 夜雨聆风
夜雨聆风系列:一个写了 7 年 Java 的工程师,转型 AI Agent 的真实记录 · 第②③期合集
(中登和陪伴型咪子)
Karpathy 开源了什么
https://github.com/karpathy/autoresearch
项目叫 autoresearch, 截至今晚已经37,900 star。GitHub 上能有几百 star 就烧高香的年代,这个数字意味着整个 AI 工程师社区的集体共鸣——不是爆火,是他们看完之后觉得"这个我也能做"。
理解这个项目,要先理解它解决的是什么具体问题。
ML 研究者每天面对的瓶颈
做语言模型研究,真正的工作流是这样的:
改超参/架构 → 跑训练(可能要几小时)→ 看结果 → 再改 → 再跑…按这个节奏,一个研究员每天能跑 3~5 个实验,已经算快了。实验空间那么大,大部分时间都浪费在等待上。
autoresearch 的回答是:一晚上跑 100 个实验,你睡觉,Agent 替你跑。
三个文件,一个约束,整套系统
项目只有 630 行 Python,整个项目放进 LLM 的 context window 完全没问题。核心就三个文件,分工明确:
program.md | ||
train.py | ||
prepare.py |
关键约束只有一个:每次实验固定跑 5 分钟。不管改了什么,不管 GPU 多贵,5 分钟到了就停,用同一个指标评估结果。
评估指标是 val_bpb(验证集 bits-per-byte),越低越好,而且不受词表大小影响——这样不同架构的实验结果才能公平比较。
每 5 分钟一轮的自动循环
① 读取 program.md(人类写的研究方向)② Agent 提出对 train.py 的修改③ 用修改后的 train.py 跑训练,精确 5 分钟④ 比较 val_bpb:变小了 → git commit 保留;变大了 → git revert 回滚⑤ 回到 ①,继续下一轮一小时约 12 轮,一晚上约 100 轮。这个设计最妙的地方在于:约束不是限制,而是让自动化成为可能的前提。固定时间预算 → 结果可比;单一指标 → 决策无歧义;只改 train.py → Agent 搞不出幺蛾子。每一个约束都是精心设计的。
它真的跑出结果了
Karpathy 在 GitHub Discussions 公开了一次 H100 上的完整 session 记录:89 个实验,val_bpb 从 0.9979 降到 0.9773。
其中最大的单次提升,是 Agent 把 batch size 从 524K 减半到 262K:
Agent 发现:在 5 分钟固定预算内,更小的 batch size → 更多梯度更新步数 → 更好的结果。这是个反直觉的结论,但在这个约束下完全正确。
还有一些有意思的发现:depth 9 + width 512 的架构优于更宽的网络;context window 缩到 1/8 反而更有效;RoPE base 从 10K 调到 200K 有收益。当然,也有彻底失败的尝试——加 label smoothing 直接让 val_bpb 爆涨 0.34,Agent 立刻回滚。
后来还有人在 Hyperspace 网络上跑了分布式版本:35 个 Agent,一晚上 333 个实验。
真正的革命性在这里:瓶颈不再是"执行能力",而是你怎么定义问题——program.md 里写什么,约束边界在哪,指标是否合理。这是个思维方式的转变。
当然了, 对于创新,还是做不到的。
一个念头,成了我的下一个项目
我把这个项目 clone 下来,交给 Claude Code 逐行解读之后,脑子里冒出一个想法:
我现在不就是在做调研吗?
每天我需要:搜索 AI 最新进展 → 阅读技术文章 → 判断哪些值得深入 → 总结成可以用的知识。这不就是一个调研 pipeline吗?如果 autoresearch 能让 Agent 自主迭代代码,那我能不能让多个 Agent 协作,帮我做技术调研、打分、汇总、生成报告?
于是我开始"创造性地抄作业"。选了 OpenClaw——工程导向,最近最火的 ai 产品

Pipeline 设计:三层 Agent 架构
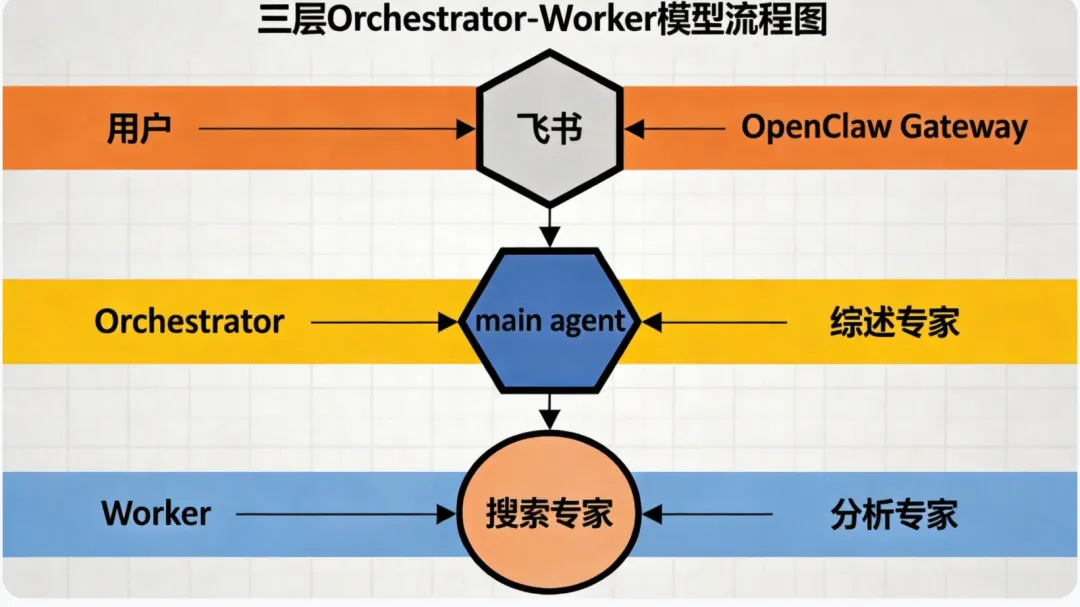
整套系统不是简单的"几个 Agent 并排跑",而是三层层级结构,每一层职责明确:
飞书消息 → OpenClaw Gateway ↓ main agent(depth-0,全能助手) 识别调研请求 → sessions_spawn → 综述主管 ↓ 综述主管(depth-1,调研编排者) ├── Phase 1: sessions_spawn → 搜索专家 │ └── GitHub API / Tavily / Hacker News / Papers with Code │ → candidates.csv(含工程导向评分 1-5) ├── Phase 2: 筛选 score≥4 → sessions_spawn → 分析专家 │ └── 逐条 web_fetch 精读 │ → notes/[id].md(每条数据强制附来源 URL) │ → matrix.csv(对比评分表) ├── Phase 3: 覆盖度检查 → 不足 → 回 Phase 1 补搜 ├── Phase 4: 读 review-writer/SKILL.md → 写 review.md ├── Phase 5: 读 research-vault/SKILL.md → 持久化到 Obsidian └── Phase 6: 汇报结果给用户 ↓ 用户收到飞书回复 + TL;DR两个设计决策,解释了整个架构
为什么是三层,而不是 main 直接派 搜索专家 和 分析专家?
职责分离。main 是全能助手,不该变成调研专家。综述主管 是调研的唯一入口,它知道:搜完要做覆盖度检查、精读要筛选 score≥4 的内容、报告要按模板写、最后要持久化——这些逻辑全装在 调研编排者 的 AGENTS.md 里。如果让 main 直接管这一切,main 的上下文会变成几百行操作手册,改一处牵连全局。
SKILL.md 是什么,为什么 worker 要"先读"它?
搜索专家 和 分析专家 启动时,task 参数里只写一句"先读 /clawd/skills/paper-scout/SKILL.md",真正的操作手册(搜哪些源、每个 API 的格式、candidates.csv 的字段定义)全在那个文件里。这不是偷懒,是刻意设计的:
task 参数 = 这次具体做什么;SKILL.md = 怎么做的通用规范。改一次 SKILL.md,所有后续调用立即生效,不需要修改任何 sessions_spawn 调用。
还有一个细节:评分是工程导向的(1-5 分),"能不能用"的权重远高于引用数。一个有 GitHub 代码、可以直接跑的项目,得分会高于一篇引用量很高但无法落地的论文。这是 Java 工程师视角带来的自然选择。
结果展示一下:
比如我想要调研一个 skills 系统,如何建立,我先表达了我对 skills 的理解,并让他调研如果使用 java 去做,可以怎么去做;

设置了 15 分钟的超时时间,我让他 15 分钟必须给我出报告,否则 token 容易给我家底烧没了,生成相关调研报告,并提取到我的 obsidian 里


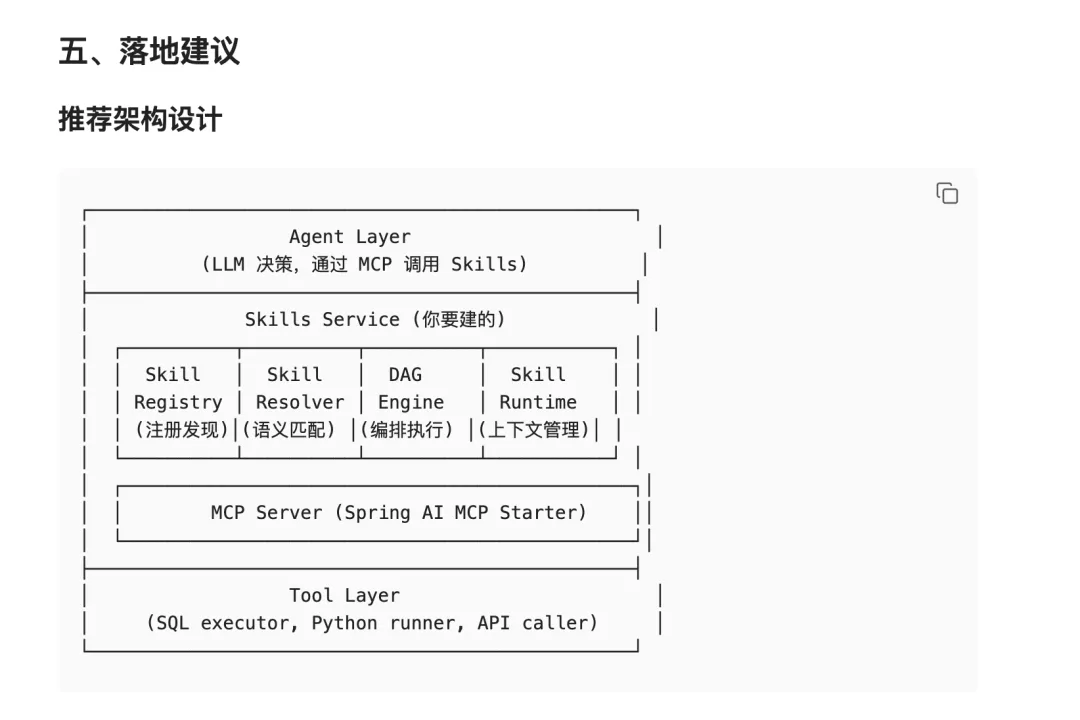

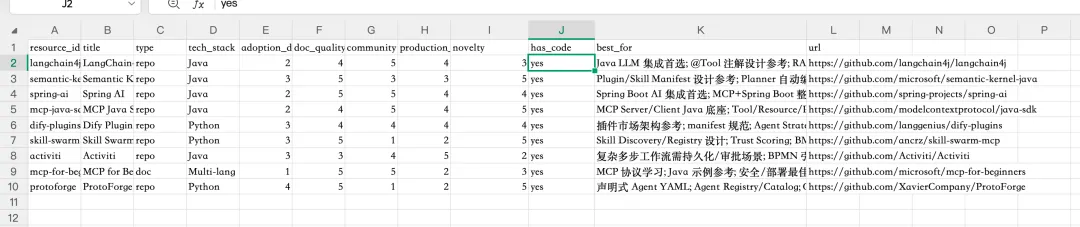
取资源里评分 3 分以上的内容进行总结
我就可以根据他的调研报告,去理解,去尝试落地,减少大量搜索资源的时间。
踩了哪些坑
换了模型,整个 Pipeline 哑火
用了公司默认某国产模型,(具体是谁不说了 不重要,相信未来模型能力会一直提升的)。发"帮我调研 AI Agent 平台",agent 回复得还挺好——直接给了一篇分析文章。
但 ~/research/ 目录从来没被创建过。sessions_spawn 从来没被调用过。
查了 session 日志才发现:模型看到 AGENTS.md 里 sessions_spawn: {...} 的代码块,把它当成了"示例文档",而不是"执行指令"——然后选择了最短路径,直接用自己的知识写答案。
这不是国产模型 差,而是"看到工具调用指令就真的去调"这个能力,Claude 系列明显更稳定。主控节点必须用指令遵循能力强的模型,这是架构决策,不是模型偏好。
解决方案:主控节点(main、review-lead)换回 Claude Opus 4.6。worker(paper-scout、paper-analyzer)任务更机械,可以用便宜模型。
最终效果
报告结构是固定的,由 review-writer/SKILL.md 模板约束:
## TL;DR ← 先给结论,3-5 句话## 技术全景 ← 这个方向现在在哪里## 方案对比表 ← 所有候选方案横向对比,方案名直接超链接## 各方案详细分析 ← 每个方案深入,数据附来源 URL## 技术趋势 ← 从搜索结果里归纳的方向判断## 落地建议 ← Java 工程师视角的实操建议## 参考资料索引 ← 所有来源链接汇总,相当于审计日志✅ 信息密度提升明显,再也不用手动刷 5 个平台✅ 过滤掉了大量噪音内容✅ 发现了几个之前不会主动关注的优质项目
⚠️ 链接验证有时候会因为网络问题误报,需要偶尔手动复查⚠️ 对中文内容的理解质量略逊于英文
给同样在转型的工程师们(AI 总结的)
1. 不要被"AI 原理"吓到
你不需要搞懂 Transformer 的每一个矩阵运算,才能做出有价值的 Agent 应用。工程师的优势在于系统思维和落地能力,这恰恰是很多 AI 研究者缺乏的。
2. 先找一个真实的自己的需求
不要为了学 Agent 而学 Agent。找一个你真的有的需求,然后用 Agent 去解决它。在解决真实问题的过程中学到的东西,是最扎实的。
3. Follow the builders
别被"AI 要颠覆一切"的焦虑情绪裹挟。去 GitHub,找那些真正在造东西的人,跟着他们的思路走。
这篇文章,记录了我从"看到 autoresearch"到"搭出第一个真实 Agent 项目"的过程。不是教程,不是方法论,就是一个普通工程师的真实经历。如果对你有一点点帮助,就是最大的价值。
下一个系列,我准备做一个 learn-claude-code 的专题 ,一个从 loop 开始的故事
one loop & bash is all you need
系列导航 第①期:Java 老兵转型 AI:我的第一个问题不是"怎么学",而是"信谁" 第②③期:Karpathy 开源了什么?我抄了作业,搭了个多 Agent 调研神器 ◀ 本期
