 夜雨聆风
夜雨聆风
今年2月春节后,我开始做一件听起来有点疯的事——把家里一台巴掌大的N100小主机,结合openclaw的架构和家里的工作主机,变成一套能帮我投资、帮我产出内容、帮我理解 AI 的"个人 AI 基础设施"。三个礼拜后,这套系统真的跑起来了。
这篇文章不讲怎么装软件,讲的是两件事:为什么要这么想问题,以及这套架构究竟能用来做什么。
为什么你用 AI 总感觉差点意思?
很多人用过 千问、豆包或者 Kimi,感觉挺聪明,但总差那么一口气。原因其实很简单:它不那么充分认识你,没有那么多关于你的独家记忆。它不知道你在关注哪几只股票,不知道你上周读了什么,不知道你的判断风格,不知道你的业务背景。每次对话,它都是只能从历史对话抽取信息,对于它,你的行为数据还不够。更重要的是,它工具有限,它能聊,但往往不能帮你实时查深度行情、不能帮你跑策略回测、不能帮你监控信息流。
所以问题不是 AI 不够聪明,而是AI 没有一个能干活的环境。
我想解决的,就是这个问题:
第一层:先建地基,不是先装 OpenClaw
很多人看了网上很多fancy的视频,一上来就想用 OpenClaw,但忽略了最基础的问题:它要跑在哪里?
云服务当然可以,还算便宜但不可控。Mac Mini?太贵了,而且计算性能溢出。我选择的方案是:一台畅网N100 迷你主机,不算内存硬盘的话,大概一千多块钱,功耗不到 20W,24 小时在线。
这台小机器上跑了一个叫 PVE 的虚拟化系统,里面同时运行两个虚拟机:一是软路由(iStoreOS),负责管理全屋网络出口、科学上网和流量代理;另一个是 Ubuntu 服务器,负责 VPN 出口和远程访问(通过 Tailscale)。布置完以后,我家里只要连上wifi,就可以无感访问全球所有的网站和服务,同时在外面也可以随时随地通过互联网访问家里设备,并借由家里的路由科学上网。
为什么要花这么多精力在网络上?
因为这套系统里有大量服务需要稳定运行,有大量 API 需要稳定访问。网络不稳,上面建什么都会出问题。这个教训我在排查过n次各种原因导致的全屋网络崩溃之后,体会特别深——地基不稳,上面建什么都会塌。
第二层:给 OpenClaw 一个记忆
地基盖好了,下一个问题是:怎么让 OpenClaw认识你并且复用你的知识?我的方案是把过去几年积累的 Obsidian /Onenote笔记(超过 22000 条)接入一套叫 RAG 的系统。RAG 的原理说白了就是:把你的知识库变成可以被语义检索的向量数据库,OpenClaw 回答问题之前,先去里面找和这个问题相关的内容,再结合这些内容来回答。
这套自主开发的小系统我叫它Memory Brain,运行在家里的工作主机上,用的是专门针对中文优化的嵌入模型。同时,我还接入了 Google NotebookLM 作为开发时的上下文来源——写代码的时候,Claude和Antigravity可以直接检索我过去的笔记和技术方案,带着我的历史记录帮我开发,而不是每次从零开始。存储层面,我搭建了一个8TNAS负责数据备份兜底,同时有一个9T的冷备份盘,保证数据的安全性——没有记忆的 AI 是陌生人,有了知识库才是助手。
第三层:给 OpenClaw装上手和眼睛
光有大脑还不够,AI 还需要能看到外部世界。我给OpenClaaw配了 7 个"技能"(Skill),全部是自己写的,充分反映我自己对workflow的理解和要求,覆盖不同的能力域:
投资方向:
- Ari金融网关:连接美股、A 股、加密货币的实时行情,能做策略回测、AI 诊断、深度报告,还能追踪内部人交易、机构持仓、分析师预期
- Twi情报管道:监控我关注的 KOL 动态,追踪热点话题,还能查 Polymarket 预测市场的情绪
信息摄取方向:
- read-url:读任意网页(包括付费内容),AI 评分+我手动评分后归档到知识库(6分以上入RAG库)
- wechat-clip:微信公众号文章自动摘要评分,也是一样的入库机制
- gcp-search:基于 Vertex AI 的语义搜索,覆盖 arXiv、Bloomberg 等高质量来源
- inbox-push:手动触发的文章收件箱
内容产出方向:
- 话题助手:联网实时选题,驱动多个不同垂直方向的自媒体账号(前端是上篇文章给大家看的自动化内容管理平台),现在已经长这样了:
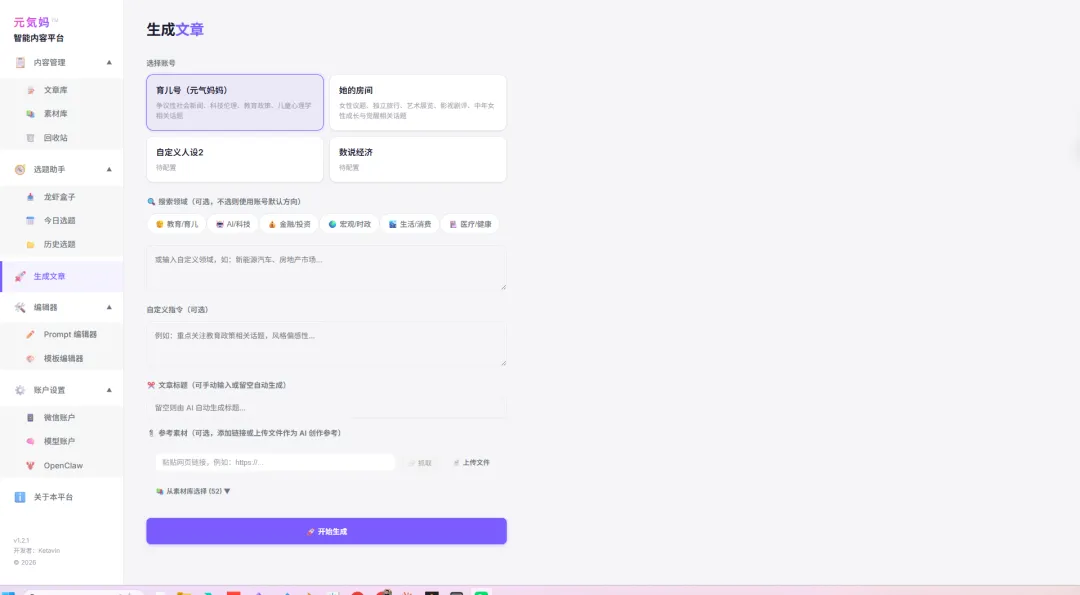
这些工具连起来,OpenClaw就不只是一个聊天对象,而是一个能查数据、能追信息、能产出内容的工作系统——你给 AI 接了什么,它就能干什么。
第四层:用 AI 来构建 AI
这套系统是怎么开发出来的?
这里有一个有意思的闭环——我用 AI 工具来构建这套 AI 系统。开发工具链是:Antigravity IDE(一个 VS Code 的变体)+ Gemini + Claude Code + NotebookLM MCP。Claude Code 通过 SSH 直接操作服务器,Gemini 负责日常的代码生成和问题排查,NotebookLM 把我的笔记实时注入开发上下文。我不需要记住每个配置细节,AI 帮我记着。
这个过程让我意识到:普通人和"会开发"之间的距离,正在被 AI 快速压缩——你不需要是程序员,但你需要会描述需求、会判断结果、会迭代。
第五层:让系统自己运转起来
所有这些能力,最终汇聚到一个叫 Keta 的 OpenClaw Agent 上。Keta 运行在N100的小机器上,主模型是 Gemini Flash Lite(几乎零成本),备用链是 Gemini Pro → Qwen3,模型会根据任务复杂度自动切换。它通过 Telegram 和飞书两个频道接受指令,调用上面所有的技能和工具。还有一个子 Agent 叫 kidlearn,专门负责儿童教育方向,绑定独立的 Telegram 频道——从"我在用工具"到"系统在为我工作",这是质的变化。
这套系统,其实在复现大厂的工程原理
做完这一切,我回过头来看,发现一件有意思的事:我这套家庭 AI 系统,和大型 AI 应用的工程架构,原理上是同一件事:
还有就是对成本的思考,这关系到Context Engineering——这是目前 AI 工程最前沿的概念之一,核心思想是:上下文窗口是稀缺资源,怎么用好每一个 token,决定了系统的成本和质量上限。
我在 OpenClaw 里做了一个 Content Router:根据任务类型自动切换模型,把 Prompt 结构化以利用 KV Cache,按需压缩上下文,只在必要时调用 RAG——而不是把所有内容都塞进去。这些优化,和大厂工程师在做的事,其实是同一个道理,但你不需要一个团队,也不需要百万预算。同样的架构原理,一个人、一台 N100加一台台式机、两三个礼拜,可以跑通。
这套架构能用来做什么
这是这篇文章最想回答的问题。搭架构不是目的,用起来才是。openclaw 这套体系,本质上是一个可以不断挂载新能力的平台。基础设施搭好之后,真正有价值的事情是:想清楚你要解决什么问题,然后把对应的能力接进来。
以我自己为例,这套系统目前在做三件实际的事:
投资决策辅助:Arist 金融网关提供实时行情和回测,twitter-intel 追踪市场情绪和 KOL 动态,Polymarket 提供预测市场的概率参考。AI 帮我看得更快、更全,但最终拍板还是我自己。这是辅助判断,不是替代判断。
内容产出自动化:选题、摘要、信息归档都已经自动化。多个不同方向的不同平台账号共享同一套基础设施,但各自输出差异化内容。一个人也能运转多个内容出口。
持续认知积累:wechat-clip、read-url、gcp-search 构成一套信息过滤漏斗,高质量内容自动进入知识库。我的 Obsidian 每天在被动生长,下次需要检索某个领域的判断或资料时,Memory Brain 已经帮我整理好了。
正在做的两件新事
系统跑通之后,更有意思的问题出现了:这套架构还能解锁什么?我在做如下两个工作:
历史工作文档 RAG + 思维链提取
我把过去多年积累的 8000 多份工作文档导入了 Memory Brain。但光能检索还不够——我更想做的是把这些文档里隐含的决策逻辑和分析框架提取出来,形成结构化的 Chain-of-Thought。这不只是把文件变成可搜索的数据库,而是在尝试把过去的工作经验,转化成 AI 可以调用的推理资产。当 Keta 面对一个投研问题时,它不只是搜索相关内容,而是能够复现我过去处理类似问题时的思路路径。
AI 深度背景尽调系统
这是一个更有野心的复现实验。过去,对一个人做完整的背景调查,需要专业调查员花大量时间,成本高、周期长。但有了 LLM 和 Agent 架构,这件事的门槛正在被大幅压缩——研究表明,单次完整的去匿名化分析,成本可以低至几美元,运行时间仅需几分钟。
我正在复现的这套系统,采用四智能体流水线架构:
- 提取 Agent:从非结构化文本中提取人物的微观特征,输出结构化 JSON 画像
- 搜索 Agent:将画像向量化后在候选库中检索,同时调用网络搜索补全信息盲区
- 推理验证 Agent:扮演"调查法官",对候选人进行逐条比对,寻找时间线、语言习惯、经历上的交叉验证点
- 校准输出 Agent:对匹配结果打置信度评分,附带完整证据链
这套系统目前已经产出了初步报告,后续会通过 MCP 接入 OpenClaw,成为 Keta 可调用的一个 Skill——你对着它说一个名字或者描述,它自动完成全流程的背景调查。
这两件事放在一起,说明了一个更大的逻辑:OpenClaw不是一个固定的产品,而是一个能力平台。你想解决什么问题,就往里面接什么能力。架构搭好之后,边际成本越来越低。
最后,普通人的起点在哪里?
不需要一步到位。
如果只能做一件事,从知识库开始:把你的笔记、收藏、文章,整理进 Obsidian,开始积累可以被语义检索的个人知识图谱。这一步不需要任何技术背景,但会是你未来所有 AI 应用的地基。
想清楚你要解决什么问题,再决定往上加什么层。投资、内容、研究、尽调——架构是一样的,应用场景由你决定。
AI 不是魔法,是基础设施。你搭得越扎实,它帮你干的活就越多。
希望大家都能拥有自己定制的OpenClaw,让自己的能力边界越来越宽广,让自己的成长曲线如同蒸馏模型的迭代一样陡峭。
