 夜雨聆风
夜雨聆风导读:很多人用 OpenClaw 时都会遇到一个隐蔽的"吞金兽"——随着对话时间变长,上下文像滚雪球一样膨胀,同一个问题的 Token 消耗可能从几千涨到几十万。这不是玄学,这是大语言模型的底层机制决定的。本文从原理出发,拆解三种经过验证的降本策略。
一、斜杠命令:对话"瘦身"的即时手术刀
对于 LLM 而言,每次请求的成本 = f(上下文长度)。上下文越长,推理越慢,Token 越贵。这是一条几乎无法绕开的物理定律。
好消息是,OpenClaw 内置了三条斜杠命令,可以直接在聊天框中发送,无需任何前缀,即刻生效。
1. /compact —— 压缩上下文,保留精华
原理:让 OpenClaw 对当前会话历史执行一次"摘要式压缩",保留关键信息,丢弃冗余细节。后续对话将基于这份精简摘要继续,而非完整的历史记录。
适用场景:
📌 对话已经进行了很多轮,前面带着一大段历史 📌 响应明显变慢、费用飙升,但又不想从头开始 📌 当前话题还要继续,只是不需要保留所有细枝末节
操作:直接发送 /compact
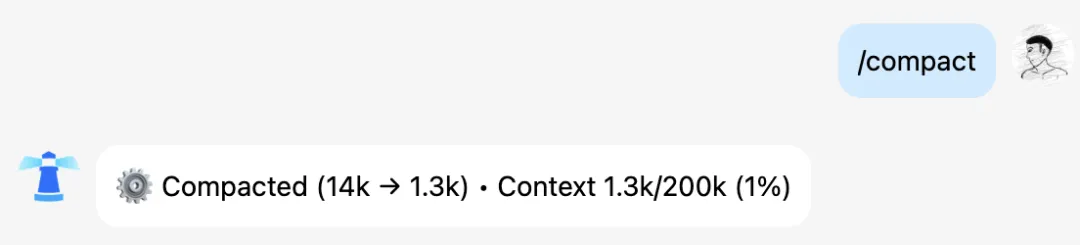
实测数据:如截图所示,一次 compact 操作可以将上下文从 14k 压缩到 1.3k,压缩比高达 90% 以上。这意味着后续每一轮对话的 Token 成本都会大幅下降。
2. /reset —— 清空短期记忆,保留长期认知
原理:重置当前会话的短期上下文,但长期记忆(如你的个人偏好、项目背景、团队代号等)仍然保留。类比人类认知——你忘记了今天上午的闲聊内容,但没忘自己叫什么名字。
适用场景:
📌 当前话题已结束,准备聊一个完全不同的事 📌 上下文臃肿,Token 消耗持续走高 📌 不希望清空已积累的关键背景信息
操作:直接发送 /reset
执行后效果:
✅ 当前对话线程的历史上下文被清空 ✅ Agent 的长期记忆(MEMORY / 重要存档)完整保留 ✅ 后续问题在全新的短期上下文中继续
3. /new —— 彻底"新建标签页"
原理:创建一个真正从零开始的新会话。如果说 /reset 是"换个话题",那 /new 就是"换个房间"。
适用场景:
📌 需要彻底隔离上下文,不希望任何历史信息干扰 📌 想做 A/B 对比测试——一个会话保留上下文,另一个完全从头 📌 在同一频道里开启全新的独立对话
操作:直接发送 /new

从信息论的角度,/new 将信道噪声归零。对于需要精确输出的场景(如代码生成、数据分析),这往往是最经济的选择。
二、多 Agent 分工:从架构层面做"降维优化"
如果说斜杠命令是"战术级"优化,那么多 Agent 分工就是"战略级"降本。
问题根源:当你用一个 Agent 同时处理写文档、写代码、运营维护、团队管理等多种任务时,所有信息都堆在同一个"大脑"里,会带来两个致命问题:
1️⃣ 记忆越来越杂乱
写代码、写周报、写公告、记代号,全都在同一个 workspace 中。模型每次生成时,都要从一大堆不相关内容中筛选有用信息——这就像让一个人同时备考高考六门科目,用同一本笔记本记所有知识点。
2️⃣ 每个会话的上下文越来越长
为了让它"记得住",你不断把历史信息喂给同一个 Agent,Token 消耗呈指数级增长。
解决方案:像组织团队一样拆分 Agent
为不同团队 / 不同飞书群 / 不同职能,配置各自独立的 Agent 每个 Agent 拥有自己的 workspace、记忆、技能、模型 某个团队的长对话和知识积累,只占用对应 Agent 的上下文,而非污染整个系统
收益量化:
| 维度 | 单 Agent 模式 | 多 Agent 分工 |
|---|---|---|
| 上下文干净度 | ❌ 大量无关信息 | ✅ 精准聚焦 |
| Token 可控性 | ❌ 持续膨胀 | ✅ 独立计量 |
| 排查效率 | ❌ 全局影响 | ✅ 独立调优 |
💡 如果你希望按「飞书群聊 → 独立 Agent」的方式落地,可以参考教程:配置相互独立 Agent(飞书多 Agent 实战教程)
实践中的"组合拳":先通过多 Agent 分工从架构层面拆分,再在每个 Agent 内部用 /compact / /reset 控制单次对话长度。这是目前最有效的全链路降本方案。
三、memory-search:让 Agent 学会"查资料"而非"死记硬背"
这是最容易被忽略、但长期收益最大的一招。
核心思想:不要把所有东西都塞进同一段对话。让 Agent 在需要时主动检索历史记忆,而非每次都携带全部历史上下文。
OpenClaw 提供的 memory-search 机制(默认开启),其工作方式是:
把关键信息固化到 memory 文件 / 知识库中 Agent 在需要时用查询的方式取回小块相关内容 模型输入中只包含 当前问题 + 高度相关的一小段记忆
效果对比:
❌ 旧模式:每次对话都重复大量背景 → Token 线性增长 ✅ 新模式:按需检索 → Token 消耗趋于稳定
你需要养成的一个习惯:在完成一轮对话或任务后,主动告诉 OpenClaw"把这些关键信息记下来"。就这一步,就能让 memory-search 持续为你省钱。

小结:三层防线,全链路降本
以上三种策略可以叠加使用,形成完整的 Token 降本体系:
🔹 日常随手用
/compact、/reset、/new掌控当前对话长度 🔹 架构层面 拆分多 Agent,让不同任务各用各的脑 🔹 知识管理层面 把长期信息迁移到 memory / 知识库,用 memory-search 做精确查找
合理组合这些手段,你会看到两个显著变化:
对话质量提升 —— 响应更稳定,跑偏更少 成本可控 —— 每个月的 Token 账单不再「一路爬坡」
如果这篇文章帮你省了钱,点个「在看」让更多人看到 👇
你在使用 OpenClaw 时还有哪些省 Token 的骚操作?欢迎在评论区分享,点赞最高的送一份 Token 额度 🎁
📌 本文灵感来源于腾讯云开发者社区。OpenClaw 使用推荐云上部署,云上部署推荐使用腾讯轻量云 Lighthouse。养虾就用轻量云。 🦞
