 夜雨聆风
夜雨聆风但如果一个 Agent 只能聊天,它的价值其实很有限。
真正有意思的地方在于:它能不能进入真实工作流,替你把一串原本要手动完成的动作,完整执行下来。
最近我专门拿 OpenClaw 做了一次实战测试。
目标很简单:
去抖音搜“整体厨房”相关爆款视频 批量采集 50 条 全部下载到本地 提取每条视频文案 再把每条视频按场景自动拆片 最后按目录整理好,方便后续二创、分析和复用
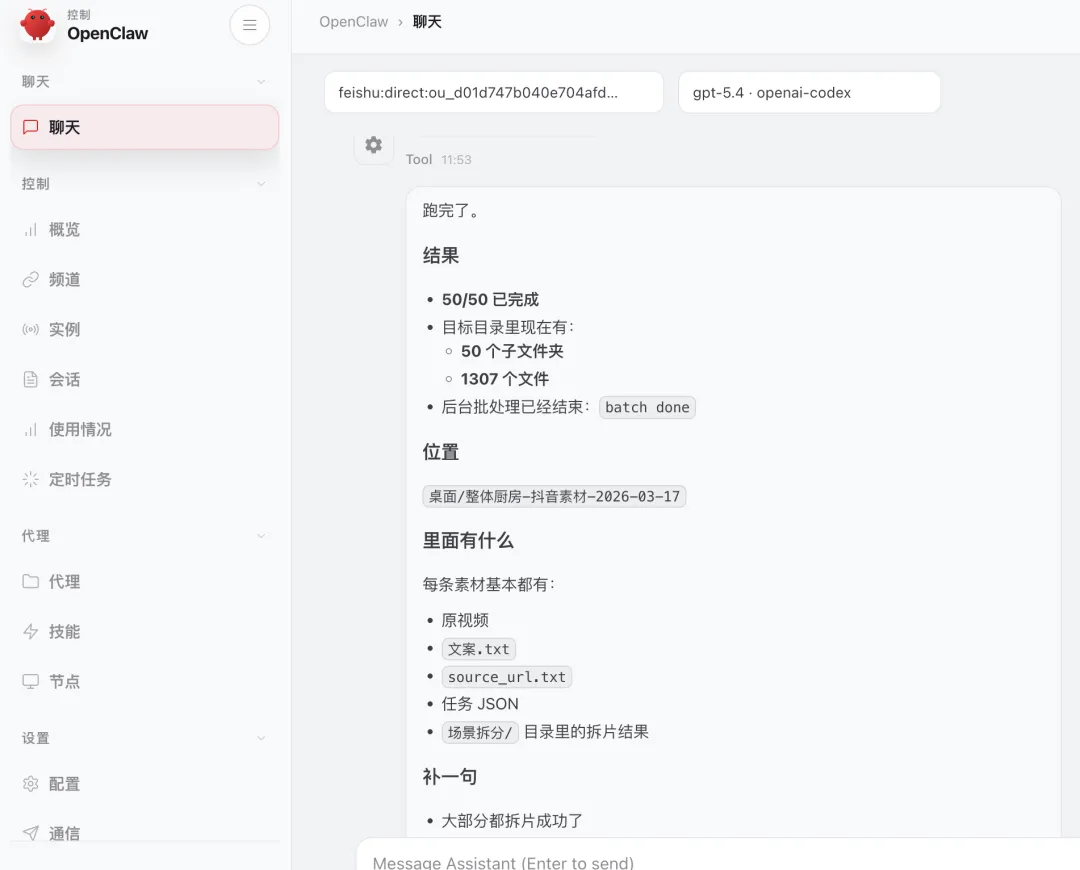
结果是,这条链路跑通了。
最终本地落地了:
- 50 个素材子目录
- 1307 个文件
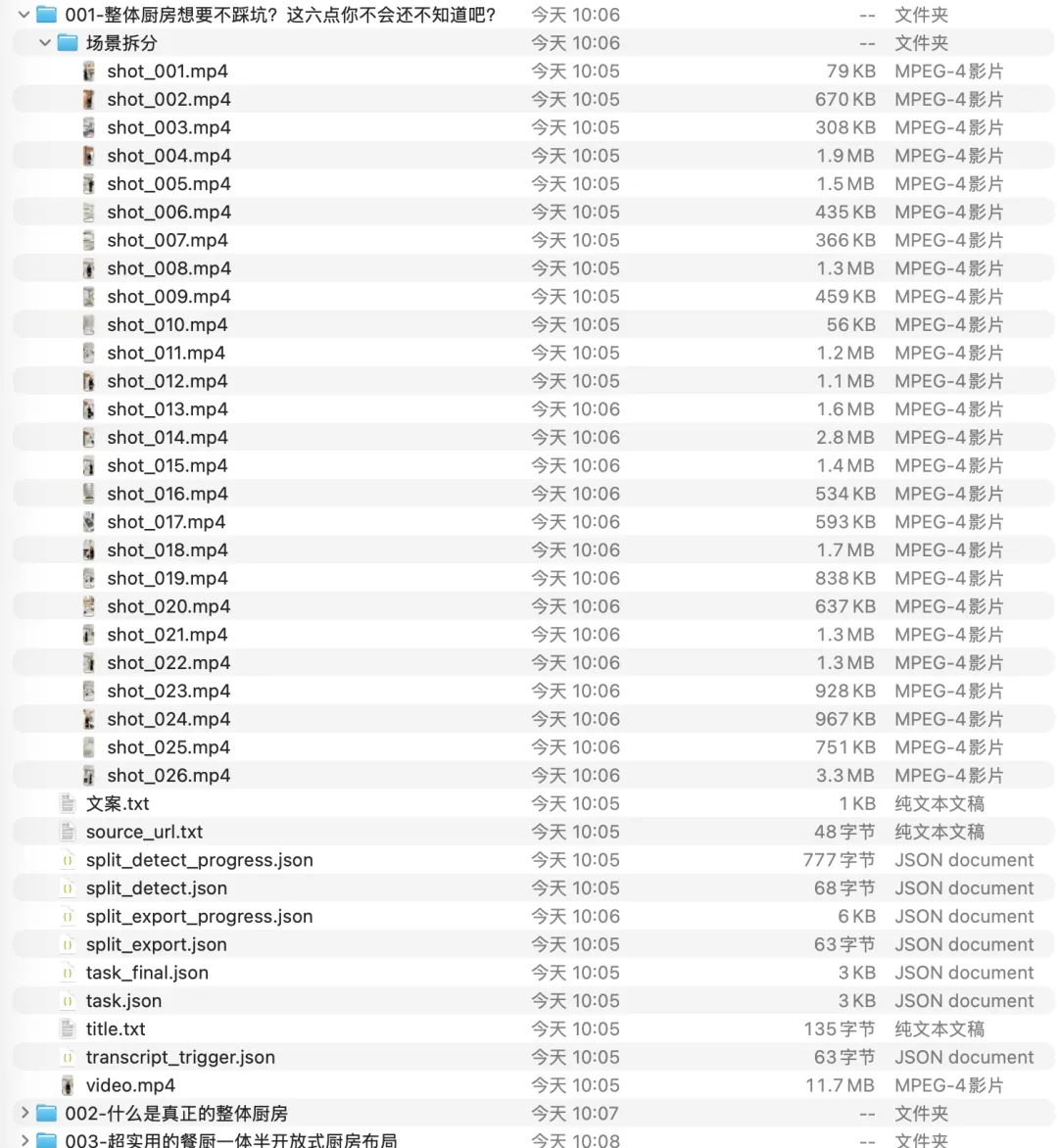
每条素材都包含: 原视频 文案文本 原始链接 任务状态文件 场景拆分后的镜头片段
这件事看起来像一个“内容采集任务”。
但本质上,它更像一次能力验证:
OpenClaw 已经不只是个会聊天的 AI。它已经可以把浏览器、接口、本地文件、媒体处理服务串起来,完成一条真实的自动化工作流。
今天这篇文章,我不讲虚的,重点讲两件事:
OpenClaw 到底能干这件事到什么程度 它是怎么把这件事干成的
一、这件事真正解决的是什么问题?
先说结论。
这次测试,解决的不是“怎么找 50 个视频”这么简单。
它真正解决的是:如何把一个跨平台、跨工具、跨步骤的内容处理流程,变成一条可执行的自动化链路。
如果你以前做过短视频素材收集,你应该很熟悉这套低效流程:
手动去抖音搜关键词 一条条点进去看 复制链接 下载视频 提取语音文案 把视频导入工具拆镜头 再把所有结果整理成文件夹
这套流程的问题,不是某一步不会做,而是:
步骤太多 软件太散 容易中断 中间状态不透明 最后产物不统一
也就是说,难点不是“功能缺失”,而是执行闭环缺失。
OpenClaw 这次做的事,就是把这些分散动作,串成一条统一执行流。
二、OpenClaw 在这次任务里,具体做了什么?
先直接说结果,再拆过程。
这次完整流程包括 4 个核心动作:
1)批量采集视频链接
OpenClaw 先通过浏览器进入抖音搜索页,抓取与“整体厨房”相关的视频结果。
不是简单做网页摘要,也不是给几个模糊推荐词,而是直接拿到真实的视频 URL 列表。
2)批量创建视频解析任务
有了链接之后,OpenClaw 继续调用本地视频处理服务,把每条抖音链接送去解析。
解析成功后,会生成:
视频文件地址 封面信息 音频转换任务 后续文案提取任务入口
3)提取视频文案
等音频转好后,再发起文案提取,也就是 ASR 语音转文字。
最终每条视频都会落一份文本结果,方便后续做:
爆款脚本分析 钩子拆解 口播结构复盘 批量改写 内容聚类
4)按场景自动拆片
视频下载完成后,再继续走“场景检测 → 镜头导出”流程。
最后每条视频都被拆成多个镜头片段,放进独立目录。
这一步特别关键,因为它让这些视频不再只是“看过就算了”的素材,而变成了可以直接进入二创生产环节的镜头资产。
三、这件事为什么不是“写个脚本”那么简单?
很多人看到这里会觉得:
“这不就是爬链接 + 调接口 + ffmpeg 吗?”
如果只是从技术组件层看,确实可以这么理解。
但真正难的,从来不是单个工具,而是把这些工具稳定串起来。
这次实际执行过程中,遇到过好几个典型问题:
1)服务没启动
刚开始时,本地媒体服务端口不可用,导致后续解析流程根本跑不起来。
OpenClaw 先做了健康检查,确认问题不在抖音,而在本地服务未启动。
2)登录态失效
服务启动后,第一次调用接口返回的是:
401,无效 token
这说明流程表面通了,但真正执行依赖的登录态还没准备好。
这类问题,传统自动化很容易卡死,因为很多脚本只会“一路往下跑”,不具备发现和解释环境问题的能力。
但这次 OpenClaw 的做法是:
先验证单条任务 再识别问题在认证层 等本地登录态恢复后再重试 确认样本跑通,再启动批量任务
3)长任务被系统中断
第一次后台批处理时,任务被系统直接 SIGTERM 掉了。
这不是业务失败,而是任务托管方式不对。
后面改成真正脱离会话的常驻后台方式后,批处理才稳定跑完。
这个细节很重要。
因为它说明一件事:
AI Agent 真正进入工作流之后,它面对的问题已经不是“怎么回答用户”,而是“怎么像一个真实执行系统一样处理环境、状态和长任务”。
四、OpenClaw 是怎么把这条链路串起来的?
这次任务背后,实际上调度了几类能力。
1)浏览器能力
负责进入抖音搜索页面、读取页面结果、提取视频链接。
这一步决定了它能不能接入真实互联网内容,而不是停留在模型自己的知识里。
2)HTTP / 接口调用能力
负责调用本地服务接口,比如:
视频解析 文案提取 场景检测 镜头导出
这一步决定了它能不能把“看见页面”变成“开始执行”。
3)本地文件系统能力
负责把任务结果真正落到本地目录,包括:
创建文件夹 保存视频 保存文案 保存源链接 保存任务状态 JSON 保存拆片后的镜头文件
这一步决定了结果是不是“真的存在”。
很多 AI 工具最大的问题,就是过程看起来很智能,但结果落不了地。OpenClaw 的强项之一,就是它不是只生成文字,它能处理真实文件。
4)长任务控制能力
负责批处理、后台运行、进度记录和结果汇总。
比如这次最后桌面目录里会自动生成 README.md,里面能看到:
总任务数 已完成数量 每条视频的状态 每条视频拆了多少镜头 哪些视频因为场景变化不足,没有拆出更多片段
这其实已经很像一套轻量级任务编排系统了。
五、这次任务最后产出了什么?
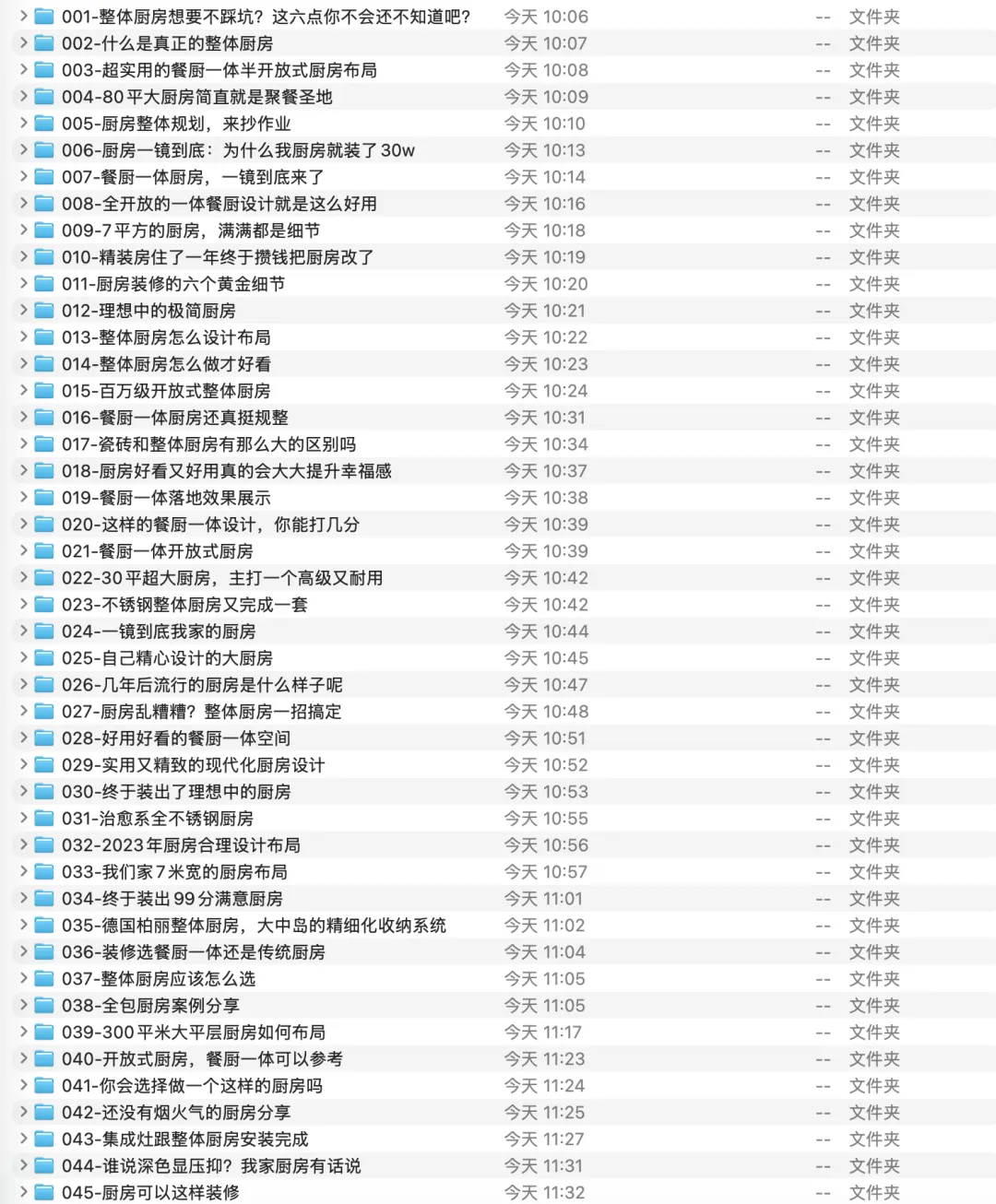
最终目录结构大致是这样的:
```text
整体厨房-抖音素材-2026-03-17/
├── README.md
├── 001-整体厨房想要不踩坑/
│ ├── video.mp4
│ ├── 文案.txt
│ ├── source_url.txt
│ ├── task.json
│ ├── task_final.json
│ └── 场景拆分/
│ ├── shot_001.mp4
│ ├── shot_002.mp4
│ └── ...
├── 002-什么是真正的整体厨房/
├── 003-超实用的餐厨一体半开放式厨房布局/
└── ...
```
这次总计完成:
- 50 条视频采集
- 50 条视频下载
- 50 条文案提取
- 50 条目录归档
大部分视频都完成了场景拆分 少数视频因为镜头变化不明显,被标记为“未检测到足够场景”
这个结果的意义,不只是“采了 50 条”。
而是这些素材已经从“原始视频”变成了结构化可用资产。
你接下来不管是做:
爆款分析 文案改写 素材拼接 镜头二创 口播重写 选题归类
都能直接接着用。
六、这说明 OpenClaw 已经具备什么能力?
我觉得可以很明确地说:
1)它已经具备“任务执行”能力
不是只会答题,而是能真跑流程。
2)它已经具备“工具编排”能力
浏览器、接口、本地文件、媒体处理,不再是彼此孤立的工具。
3)它已经具备“状态处理”能力
遇到服务未启动、token 失效、长任务中断,不是直接死掉,而是能定位、恢复、继续。
4)它已经具备“结果落地”能力
最后不是回你一段总结,而是在桌面上留下可直接使用的真实产物。
这几点放在一起,才是 OpenClaw 最值得关注的地方。
七、这件事对普通用户和企业意味着什么?
如果你是普通内容创作者,这意味着:
素材采集会更快 二创准备成本会更低 你可以把更多精力放在选题和表达,而不是重复劳动上
如果你是企业或者团队负责人,这意味着:
原来靠人手搬运和整理的流程,可以开始半自动化甚至全自动化 内容中台、销售素材库、竞品库、培训资料库,都会变得更容易搭起来 AI 的价值不再只是“辅助思考”,而是进入执行层,开始真正节省时间
换句话说:
过去我们用 AI,是让它帮我们“想”。现在开始可以让它帮我们“做”。
这一步的意义,比很多人想象中要大得多。
八、结语
这次“批量采集 50 个抖音视频、下载、提取文案、自动拆片”的测试,最重要的不是数字本身。
不是 50 条,也不是 1307 个文件。
最重要的是,它验证了一件事:
OpenClaw 已经可以从“聊天工具”走向“执行系统”。
它不只是会回答你“能不能做”,而是开始真的去做,并且把结果交付出来。
这才是我认为 Agent 真正开始有现实价值的标志。
因为业务里最贵的,往往不是某个聪明想法,而是那些又脏、又碎、又长、又容易出错的执行过程。
谁先把这些过程交给 Agent,谁就更早进入下一阶段。
而这次测试说明,OpenClaw 已经站在这个门槛上了。
大家对openclaw小龙虾感兴趣的,欢迎评论区交流。
