 夜雨聆风
夜雨聆风想象一下,你的AI助手能够从每次对话中学习,从每个错误中成长,甚至在你纠正它的时候自动优化自己。这不再是科幻,而是普林斯顿大学等机构联合推出的OpenClaw-RL框架所实现的现实。
论文名称:OpenClaw-RL: Train Any Agent Simply by Talking论文链接:https://www.arxiv.org/abs/2603.10165AI训练的"圣杯"问题
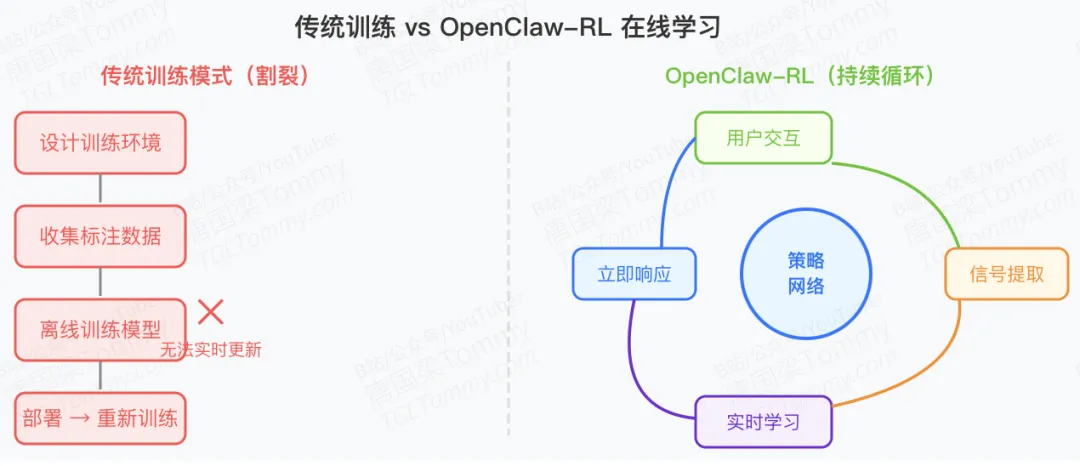
传统的AI智能体训练面临一个根本性困境:训练和使用是割裂的。开发者们需要:
精心设计训练环境 收集大量标注数据 离线进行模型训练 部署后发现问题再重新训练
这就像培养一个孩子,只让他在课堂上学习,却永远不让他从真实生活的反馈中成长。更糟糕的是,不同场景的智能体——聊天机器人、代码助手、GUI操作员——往往需要完全不同的训练流程和基础设施。
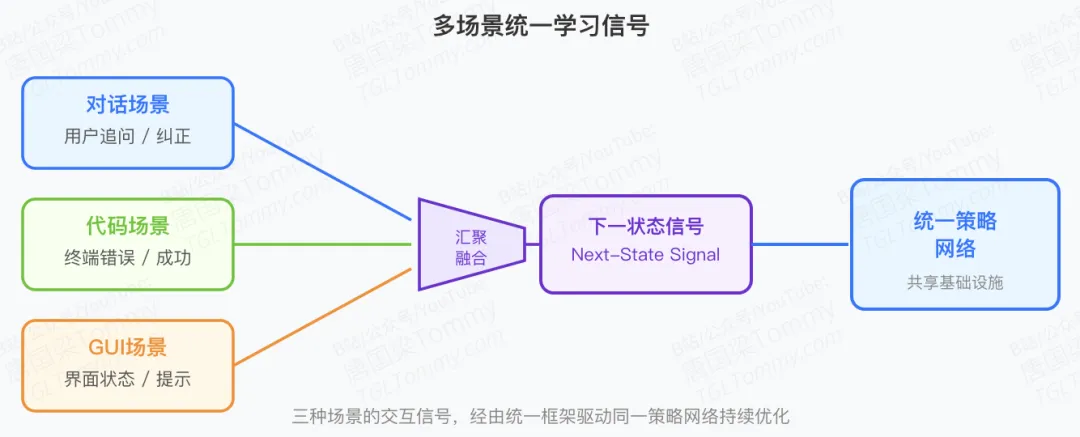
OpenClaw-RL的突破在于一个简洁而深刻的洞察:所有的交互都会产生"下一状态信号"(next-state signal),无论是用户的回复、工具的输出、终端的反馈,还是图形界面的状态变化。这些信号本质上是统一的,完全可以用来训练同一个策略模型。
什么是"下一状态信号"?
让我们用几个实际例子来理解这个核心概念。
场景一:日常对话
你问AI:"明天北京天气怎么样?" AI回答:"明天会下雨,气温15-22度。" 你追问:"那我需要带伞吗?" 👉 这个追问就是下一状态信号——它暗示AI的第一次回答不够完整
场景二:代码执行
AI生成了一段Python代码 终端返回:"NameError: name 'pandas' is not defined" 👉 这个错误信息就是下一状态信号——它明确指出代码哪里有问题
场景三:图形界面操作
AI尝试点击"提交"按钮 界面弹出:"请先填写必填字段" 👉 这个提示就是下一状态信号——它说明操作顺序不对
OpenClaw-RL的天才之处在于:无论是对话、代码、还是GUI操作,这些看似完全不同的场景,本质上都在提供相同类型的学习信号。框架可以同时从所有这些交互中学习,用同一套基础设施训练同一个策略网络。
双信号学习机制:评估+指导
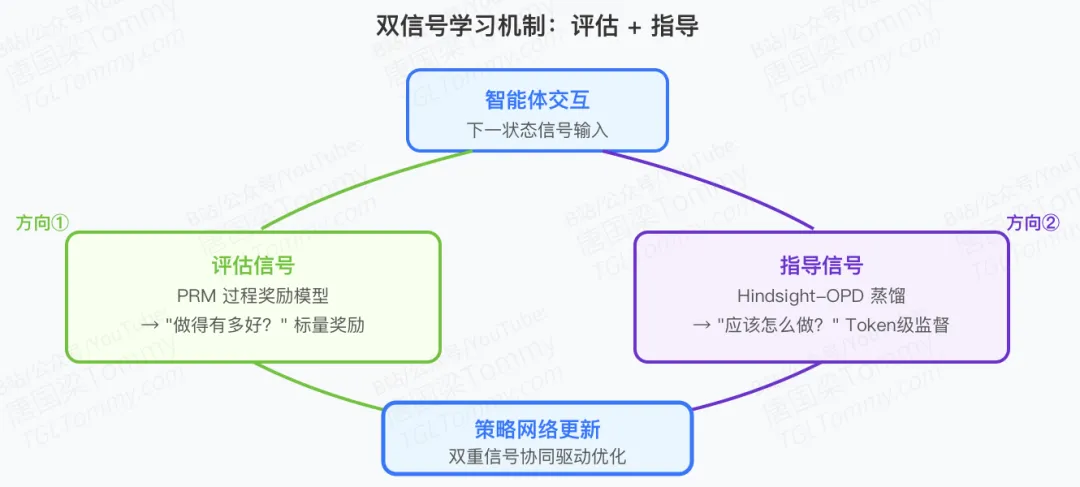
OpenClaw-RL将"下一状态信号"解构为两种互补的学习源:
评估信号(Evaluative Signals)
这回答了"做得有多好"的问题。
系统通过PRM(Process Reward Model)评判器,将复杂的交互结果转化为清晰的数值奖励:
用户说"完美,谢谢!" → 高奖励 终端成功执行 → 正奖励 程序报错 → 负奖励 用户重新提问 → 中性或轻微负奖励
这种标量化的评估为强化学习提供了优化方向。
指导信号(Directive Signals)
这回答了"应该怎么做"的问题。
仅仅知道"做错了"是不够的,更重要的是知道"怎么做才对"。OpenClaw-RL通过一项名为Hindsight-Guided On-Policy Distillation (OPD) 的创新技术,从下一状态中提取文本提示,构建增强的教师上下文,并提供token级别的方向性优势监督。
举个例子:
原始情况:AI说"明天会下雨",用户问"那要带伞吗?" Hindsight提示:从用户追问中提取出"答案应该包含实用建议" 增强学习:不仅知道回答不够好(评估),还知道应该主动提供建议(指导)
这种token级别的监督比任何标量奖励都要丰富,因为它直接告诉模型哪些词、哪些表达方式更好。
革命性的异步架构
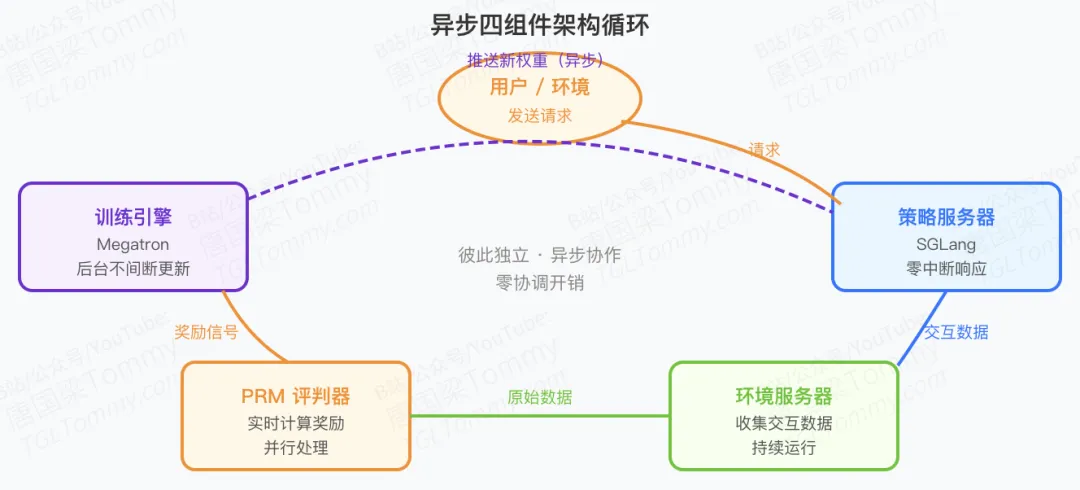
传统RL系统有个致命缺陷:训练时无法服务,服务时无法训练。就像餐厅必须停业才能培训厨师一样荒谬。
OpenClaw-RL基于Slime异步框架,实现了四个组件的完全解耦:
环境服务器 - 持续收集交互数据 PRM评判器 - 实时计算奖励信号 Megatron训练引擎 - 不间断更新策略 SGLang策略服务器 - 零中断响应请求
这四个组件彼此独立运行,通过异步通信协作:
用户请求 → 策略服务器(立即响应) ↓ 交互数据流向RL服务器 ↓ PRM评判器并行计算奖励 ↓ 训练引擎后台更新模型 ↓ 优雅地推送新权重到服务器零协调开销意味着:
用户感受不到任何训练带来的延迟
模型可以实时从每次交互中学习
系统可以无缝扩展到数千个并行环境
两种部署模式的统一
OpenClaw-RL支持两类完全不同的应用场景,却使用同一套基础设施:
个人智能体
部署在用户个人设备上,处理隐私敏感的对话任务:
通过HTTP连接到RL服务器,使用机密API密钥
从用户的重新提问、纠正、明确反馈中学习
"通过使用来改进" - 你用得越多,它就越懂你
这开启了一个激动人心的可能性:每个用户都在帮助训练自己的专属AI助手,而系统从海量个性化交互中提取共性,持续优化通用策略。
通用智能体
部署在云服务上,支持大规模并行化:
Terminal Agent - 命令行操作专家
GUI Agent - 图形界面自动化
SWE Agent - 软件工程任务处理
Tool-call Agent - API和工具调用
所有这些不同类型的智能体共享同一个策略网络,在统一的RL循环中共同进化。一个智能体在终端操作中学到的"谨慎性",可能帮助另一个智能体改进GUI交互的安全性。
技术价值与未来想象
OpenClaw-RL的意义远超一个技术框架:
研究层面
证明了跨场景统一RL的可行性
展示了过程奖励(process rewards)在实际应用中的效用
为在线学习提供了工程级解决方案
应用层面
大幅降低智能体训练和维护成本
让AI系统能够自主适应用户需求变化
为个性化AI助手提供了可行路径
想象空间
未来的AI助手不需要"版本更新",而是持续进化
每个用户的使用都在为整个社区贡献训练数据
AI系统可以快速适应新工具、新环境、新任务
结语
OpenClaw-RL最打动人心的地方,或许不是复杂的技术细节,而是它对AI学习本质的回归:学习应该发生在真实交互中,而不是实验室里。
就像人类通过生活经验成长一样,AI智能体也应该从每一次对话、每一个错误、每一次纠正中学习。OpenClaw-RL让这个愿景成为现实——你的每一次使用,都在让AI变得更好。
这个框架已经在GitHub开源:
https://github.com/Gen-Verse/OpenClaw-RL
邀请全球开发者共同探索智能体训练的新范式。
也许不久的将来,我们不再需要"训练"AI,我们只需要"使用"它。
进阶学习
👉如果你希望系统掌握大模型核心技术、以及Agent应用开发,推荐你学习我最新上线的精品课程:
📚这是一套从模型微调、部署,到强化学习训练的系统学习路线,课程以企业级落地为目标,你将掌握LLM核心原理、Agentic RAG、MoE/MLA/MTP机制拆解、PPO/GRPO强化学习与工业级DeepSeek-OCR多模态实战等,想系统掌握并落地这些能力,就从这门课开始。
💡本课程已在我的个人官网以及B站课堂上线,点击链接了解课程详情:
📺B站课堂(点击左下角“阅读原文”直接跳转)https://www.bilibili.com/cheese/play/ss556613313
🌐官网链接(国内访问需科学上网):https://www.tgltommy.com/p/deepseek

