:
●默认开发 agent 保留 main
●dev-claw 只作为兼容别名存在
这不是命名审美,而是稳定性问题。
二、把 6 个 agent 的 workspace 先拆开
这是基础动作。
我给六个角色分别建了六套 workspace:
●workspace/agents/dev-claw
●workspace/agents/product-claw
●workspace/agents/qa-claw
●workspace/agents/research-claw
●workspace/agents/analytics-claw
●workspace/agents/ops-claw
这一步的收益特别直接:
●不同角色的长期记忆不会混在一起
●本地 skill、模板、文档可以按角色分别放
●同一个飞书机器人进来的消息,最终会落进不同工作目录
如果不拆 workspace,多 agent 很容易只是幻觉。
真正让这套系统开始“转起来”的,是后面补上的两个角色:
●analytics-claw:盯上线后的指标、漏斗、留存和预期差
●ops-claw:盯活动、活跃、转化、营收和口碑扩散
到这一步,OpenClaw 里就不只是“分工”,而是开始形成 research -> product -> dev -> qa -> analytics -> ops -> 下一轮 的闭环飞轮。
三、给每个 agent 明确角色边界
只改名字和 emoji 根本不够。
所以我给每个 agent 都单独配置了:
●AGENTS.md
●IDENTITY.md
●SOUL.md
●USER.md
●TOOLS.md
●MEMORY.md
然后按职责分别写清楚:
开发 agent
负责:
●写代码
●改配置
●查日志
●接 API
●做最小改动和最小验证
它的风格是实现优先,少废话,有判断,遇到愚蠢操作会直接点出来。
产品 agent
负责:
●写 PRD
●做优先级判断
●输出需求边界
●拆执行顺序
它的核心规则不是“帮我头脑风暴”,而是把目标、scope、non-goals 和 acceptance criteria 说清楚。
QA agent
负责:
●写测试计划
●做回归检查
●做发布判断
●输出 findings first 的审查结果
它不是来讲平衡的,它是来把风险翻出来的。
Research agent
负责:
●查变化快的信息
●做来源比对
●给出 source-backed summary
●区分事实、推断和建议
它最重要的规则是:不要把猜测伪装成事实。
四、给产品 agent 装一整套 PM Skills
这一段是我这次特别满意的增强。
因为产品 agent 如果只靠手写规则,最多只是“更像产品经理”,但还不够像一个真正有方法库的 PM。
所以我把开源的 Product Manager Skills 整套装进了 product-claw 的本地 workspace。
最后装进去的是:
●46 个 skills
●6 个 command wrappers
放在:
●workspace/agents/product-claw/skills
●workspace/agents/product-claw/commands
这一步之后,product-claw 就不只是“会写 PRD”,而是有了一整套可执行的方法库,比如:
●PRD workflow
●roadmap planning
●prioritization advisor
●discovery process
●strategy session
而且我没有把整个上游仓库硬搬进来,只装了:
●skills/
●commands/
●少量参考文档
像它上游的 app/ 和 repo 级工具脚本,我没有丢进 agent workspace。原因很简单:
agent 需要的是方法库,不是额外的运行面。
五、同一个飞书机器人,按群聊 id 路由到不同 agent
前面这些都做完以后,最后的关键就是路由。
如果没有路由,飞书消息还是会全进默认 agent,前面的拆分就白做了。
我的做法是在 config/openclaw.json 里加 bindings,按 peer-id 绑定到指定 agent。
这次实际绑定的是:
●qa-claw ← oc_xxx111
●research-claw ← oc_xxx222
●product-claw ← oc_xxx333
●main ← oc_xxx444
●analytics-claw ← oc_xxx555
●ops-claw ← oc_xxx666
这意味着:
●对飞书用户来说,还是同一个机器人
●对 OpenClaw 来说,消息已经被分流进不同 agent
你可以把它理解成:
同一个前台号码,背后接了六个分机。
这套设计最大的好处,就是对用户没有学习成本。
在产品群里聊产品,在开发群里聊开发,在测试群里聊测试,在调研群里聊调研,在数据分析群里看指标,在运营群里推进活动。机器人自己会进正确的角色。
六、验证通过,终于不拧巴了
验证通过后,我最直接的感受不是“酷”,而是:终于不拧巴了。
以前一个通用 agent 最难受的地方,是它在同一段对话里会来回切身份:
●一会儿像产品
●一会儿像开发
●一会儿又像调研
●最后什么都沾一点,但没有一个特别像
现在拆开以后,这个问题明显减轻了。
产品群里,它更像真的在收敛 scope 和写 PRD。
开发群里,它更像真的在改配置、查日志、落 patch。
测试群里,它会更自然地从风险和验证角度说话。
调研群里,它也不会轻易把没查过的东西说得像板上钉钉。
数据分析群里,它会追着你要指标、口径和对照组。
运营群里,它会更自然地去想活动、增长、活跃和转化。这个变化不是“看起来像”,而是连续用几轮以后你会感觉到:
每个群的上下文开始有自己的惯性了。
七、这套方案的边界
这套方案解决的是:
●角色分工
●上下文隔离
●单机器人多场景协作
但它没有解决的是:
●容器级强安全隔离
●多套全局凭证隔离
●多飞书机器人并行的插件级支持
因为本质上它还是:
●同一个 gateway 进程
●同一个 OpenClaw 实例
●同一套全局配置
所以更准确地说,这是一套:
角色隔离 + 上下文隔离
不是基础设施级彻底隔离。
如果你后面真的要做到团队级、组织级的强边界,那还是应该走多个独立 OpenClaw 实例。
但对个人开发机和小团队试运行来说,这一步没必要一开始就上。
八、实践中一些有价值的经验
1. 默认开发 agent 尽量保留 main
这不是保守,而是兼容性现实。
2. 多 agent 的关键不是多写几个 id,而是拆 workspace
不拆 workspace,多 agent 很容易只是幻觉。
3. 人格文件必须落到角色边界上
SOUL.md 有用,但必须和 AGENTS.md、TOOLS.md、MEMORY.md 一起工作。
4. 产品 agent 特别值得挂方法库
开发 agent 靠代码库天然就有很多上下文,产品 agent 没有方法库的话,很容易退化成“会写点文档的通用聊天机器人”。
5. 同一个飞书机器人按群路由,是这套方案最顺手的形态
你当然可以用命令切换、前缀切换、人工切换,但都不如按群路由自然。
因为人在协作里,本来就已经按群在分场景了。
九、遇到的问题:飞书接入还有两个小坑,不补掉体验会差一截
做到按群路由之后,我本来以为这套方案已经差不多了。
结果真正用起来,又冒出来两个很典型的问题:
1.机器人在飞书群里的名字到底在哪里改
2.群里明明只有我和机器人,为什么还是非得 @ 它才回
这两个都不算大问题,但都很影响“专人助手”的使用感。
机器人名字不是在 OpenClaw 里改的
这个问题特别容易想歪。
因为 OpenClaw 里已经配了飞书 appId 和 appSecret,很多人会自然地以为,机器人名称也应该在 openclaw.json 里改。
其实不是。
机器人显示名是在飞书开放平台改,不是在 OpenClaw 里改。
准确一点说,是在应用的 Bot 能力页里改显示名称,然后重新发布。
这事想明白后就很顺:
●appId / appSecret 解决的是“这个机器人是谁”
●Bot 显示名解决的是“别人看到它叫什么”
所以如果你只是想把飞书里的机器人名字换掉,不要去动 OpenClaw 渠道配置,直接去飞书开放平台改 Bot 名称,再发布就行。
文档明明支持关掉 @,结果群里还是不回
这个坑更烦一点,因为它特别像“自己配错了”。
我的诉求其实很简单:
这些群本来就是专门给某个 agent 用的,群里也基本只有我和机器人,那就没必要每次都先 @ 一下。
按 OpenClaw 的文档,飞书群聊本来就支持按群配置:
"channels": {
"feishu-china": {
"groupPolicy": "open",
"groups": {
"oc_xxx": { "requireMention": false }
}
}
}
我也确实这么配了。
结果配置写进去、网关重启完,群里还是没回。
这时候最值钱的动作不是继续猜,而是直接看日志。
日志给出的信息很清楚:
Inbound: chat=oc_xxx type=text ... policy rejected: message did not mention bot 这说明消息其实已经进了网关,但又在插件内部被拦了一次。
继续往下看 feishu-china 的运行时代码,问题就出来了:
●文档支持 groups..requireMention
●配置 schema 也支持这个字段
●但真正跑策略判断时,代码只读了全局 channels.feishu-china.requireMention
●当前群的覆盖配置根本没被用上
说白了,就是这版插件自己有个 bug。
所以最后的处理不是“继续调配置”,而是直接修运行时代码:
●按 ctx.chatId 读取当前群的覆盖配置
●优先使用 groups..requireMention
●再回退到全局默认值
修完再重启网关,群里就能在不 @ 的情况下直接回复了。
这件事背后的结论其实很实用
表面上看,这只是一个“要不要 @”的小问题。
但它背后其实对应的是两种完全不同的使用方式:
●如果机器人是共享工具,那 @ 一下很合理
●如果机器人本来就是某个专属群里的长期助手,那每次都 @ 一下就很蠢
我后来越来越确定一件事:
专人助手式的 agent,交互摩擦一定要足够低。
不然你会不自觉地少用它。
所以这次补完之后,我对这套方案的理解也更完整了:
●名字在飞书侧改,别在 OpenClaw 里绕
●路由在 OpenClaw 里做
●对专属群,尽量关掉 @ 门槛
●如果配置明明对了但还是不工作,第一时间去看运行时日志,不要先怀疑自己
最后总结
如果你已经把 OpenClaw 跑在起来了,我非常建议继续往前做这一步:
不要满足于一个什么都能聊的 agent,尽快把它拆成几个真正有边界的角色。
这次我验证下来的最实用组合是:
●一个 OpenClaw gateway
●一个飞书机器人
●多个按职责拆分的 agent
●多个独立 workspace
●按群聊 peer-id 路由
这套设计不会让你瞬间拥有一个完美的多智能体系统。
但它会很稳定地解决一个特别现实的问题:
机器人终于开始像团队,而不是像一个上下文越来越浑的“万能人设”。
而且这次最关键的变化已经不只是“上下文不串了”,而是:
从调研到产品、从开发到测试、从数据到运营,这几件事终于能在一个系统里自己滚起来。
这已经不是玩具升级,而是开始接近真正能长期用的工作流了。
