 夜雨聆风
夜雨聆风
在 AI 智能体生态狂飙突进的当下,一场关于开源伦理与数据抓取的激烈交锋,将腾讯推向了全球开发者关注的风口浪尖。
近日,爆火的开源项目 OpenClaw(昵称“龙虾 AI”)创始人 Peter Steinberger 在社交平台 X 上公开发难,指责腾讯未经授权,暴力抓取其 ClawHub 平台的所有技能数据,用于构建自家的“SkillHub”平台。
这一指控不仅直指腾讯“照搬抄袭”,更带着对大厂傲慢态度的愤怒——Steinberger 抱怨道,腾讯在疯狂吸血的同时,甚至还有人员发邮件嫌弃他的服务器“访问速率限制”阻碍了抓取效率,这直接导致他的服务器成本飙升至五位数美元。
面对“只索取不贡献”的质疑,这位奥地利程序员的怒火,无疑代表了开源社区在面对商业巨头生态扩张时普遍存在的被剥夺感。
针对这起沸沸扬扬的“抄袭门”,腾讯 AI 团队并未选择沉默,而是迅速给出了一份充满技术细节的回应,试图用数据来重构事件的叙事逻辑。
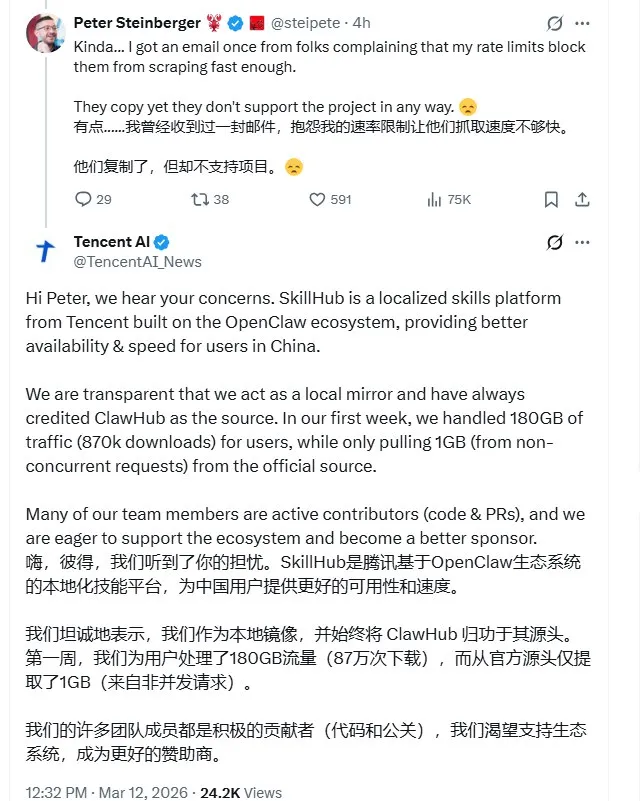
腾讯官方强调,SkillHub 并非恶意的抄袭品,而是为了解决中国用户访问延迟痛点而特意打造的“本地化镜像站”。
为了证明这一点,腾讯抛出了一组极具说服力的对比数据:SkillHub 上线首周,虽然向中国用户分发了高达 180GB 的数据流量(对应约 87 万次技能下载),但实际上仅从 OpenClaw 官方源站拉取了区区 1GB 的原始内容。
换言之,腾讯通过构建本地缓存与加速节点,客观上为原项目分担了 99.4% 的带宽压力,而非像对方指控的那样加重了负担。
同时,腾讯还打出了“情怀牌”,指出其团队成员一直是 OpenClaw 生态的代码与 PR(合并请求)活跃贡献者,并表达了未来愿意通过赞助形式深化合作的意愿,力求将这场对立转化为共赢。

这起争议的本质,其实是开源协议与商业伦理在 AI 时代的一次剧烈碰撞。从法理上看,OpenClaw 遵循的 MIT 协议允许商业使用与分发,只要保留版权声明即可,腾讯的行为在法律层面似乎并无瑕疵。
然而,在开源社区的“江湖规矩”里,尊重知情权与互惠互利才是合作的基石。Steinberger 的愤怒,更多源于一种“被蒙在鼓里”的不尊重感,而非单纯的利益受损。
这一事件也折射出腾讯在拥抱“龙虾热潮”时的急切心态——从马化腾朋友圈罕见力挺“养虾计划”,到推出 WorkBuddy、QClaw 等一系列“龙虾”生态产品,腾讯正试图以最快速度构建起覆盖云端、本地及企业的全场景智能体矩阵。
在这个过程中,如何平衡技术落地的效率与对原创者的尊重,如何让“拿来主义”变得更加体面与双赢,将是所有试图在开源沃土上掘金的大厂必须修好的一门必修课。


分享AI、科技新闻及相关见解,**仅供参考和娱乐**