 夜雨聆风
夜雨聆风3月16日,智谱发布了一款很有意思的模型——GLM-5 Turbo。
有意思的地方在于,它没有追求全知全能。相反,智谱主动"砍掉"了视觉能力,把所有参数和算力都砸向了一个目标:让 AI Agent 长时间、稳定地执行复杂任务。
这背后藏着一个关键信号:大模型竞争的核心指标,已经从单次对话的准确度,转向了长周期任务的执行稳定性。
🎯 一场"断舍离"的豪赌
GLM-5 系列有两个版本。基础版开源,对标 Claude Opus 4.5 和 GPT-5.2。而 Turbo 版闭源,专门为 OpenClaw(外号"龙虾")智能体场景优化。
这个定位很克制。Turbo 版本被严格限制为纯文本输入输出,放弃了视觉、音频生成等多模态能力。智谱的解释很直接:在云端自动化和系统运维的核心逻辑链条中,代码、日志、JSON 才是真正的数据载体。剥离非必要模块,能为长序列逻辑推演保留更多计算裕度。
这让我想到一个类比:通用大模型像是瑞士军刀,什么都能干但都不精;而 GLM-5 Turbo 更像是一把手术刀——功能单一,但在特定场景下锋利无比。
数据也印证了这个判断。在工具调用精确度上,GLM-5 Turbo 的错误率被压缩到了 0.67%。相比之下,第一梯队的其他通用模型,错误率普遍在 2.33% 到 6.41% 之间。
差距不是一点点。
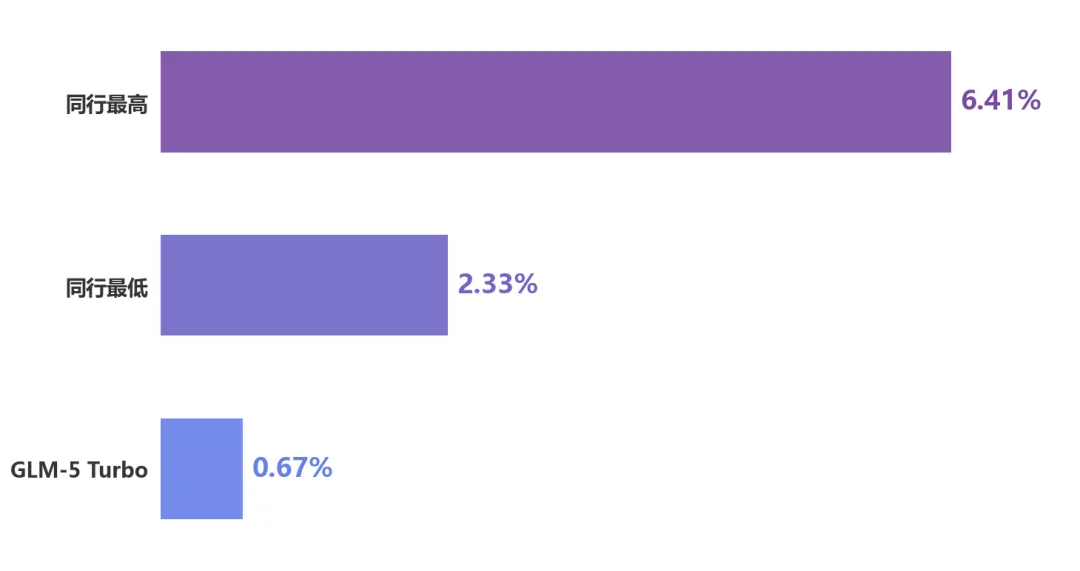
工具调用错误率对比
⚙️ 技术底座:三把斧头撑起"长链路执行"
GLM-5 Turbo 凭什么能做到这么低的错误率?答案藏在三项核心技术里。
第一把斧:MoE 架构与华为昇腾适配
GLM-5 系列采用了混合专家(MoE)架构。总参数量 7440 亿,但每次推理只激活约 400 亿参数。这让它能保持极高的知识容量,同时控制算力消耗。
架构上有个细节值得一提:除了被路由的 8 个专家外,还有一个持续激活的"共享专家"。这个设计解决了传统 MoE 模型中通用常识连贯性断裂的问题。
更关键的是,GLM-5 从第一天就实现了对中国本土 GPU 生态(特别是华为昇腾)的全栈适配。在当前的地缘政治环境下,这点至关重要。
第二把斧:DSA 动态共享注意力
处理 20 万 Token 的超长序列时,传统 Transformer 会遇到显存和算力爆炸的问题。GLM-5 引入了 DeepSeek 首创的 DSA 机制,核心思路是:不计算所有历史序列,而是通过一个独立的索引网络快速扫描关联度,只对最相关的 Top-2048 个 Token 进行精细计算。
配合 KV Cache 的低秩投影压缩,这个架构在维持超长上下文信息保真度的同时,实现了推理资源的指数级下降。
第三把斧:Slime 异步强化学习框架
这是我认为最值得关注的技术突破。
大模型从"具备知识"到"表现卓越",需要强化学习阶段的对齐。但在千亿参数规模上做智能体任务的 RL 训练时,传统的同步策略梯度算法会遇到巨大的效率瓶颈——智能体试错的过程极其耗时,训练引擎如果停机等待数据生成,会导致成千上万张 GPU 闲置。
Slime 框架的解决方案是"解耦":将推理引擎和训练引擎物理隔离到不同的 GPU 集群。推理引擎连续生成交互轨迹,完全无需等待模型更新。当轨迹数量达到阈值,数据才被推送到训练引擎。
这种异步架构虽然释放了算力,但也带来了策略滞后的风险。团队通过直接双边重要性采样和 Token 级别截断机制来应对,将策略更新比率限制在信任域内。
三把斧头合在一起,构成了 GLM-5 Turbo 能够支撑高吞吐量、长链路执行的算力基础。

GLM-5技术底座:三把斧头撑起长链路执行
🦞 OpenClaw:一个开源生态的野蛮生长
GLM-5 Turbo 的发布不能脱离 OpenClaw 来看。
OpenClaw 是一个开源的 AI Agent 框架,自 2026 年 1 月推出正式版以来,GitHub 星标数已经突破 28 万,成为全球开发者社区最瞩目的项目之一。技术极客圈甚至把部署 OpenClaw 戏称为"养虾"。
它的架构高度模块化:运行环境("虾缸")、推理"大脑"(LLM API)、人格定义(SOUL.md)、记忆中枢(Memory 目录),以及最具扩展性的"技能"插件系统。通过这些技能,OpenClaw 能接管邮件系统、自动代码审查、爬取竞品数据、接入即时通讯工具做自动客服。
数据显示,技能系统的使用比例在极短时间内从 26% 飙升至 45%。这说明 AI 的范式正在从信息检索工具向模块化生产力底座演变。
在 OpenClaw 的五步执行循环(意图解析 → 动作生成 → 系统执行 → 结果验证 → 自我纠错)中,最大的噩梦是"木桶效应":只要在一个微小的 API 参数传递上发生幻觉,整个工作流就会瞬间崩塌。
GLM-5 Turbo 正是在这个痛点上实现了降维打击。
📊 评测数据:长板很长,短板也不短
让我用数据说话。
在 MATH-500 数学推理测试中,GLM-5 获得了 97.4% 的高分,击败了 Claude Opus 4.6。在多语言软件工程基准 SWE-bench Multilingual 中,它以 73.3 分反超了 GPT-5.2(72.0 分)。在长线资源管理测试 Vending Bench 2 中,GLM-5 取得了 $4,432 的高收益,比前代产品接近翻倍。
但冷峻的一面同样存在。
在考验跨学科前沿知识广度的 Humanity's Last Exam 测试中,GLM-5 仅得 10.37%。这种断崖式的成绩落差(数学 97% vs HLE 10%)揭示了一个问题:纯粹的数理推演能力,无法自然泛化为对复杂物理世界的理解。
我的判断是:在真实业务投产前的模型选型阶段,不能盲目迷信单一榜单高分,必须基于全场景进行压力测试。
💰 商业化:涨价背后的财务焦虑
智谱在 2026 年一季度连续两次逆势提价。2 月 12 日,GLM-5 发布时 API 费率上涨约 83%;3 月 16 日,Turbo 版在基础版之上再涨 20%。
为什么敢涨价?看看财务数据就明白了。

智谱财务真相:流血的算力账
2025 年上半年,智谱收入 1.9 亿元,同比增长 325%。但研发支出狂飙至 16 亿元,其中 72% 用于购买和租赁 GPU 算力。收入 1 元,烧 8 元,6 元拿去交电费和显卡钱。结果是半年净亏 18 亿元。
这份流血不止的财务报表,解释了智谱为什么顶着开发者谩骂也要涨价。大模型企业的自救路径,只能拼命提高单位变现率。
但涨价的代价是信任危机。开发者在 Reddit 等论坛抱怨:Turbo 版的流式输出速度仅 25 tps,对挂着 Turbo 名号的模型来说"极其缓慢"。基础版 GLM-5 在某些优化节点能达到 46 tps。有人推测,智谱为了整体吞吐率最大化,可能在服务端限制了单次请求的并发序列数量。
更让开发者不满的是订阅制权益的隐性缩水。MAX 年度订阅计划的年费从 260 美元暴涨至 650 美元,服务量纲却遭遇全方位削减。这种"花更高价格买到更低服务上限"的恶性循环,挫伤了生态建设的信心。
📦 硬件落地:软硬一体化的野心
在涨价争议之外,智谱的硬件布局值得关注。
3 月 16 日,软通动力旗下的 PC 品牌"机械革命"联合智谱,首发了"龙虾盒子"——一台体积仅 0.87 升的微型主机,出厂预装 GLM-5 Turbo,售价 1999 元。
在此之前,想本地运行 GLM-5 级别的模型,需要斥巨资组装搭载双路 RTX 6000 Ada 显卡的工作站。"龙虾盒子"通过软硬件底层打通,把 OpenClaw 框架降维成了一个"插电即用"的商业标准品。
从"云端订阅"走向"模型+算力+终端"的软硬一体捆绑,标志着大模型厂商开始抢占物理世界的交互入口。
💡 我的判断
综合来看,GLM-5 Turbo 代表了大模型竞争的一个转折点。
通用大模型追求全知全能的时代正在过去,"降维与特化"将成为下半场的主旋律。GLM-5 Turbo 的破局之道在于敢于承认局限、主动取舍,把宝贵的参数和算力倾注于提升工具调用精确度和长链路执行的鲁棒性。
OpenClaw 模式正在重塑人机交互范式。当 AI 拥有了自主编译代码、调配系统权限、在遭遇 Bug 时不懈查杀的能力,传统 SaaS 应用层将被降维重构。企业 IT 采购目录的核心类目,将从特定的软件转变为全天候在线的"数字职员集群"。
但残酷的算力经济学压力,将彻底倒逼定价模式重构。智谱的涨价与服务降级,戳破了廉价 AI 算力无限充沛的市场幻觉。Agentic 工作流对 Token 的无止境吞噬,使现有云计算架构长期处于高负荷红线。
核心结论:2500 亿港元市值的背后,智谱必须在下一个算力潮汐到来之前,完成跨模态能力融合、国产硬件磨合,以及在开源社区争夺规则制定权。在这场豪赌中,仅靠商业模式创新带来的短期财报粉饰,将在下一轮技术颠覆的巨浪面前暴露本质。
