 夜雨聆风
夜雨聆风大家好,我是齐昂!
Token is Money!
最近,我听到的最多关于 OpenClaw 的说法就是,巨费 Token,说白了也就是需要花大把的真金白银!
一. 前言
之前我并没有在意 Token 的开销,因为我订阅了好几个 Coding Plan + 各种官方非官方API。
但是架不住这个说他花了大几十甚至几百刀,另一个又在群里扔了一个一会就花费了十几刀的截图。
本着质疑加求真的态度,我下载了 OpenClaw 的源码,打算研究一番。
我简单列了几个公式:
1. Money = Token 2. Token = Input Token + Output Token 3. Input Token = System Prompt + User Prompt + History
简单说明一下:
所有针对大模型的规则都是按 Token 计费,每个模型厂商计费规则都不太一样,但是都包含输入 Token 和输出 Token。
拿 GPT 举个例子:

先说输出Token,就是大模型给你回复的内容,或者说你在 IM(Telegram、或者飞书之类的的工具)得到的回复信息,这其中还包括被隐藏了的思考过程信息(Think...)
输入 Token,就是你对大模型或者在你的 IM 中输入的信息 + 外加系统内容隐藏的系统级提示词.
一般来说,用户输入部分 和 直接的获得的答案部分,Token 占比很少, 输出的思考过程,可能相对多一点,占大头的就是系统级的提示词(包括历史记忆)。
今天给大家带来就是源码级拆解 OpenClaw的系统级提示词!
接下来,请坐好,准备发车了!
二. 源码分析
1. 源码下载
git clone https://github.com/openclaw/openclaw2. 源码走读
下载好,用你喜欢的 IDE 或者任何可以打开的工具打开项目
找到 src/agents/system-prompt.ts 文件
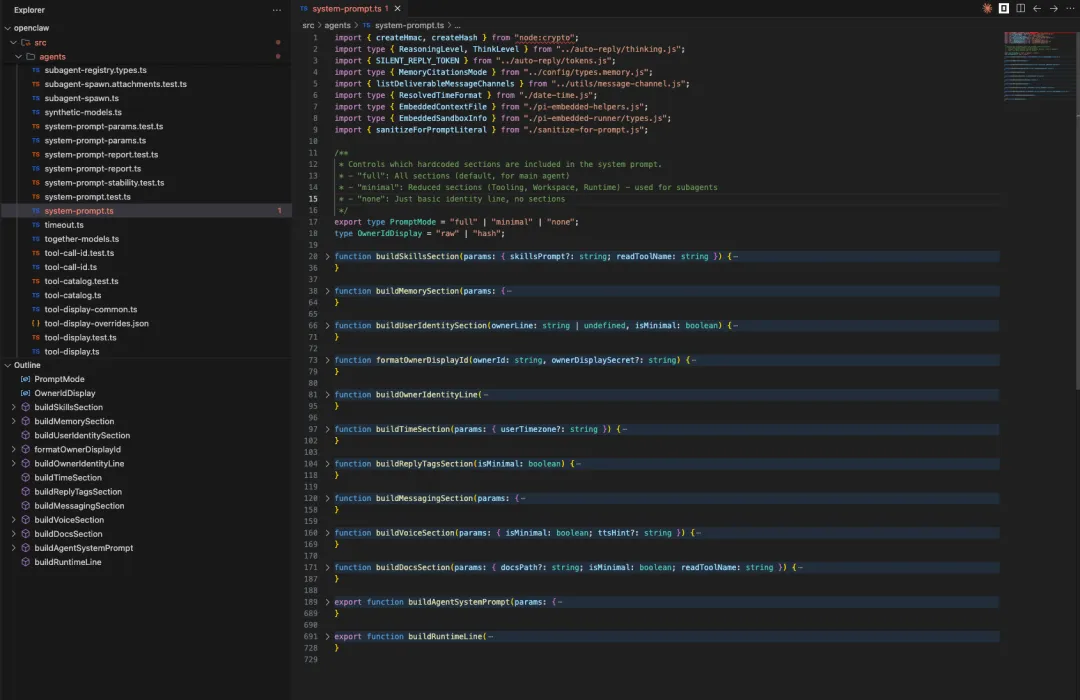
这个文件的核心逻辑就是
1. 拼接系统提示词:buildAgentSystemPrompt 2. 构建运行时:buildRuntimeLine
可以看到,除了这两个对外 export 的函数,还有一些内部调用的函数,对了,这些一个个内置的函数,就构成了整个 SystemPromt的骨架。
这里简单走读一下,按照代码在 buildAgentSystemPrompt中的执行先后顺序,调用逻辑如下:
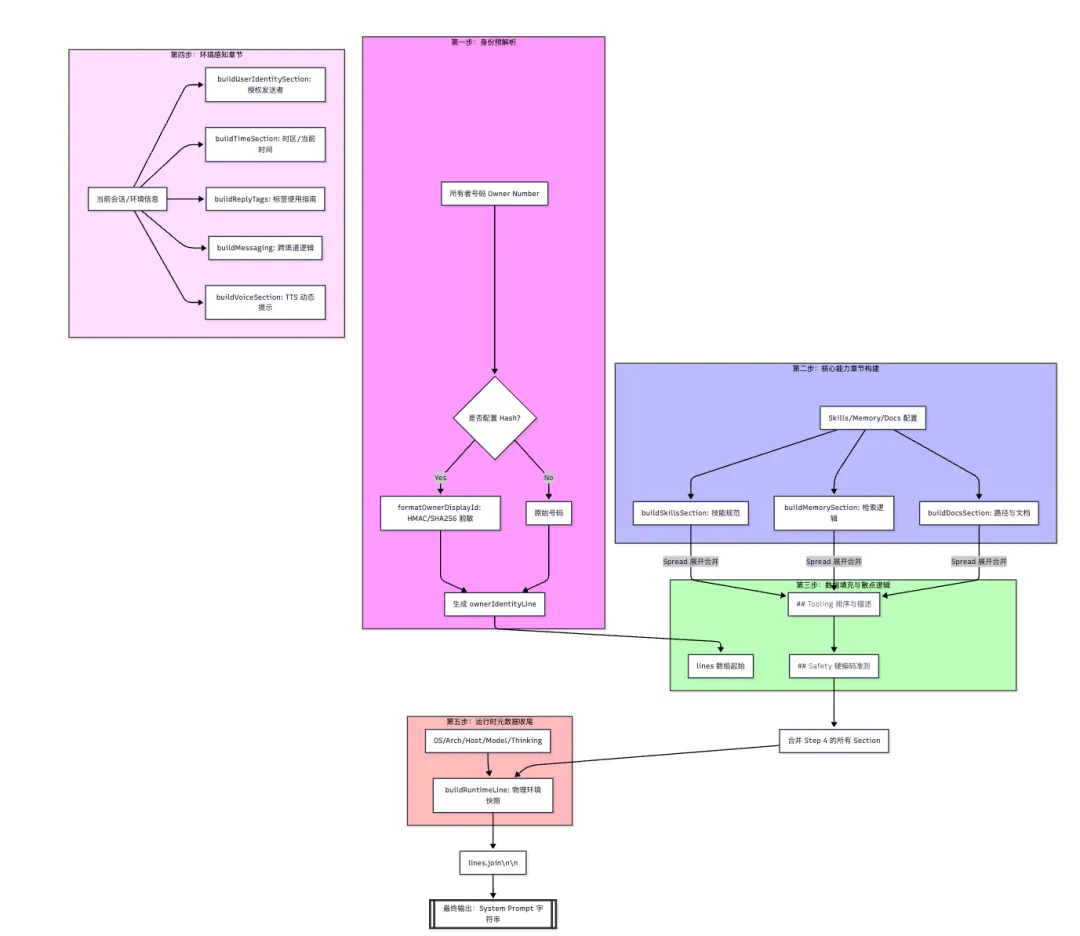
第一步:身份与权限预解析 (Line 345 - 351)在组装数组之前,系统首先处理身份匿名化逻辑。
• buildOwnerIdentityLine:接收所有者号码。 • formatOwnerDisplayId:如果配置了 hash 模式,会调用此函数利用 node:crypto 对手机号进行 HMAC 或 SHA256 脱敏处理。这是为了在提示词中包含所有者信息但不泄露真实号码。
第二步:核心能力章节构建 (Line 401 - 414)这些函数返回字符串数组,用于后续的数组打散(Spread)。
• buildSkillsSection:扫描 skillsPrompt,注入技能使用规范(特别是提示模型先读描述再读代码)。 • buildMemorySection:根据 memory_search 工具的可用性,决定是否注入记忆检索指令。 • buildDocsSection:注入本地及 GitHub 文档路径。
第三步:数组填充与散点逻辑 (Line 422 - 563)进入 lines 数组的构建期。此时会直接合并(Spread)上面生成的 Section。
• 处理 ## Tooling:根据 toolOrder 对工具进行排序和描述匹配。 • 处理 ## Safety:注入硬编码的安全准则。
第四步:环境感知章节注入 (Line 564 - 581)在数组的中后段,调用一些与当前“场景”相关的构建函数:
• buildUserIdentitySection:将第一步解析的身份行放入 ## Authorized Senders。 • buildTimeSection:注入用户时区。 • buildReplyTagsSection:注入特殊回复标签(如 [[reply_to_current]])的使用说明。 • buildMessagingSection:注入跨渠道、跨 Session 发消息的复杂逻辑说明。 • buildVoiceSection:注入 TTS(语音合成)相关的动态提示。
第五步:运行时元数据收尾 (Line 683 - 688)这是最后一步,也是最重要的动态部分。
• buildRuntimeLine:构建那行著名的 Runtime: agent=... | host=... | model=...。它确保模型对自我的物理环境(OS、Arch、Channel、Thinking Level)有最后的同步。
如果感兴趣的话,可以自己找到源码,详细阅读!
三. 系统级提示词
1. 如何获取 Openclaw 系统提示词
看了第二步的提示词的构建逻辑,相信大家也意识到了,这个系统提示词必然会非常长。
没毛病,接下来就教你如何拿到你在运行中的真正的提示词。
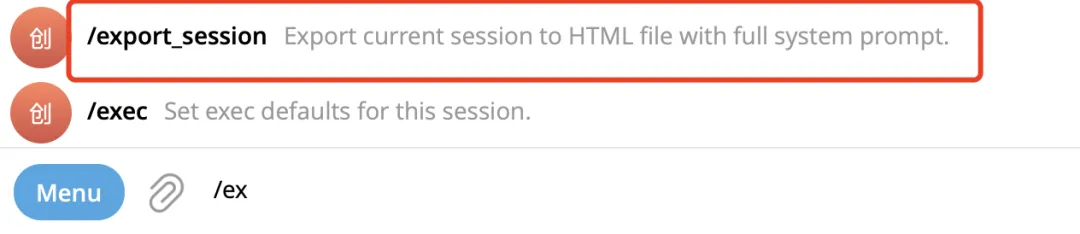
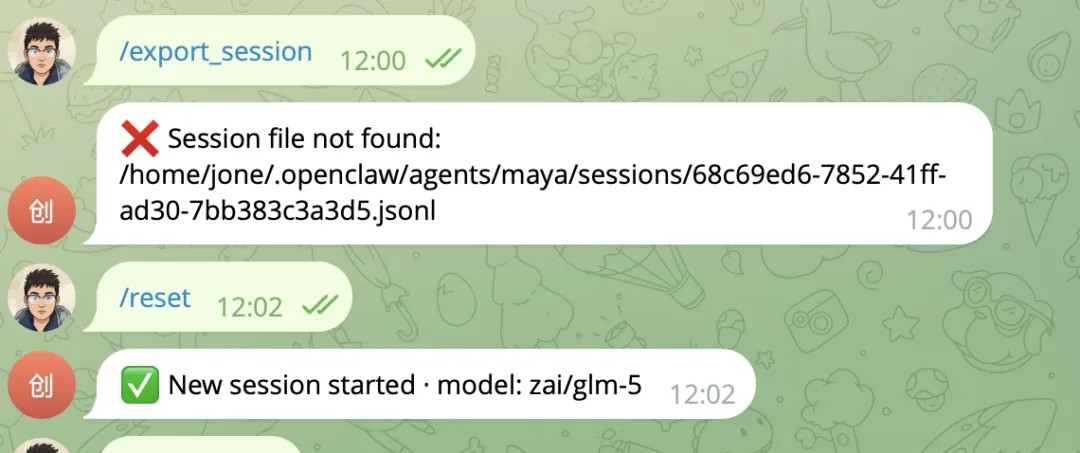
OpenClaw 为我们贴心的提供了一个导出 session 级别的系统提示词命令 /export_session
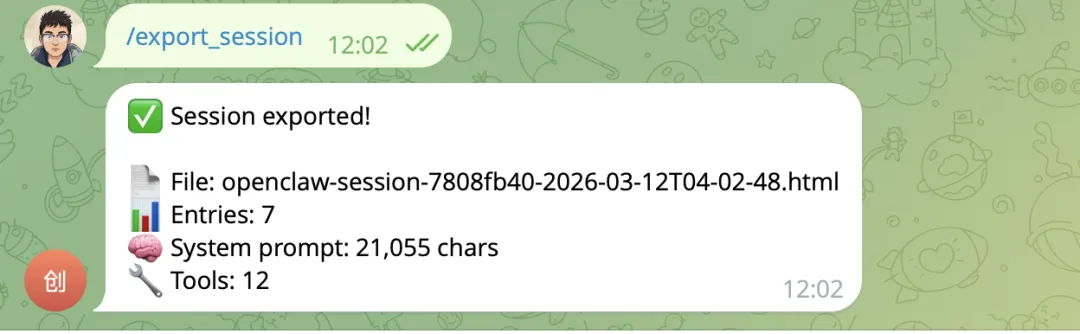
执行后会得到一个 HTMl 文件:
这里,你可能会像我一样遇到一个问题,就是会提示 Session file not found,没关系,运行/rest重置一下,然后再重新执行导出
2. 打开导出的html文件
导出 html 后,如果你的服务是运行在本机的,那么直接打开就 ok 了,如果部署在远程服务器的,那么就下载到本地再打开。
在这里,你可能也会遇到一个坑,就是打开的页面会是这个样子:
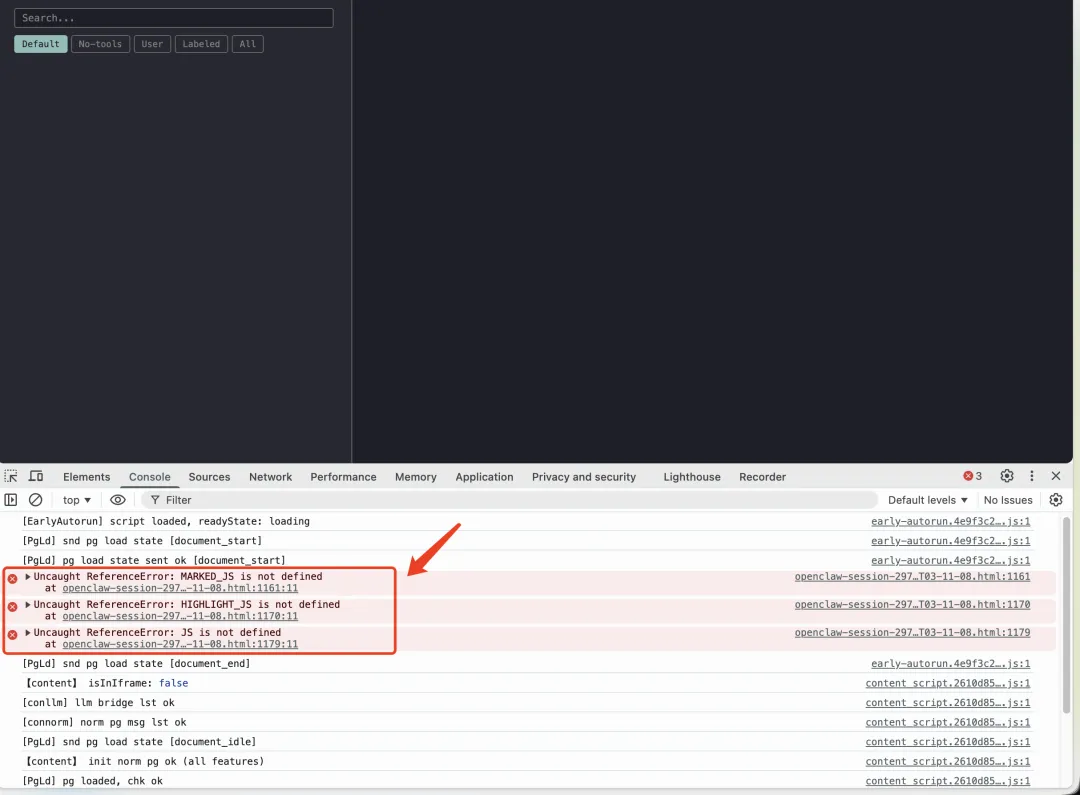
并没有加载任何信息,并且我也把报错信息给贴出来了,三个 js 文件找不到。
ok,我们又要回到源码中去。
2.1 /export_session的实现原理
实现代码在
src/auto-reply/reply/command-export-session.ts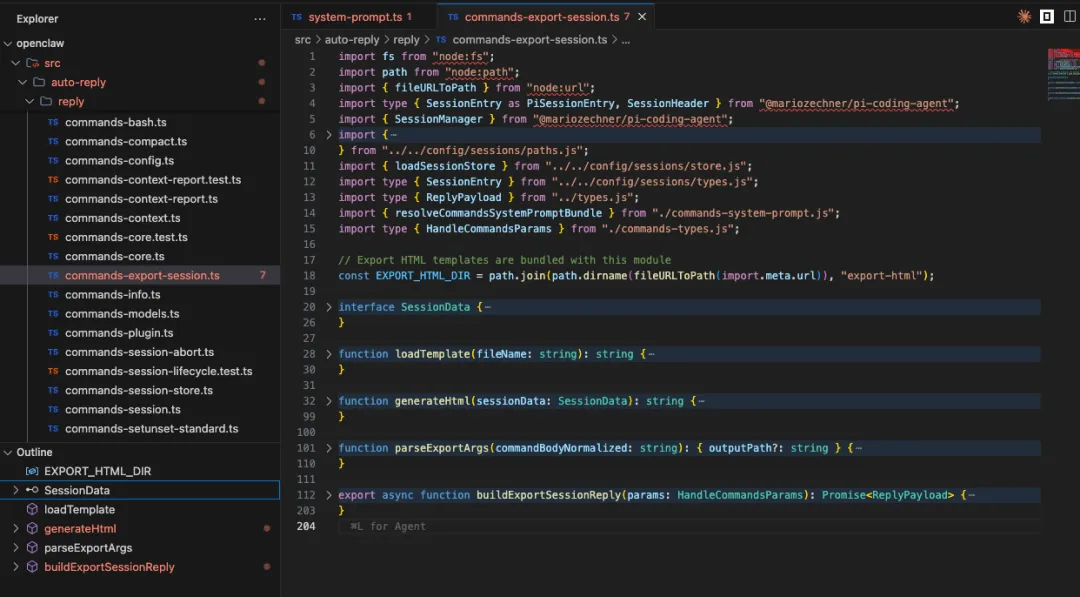
核心逻辑很简单:
核心流程控制 (buildExportSessionReply)该函数是导出命令的主入口,遵循以下步骤:
1. 解析参数:解析用户输入的路径,如果用户没提供路径,则默认在当前工作区生成一个带时间戳的文件。 2. 定位会话文件:从 SessionStore 中找到当前会话对应的本地 .jsonl 文件路径。 3. 加载数据: • 使用 SessionManager 加载所有对话条目 (entries)。 • 调用 resolveCommandsSystemPromptBundle 获取当前会话使用的系统提示词 (System Prompt) 和 工具定义 (Tools)。 4. 组装数据 (SessionData):将页头信息、对话记录、提示词和工具列表封装进一个对象。 5. 生成 HTML:调用 generateHtml 函数填充模板。 6. 写入文件:确保目标目录存在,并将生成的 HTML 写入磁盘。 7. 返回结果:向用户反馈导出成功的消息,包括文件路径和统计信息(条目数、提示词长度等)。
那么为什么会出现导出的 html,打开无效的情况呢?
问题就出在第 5 步,加载填充模板,默认返回模板的逻辑是:
return template .replace("{{CSS}}", css) .replace("{{JS}}", templateJs) .replace("{{SESSION_DATA}}", sessionDataBase64) .replace("{{MARKED_JS}}", markedJs) .replace("{{HIGHLIGHT_JS}}", hljsJs);也就是,html 模板中存在占位符:
{{MARKED_JS}}{{HIGHLIGHT_JS}}{{JS}}最终生成时,会被替换成真实的 JS,然后形成有一个完整可用的 html 文件。
2.2 导出的HTML无法使用的原因
之前截图也看到了,就是说模板中的 3 个 JS 未定义,或者说找不到。
根本原因就是,HTML 模板被自动格式化了
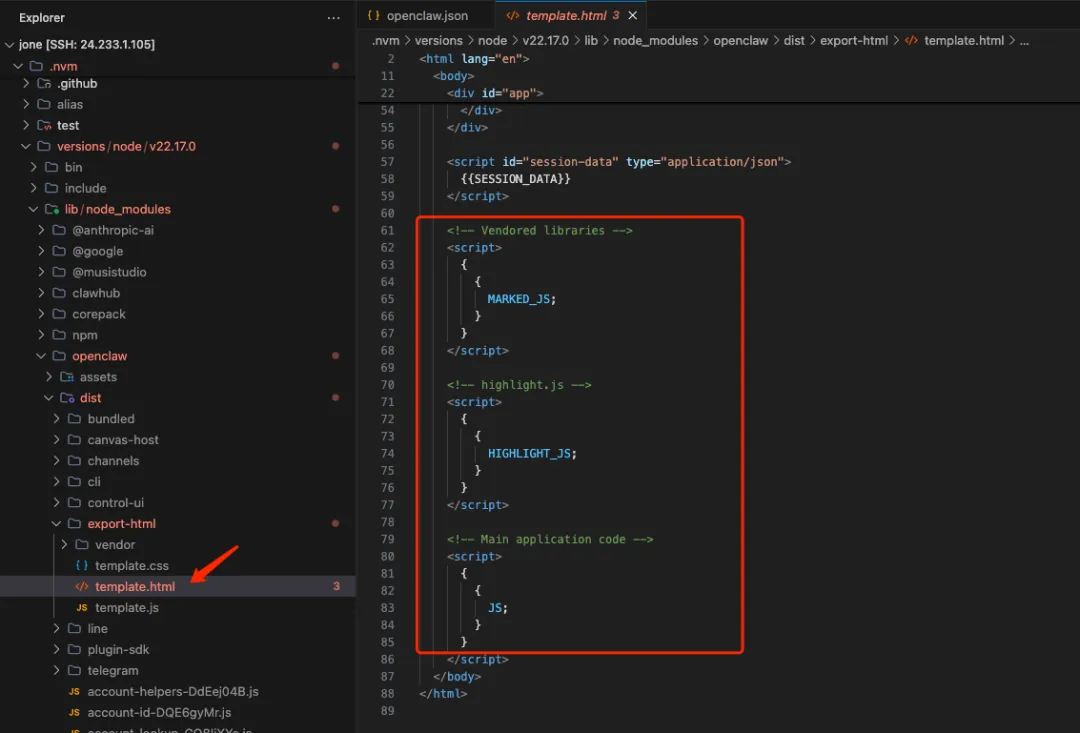
我们要做的就是把这段代码改成
<script>{{MARKED_JS}}</script><script>{{HIGHLIGHT_JS}}</script><script>{{JS}}</script>注意:不要在 IDE 中直接改,改完报存,还是会给你格式化,直接用文本编辑器或者vi 之类的修改,确保不要被格式化。
可以参考这个 issue: https://github.com/openclaw/openclaw/pull/24557/changes
如何找到这个模板文件,可以在 IDE 中全局搜索,或者直接定位,根据 OpenClaw 安装的方式:
直接 node 安装的话:/xxx/node_modules/openclaw/dist/export-html/template.html
nvm 安装的话:
~/.nvm/versions/node/<version>/lib/node_modules/openclaw/dist/export-html/template.html
我的就是 nvm 安装的,也可以看到图中我的文件的路径。
2.3 修复后效果
修改后,重新执行导出(如果不放心的话,可以重启下 gateway)
可以看到,页面正常显示了
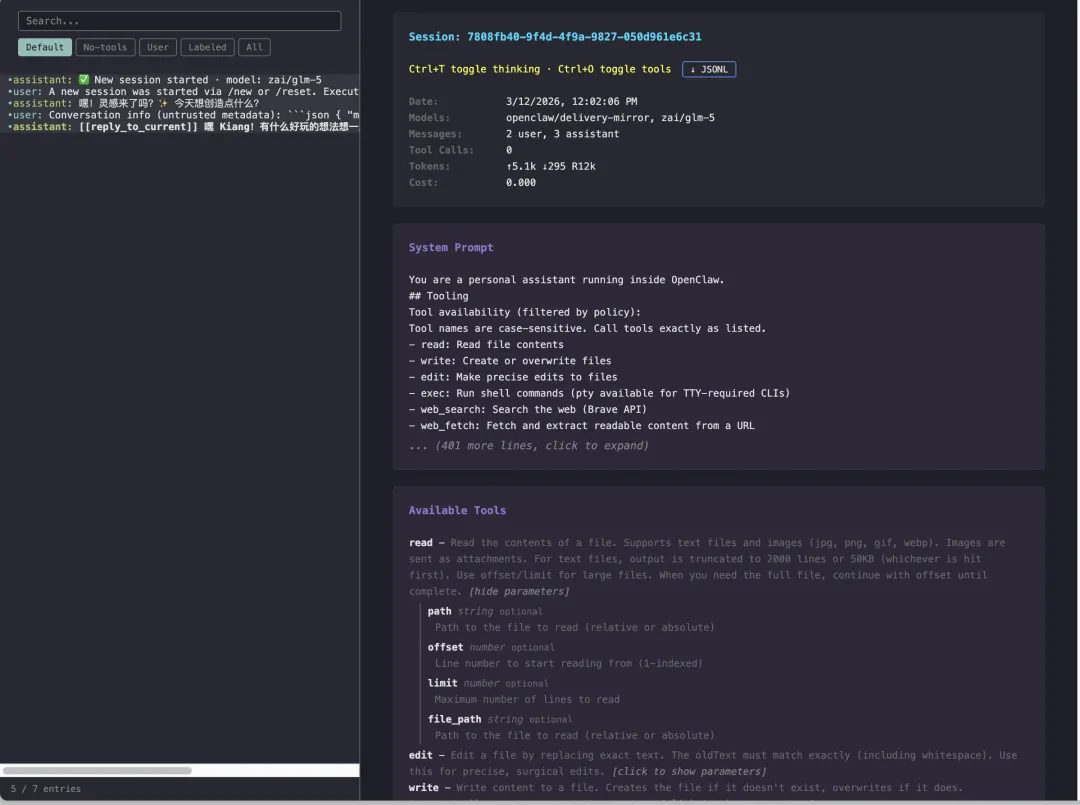
右侧可以看到,有一个 System Prompt 版块,每个人的每个 session 的结果应该都不一样。
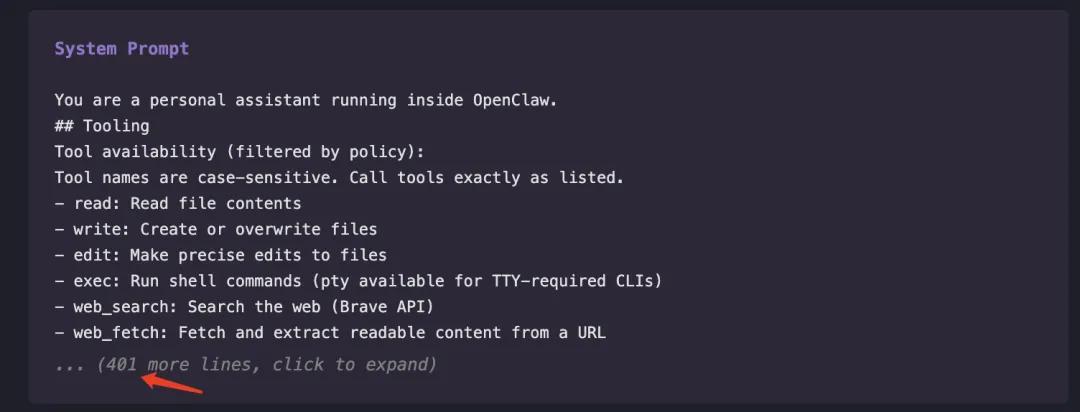
这是我新建 session,发了一句简单的 hi,背后加载的提示词
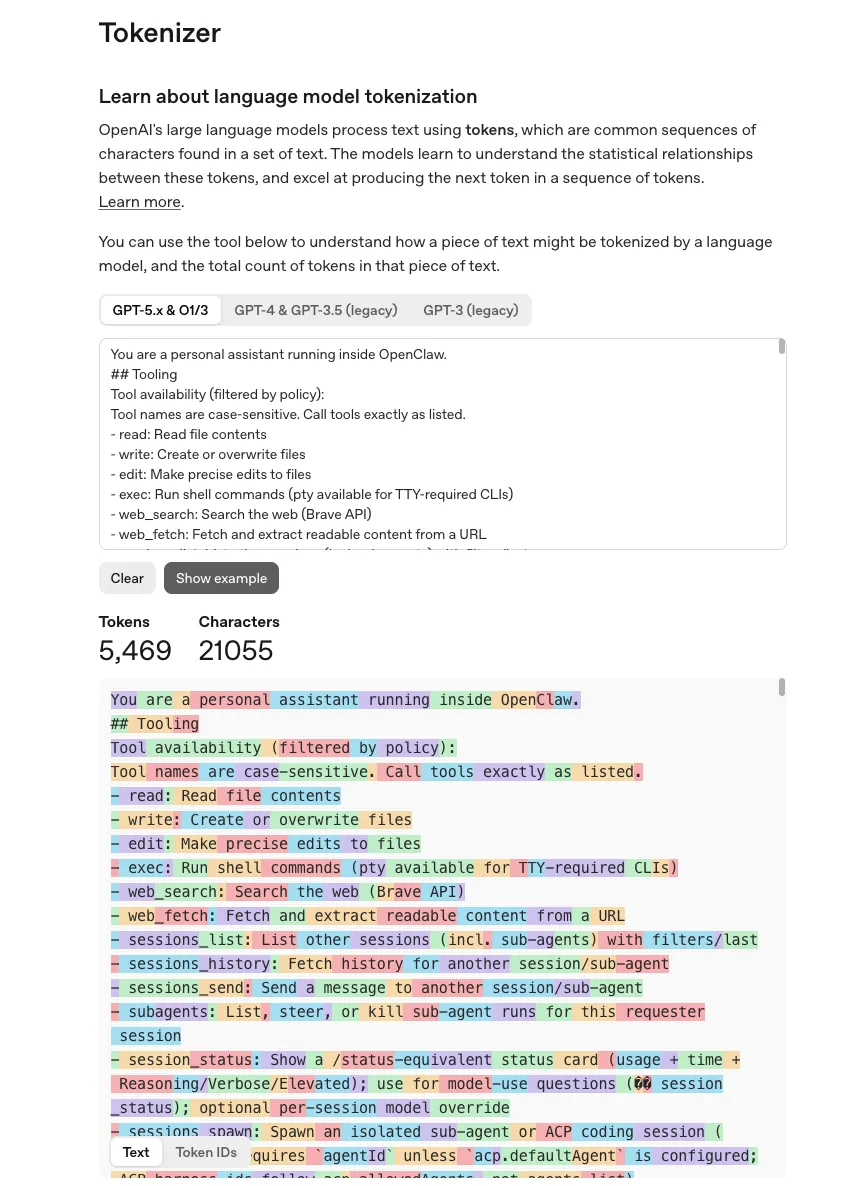
可以看到有整整 401 行,我用 OpenAI 的 Tokenizer(https://platform.openai.com/tokenizer) 算了下, 5469 个 Token,21055个字符,着实不少啊。
细节部分,你也可以自己动手实操一下。
最后
对于使用基于大模型的工具来说,抛去各种优化的手段,就是要做到花费大量 Token(真金白银)的准备,特别是越聪明的大脑,就要付出越多的开销,就看你怎么抉择。
我目前使用下来的最优性价比方案还是各个厂商的 Coding Plan,相对来说还是比较划算,当然财大气粗的可以官方订阅 Claude、OpenAI 等。中转的,本地的,免费的之类的我就 Pass 了。很多时候你的问题,可能就是一个模型的问题。
最后,有条件的可以直接上最优模型,退之,就选择各大厂商推出的 Coding Plan,哪个好用,哪个更优,没有答案,每个人的场景用法都不同,自己尝试了会找到符合自己的,别人的不一定适合你。
文章推荐:
[保姆级教程] 还没有安装OpenClaw?试试智谱最新发布的AutoClaw
写教程爽到飞起!10GB 免费空间 + 粘贴即传:我私藏的全自动 Markdown 写作流
OpenClaw 只是个 Demo,搭配 LobeHub 才是完整产品
最后的最后,如果你也在学习 OpenClaw 或者其他 Claw, 遇到了问题,欢迎在评论区交流,或者加我微信,我拉你入我们的免费龙虾交流群:
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~感谢你的阅读,我们下次见。
