夜雨聆风
夜雨聆风
1. 智能体的"静止"问题
2. 重新定义"下一状态"
评价性信号:通过"下一状态"隐性地为前一个动作打分。用户的重复提问暗示不满,测试通过代表成功,错误日志标示失败。这些信号被提取为标量奖励。 指示性信号:包含更高级的纠正方向。例如用户说"你应该先检查文件再编辑",这不仅是差评,更指出了 Token 级的改进逻辑。
3. 从标量到 Token:事后引导的在线策略蒸馏
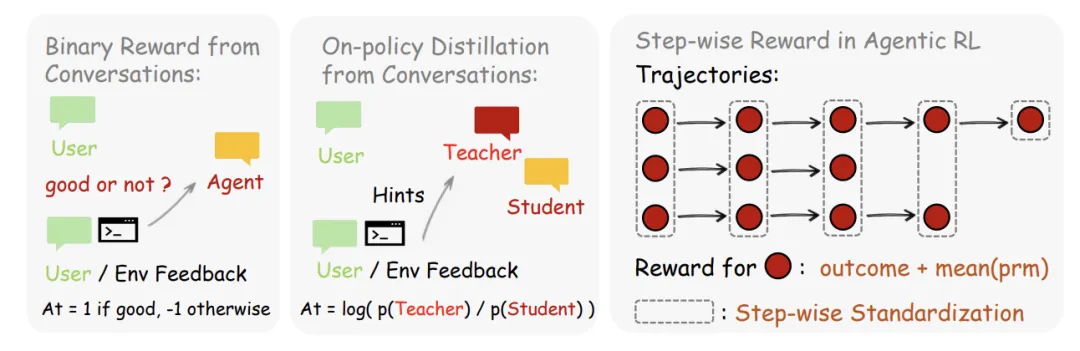
暗示提取:利用 PRM Judge 对下一状态信号进行 m 次独立查询并采取Majority Vote(多数投票制),提炼出简洁的文本暗示(如"需先检查权限")。 教师环境构建:将暗示附加到原始 prompt 中,构建增强上下文。 Token 级优势计算:模型在已知"标准答案暗示"的情况下,计算其输出分布与原学生分布之间的对数概率差。 非对称剪裁损失优化:采用带非对称边界的 PPO 风格剪裁损失,在确保策略平滑更新的同时,赋予 AI 改错的能力。
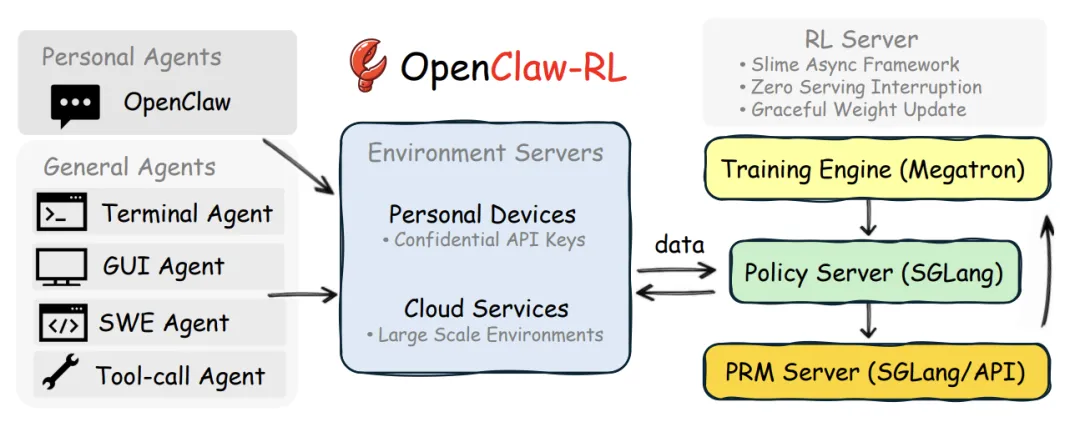
4. "零中断"进化:基于 Slime 的异步四循环架构
策略推理:高效响应用户请求。 环境模拟:支持 128 个以上的并行环境(针对终端代理),实时收集交互流。 PRM 判别:利用多数投票制对交互结果进行多维度评估。 策略训练:在后台异步更新权重。

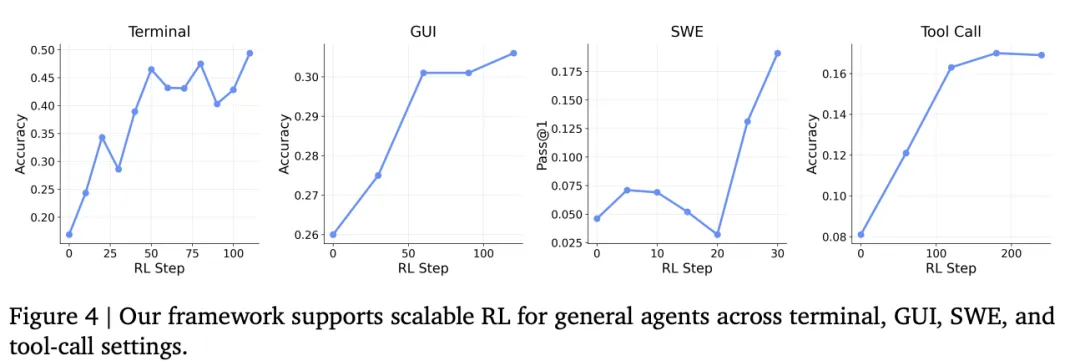
5. 全场景覆盖:从个性化到大规模工业应用

个性化:在学生完成家庭作业场景下,OpenClaw-RL 仅需 8 步更新,个性化评分就从0.17 (Base Model) 升至 0.76。 长程任务:在复杂的 Tool-call 设置中,结合过程奖励和结果奖励的综合优化,将准确率从0.17 提升至 0.30。 规模化:系统在云端部署了128 个并行环境。