 夜雨聆风
夜雨聆风一、问题:AI 的"失忆症"
你有没有遇到过这种情况?
和 AI 聊了一个下午,讨论了项目方案、定了技术选型、甚至聊到了你的偏好。
第二天再打开对话,它问你:
你好,我是 AI 助手,有什么可以帮你?
一切归零。
这不是 AI 的错。是 context 上下文窗口的限制。
两种记忆
人的记忆分两种:
- 短期记忆
工作记忆,容量有限,持续几秒到几分钟 - 长期记忆
永久存储,容量近乎无限
AI 也一样。
context 上下文窗口是 AI 的"工作内存",但它没有"硬盘"。
对话一结束,工作内存清空。下次见面,它不认识你。
二、方案:两层记忆架构
OpenClaw 的解决方案很直接:
给 Agent 加一个"硬盘"。
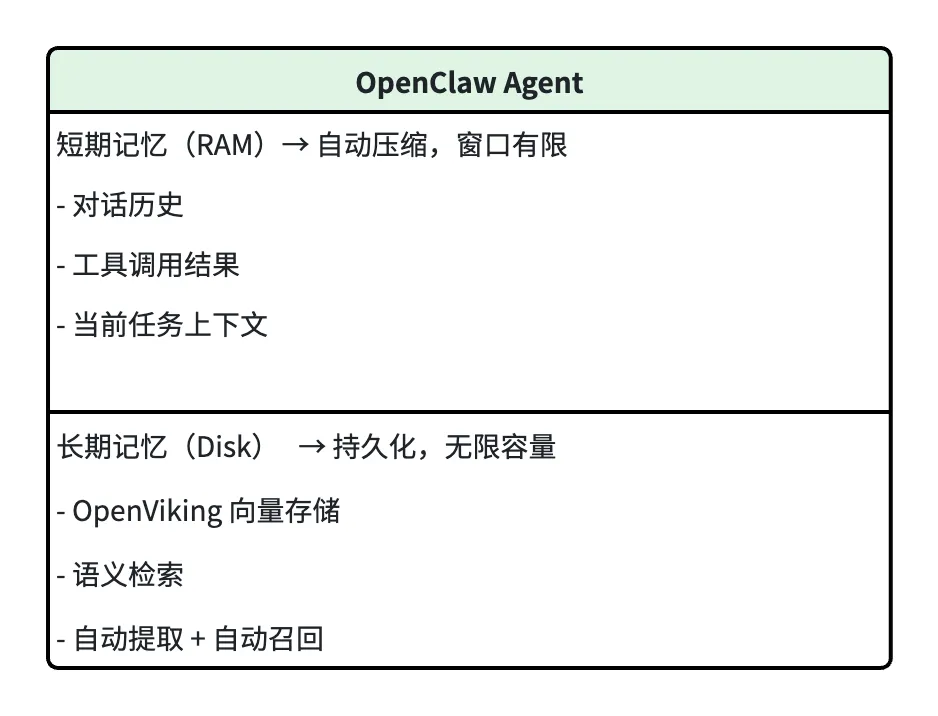
短期记忆让 Agent 能对话,长期记忆让 Agent 能成长。
三、OpenViking:记忆系统的核心
OpenViking 是 OpenClaw 官方的记忆插件。
它做了三件事:
1. 向量化存储
把文本变成向量,存进向量数据库。
"用户偏好 Python,不喜欢 JavaScript" ↓ embedding[0.12, -0.34, 0.56, ..., 0.78] # 512 维向量 ↓ 存储sqlite-vec / FAISS / 云端向量库2. 语义检索
用户说:"上次那个项目"
系统搜索向量库,找到相关记忆。
不需要精确匹配。
"上次那个项目" ≈ "3月15日讨论的数据分析平台"
3. 自动闭环
这是最关键的部分。
Auto-Capture(自动捕获):对话结束,自动提取有价值的记忆
Auto-Recall(自动召回):用户提问前,自动注入相关记忆
用户提问 → 自动召回 → 注入上下文 → 模型回答 ↓对话结束 → 自动捕获 → 提取记忆 → 写入向量库自动召回 + 自动捕获 = 记忆闭环
用户无感知。AI 自己"记住"了。
四、实战:安装与配置
OpenViking 提供了一键安装脚本,支持三种部署模式:
| 本地部署 | ||
| 远端连接 | ||
| 火山引擎 ECS |
快速安装
方式一:npm 安装(推荐,全平台)
npm install -g openclaw-openviking-setup-helperov-install方式二:curl 一键安装(Linux / macOS)
curl -fsSL https://raw.githubusercontent.com/volcengine/OpenViking/main/examples/openclaw-plugin/install.sh | bash安装助手会自动:
检测 Python / Node.js 环境 提示输入火山引擎 Ark API Key 生成配置文件 ~/.openviking/ov.conf配置 OpenClaw 插件
启动与验证
# 加载环境变量并启动source ~/.openclaw/openviking.env && openclaw gateway# 验证记忆功能已启用openclaw status# Memory 行应显示:enabled (plugin openviking)完整安装指南:OpenViking 官方文档
⚠️ 兼容性提示:OpenClaw
2026.3.12+存在已知兼容性问题,可能导致对话卡死。如遇到此问题,临时回退到2026.3.11:npm install -g openclaw@2026.3.11
五、零成本方案:Hugging Face Space
Embedding API 要钱?
用 Hugging Face Space,免费。
方案对比
| HF Space + BGE | 完全免费 |
五分钟搭建
1. 创建 Space
访问 https://huggingface.co/new-space
SDK:Docker Hardware:CPU(免费)
2. 添加三个文件
创建 Dockerfile、requirements.txt、app.py:
Dockerfile
FROM python:3.10-slim# 设置工作目录WORKDIR /app# 复制依赖文件并安装COPY requirements.txt .RUN pip install --no-cache-dir -r requirements.txt# 复制应用代码COPY app.py .# 创建非 root 用户运行 (Hugging Face 安全要求)RUN useradd -m -u 1000 userUSER userENV HOME=/home/user \ PATH=/home/user/.local/bin:$PATHWORKDIR $HOME/appCOPY --chown=user . $HOME/app# 暴露端口并启动服务EXPOSE 7860CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]requirements.txt
fastapiuvicornsentence-transformerspydanticapp.py(带 Token 认证)
import osfrom fastapi import FastAPI, HTTPException, Depends, statusfrom fastapi.security import HTTPBearer, HTTPAuthorizationCredentialsfrom pydantic import BaseModelfrom typing import Union, Listfrom sentence_transformers import SentenceTransformerimport uvicornapp = FastAPI(title="Embedding API with Auth")# 1. 实例化 HTTPBearersecurity = HTTPBearer()# 2. 从环境变量读取预设的 TokenEXPECTED_TOKEN = os.getenv("API_TOKEN", "default-secret-token")# 3. 定义鉴权依赖函数def verify_token(credentials: HTTPAuthorizationCredentials = Depends(security)): """校验传入的 Bearer Token 是否合法""" if credentials.credentials != EXPECTED_TOKEN: raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Invalid authentication token", headers={"WWW-Authenticate": "Bearer"}, ) return credentials.credentials# 加载模型MODEL_NAME = "BAAI/bge-small-zh-v1.5"model = SentenceTransformer(MODEL_NAME)class EmbeddingRequest(BaseModel): input: Union[str, List[str]] model: str = "bge-small-zh-v1.5"# 4. 在接口的 dependencies 中注入鉴权函数@app.post("/v1/embeddings", dependencies=[Depends(verify_token)])async def create_embedding(request: EmbeddingRequest): texts = [request.input] if isinstance(request.input, str) else request.input embeddings = model.encode(texts, normalize_embeddings=True).tolist() data = [ {"object": "embedding", "embedding": emb, "index": i} for i, emb in enumerate(embeddings) ] return { "object": "list", "data": data, "model": request.model, "usage": {"prompt_tokens": 0, "total_tokens": 0} }@app.get("/health")def health_check(): return {"status": "ok"}3. 推送,等待构建完成
4. 配置 OpenViking
"embedding": { "dense": { "provider": "openai", "api_base": "https://your-username-bge-embedding.hf.space/v1", "api_key": "your-api-token", // 可选,如设置了 API_TOKEN 环境变量 "model": "bge-small-zh-v1.5", "dimension": 512 }}api_key 说明:如果你在 HF Space 设置了
API_TOKEN环境变量,需要在配置中添加对应的api_key。如果未设置认证,可省略此字段。
搞定。
记忆系统不再依赖付费 API,个人开发者零成本使用。
六、高级功能:为什么它比你想的更强
混合检索:Dense + Sparse Vector
纯向量检索有个问题:
擅长"意思是这个",但不擅长"精确匹配 ID/代码"
比如搜索 sessionKey = "agent:main:feishu",向量可能找不到。
因为语义上它和其他 sessionKey 太像了。
OpenViking 的解决方案:混合向量存储
存储层:├── dense_vector # 稠密向量,语义相似└── sparse_vector # 稀疏向量,关键词匹配索引类型:flat_hybrid(自动混合)Dense vs Sparse vs BM25 对比:
| 原理 | |||
| 语义理解 | |||
| 关键词匹配 | |||
| 存储成本 | |||
| 适用场景 |
Sparse Vector 是 BM25 的"神经网络升级版"——既保留关键词精确匹配能力,又能学习词项重要性,效果更好。
检索流程:
Query → Intent Analysis(LLM 意图分析) → Hierarchical Retrieval(目录递归) ├─ 向量定位高相关目录 └─ 递归精细检索 → Rerank(重排序) → Results两全其美:语义理解 + 关键词精确匹配。
这是 OpenViking 内置能力,无需额外配置。
时间衰减:新信息更重要
你有 100 条记忆,今天的和去年的,哪个更相关?
时间衰减算法:
decayedScore = score × e^(-λ × ageInDays)新信息自然排名更高。
Session 隔离:安全第一
一个 Agent 服务多个用户,会不会串话?
不会。
sessionKey = agent:<id>:<channel>:<type>:<peer>示例:agent:main:feishu:dm:user123 # 私聊agent:main:feishu:group:oc_xxx # 群聊不同的 sessionKey = 不同的对话宇宙。
sessionKey 是上下文的宇宙边界,正确的隔离配置是安全的基础。
七、对比:为什么选 OpenClaw + OpenViking
| OpenClaw + OpenViking | ||
我的选择理由:
- 零依赖
不需要 Redis、PostgreSQL,文件系统就是数据库 - 可调试
JSONL 文件,人类可读 - 免费可用
HF Space 托管 Embedding,成本为零 - 安全隔离
Session 机制天然防止信息泄露
八、总结
AI Agent 的记忆问题,本质是存储问题。
context 上下文窗口是工作内存,会清空。
OpenViking 是硬盘,永久保存。
配置五分钟,Agent 从"失忆"变"有记忆"。
更关键的是:这套方案免费可用。
HF Space 托管 Embedding 模型,个人开发者零成本体验。
短期记忆让 Agent 能对话,长期记忆让 Agent 能成长。
给你的 Agent 装个"硬盘"吧。
相关资源
OpenClaw 文档 OpenViking GitHub BGE Embedding 模型
— 完 —
