 夜雨聆风
夜雨聆风
本期我们来聊聊,在同等参数规模,甚至同一个AI模型下,当我们选择了不同的底层架构和推理工具,到底能让它的速度相差多少?
这个话题在我做Mac mini开箱时,曾简单地演示过。但在当时,刚刚接触AI模型,对于不同AI模型、以及同一AI模型的规模、架构、量化格式等等,这些参数之间的区别,并不是很清楚。
当然,现在也不能说就很了解,只不过因为想要部署OpecClaw的原因,对此多花了一点时间学习。
然后就发现,对于同一个AI模型,当调整了以上一些因素,内容生成速度会有翻倍、甚至4倍的增长。所以,就和大家来分享一下,也算是对去年开箱视频中AI模型体验的一个内容补充。
一、演示设备和模型
首先,先和大家介绍下我用过的设备和AI模型。
电脑我用的是Mac mini M4版,内存是32G。
AI模型用的是:Qwen3.5-35B-A3B
大家看到35B不要觉得我疯了,而是这个模型很有代表性。
在去年的开箱视频中,我测试了DeepSeek-R1的每秒输出的Token数量,然后说了一个结论:由于14B模型每秒可以输出15个左右的Token,而32B模型只能输出4~5个Tokens,所以建议大家选择14B模型。
但这个结论过于简单。
所以,第二个问题我们来聊聊,如何通过看一些AI模型参数的简单描述,来判断是不是适合自己。
模型参数规模很重要,但除此之外,影响使用体验的因素却有很多,比如模型的底层架构(Dense/MoE)、量化方案(Q4_K_M/S/XS)、运行的推理框架(Ollama/LM Studio/oMLX),以及能力类型(Vision/Tool Use/Reasoning),是否需要“thinking”的过程,是否需要“reasoning”的功能,进而影响首字相应时间以及Token的输出速度等等。
Qwen3.5-35B-A3B这个专家混合模型(MoE),正好能说明一个问题:
“模型大小”并不等于“实际运行负担”。
二、AI模型参数解析
如果你很了解AI模型,可以直接跳到第三部分。
接着,来说下我们要用到的模型和推理引擎。
- 模型名称
Qwen3.5-35B-A3B - 架构类型
MoE (Mixture of Experts / 专家混合) - 模型规模
35B Total / 3B Active (总参 350亿 / 激活 30亿) - 量化方案
4-bit (INT4 / Q4_K_M) - 部署框架
MLX (Apple Silicon Native) / GGUF (llama.cpp)
由于需要对比不同的部署框架,同时为了更好地发挥Qwen3.5-35B-A3B这类专家混合模型的多任务并发能力,所以,在推理引擎方面,除了会用到LM Studio,也给大家推荐一个新的工具:oMLX。大家如果想要详细了解它的技术特点,可以用各种AI总结下,总之就是:专为Apple M芯片设计,做到极致速度,同时独有的SSD KV缓存技术,可以解放内存,非常适合多轮对话的大型任务。
接下来,我们还是拿Qwen3.5-35B-A3B,聊一聊如何根据模型的关键参数,来选择适合自己设备的模型。
2.1 模型名称和参数规模
我们先看Qwen3.5-35B,Qwen是模型的来源,3.5是版本,35B是模型的参数规模。
我们可以通过Qwen、DeepSeek、GML、MiniMax、Gemma、Llama,配合版本号,简单判断各类模型的特点,然后结合自己的使用场景来选择。
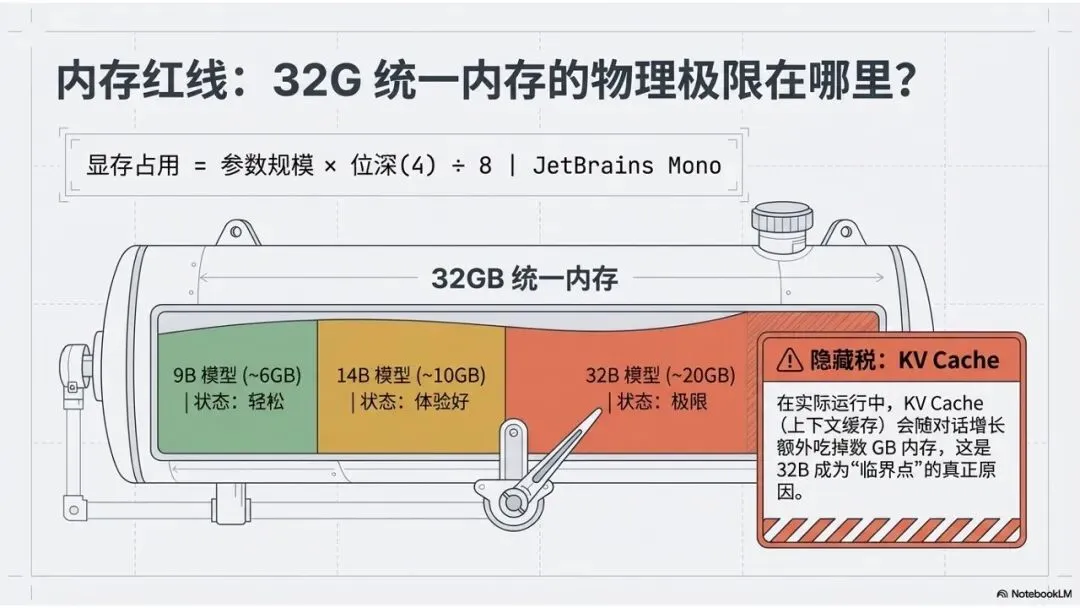
而像9B、14B、32B这样的参数模型,会和显存直接挂钩。当然,由于Apple M芯片是统一内存架构,也就是和内存直接相关。这里有一个简单的换算公式:
内存(模型权重占用)=参数规模✖️每个参数的位深➗8
比如我们32B模型,量化方式是4-bit,所以需要的内存就是:
32✖️4➗8=16G
也就是至少需要16G内存,当然我们跑模型不仅模型需要内存,推理引擎以及图形界面等等也需要。最终换算下来,就会是这样:
| 模型规模 | 4-bit 实际占用 (VRAM) | 32G 内存剩余情况 |
|---|---|---|
| 9B | ||
| 14B | ||
| 32B | ~20 GB |
当然,请注意:在实际运行中,KV Cache(上下文缓存) 往往会随着对话增长额外吃掉数 GB 内存,这也是为什么 32B 模型在 32G 内存上是“临界点”的原因。
2.2 Token/s与内存带宽

模型的参数规模、位深和电脑内存大小决定了模型能不能跑起来。但决定模型跑得快不快,有一个重要因素,就是内存带宽。比如我的Mac mini,用的是标准版M4芯片,内存带宽是120GB/s。
这里可以简单做一个的计算公式:
推理速度(Tokens/s)=内存带宽➗模型运行的实际大小
我们再看刚才的表格:
| 模型规模 | 4-bit 实际占用 (VRAM) | |
|---|---|---|
| 9B | ||
| 14B | ||
| 32B | ~20 GB |
首先说明,这只是简单类比。在实际运行中,推理速度会受到计算单元、KV缓存访问模式、Batch Size(批大小)、并发数、框架优化以及缓存命中率等等多钟因素影响。
这里只是可以粗略理解为:模型越大,占用内存越多,对内存带宽的压力越大,推理速度通常会下降。
所以,当我们想用Mac电脑部署本地AI模型,就要考虑两个因素:M芯片的版本以及内存的大小。
2.3 运行逻辑和稠密程度
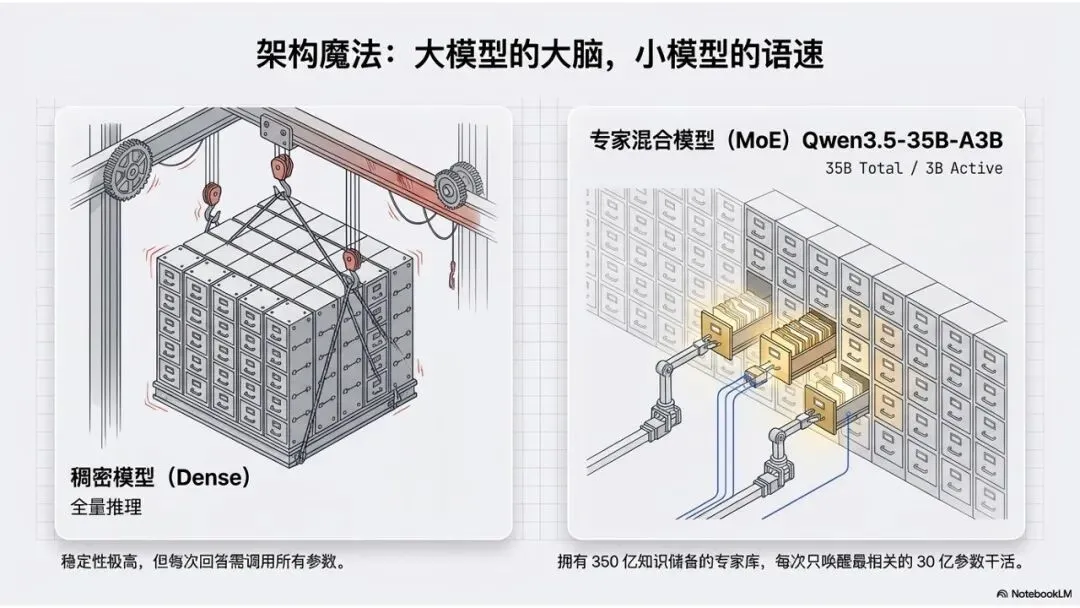
我们看Qwen3.5-35B-A3B这个模型,35B是模型的物理规模,那A3B代表什么?
在这里,A就是英文:activate,激活的意思。
也就是说:虽然这个模型总大小是35B,但每次对话只执行其中3B参数来推理。相当于这个你用的模型智力是35B,但实际只有3B最有关联的参数在运行。
你可以把它想象成一个拥有 350 亿知识储备的‘专家库’,但在你问具体问题时,它只会派出最专业的 30 亿参数‘专家’。既保留了大模型的大脑,又拥有小模型的语速。
所以,这就是我刚接触模型时,然后困惑的一个参数:模型稠密程度。
也就是模型参数分为全量推理的稠密模型(Dense),以及只有少量相关参数参与推理的专家混合模型(MoE)。
两类模型无好坏之分,稠密模型通常在稳定性和一致性上更好,专家混合模型在推理效率和扩展性上更有优势。
只不过,对于我们这种家用电脑以及日常需求来说,专家混合模型会更适合一些。
那么,在标准版的M4芯片上,35B-A3B的理论推理速度是多少?
| 模型规模 | 4-bit 实际占用 (VRAM) | |
|---|---|---|
| 9B | ||
| 14B | ||
| 32B | ~20 GB | |
为了保护下自己,仍然做一个补充说明:我虽然还是用A3B的大小来计算速度,但对于MoE模型来说,激活3B参数,不等于运行时就是3B模型的速度。其中还会受路由开销、内存访问、KV缓存等因素影响。
大家可以记一下这个80Tokens/s,一会在oMLX的基准测试中会发现,单线程任务只有47,而8线程连续批处理任务会高达93。
数据之所以如此,一方面体现了Qwen3.5-35B-A3B专家混合模型在多任务推理方面有更大的发挥空间,另一方面体现出oMLX独有的SSD KV缓存技术优势。当然,除此之外,像M4芯片的L2级缓存等等因素都没有考虑,也会导致数据有所出入。
我觉得,刚接触的朋友可以先建立一个电脑配置与模型参数的简单换算关系。有需要,再去花时间深入研究。
2.4 部署框架与推理引擎
在前面,我们选对电脑、选对模型。同样,选对模型的部署框架和推理工具(引擎)也很重要。
对于Qwen3.5-35B-A3B模型,我使用了两种部署框架,让大家可以直观感受由此对推理速度的影响。
第一种是基于GGUF通用格式的llama.cpp,我用了大家最常用的ollama来下载,同时用Anything LLM来加载,方便展示相关数据。
第二种是对Apple M芯片专门优化的MLX框架,我会分别用LM Studio和oMLX来演示。
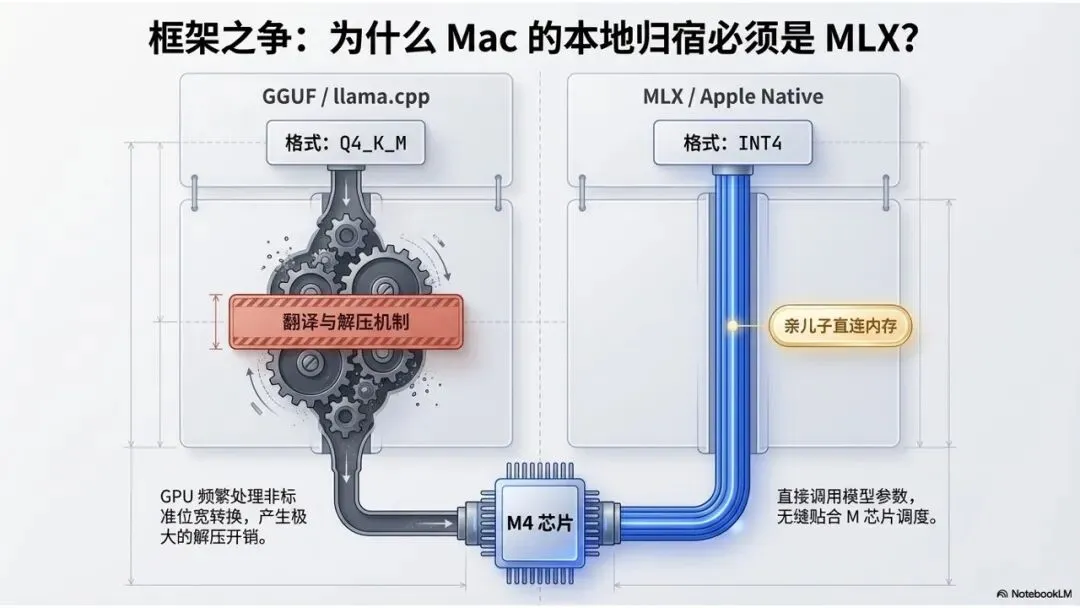
这里需要说明的是,虽然都是4-bit的Qwen3.5-35B-A3B模型,但GGUF和MLX的量化精度还是有区别的。在量化精度方面:
GGUF格式的典型代表Q4_K_M,这种框架属于对关键部分进行6-bit量化,非关键部分保持4-bit。由于采用了混合精度,GPU 在计算时需要频繁进行‘非标准位宽’的转换,这种解压开销在非原生支持的框架下会显著拖累速度
MLX则是INT4(全量4-bit),可以让Apple M芯片直接调用模型参数,无需“寻找”和“翻译”。它可以让Mac电脑运行模型时,内存访问效率更高,调度也更贴合M芯片。
这也是Mac电脑为什么要首选MLX模型的原因之一。
三、模型部署对比测试【详见视频】
在这次对比测试中,我四个推理工具,分别是Ollama、Anything LLM、LM Studio和oMLX。
下载的模型有两个,分别是GGUF和MLX的Qwen3.5-35B-A3B 4-bit。
测试的问题主要分三个方面:生成速度测试、首字响应测试和多轮重载测试。
最后,我会补充一个测试,由于我选择本地部署模型的目的之一,就是使用OpenClaw。所以,就对比下Qwen3.5-35B与Qwen3-Coder-30B,如果你和我一样,想用OpenClaw开发网页或者应用程序,或许专攻编程类的模型会更好。
3.1 生成速度测试**(Tokens/s)**
测试方法:给它们发送同一个复杂的 Prompt(例如:“请用 Python 写一个完整的贪吃蛇游戏,并详细加注释”),观察后台打印的生成速度。
Ollama: 15.42 t/s LM Studio: 35.06 t/s oMLX: 35.70 t/s
3.2:首字响应时间 / 提示词处理 (TTFT / Prefill)
测试方法:将一篇 大概5000 字的长文档发给它们,要求总结。计算从“按下回车”到“吐出第一个字”等待的秒数。 理论上,这轮测试应该是MLX占优,大家可以感受下。
LM Studio: 略 oMLX: 略
3.3 Agent 多轮重载测试 (Reprefill / 记忆测试)
测试方法:使用附录中的《标准 10 轮高压测试剧本》
是一个模拟 OpenClaw 持续敲代码的场景。 请在一个全新的对话框中,依次发送以下 10 个 问题。 前 9 轮不需要在意它的回答内容,耐心等它生成完即可(这几轮会迅速吃掉大约 10万左右 Token 的上下文)。 - ⚠️ 重点在第 10 轮!
在发送第 10 个 Prompt 的瞬间,立刻按下你的秒表,直到它屏幕上吐出第一个字,记录下这个时间差(TTFT)。
在这轮测试中,除了去看10个问题的生成速度;另外要去看看Token的缓存数量和缓存效率。仅仅10个问题后,就已经有14万Token,缓存了11万Token。这相当于用硬盘空间替代内存,省下了1~3G的空间。【模型参数量越大、量化位数越高(精度越高),加载模型所需的空间以及处理相同数量 Token 产生的动态缓存空间都会更大。】
这里大家要了解一下,固态硬盘的速度是慢于内存,尽量固态硬盘节省了宝贵的内存空间,但却会牺牲一点点推理速度。不过,在多轮的长线问答中,能让系统运营得更加稳定,显然是更划算的。
3.4 oMLX连续批处理基准测试
测试方法:在oMlx的基准测试中,测试Qwen3.5-35B-A3B模型的并发任务推理速度
这轮并发测试中,大家不仅要看Token生成速度,同样要看下首字生成时间。
对我这台32G的标准版M4来说,2X,tg TPS为72.1 tok/s,平均TTFT为4933.2ms,就是一个理想的状态。如果到了4X,平均TTFT就到了9664.7ms,有点得不偿失。
3.5 推理模型真的好吗
测试方法:用Qwen3-Coder-30B测试第一轮问题的速度
最后补充一句,虽然今天我们用 35B 通用版 做了测速,但如果你和我一样,是想在本地跑 OpenClaw 来自动化写代码,那我强烈推荐你把模型换成 Qwen3-Coder-30B-A3B (MLX版)。 通用模型文笔好,但偶尔会给错 JSON 格式让 Agent 崩溃;而 Coder 模型就是没有感情的代码机器,它在 OpenClaw 里绝对不会翻车。
四、小结
好啦,以上就是本期视频的全部内容了。
这个视频我其实做了两次,文案也重新改了好几遍。估计大家从测试中也能看出来。本来我只是想做个一个简单的对比:不同模型、不同工具,到底哪个更快,方便选出最适合的一个,用在OpenClaw本中。
但随后发现,我对AI模型的理解,很多都似懂非懂、似是而非。
前两天我看到,去年的Mac mini开箱视频下,还有人留言,说这个视频帮到了他。
这让我有了一种“负罪感”,也正是在回复这位朋友时,让我坚定了重做视频的决心。
也正是如此,我发现——
AI并不是一个“选对参数就能搞定”的东西,它更像是一整套系统工程。
模型、量化、推理引擎、硬件架构,再结合实际需求,每一个选择,都会影响最终结果。
按说,我应该给出一个“标准答案”:比如日常聊天、分析报告、开发软件等等,什么场景应该选择什么模型,用什么推理工具,配置什么样的电脑。
但真正写完这篇文案,我反而觉得:固执地寻找固定答案,就是一种“执念”。
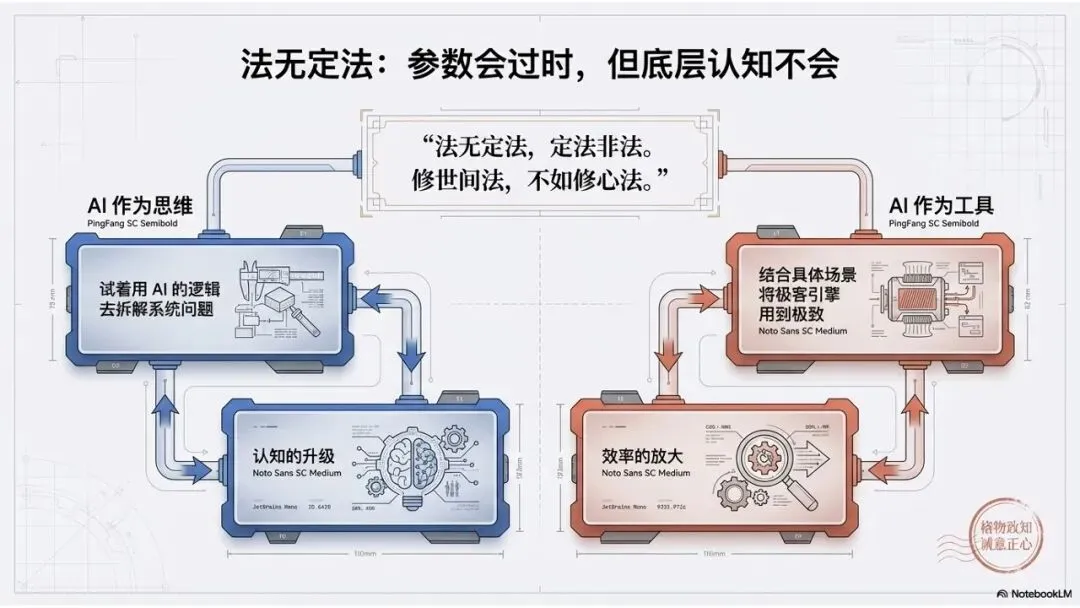
法无定法,定法非法。修世间法,不如修心法
放在AI这里,其实很好理解——
今天最优的模型、最优的框架,可能几个月之后就被替代;
你当前最适合的方案,换一台机器、换一个场景,换一个模型,可能就完全不一样。
所以,比起记住“用哪个”,更重要的是理解:
为什么它在这里更合适。
至于所谓的修“心法”,我的理解就是:
如果把AI当作思维,那就试着用“AI的方式”去理解问题、拆解问题;
如果把AI当作工具,那就把它拿在手中用到极致,去发现问题、解决问题。
前者,是认知的升级;
后者,是效率的放大。
在信息爆炸、思维日新的当下,参数会过时,模型会淘汰,但你的理解却不会。
希望这个视频可以帮得到屏幕前的你。
如果觉得有用的话,可以关注下我的频道
