夜雨聆风
夜雨聆风
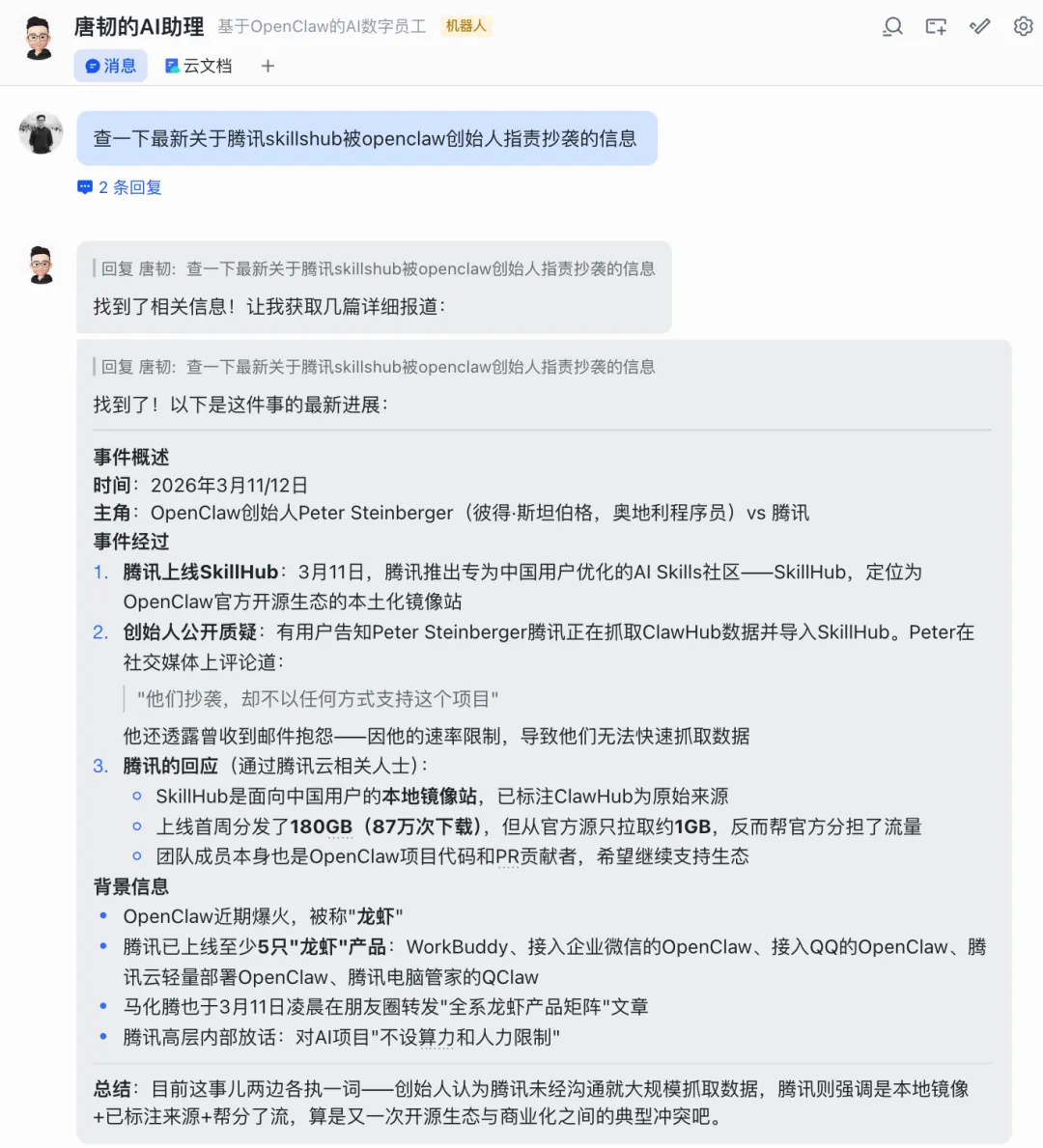
腾讯说 SkillHub 是基于 OpenClaw 生态系统构建的面向中国用户的本地镜像站,且标注了 ClawHub 为原始来源。
同时,腾讯上线 SkillHub 后第一周,就给用户分发了 180GB(87 万次下载),但从官方源只拉取约 1GB 数据。
另外,SkillHub 的团队成员本身也是项目代码和 PR 贡献者,希望继续支持生态并成为更好的赞助商。
在我看来,腾讯话里总共说了三个意思。
第一,SkillHub 不是抄袭,而是一个标注来源的镜像站。
第二,SkillHub 帮 ClawHub 分担了流量压力,扩充了中国市场,且对官方造成的服务器压力很小。
第三,腾讯愿意支持 ClawHub 的发展并提供赞助。
不得不说,小鹅子还是有两下子,这话说得哪哪都没毛病。
估计有读者不懂什么是镜像站,这里我再通俗易懂解释一下,也算是做些技术科普。
所谓镜像站,实际就是把国外网站的一些资源拉到国内并提供同类型服务,避免服务器在海外导致无法访问或者访问慢的问题。
SkillHub 承认了资源来源于 ClawHub,所以他们就是通过镜像的方式做了国内站,但数据源并不是自己的。
因为 ClawHub 上都是一些开源 Skills,所以也不构成侵权。但怎么说呢,这么做肯定让开源项目的作者觉得不爽。
我举一个不怎么恰当的例子,或许你们就明白了。
比如,我写了一篇文章发到网上,这篇文章很受欢迎、数据也很好。
此时,有人直接复制这篇文章发到他自己的内容渠道,虽然用小字标记出处是我,但实际上也是在用我的内容去给他自己带数据。
假设这个复制我文章的作者被我发现了,然后他跟我说是为了帮我分担流量,那我一定会觉得怪怪的。
例子不同,但道理是类似的。
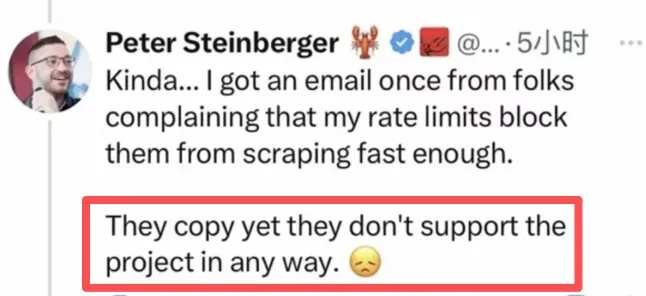
OpenClaw 创始人之所以觉得不爽,就是因为腾讯在没打招呼的情况下直接复制了自己的文章。
只能说,开源的世界里有太多的人心叵测。
瓜就吃到这了,接下来说点有用的。
既然提到了 Skills,我觉得还是有必要给你们推荐几个在 OpenClaw 上必装的 Skills 了,尤其是最后一个。
第一个,Tavily Search。
不管你用什么方式安装了 OpenClaw,它默认的搜索功能其实是不好用的,要么搜不到,要么无法搜索网上最新信息。
比如上面那个瓜,如果我用没装 Tavily 的 OpenClaw 去找相关信息,它的回复是这样的。

如果我让装了 Tavily 的 OpenClaw 去找,它就能获取最新信息。
Tavily Search 就是一个能联网检索最新信息的技能,不过你需要先去 Tavily 官网注册一个 API Key,是免费的。
在 OpenClaw 里安装也很简单,直接跟你的 Agent 说:「帮我安装一下这个skill:https://clawhub.ai/Jacky1n7/openclaw-tavily-search」。
安装完成后,它会问你要 API Key,把你之前在 Tavily 注册的 Key 发给它就行。
使用也很简单,之后你可以直接跟 OpenClaw 对话,让它帮你用 Tavily 搜索最新信息,或者直接说搜索xxx最新信息,还可以固化到你的记忆文件里。
第二个,self-improving-agent。
这是一个可以让你的 OpenClaw 越来越聪明的 skills,安装方式和上面一样,直接跟你的 OpenClaw 说:「帮我安装这个skill:https://clawhub.ai/pskoett/self-improving-agent」。
你们如果经常用 OpenClaw 会发现,有些时候它会犯一些错误,或者没按你的要求执行,或者执行结果没达到你的要求。
此时,你可以纠正他,并且告诉他什么是对的,而 self-improving-agent 就可以帮你自动完成 Agent 的自我学习和迭代。
第三个,Skill Vetter。


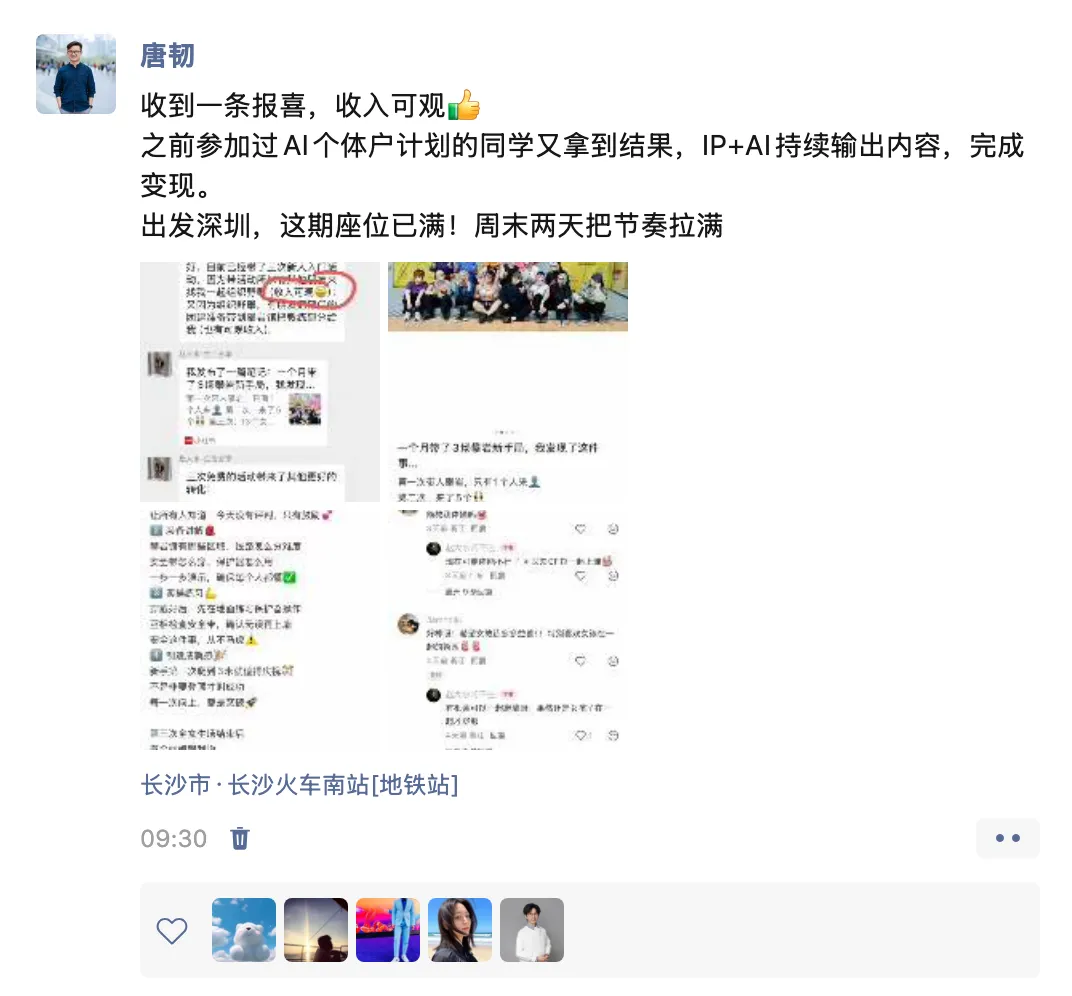
今天出发深圳了,这周末两天在深圳举办最新一期 AI 个体户训练营。
这两天时间里,我会教大家怎么通过 AI + IP 的方式来做人设定位、内容创作、商业化产品设计、变现路径设计。
这里面的核心,就是我那套被验证过的方法,因为我已经在不同领域做起来两个自己的独立 IP 了,之前参加过的同学也陆续起号。
这次还加上了 OpenClaw 的最新实践,生产力又是原地起飞。
就今天早上,还收到了之前参加过的一位同学在群里报喜。
深圳这一期座位全满了,下一站是北京,之后是上海,可提前联系我占座。