 夜雨聆风
夜雨聆风
对于OpenClaw-RL的通俗概括表达:每一次你跟AI的交互,其实都在产生一个免费的“下一状态信号”(next-state signal),而这些信号完全可以直接拿来在线训练和改进AI本身!
以前我们训练Agent要么靠人工标注,要么靠模拟环境 rollout 成千上万次。现在这篇工作告诉你:你平时跟AI聊天、让它写代码、操作终端、点GUI、调用工具……这些日常使用行为本身就是最真实、最优质的训练数据。
他们把这个想法做成了一个叫 OpenClaw-RL 的框架,而且开源了(GitHub: Gen-Verse/OpenClaw-RL:https://github.com/Gen-Verse/OpenClaw-RL mark下: 3.5k until now)。
为什么以前的Agent RL系统做不到“越用越好”?
大多数现有的Agent强化学习系统把“训练”和“服务”严格分开:
训练阶段:用模拟环境或离线数据rollout 服务阶段:冻结模型,只推理不更新
结果就是:用户越用越觉得它笨,它却学不到任何东西。
而OpenClaw-RL的核心设计是异步四组件解耦架构,让训练和服务彻底并行:
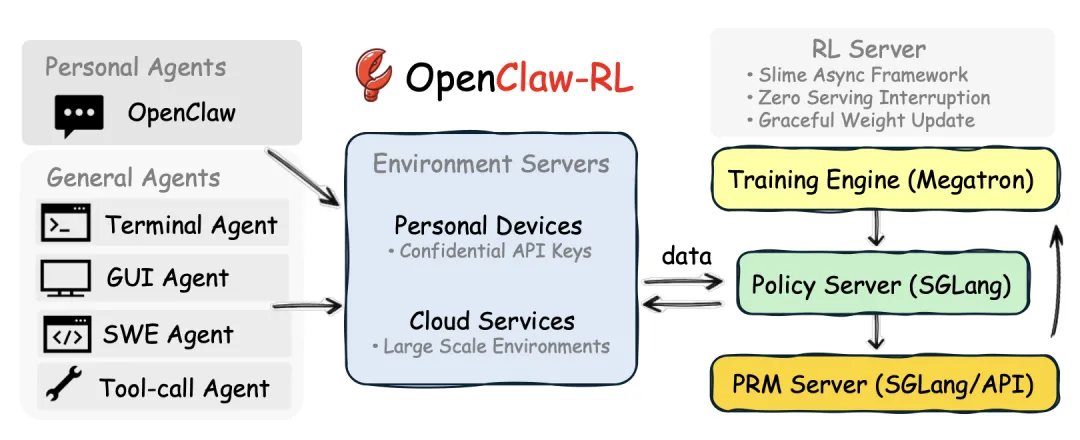
图:OpenClaw-RL整体基础设施一览。环境服务器、PRM过程奖励裁判、Megatron训练引擎、SGLang推理服务,四者异步协作,零协调开销
OpenClaw RL基础设施概述图,展示出交互流来自两种智能体类型:
托管在个人设备上的个人智能体Personal Agent(会话式、单用户)
托管在云服务上的通用智能体General Agent(终端/GUI/SWE和工具调用智能体)
应用于个人智能体(Personal Agent),OpenClaw RL使智能体能够通过使用来改进,从用户的重新查询、更正和显式反馈中恢复会话信号。应用于通用智能体(General Agent),相同的基础设施支持跨终端、GUI、SWE和工具调用设置的可扩展RL。
收集到的样本流入我们基于异步黏液框架(Slime Framework)构建的强化学习服务器,该框架由四个解耦的组件组成:
环境服务器(Environment Servers):
负责托管和管理所有代理的交互流(personal agents + general agents),收集真实的“下一状态信号”,这是整个在线训练的数据源头。它是“数据采集与环境桥接”层,把用户聊天回复、终端输出、GUI变化、工具调用报错等下一时刻的真实反馈结构化后源源不断送入训练管道。
PRM/奖励判断(PRM/Judge for reward computation):
把下一状态信号转化为训练所需的评估信号(标量奖励)和指令信号(文本提示/hints),为后续的RL和蒸馏提供监督。它是“在线自动评分 + 提炼改进方向”的裁判,决定“这次回答是变好了还是更差了”,并在可能时给出“应该怎么改”的具体建议。
Megatron训练引擎,用于政策培训(Megatron):
消费前面两个组件产出的样本 + 奖励/提示,持续更新策略模型(policy),实现 Binary RL 和 OPD 两种学习路径的结合。它是“后台持续进化的发动机”,利用标量奖励做强化学习(PPO-style),利用文本hints做标记级蒸馏,让模型越用越懂用户。
SGLang推理服务,提供政策服务(Policy Server(SGLang)):
承载当前最新的策略模型,对外提供实时、低延迟的Agent推理服务,同时把交互日志非阻塞地送回训练循环。一句话概括:它是“面向用户的前端大门”,保证用户随时能得到快速响应,而模型在后台悄无声息地升级。
这些组件支持优雅的权重更新,并允许使用任何智能体框架进行训练。个人智能体的环境只是用户的个人设备,这些设备通过HTTP通过机密的API密钥连接到强化学习(RL)服务器。通用智能体的环境托管在云服务上,以实现可扩展的并行化。
流程:用户发消息 → Agent推理回答 → 下一状态(用户回复 / 工具报错 / 终端输出 / GUI变化)立刻进入PRM裁判打分,同时也用来做蒸馏,模型在后台持续更新。
你跟它聊得越多,它就变得越懂你。
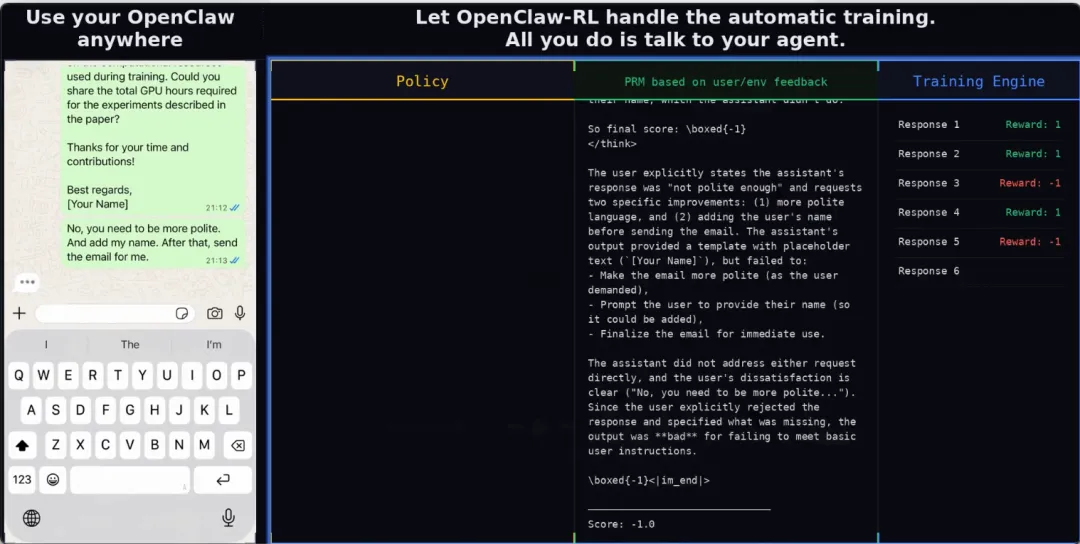
一个非常直观的例子:让AI写作业时“越改越好”
论文里有个很生动的对比实验(模拟学生让AI帮忙写数学作业):
初始版本的AI回答很泛泛、学术味重,用户不满意反复追问/纠正。用了OpenClaw-RL之后,AI在被反复“吐槽”的过程中逐步学会:
用更口语化、亲切的语言 给出具体步骤而不是扔公式 主动问用户哪里不懂

图:只用它,就自己变好。左边是初始版,右边是经过几次用户交互优化后的版本,语气和质量差异非常明显
这基本就是“越用越聪明”的真实写照。
他们是怎么从“下一状态”里榨出训练信号的?
下一状态信号其实包含两种信息:
- 评估信号(evaluative)→ 我这件事干得好不好? → 用PRM过程奖励模型打一个标量分数(Binary RL)
- 指令信号(directive)→ 我到底应该怎么改才对? → 用Hindsight-Guided On-Policy Distillation(OPD)从用户后续的纠正/重问/补充说明里提炼出标记级(token-level)的优势监督
两种信号结合使用,效果最好:
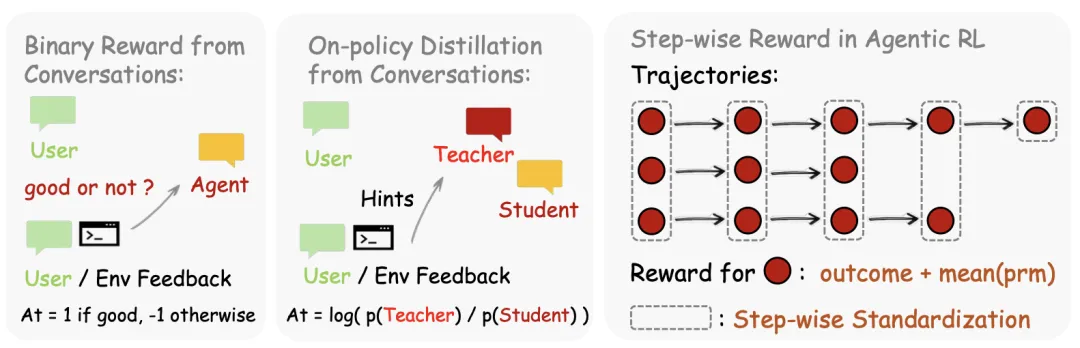
图:Peronal Agent的优化方法总览。Binary RL提供标量奖励,OPD提供更精细的标记级方向监督,二者结合提升最大
不只个人聊天,终端/GUI/SWE/工具调用也能一起训!最酷的一点是:这个框架是统一的。
不管你的Agent是:
在聊天界面陪你水群 在终端敲命令 操作电脑GUI 修GitHub上的bug(SWE-Bench) 调用各种工具(Tool-call)
产生的下一状态信号都可以丢进同一个训练循环。
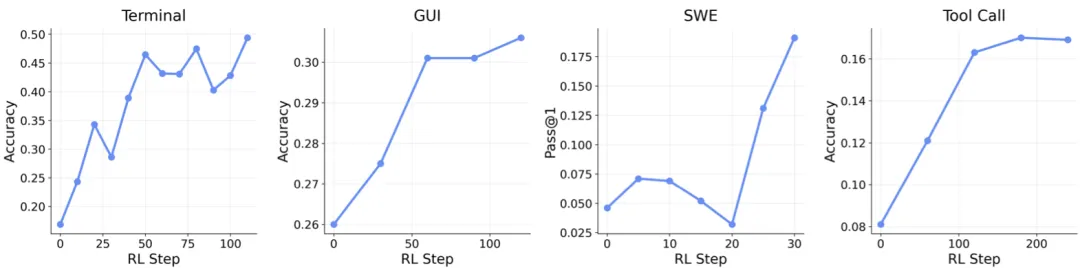
图:同一个框架支持跨终端、GUI、SWE、工具调用等各种通用Agent的大规模可扩展强化学习。
他们通过实验表明:框架可以处理各种现实世界的设置,包括终端、GUI、SWE和工具调用代理,并在不同模型大小和模式之间实现大规模环境并行化。在广泛使用的真实世界代理设置中进行实验,包括终端、GUI、SWE和工具调用场景(如上图)。大规模环境并行化进一步提高了我们RL训练的可扩展性。具体来说,在RL培训期间,我们使用128个并行环境用于终端代理,64个用于GUI和SWE代理,32个用于工具调用智能体。过程奖励(process reward)在长时序任务上特别有用,能显著提高成功率。
总结
OpenClaw-RL 把“使用”和“训练”的边界彻底打破了。以后你骂AI、嫌它笨、反复改提示词,其实都是在帮它在线进化。
这可能就是未来个人AI助手真正的闭环进化路径:不用特意收集数据,不用跑昂贵的离线强化学习RL,你越日常用它,它就越变成“懂你的那一个”。
https://arxiv.org/pdf/2603.10165
https://github.com/Gen-Verse/OpenClaw-RL
