 夜雨聆风
夜雨聆风OpenClaw-RL的核心价值在于:它能让您的OpenClaw🦞仅仅通过与你日常对话产生的自然反馈(如你的纠正、补充说明或环境报错),就能在后台实时自动更新权重,变得越来越符合您的个性化偏好,并在实际任务中不再犯同样的错误。
谁能用?有两种人。前提是普林斯顿的这套工具是只为开源模型自托管玩家准备的。并且严格限定在CUDA生态内。因为系统需要执行实时的梯度下降操作,所以您必须掌握Agent背后大模型的完整控制权。
那如果我的设备没有cuda怎么办?(假设您用的Mac mini)对于这种情况,官方给的方案是Tinker云端路线,您的Mac只负责运行OpenClaw/OpenClaw-RL的本地代理与控制逻辑,真正的LoRA训练和云端采样由Tinker在它自己的GPU集群上执行。

OpenClaw-RL目前只有上述两种方案,如果您的龙虾🦞只想用闭源API(如Claude-Opus4.6)那这个框架就与您无缘了。明确了环境边界后,接下来,我们将硬核拆解其底层的Binary RL与OPD算法实现。项目地址:https://github.com/Gen-Verse/OpenClaw-RL

论文最核心的判断:数据一直在被浪费
这篇论文最值得您注意的,不是又造了一个PPO变体,而是它对“交互数据”的重新定义。
评价性信号:用户重复问一次,往往说明上一轮没解决问题;测试通过,说明动作有效;stderr、错误trace、lint 失败,说明动作无效或者方向有偏差。
指令性信号:用户说“你应该先检查文件再改”,这不是简单负反馈,而是在告诉模型“该改哪类 token、先后顺序应该怎样”;SWE场景里的diff、编译器诊断、失败日志,也常常隐含类似方向。
研究者认为,这两类信号都天然存在于在线交互里,不需要额外标注流水线。现有系统的问题不是拿不到信号,而是没有把它当成训练目标的一部分。
换句话说,OpenClaw-RL的出发点不是“如何造更多训练数据”,而是“如何把已经存在的数据从上下文恢复成监督”。这是整篇论文最重要的思想支点。
问题建模与信号分类
在OpenClaw-RL的设计中,任何交互流都被形式化为一个马尔可夫决策过程(MDP),定义为四元组 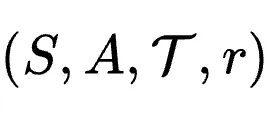 :
:
状态
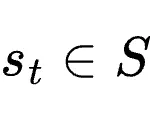 :包含截至第 t 轮的完整对话或环境上下文。
:包含截至第 t 轮的完整对话或环境上下文。动作
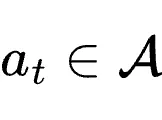 :代理的响应,即由策略
:代理的响应,即由策略  生成的Token序列。
生成的Token序列。状态转移
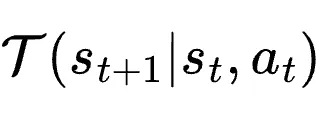 :在给定环境下是确定性的;
:在给定环境下是确定性的;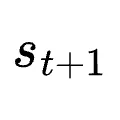 就是跟随在
就是跟随在 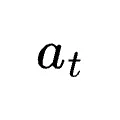 之后的用户回复、执行结果或工具输出。
之后的用户回复、执行结果或工具输出。奖励
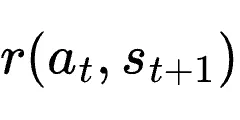 :通过过程奖励模型(PRM)从下一状态信号中推断得出。
:通过过程奖励模型(PRM)从下一状态信号中推断得出。
研究者将 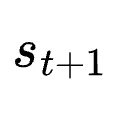 包含的训练信号划分为两类,并针对性地设计了算法:
包含的训练信号划分为两类,并针对性地设计了算法:
评估性信号(Evaluative signals):隐式对前置动作进行评分。例如测试通过或用户重新提问。这构成了密集的逐步奖励。
指导性信号(Directive signals):包含具体的修正方向。例如错误追踪日志或用户明确指出的修改意见,这类信号在Token级别提供了梯度方向。传统的纯量奖励(Scalar rewards)无法利用此类信号。
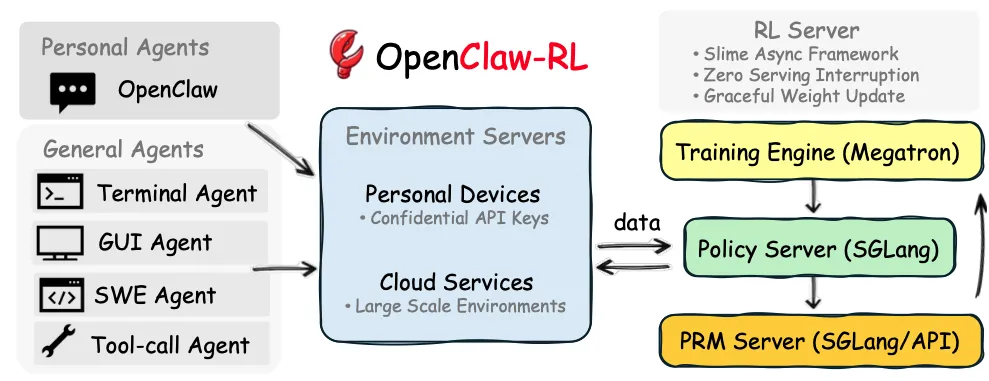
OpenClaw-RL异步系统架构
为了支持从单设备个人代理到云端大规模并发环境的在线强化学习,研究者基于slime框架构建了一个完全解耦的异步流水线。
四大解耦组件
OpenClaw-RL包含四个独立运行、互不阻塞的循环组件:
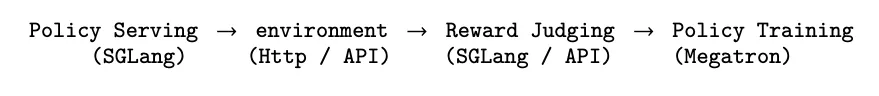
策略服务(Policy Server):基于SGLang部署,通过HTTP/API处理来自环境的推理请求。
环境服务器(Environment Servers):维护交互状态。
奖励裁判(PRM Server):同样基于SGLang或API调用,异步计算前置轮次的奖励。
训练引擎(Training Engine):基于Megatron执行策略的梯度下降。
在这种架构下,模型在服务下一个用户请求的同时,PRM正在并行评估上一个响应,而训练器正在计算梯度并应用更新。这实现了服务零中断(Zero serving interruption),并避免了长周期任务导致的长尾阻塞问题。
环境支持与会话感知
系统支持两种环境拓扑:
私人设备端:使用机密API密钥连接,系统具备“会话感知”能力。API请求被分类为产生训练数据的“主线轮次(Main-line turn)”和仅做转发的“侧线轮次(Side turn,如辅助查询或内存整理)”。
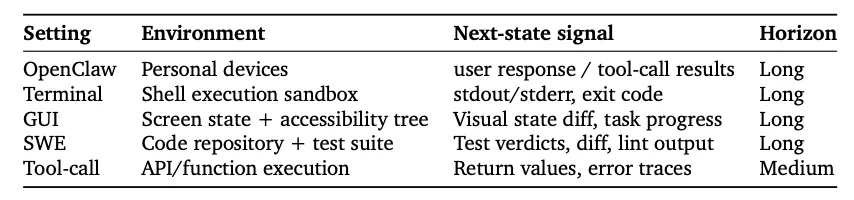
云端大规模并行环境:支持终端(Shell执行沙盒)、GUI(屏幕状态与无障碍树)、软件工程(代码库与测试套件)、工具调用(API执行)四类场景。
非阻塞可观测性
所有交互与评估数据(包括完整消息历史、生成的Token、PRM并行投票得分、提取的提示以及接受/拒绝决策)均通过后台线程以“触发即忘(fire-and-forget)”的模式实时写入JSONL日志。这确保了不会为推理或评估链路引入任何延迟。每次策略权重更新时,系统会自动清除日志文件,以确保收集的样本严格对应单一版本的策略。
算法解析:如何将下一状态转化为梯度
研究者设计了三种机制来处理不同丰富度的反馈流。
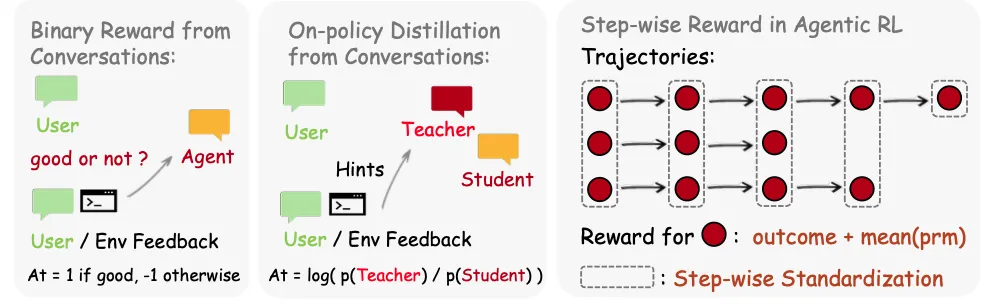
个人代理:二元强化学习(Binary RL)
当信号仅包含“评估性”特征时,系统将其转化为标量过程奖励。
多数投票(Majority Vote)构造PRM:给定动作
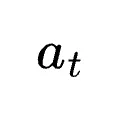 和下一状态
和下一状态 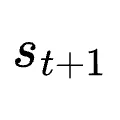 ,PRM评估动作质量并输出
,PRM评估动作质量并输出 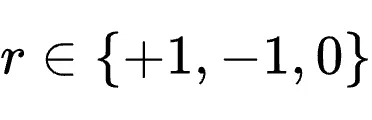 。为了降低方差,系统并行运行
。为了降低方差,系统并行运行 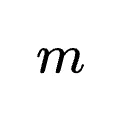 次推理,最终奖励取多数投票结果
次推理,最终奖励取多数投票结果 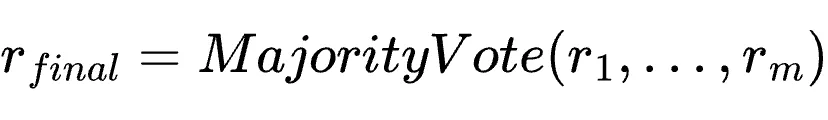 。
。目标函数:直接使用该标量作为优势
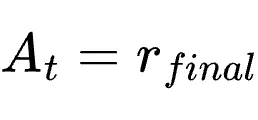 。由于在线流式数据缺乏组结构,无法使用GRPO的组内标准化。采用带有不对称边界的PPO裁剪代理损失:
。由于在线流式数据缺乏组结构,无法使用GRPO的组内标准化。采用带有不对称边界的PPO裁剪代理损失: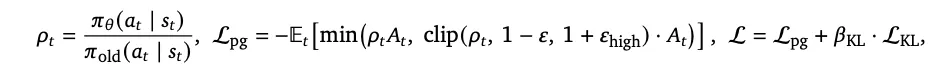
此处超参数设定为
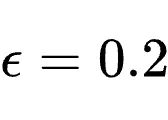 、
、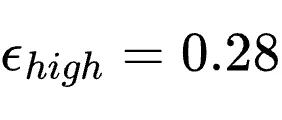 、
、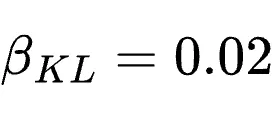 。
。
个人代理:后见之明引导的同策略蒸馏(OPD)
纯量奖励会丢失文本中的“指导性信息”。研究者提出了OPD算法,将下一步状态转化为Token级别的教师监督。具体操作分为四个步骤:
步骤一:后见之明提示(Hint)提取:PRM裁判不仅打分,若得分为+1,还会从冗长嘈杂的
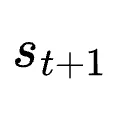 中提取1-3句话的精炼行动指令,并包裹在
中提取1-3句话的精炼行动指令,并包裹在 [HINT_START]...[HINT_END]标签内。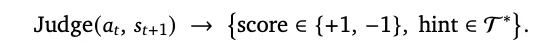
步骤二:提示选择与质量过滤:在所有大于10个字符的正面投票提示中,选择最长(信息量最大)的一个。如果没有满足条件的提示,系统直接丢弃该样本。这种严格的过滤机制用样本数量换取了极高的梯度信噪比。
步骤三:增强教师构建:将提取的提示以前缀
[user's hint / instruction]\n{hint}的形式追加到最后一条用户消息末尾,构建出一个增强上下文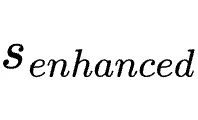 。此时模型处于一种“预先已知修正方案”的教师状态。
。此时模型处于一种“预先已知修正方案”的教师状态。步骤四:Token级优势计算:在
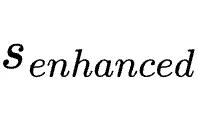 下强制输入原始动作
下强制输入原始动作 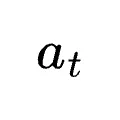 ,获取每个Token的对数概率。优势定义为:
,获取每个Token的对数概率。优势定义为:
若
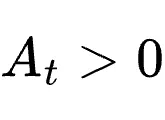 ,说明了解提示的教师认为该Token合理,策略应提升其生成概率;若
,说明了解提示的教师认为该Token合理,策略应提升其生成概率;若 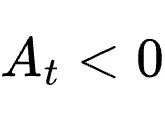 ,则应抑制。这种定向梯度提供了远超单一纯量的高维度修正信息。
,则应抑制。这种定向梯度提供了远超单一纯量的高维度修正信息。
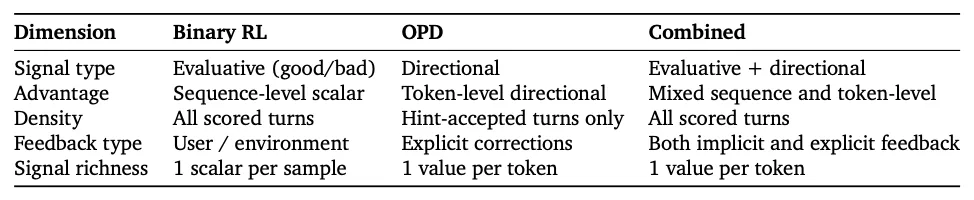
二元RL与OPD的加权联合
Binary RL覆盖面广(接受所有已评分轮次),OPD精度高(仅针对含有明确纠正指令的轮次)。研究者提出共享同一PPO损失函数,直接计算联合优势:
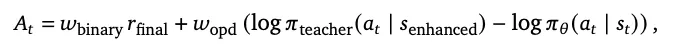
默认情况下,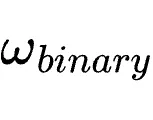 与
与 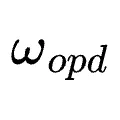 均设为1。
均设为1。
通用代理:结果与过程奖励融合
在长周期代理任务中,纯结果奖励导致梯度极度稀疏。基于RLAnything的经验,研究者将环境提供的可验证结果(Outcome 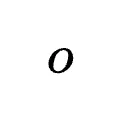 )与PRM给出的密集过程奖励(
)与PRM给出的密集过程奖励(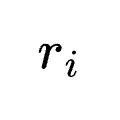 )相加:
)相加:
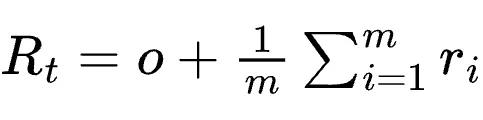
在此场景下,系统将在同一步骤索引(Step index)下的不同样本进行分组,执行组内标准化(Standardization),从而解决状态难以直接聚类的问题。
实验配置与核心数据分析
研究者在两条独立的赛道上对OpenClaw-RL进行了验证:个人代理赛道(验证从对话信号中持续个性化)和通用代理赛道(验证在终端、GUI、SWE、工具调用环境下的扩展性)。
个人代理赛道配置
模拟设定:使用LLM模拟两类用户。一是“希望使用OpenClaw做作业且不被发现使用了AI的学生”;二是“希望OpenClaw批改作业且评论需要具体、友好的教师”。作业数据采自GSM8K。
模型与超参数:策略模型为Qwen3-4B。学习率设为
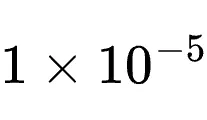 ,KL系数为0,每收集16个有效训练样本即触发一次反向传播。
,KL系数为0,每收集16个有效训练样本即触发一次反向传播。对比结果:在基准得分为0.17的评价体系下,单纯的Binary RL在16步更新后仅达到0.23;单纯的OPD由于样本稀疏,初期表现平缓,但在16步后达到0.72;而加权联合方法(Combined)在16步后取得了0.81的评分,证明了两者的强互补性。
收敛速度:在联合优化下,学生代理仅需36次交互即学会丢弃粗体标记(如
**50%**)并采用自然的段落表述;教师代理仅需24次交互便学会提取学生的中间步骤并附加鼓励性表情符号。
通用代理赛道配置
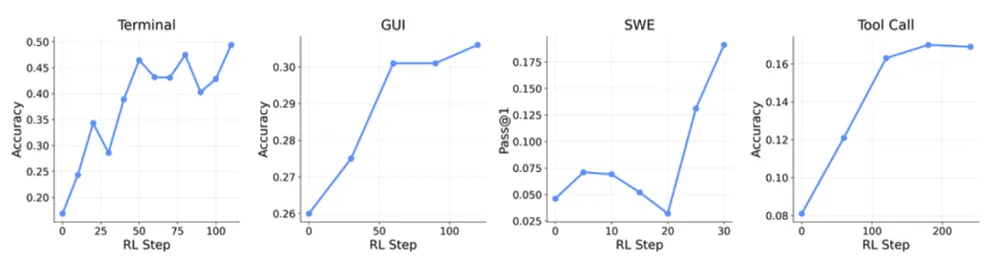
模型与环境:
终端代理:Qwen3-8B,环境SETA RL,最大交互10步。
GUI代理:Qwen3VL-8B-Thinking,环境OSWorld-Verified,最大交互30步。
SWE代理:Qwen3-32B,环境SWE-Bench-Verified,最大交互20步。
工具调用代理:Qwen3-4B-SFT,环境DAPO RL,评估集AIME 2024。
并行度与超参:终端开启128个并行环境;GUI与SWE开启64个;工具调用开启32个。学习率
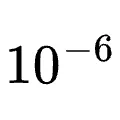 ,KL系数0.01,裁剪率设定为
,KL系数0.01,裁剪率设定为 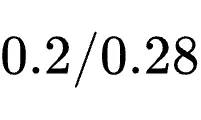 。GUI和SWE每step采样8个任务,terminal为16个,tool-call为32个;每个任务再独立采样8次。
。GUI和SWE每step采样8个任务,terminal为16个,tool-call为32个;每个任务再独立采样8次。奖励消融分析:长周期任务中过程奖励极为关键。在工具调用任务中,整合过程与结果奖励使准确率从0.17提升至0.30;在GUI任务中,准确率从0.31提升至0.33。
核心Prompt工程细节解析
了解模型如何作为PRM进行判决是复现本论文的关键。研究者为不同场景设计了精确的系统提示(System Prompts)。
个人代理:PRM与OPD提示
二元RL裁判:要求模型充当过程奖励模型,观察助手输出与后续用户回复。如果回复好输出
\boxed{1},差则输出\boxed{-1},中立为\boxed{0}。
OPD后见之明提取器:要求模型判断下一状态是否包含了可以改善当前回复的“后见之明”。如果存在,输出
\boxed{1}并在[HINT_START]...[HINT_END]内提供具体且可执行的1-3句话提示;否则输出\boxed{-1}并禁止提供提示。
复杂代理场景的PRM规则
对于通用代理,裁判必须依据具体的环境反馈进行推理:
终端环境:输入任务指令、历史记录(包含工具调用与结果)以及当前动作。必须满足全部条件(动作推动任务、工具格式有效、工具使用适当、结果显示进展)才给予+1。若出现格式损坏(无效JSON解析错误)或错误无关的使用,则判定-1。
GUI环境:除了文本历史,系统需要向PRM注入“动作执行后的下一帧视觉观察(Next observation after executing this action)”。PRM需核对动作是否在视觉上产生了实际效果,若造成了倒退或只是无效操作(no-op),则打分为-1。
SWE代理:输入问题描述、历史摘要、当前包含bash命令的动作以及返回码(returncode)与标准输出。如果返回码提示非预期错误(如路径错误、语法错误)、代理在重复之前失败的命令(兜圈子)、或者修改引入了明显的Bug,PRM必须严格判定为-1。
总结
OpenClaw-RL证明了一个核心结论:每一次代理交互生成的信号都是流无关(Stream-agnostic)的,单一策略可以完全依赖这些伴生数据在同一个循环中进行同步学习。通过在架构层实现四路解耦异步,在算法层引入Binary RL提取评估纯量与OPD提取Token级方向指导,该系统彻底摒弃了对离线预收集数据的依赖。您部署的代理,只需处于正常的交互使用中,就能在长周期工具执行与个人风格偏好上实现全自动的策略进化。
未来已来,有缘一起同行!
<本文完结>
转载请与本喵联系,私自抓取转载将被起诉
