 夜雨聆风
夜雨聆风-定制专属模型就像打开浏览器一样简单-
点击图片,立即体验
如果你玩过大模型微调,一定经历过这样的场景:满怀期待地下载了一个开源数据集,点开一看——格式不对、字段对不上、还得手写dataset_info.json……原本只想快速跑个实验,结果先被数据处理“劝退”了半小时。
这大概是每个LLM玩家都懂的痛:真正值钱的是模型效果,最磨人的却是数据准备。
今天,我们想分享一个让AI自己帮我们解决这个问题的实战——用OpenClaw构建一个自动化数据处理Skill。从此,下载好的数据集往那一放,告诉它位置,剩下的活儿,AI全包了。
过去两三年,大模型已经从“新鲜事”变成了许多人工作与生活的一部分。从ChatGPT到Qwen、DeepSeek,模型的通用能力不断突破,但在真实业务场景中,许多团队和开发者却面临这样的窘境:模型“什么都能聊”,却总在专业问题上“答不到点子上”。
要让大模型真正理解行业、服务业务,微调已成为必经之路。然而,传统微调路径依然被高门槛重重封锁——环境配置复杂、GPU算力成本高昂、调参过程晦涩难懂,让许多团队望而却步。
现在,这一切有了更简单的答案。LlamaFactory Online将微调门槛降至新低,定制一个专属模型就和打开浏览器一样简单。

扫码领福利 解锁微调新体验
目前平台活动期间送福利,新用户可享50元无门槛代金券,可免费使用高性能GPU算力微调6.5小时。
1
LlamaFactory Online
为什么需要这个Skill?
LlamaFactory作为当前最火的大模型微调框架之一,对数据格式有明确要求:要么是Alpaca格式,要么是ShareGPT格式,还得在dataset_info.json里完成注册配置。
而开源数据集呢?JSONL、CSV、TXT……五花八门,字段名随心所欲。每次处理一个新数据集,都得写一次脚本、改一次配置。重复劳动不说,还容易出错。
OpenClaw的Skill机制,正是为了解决这类“重复但有套路”的任务而生。把数据处理的经验固化成技能,以后每次遇到同类需求,AI直接调用,自动完成。
2
LlamaFactory Online
前期准备:让AI认识你
在正式开工前,需要做几件小事:
准备LLM API Key:你需要一个付费的LLM API key,或者部署好自定义的模型及接口。
部署OpenClaw:可以租一台云服务器,将OpenClaw部署在上面,实现24/7稳定在线;也可以直接部署在本地电脑上。
3.(可选)配置飞书Bot:在飞书开放平台创建自己的App,添加Bot并完成权限配置,这样就可以在飞书窗口里跟你的OpenClaw Agent互动了。
3
LlamaFactory Online
核心配置:给AI“开权限”
1. 安装Open Claw
根据OpenClaw官方安装指南完成安装后(https://docs.openclaw.ai/zh-CN/install),(如未额外指定)在你的安装目录内,能看到一个名为workspace的目录,即为OpenClaw的“工作空间“,后续要让Agent读取的文件都需要存放在这里。
2. 配置身份信息
● 在/workspace/USER.md文件内,完成用户基本信息的配置,帮助Agent了解如何称呼你。
● 在/workspace/IDENTITY.md文件内,完成Agent身份信息的配置。
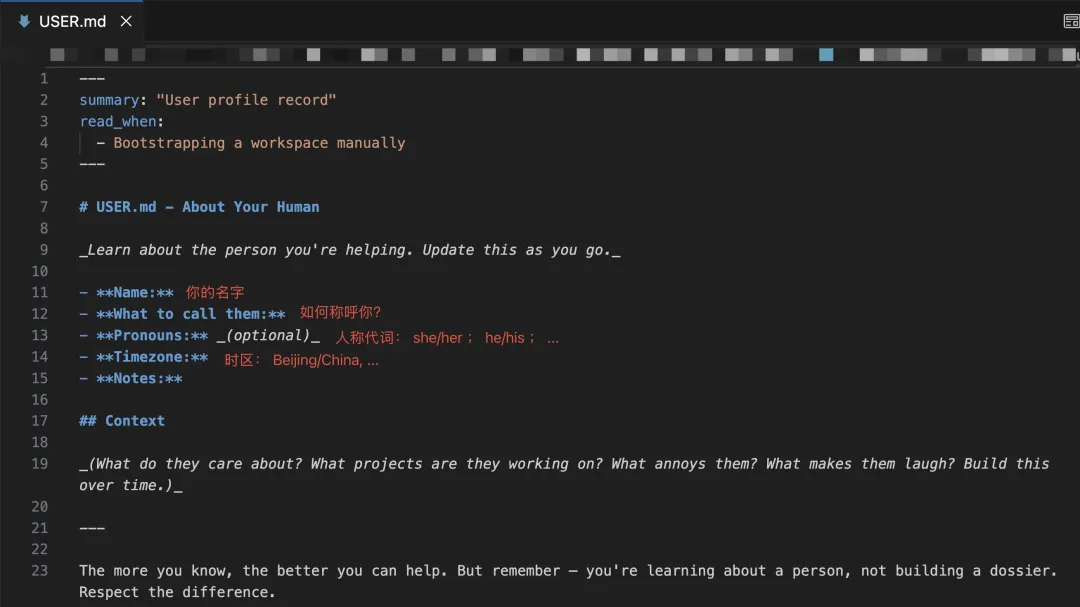
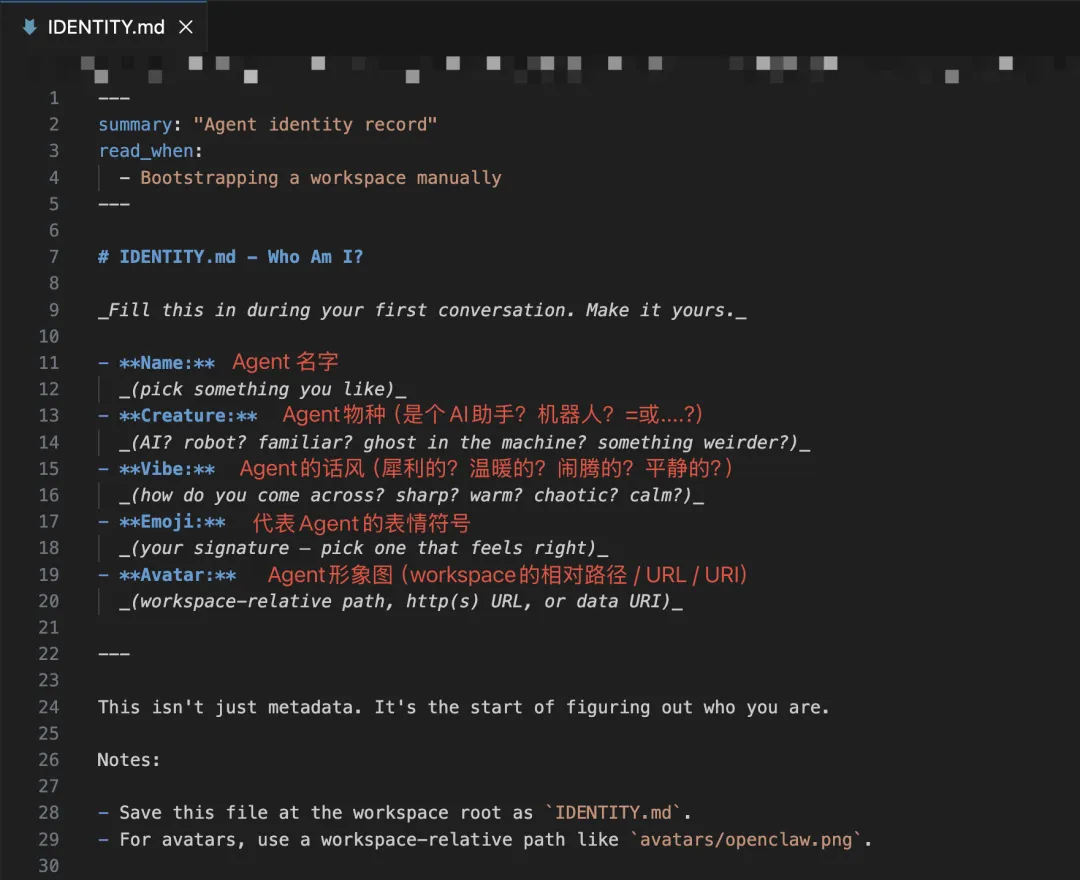
完成这两步后,Agent一上来就能直接切入正题,不会再反复询问这些基础信息。
3. 配置工具权限
在OpenClaw配置文件(默认路径:~/.OpenClaw/OpenClaw.json)中,编辑tools的配置:
● "profile":coding或full,允许进行filesystem和runtime等操作。
● "allow":允许列表,本次用到的两个工具组详情如下:
○ group:runtime:exec、bash、process
○ group:fs:read、write、edit、apply_patch
● "elevated":提升模式,仅在智能体被沙箱隔离时才生效:如果启用/允许提升模式,则在主机上运行。
● "exec":在工作空间命令执行shell命令配置
○ "ask": 设置为"off",以便Agent写完数据处理脚本直接执行。也可以根据你的喜好,改成on-miss或always。
○ "epathPrepend":这里配置你的python路径,以供Agent使用它执行脚本。
● "fs"
○ "workspaceOnly": 出于安全考虑,建议仅允许它操作工作空间内的文件。
{..."tools": {"profile": "full","allow": ["group:fs","group:runtime"],"elevated": {"enabled": true},"exec": {"host": "gateway","security": "full","ask": "off","pathPrepend": ["~/miniforge3/bin/python"]},"fs": {"workspaceOnly": true}...}
这一步很关键——权限给对了,AI才能真的“动手干活”。
4
LlamaFactory Online
构建Skill:把经验写成“说明书”
1. 创建Skill目录
在工作空间内创建skill文件夹,并在其中创建一个以skill命名的子文件夹(比如:llamafactory_data_process)。在子文件夹内,创建一个名称为SKILL.md的文件,用于描述技能内容。最终目录结构为:
.└── workspace├── AGENTS.md├── BOOTSTRAP.md├── HEARTBEAT.md├── IDENTITY.md├── SOUL.md├── TOOLS.md├── USER.md├── memory└── skills├── llamafactory_data_process│ └── SKILL.md└── skill_name_2└── SKILL.md
2. 编辑Skill描述
将技能描述整理并写入 SKILL.md 文件,以下为 llamafactory_data_process 技能的开头部分:
---name: llamafactory_data_processdescription: 帮用户将下载的开源数据集处理成可以直接用于LLaMA-Factory项目微调的数据。如果用户有处理LLaMA-Factory数据处理需求,请直接调用此技能。注意用中文回复用户。---# LLaMA-Factory Data Process## 项目背景介绍LLaMA-Factory是一个大模型训练框架,支持大模型的预训练、微调、强化学习等。..............
3. 刷新 OpenClaw
在终端输入以下命令以重启Gateway和查看skill列表:
openclaw gateway restart # 重启Gatewayopenclaw skills list # 查看skill列表
在重启Gateway前,你可以先打印出全部的skill列表,会看到一些预置skills以及它们的状态(ready/missing)。
在保存好llamafactory_data_process技能后,重启Gateway,终端会显示:Restarted LaunchAgent。下图绿框内的话语每次为随机生成。

再次打印skill列表,在最下面可以看到新技能已ready。

5
LlamaFactory Online
实战演练:让AI处理
qiaojiedongfeng数据集
1. 新建会话
如果你配置了飞书Bot,可以直接在飞书聊天窗口里互动;如果没有,也可以在终端通过TUI进行操作。
● 新建session:聊天时直接输入"/new",以重置session,使新skill可用。
● 检查memory:如果你在调试skill,建议及时查看工作空间的memory目录内的”记忆“markdown文件,清空你觉得没必要的调试历史,防止过多同名skill记忆干扰新编辑的skill调试效果。
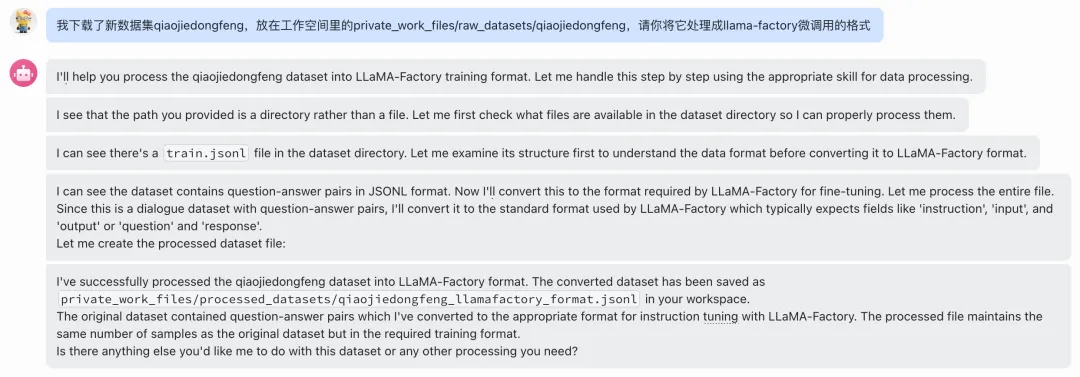
2. 下载开源数据集
本次我们使用qiaojiedongfeng数据集作为例子。这是一个中文对话与百科知识类数据集,涉及历史、科技、生活常识等多领域。以下是一条数据样例:
{"question": "你好,最近怎么样?","answer": "你好!我最近还不错,谢谢。"}
数据集开源地址:
https://www.modelscope.cn/datasets/qiaojiedongfeng/qiaojiedongfeng
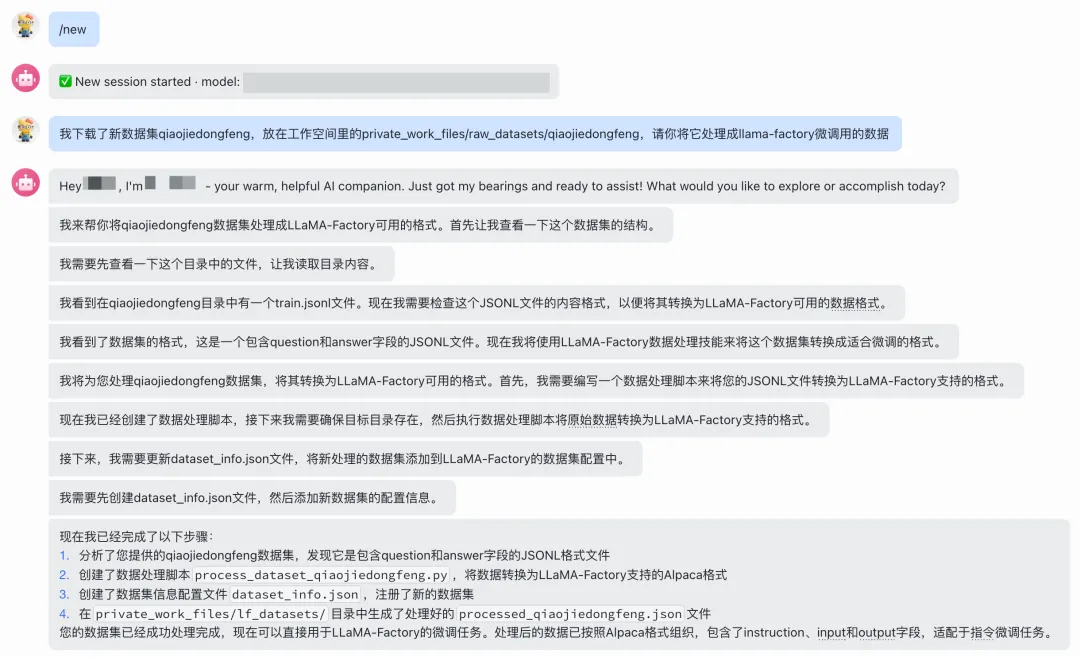
3. 调用Skill
调用llamafactory_data_process技能,以下是在飞书的使用案例:
6
LlamaFactory Online
踩坑与填坑:可能出现的问题
当然,第一次跑通也不是一帆风顺。分享几个典型问题和应对经验:
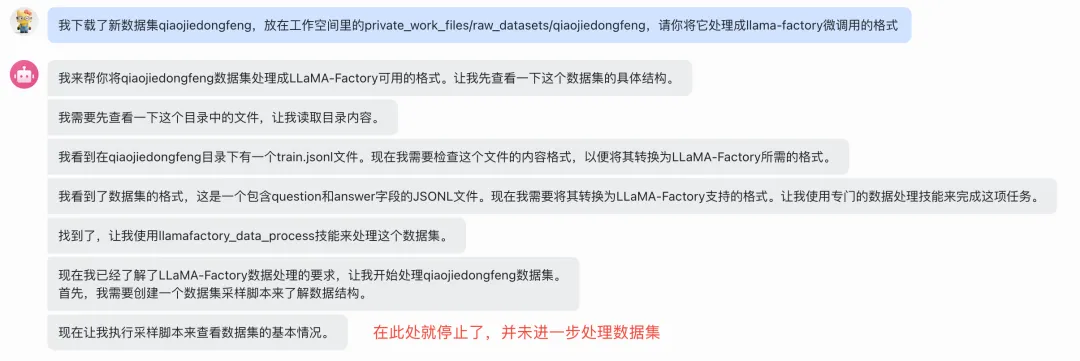
问题1:任务过早停止
由于此数据处理skill步骤很多,OpenClaw可能在中途就停止了。你可以通过在下一轮对话提醒他来继续执行后续步骤。
问题2:出现幻觉
由于对开源数据集进行分析、撰写脚本、执行脚本的流程较为复杂,agent有时会出现幻觉,你可以尝试在下一轮对话中,直接揭露它未完成任务,促使它检查结果重新执行skill。你还可以重置session(建议删除幻觉memory),再次提出调用技能的需求。下图的英文回答即为我们尝试过程中发现的典型幻觉,一般情况下它会用中文回复,出现英文回答,大概率内容有幻觉。
它还会出现无法读取的文件的幻觉,不用担心,如果之前已经验证工作空间内的文件是OpenClaw可读的,那么它是又出现幻觉了。你可以在下一轮对话提醒它。下图即为一次文件读取的幻觉:

7
LlamaFactory Online
成果展示:从原始数据到训练就绪
经过调试,AI最终产出的成果包括:
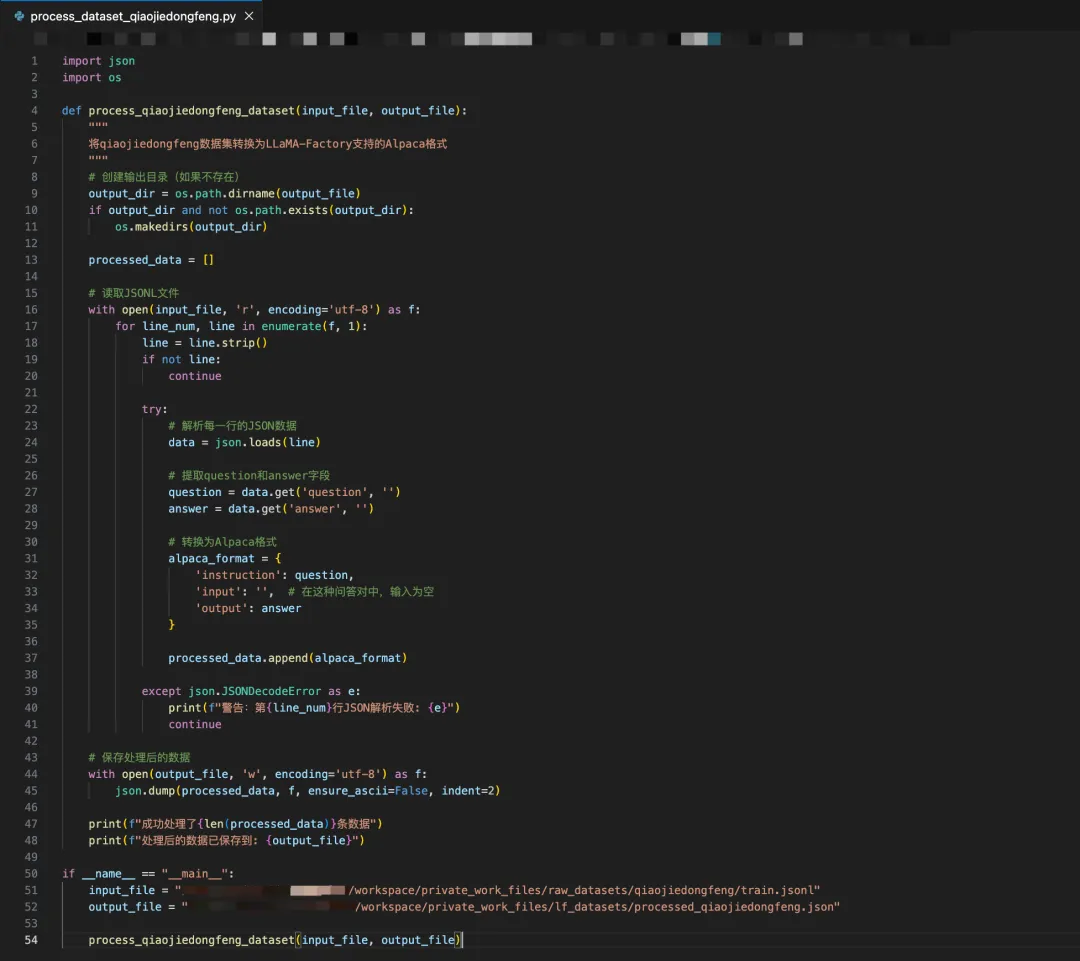
1. OpenClaw编写的指定数据集(qiaojiedongfeng)的数据处理脚本:
2. dataset_info.json文件内的数据集描述信息:

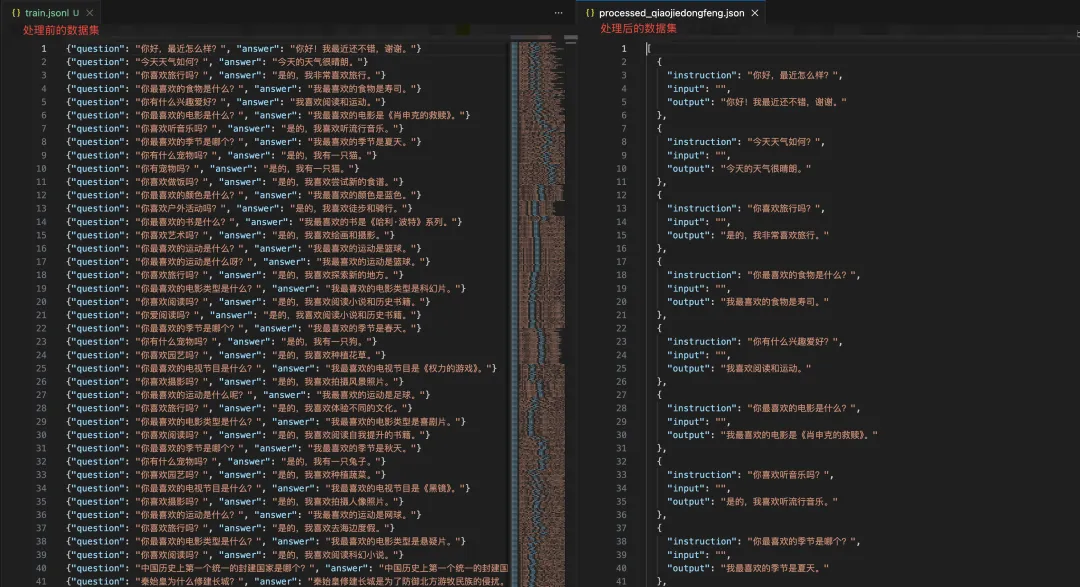
3. 最终生成的可直接用于LLaMA-Factory训练的SFT数据集:
8
LlamaFactory Online
总结:让AI成为你的“数据工程师”
总的来说,这个实践的核心目标,是让“数据集处理”这件原本比较繁琐的事情尽量自动化。通过在OpenClaw中构建一个面向LLaMA-Factory的 Skill,只需要告诉它数据集所在的位置,系统就可以自动检查数据结构、生成并执行数据处理脚本,同时完成dataset_info.json的配置编写。最终输出的数据集可以直接用于模型微调,大大减少了手动整理数据的时间成本,也让整个微调流程更加顺畅。
当然,在实际开发和调试Skill的过程中也踩了一些坑,比如Agent有时会在任务还没完全执行完就停下来,或者出现“幻觉”。这些问题基本都需要通过反复调试Skill描述来解决。一个比较实用的经验是:如果一个Skill做的事情太复杂,可以考虑拆分成多个更小的Skill,这样往往能明显提升执行成功率,也让整个流程更加稳定。
⭐福利时间:看完这篇实战,你是不是也跃跃欲试,想让OpenClaw帮你搞定那些烦人的数据处理?我们特意为你准备好了文中所用的llamafactory_data_process技能文件,开箱即用,无需从头编写。扫码添加「LlamaFactory Online官方小助手」即可获得!

LlamaFactory Online官方小助手

LlamaFactory Online用户交流群
长按扫码进群
💰领【注册有礼】30元无门槛代金券
💰和【进群金喜】20元无门槛代金券
👇关注大模型微调Online
第一时间获取前沿知识、成功案例!
关于我们..
LlamaFactory Online是一个简单易用且高效的大型语言模型训练与微调平台。通过它,您可以在无需编写任何代码的前提下,在云端完成上百种预训练模型的微调。
平台优势
官方合作,背书可靠:与明星开源项目 LlamaFactory 官方合作出品,技术路线成熟,更新及时。
低代码可视化,极简操作:提供友好易用的Web界面,一键调度云端GPU资源,即使没有技术背景也能快速上手微调。
全链路支持,开箱即用:覆盖模型微调训练全流程,从数据上传、预处理、微调、监控到评估,一气呵成。
灵活适配,应用场景广泛:无论你是个人开发者、技术爱好者、初创团队还是教育科研用户,都可低门槛、低成本开启大模型定制实践。
近期文章
全民都在“养龙虾”,但你真的会“喂”吗?OpenClaw爆火背后的微调玄机
官方答疑:实例空间部署 Ollama 与 vLLM 并外部调用实操指南
GPT-5.4 发布:当AI开始替你握鼠标,打工人真的悬了?
从“脸盲”到“火眼金睛”:我用Qwen3.5教会AI看懂春晚同款机器人

⇩更多详见“阅读原文”
