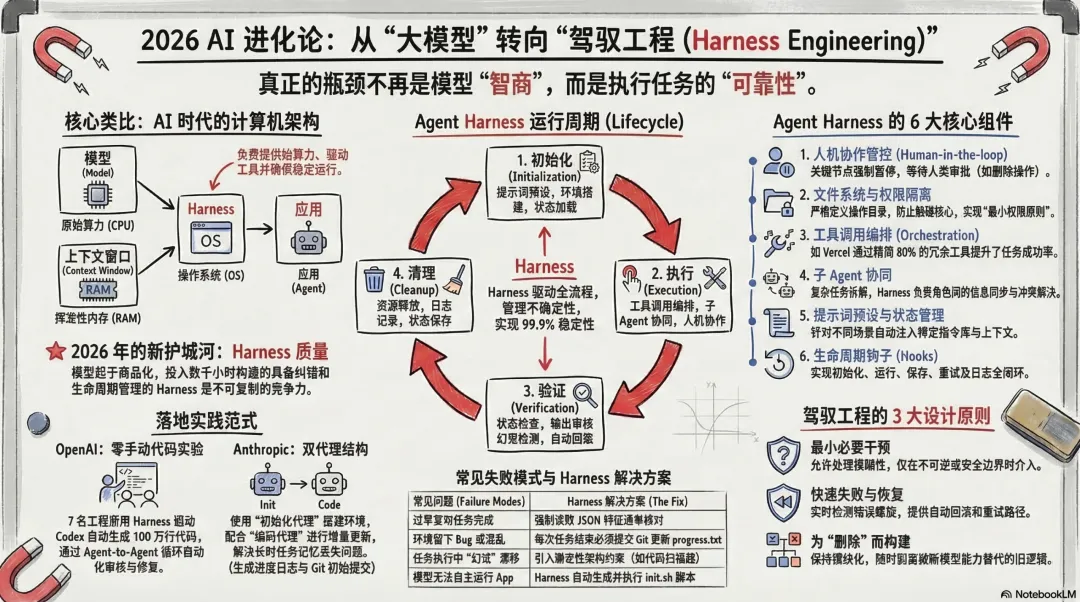
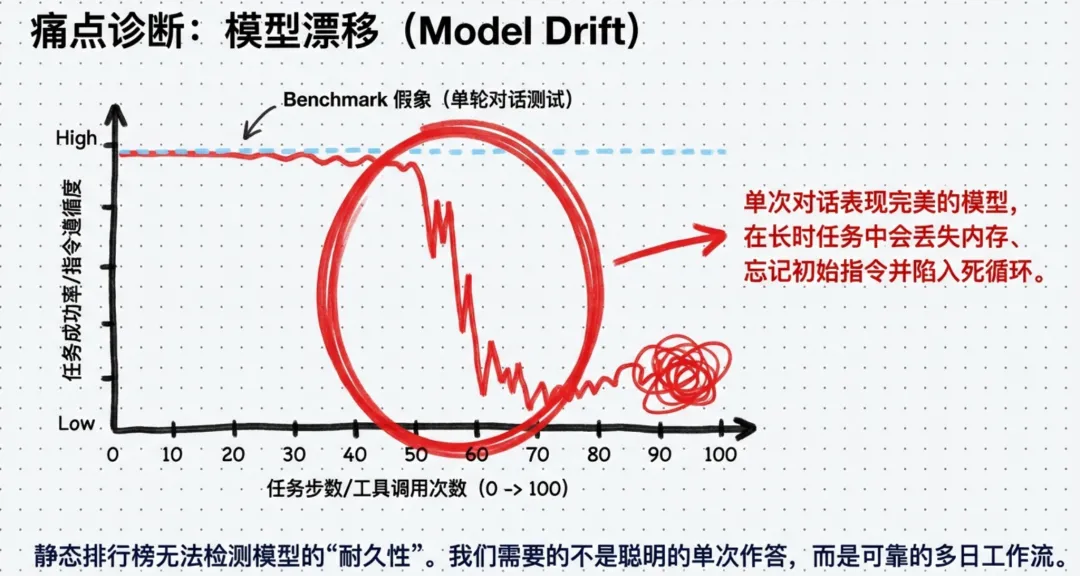
OpenClaw真正的核心Agent Harness最近,在公司没事就看看OpenClaw的代码,毕竟是程序员出身的,都有想看看大神的代码涨什么样。但发现OpenClaw的代码更新的速度太快了,于是打开了OpenClaw的issue研究了一下。发现80%的issues都在做一个事情,就是Harness Agent的工作。于是,回来又把Harness Agent的原理看了一遍,有了新的体会。到目前为止,我发现如果中小企业没有成熟的AI架构,学Palantir成本太高,倒是可以尝试用OpenClaw最为最小内核,利用Palantir给出的架构原则,结合Agent Harness实践,倒是短时间内可以有一个相对来说可以落地的AI服务平台。目前,已经有客户和我们一起做类似的落地,有了阶段性的成果。下面介绍一下Agent Harness前提,为什么要做Agent Harness在长时复杂任务中(例如执行数百次工具调用或持续数日的工作流),大模型往往会在运行几十步之后开始偏离初始指令、忘记关键约束条件或产生幻觉,这种现象被称为“模型漂移”。为了解决这一落地难题,Agent Harness 作为“管控操作系统”,通过以下几个维度的核心机制对模型进行强行“兜底”和纠偏:1. 建立长时状态交接与动态上下文管理模型漂移的首要原因是上下文窗口有限且容易信息过载。Harness 摒弃了让模型在一个无限膨胀的上下文窗口中“死扛”的做法:上下文生命周期控制Harness 内置了自动压缩(Compaction)、修剪和会话重置机制,当 Token 数量过大或任务时间过长时,自动提炼关键信息并清理旧的上下文,防止历史信息污染推理。物理化的状态交接Harness 将长任务切分为多个离散的会话。它强制要求系统在开始时建立结构化的环境(例如生成 claude-progress.txt 进度文件和初始化 Git 提交)。在随后的每次新会话中,Agent 必须先读取进度日志和 Git 记录来“恢复记忆”,并在结束时更新日志,通过这种清晰的“状态交接”来确保任务连贯性。2. 采用渐进式披露(Progressive Disclosure)代替超长说明书试图用一个几千字的超长提示词或规则手册来约束 Agent,往往会导致其注意力分散、“模式匹配”失灵,从而引发漂移。Harness 转变了思路,将系统的真实知识体系(如架构设计、质量文档)结构化地持久保存在文件库中。它仅给 Agent 注入一个简短的“目录”(例如 100 行的 AGENTS.md 作为地图),Agent 在执行长时任务时,根据当前步骤的需要逐步查阅深层文档。这确保了 Agent 随时都能获取准确的局部规则,而不会被过量信息淹没。3. 引入机械化约束与系统级验证防止漂移不能仅仅依赖大模型自身的语言逻辑,必须依靠坚固的“物理护栏”:强制架构约束Harness 通过融合确定性的自定义代码检查器(Linters)和结构测试框架,为 Agent 划定绝对的行为边界(例如强制限定模块的依赖方向和接口规范)。一旦 Agent 输出的代码违规,系统会直接拦截并要求重写。状态级验证替代语言验证Harness 赋予 Agent 真实的测试工具(如带有视觉能力的 Puppeteer 浏览器自动化工具),强制要求 Agent 像人类一样在真实环境中测试其结果(例如点击网页、查看界面是否正确渲染、接口是否报错)。通过真实的“系统状态”而非 LLM 的“嘴上说完成”来确认任务进度,大幅减少了虚假幻觉。4. 自动执行“垃圾回收”对抗系统熵增在长时任务中,随着 Agent 的不断操作,工作环境(如代码库、文档)会不可避免地产生混乱和技术债(即“熵增”),这会导致 Agent 复制早期的错误模式并进一步放大漂移。Harness 设立了专门的后台监控和清理 Agent,定期扫描整个系统。这些 Agent 会自动找出偏离规范的代码、过期的文档或无效的工具调用逻辑,并主动发起重构(Pull Request)进行修复。通过这种持续的小步清理机制,Harness 确保了长时运行的系统始终处于高质量和高一致性的状态。5. 将漂移转化为训练数据,实现底层能力进化从更宏观的视角来看,Harness 也是解决未来模型漂移问题的核心数据收集器。它能够将 Agent 模糊的多步骤工作流转化为高度结构化的运行数据(包括每一步的工具调用、推理过程和失败节点)。当模型在第 100 步未能遵循指令发生漂移时,Harness 会精确捕捉这一轨迹。各大 AI 实验室将利用这些由 Harness 捕获的真实场景反馈数据,直接用于下一代模型的训练,从而从根本上优化模型的长时推理能力,打造出在复杂任务中“不疲劳”的底层引擎。第一,什么是Agent Harness及其在AI系统中扮演的角色?Agent Harness是包裹在AI模型外围,专门用于管理长时运行任务的软件基础设施。它既不是Agent本身,也不是单纯的开发框架,而是一个负责规范、引导、管控Agent运行全生命周期的系统。它的核心目标是保证Agent在长时任务中始终保持可靠、高效、可调控的状态,从而解决模型在执行数百次工具调用或多日工作流时容易出错的“模型漂移”现象。在AI系统中,业内公认将Agent Harness扮演的角色类比为计算机的“操作系统”:CPU(算力核心)AI模型提供最基础的原始处理能力。RAM(工作内存)模型的上下文窗口负责临时存储任务过程中的关键信息。操作系统(Agent Harness)负责管理和调度算力资源、优化内存使用、提供标准的驱动程序和运行环境,让上层应用能够在稳定的基础上运行。具体应用(APP)开发者构建的AI Agent则是运行在这个“操作系统”之上的应用,负责实现特定的业务逻辑。具体而言,Agent Harness在AI系统中发挥着以下几个维度的核心作用:提供开箱即用的标准化运行环境与只提供基础“积木”的Agent Framework不同,Agent Harness是一个成品系统。它整合了全套的预设能力和最佳实践,包括提示预设、工具调用的确定性处理、生命周期钩子,以及规划、文件系统访问、子Agent管理等核心能力。这让开发者可以直接跳过构建操作系统的繁琐过程(如处理上下文溢出或工具调用异常),专注于定义Agent的独特业务逻辑,实现开发效率的质的提升。搭建基准测试与真实世界需求的桥梁它能够将最新的模型直接接入实际用例和约束条件中,验证模型在真实工作流中的技术进步。同时,它通过整合成熟的工具和最佳实践,确保开发者构建出体验一致、性能稳定的Agent,让用户真正触达模型的潜在能力。形成基于数据的持续优化闭环Agent Harness提供了一个共享、稳定的运行环境,能将Agent的多步骤工作流(如每一步的工具调用、推理过程、结果输出)转化为结构化的运行数据。开发者可以通过分析这些数据找到性能瓶颈和错误点,从而迭代优化基准测试和模型本身,让AI系统的优化从“凭经验”变成“靠数据”。未来,各大AI实验室也会将其作为模型训练的核心反馈工具,专门捕捉长时任务中的模型漂移点,优化模型的长时推理能力。第二,Agent Harness 的三个核心组件是什么?根据OpenAI团队在构建管控框架(Agent Harness)时的实践经验,其包含了以下三个核心组件:上下文工程(Context Engineering)这一层是对传统上下文管理理念的升级。它不仅包含在代码库中构建持续增强的知识库,更关键的是为Agent提供了访问动态上下文的能力(例如可观测性数据、浏览器导航和终端运行结果等)。这主要解决了“Agent知道什么”的问题,让Agent在动态变化的环境中能始终掌握完整的任务背景。架构约束(Architectural constraints)这一组件的核心作用是为Agent划定清晰的行为边界,防止其出现失控行为。它通过融合确定性的自定义代码检查器和结构测试(如ArchUnit等框架),强制要求Agent生成的代码必须遵循特定的架构模式与模块边界。如果Agent违规,系统会立刻终止操作并要求其重新生成符合规范的代码。垃圾回收(Garbage collection)这里的垃圾回收主要用于对抗系统的熵增和衰退,解决AI生成系统长期维护的难题,而不是指传统的内存管理。系统会设置专门的监控Agent定期扫描代码库和文档体系,自动找出文档不一致、代码违背架构约束或工具调用逻辑无效等问题,并自动进行修复,以确保整个系统始终处于高质量和高一致性的状态。第三,对比 Agent Framework,Harness 有哪些优势?对比传统的Agent Framework,Agent Harness在能力层面上高出一个维度,两者的核心区别可以生动地比喻为“成品系统”与“基础积木”的差异。Agent Harness的具体优势主要体现在以下几个方面:提供“成品级”的开箱即用能力Agent Framework仅仅提供构建Agent的基础模块(例如工具调用的接口、推理循环的模板),这要求开发者必须自己搭建完整的系统,并亲自解决上下文管理、工具调用异常、生命周期控制等一系列底层问题。相比之下,Harness是一个成品系统,它在框架的基础上整合了全套的预设能力和最佳实践,直接提供了提示预设、工具调用的确定性处理、生命周期钩子,以及任务规划、文件系统访问、子Agent管理等核心能力。内置标准化的管控流程,解决长时任务痛点在处理复杂的长时任务时,Harness能自动解决传统框架下棘手的难题。例如,在构建编程Agent时,开发者无需自己编写文件读取、代码编辑、终端执行等操作的整合逻辑,因为Harness已经提供了标准化的工具调用流程,同时也无需担心长时任务运行中出现的上下文溢出问题。实现开发效率的质的提升正是因为Harness承担了底层基础设施(类似“操作系统”)的管理工作,开发者可以直接跳过构建底层基础环境的繁琐过程。这使得开发者能够专注于上层的“应用开发”,即专心定义Agent独特的业务逻辑,从而大幅提升整体开发效率。第四,OpenClaw是如何做Harness以及如何保证Agent长时任务在 OpenClaw 的架构中,Agent Harness 被定义为一个“自动管理 Agent 运行生命周期的控制层(Runtime Control Layer)”,它充当了 Agent 的“操作系统内核”,负责管理上下文、会话、资源和状态,从而将 LLM 从一个单纯的“对话模型”转变为一个“可长期运行的进程”。OpenClaw 是如何做 Harness 的?OpenClaw 的 Harness 主要通过以下四个底层机制来实现对 Agent 的全面管控:上下文生命周期管理(Context Lifecycle)Harness 会自动进行上下文工程,防止 Token 爆炸或历史污染。当 Token 超过 40K 时,会自动提炼并压缩保存到记忆文件;如果上下文超过 6 小时,会裁剪旧信息;此外,还会执行每天或闲置 30 分钟后的会话重置,防止跨天任务的上下文污染。会话级控制(Session Harness)将 Agent 视作长期运行的“进程”来管理。Harness 控制会话的创建与销毁,并设定严格的资源上限(例如 100MB 的磁盘上限)和 7 天自动清理机制,确保长期运行不会耗尽系统资源。执行循环控制(Agent Runtime Loop)管理 Agent “观察-思考-行动”的循环节奏。Harness 通过队列系统控制执行步调,允许人类随时注入新消息来打断或引导当前执行(Steering),并通过严格的权限配置(如 profiles 和 tools.allow/deny)限定 Agent 在当前循环“能做什么”。事件驱动钩子(Hooks)这是一个可编程的扩展层。Harness 允许在关键节点(如会话开始、工具调用前后)插入自动化逻辑,用于自动保存记忆、记录审计日志或进行安全风控检查。OpenClaw 如何保证 Agent 在长时任务中的稳定与可靠?为了让 Agent 在持续数小时甚至数天的任务中不崩溃、不跑偏,OpenClaw 设计了一套综合了可靠性、高效性和可调控性的“基础设施公式”:稳定性 = 记忆管理 + 任务拆解 + 失败恢复 + 权限控制 + 状态验证 + 人类监督。具体措施如下:应对不可靠的外部环境(Failover & State Machine)长时任务必然面临网络问题或模型崩溃。OpenClaw 内置了失败恢复机制(如多 API Key 轮换、模型 Fallback 和推理降级),并在底层维护了明确的Agent 状态机(运行/暂停/停止),允许任务随时挂起和恢复,避免单点故障导致全盘崩溃。任务拆解与多 Agent 协同(Efficiency)为了避免单 Agent 陷入死循环或 Token 爆炸,OpenClaw 采用“总控(Orchestrator)+ 子执行器(Worker)”的多 Agent 架构。主 Agent 负责调度,后台独立的专业子 Agent 负责具体执行并回传结果,实现高效并行。三重硬性执行约束(Controllability - 核心兜底机制)总而言之,OpenClaw 解决长时任务难题的思路是:不盲目依赖大模型的智能,而是通过构建一个“默认不安全但极其可控”的操作系统(Harness),用严格的环境约束和容错机制来为 LLM “兜底”。第五,同样来看看Palantir 是如何做Harness的Palantir 主要通过其平台级的AIP Assist和AIP Agent Studio来构建和落地 Agent Harness(管控框架)。虽然他们并没有生硬地强调“Harness”这个词,但其架构设计完美契合了 Harness 作为“AI 操作系统”的理念:将底层模型包裹起来,提供上下文管理、工具编排、应用管控和统一的交互界面。具体而言,Palantir 是通过以下几个核心维度来打造其 Agent Harness 的:1. 深度集成的上下文工程(Context Engineering)Palantir 的 Harness 不仅仅是读取文本,而是与企业的数据资产和业务逻辑深度绑定。Harness 能够直接整合 Palantir 平台中的“本体对象(ontology objects)”和各种应用程序数据。用户可以在名为 Notepad 的工具中沉淀标准操作程序(SOP)或业务文档,并一键将其作为专属上下文(Context)注入到 Agent 中,让 Agent 真正掌握企业专属的“业务语言”。2. 基于场景的自动化工具编排(Context-Aware Tool Orchestration)Palantir 的 Harness 具有极强的环境感知能力,能够根据用户当前所处的应用界面,自动提供相应的工具调用和管控逻辑:在代码编辑器中Agent 会自动获取代码上下文,帮助开发者解释 Python 代码、跨整个代码库寻找 Bug,甚至将代码翻译为 SQL。在 Pipeline Builder(数据管道构建器)中Harness 会调用相应的工具来解释复杂的数据处理节点、自动生成正则表达式,甚至主动提供让管道运行更快、更省钱的优化建议。在 Quiver(数据分析工具)中Harness 允许分析师使用自然语言查询复杂的机器时间序列数据,并能直接在下方生成柱状图等可视化图表。3. 通过 AIP Agent Studio 实现精细化管控(Configuration & Constraints)在创建一个自定义 Agent(例如库存管理 Agent)时,Palantir 的 Harness 提供了一个名为 AIP Agent Studio 的控制台,让开发者可以严格管控 Agent 的运行边界:模型解耦与选择Harness 实现了应用与底层模型的解耦,用户可以从默认的模型目录中选择模型,甚至导入自带的模型(BYOM)。确定性约束开发者不仅可以设置系统提示词(System prompt),还可以强制调低模型的温度(Temperature),以此来限制模型的发散思维,强制要求其严格基于注入的文档和业务流进行确定性的输出。4. 强制的溯源与可观测性(Verifiability)为了防止模型幻觉并在企业级工作流中建立信任,Palantir 的 Harness 在输出环节设置了严格的规范。Agent 在生成答案后,必须提供信息来源的引用(Citations)。无论是参考了开发者社区的代码,还是参考了企业内部的库存管理配置文档,系统都会将来源文档与答案一并展示,让用户能够追溯上下文。5. 统一的端到端生命周期管理(Unified Lifecycle Deployment)Palantir 的 Harness 充当了全平台的“标准驱动程序”。它将所有复杂的 Agent 配置封装在后台,在前端为所有用户(无论是开发者、分析师还是物流端点用户)提供了一个统一的、随时可以弹出的“助手面板”。用户可以在面板的下拉菜单中无缝切换不同的专属 Agent(例如切换到“库存管理 Agent”),在不离开当前工作流的情况下获得上下文相关的帮助。
 夜雨聆风
夜雨聆风