 夜雨聆风
夜雨聆风用 OpenClaw 的人,大概都遇到过这种时刻。
项目刚聊顺,前面明明已经定过技术路线、文件路径、一些很关键的约束,结果聊着聊着,模型像是突然断片了。你不得不停下来,把之前说过的话再复述一遍。不是它不聪明,是上下文窗口这件事,确实一直卡着这类 AI 工具的脖子。
最近 OpenClaw 社区里有个挺值得关注的开源插件:lossless-claw。它做的事不花哨,但很实用——不是让模型“多记一点”,而是直接换掉原来那套越聊越丢信息的上下文管理办法。
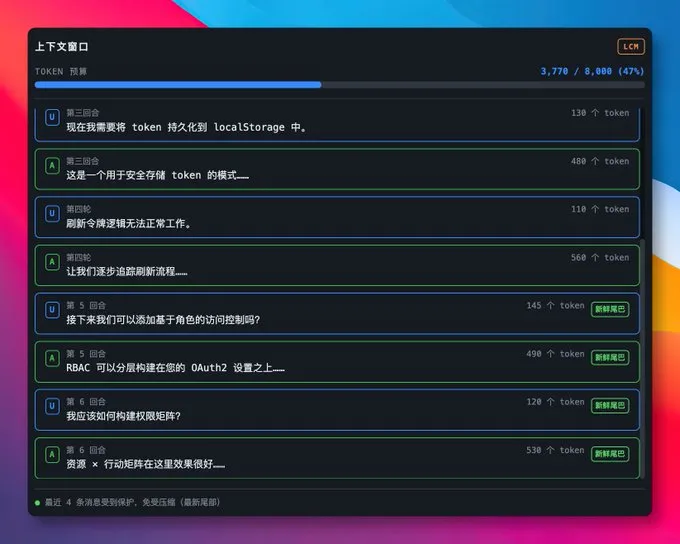
仓库 README 里写得很直白:它会把每条消息持久化进 SQLite,然后把旧消息逐步压成多层摘要,最后形成一个 DAG 结构;新一轮对话时,再把“摘要 + 最近原文”一起组装进上下文里。这样做的意思其实就一句话:旧内容不会直接被扔掉。
这点挺关键。很多人以为所谓“上下文优化”,无非就是把旧聊天记录缩一缩、糊成一段总结。但真正难受的地方恰恰在这儿:一旦压缩得太狠,那些当时看着不起眼、后来又特别要命的小细节,往往最先消失。
lossless-claw 的思路更像是在后台给对话做档案整理。底层保留原始消息,上层不断生成更高层级的摘要,真要回头翻旧账时,还能通过 lcm_grep、lcm_describe、lcm_expand 这几个工具,把压缩过的历史重新掀开来看。
我觉得它最打动人的地方,不是“树状摘要”这种术语本身,而是它终于承认了一件事:复杂项目不是一次性问答,而是连续协作。 你和 AI 真正痛苦的,不是某一次回答不够好,而是它第二天像没参与过这个项目一样。
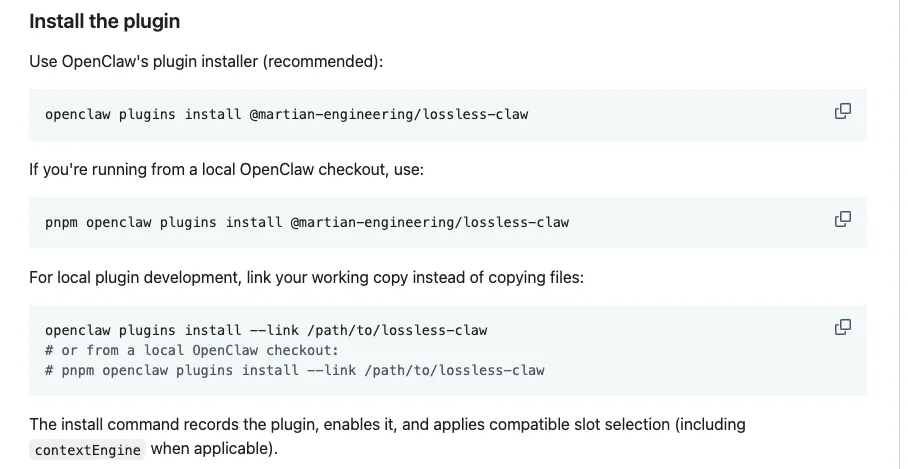
安装也不折腾。README 给的推荐方式就是一条命令直接装进 OpenClaw 插件系统里;配置上还能自定义最近保留多少条原始消息,以及在什么阈值下触发压缩。甚至连用于生成摘要的模型,也可以单独指定成更便宜、更快的那一个,不用非拿主力模型去干这种后台活。
当然,它也不是魔法。GitHub 讨论区里,作者自己说得很坦白:这套东西本质上是在把上下文管理从“一次性压缩”改成“持续整理”,目标是让对话长期维持在可控 token 范围内,同时尽量不丢信息。说白了,它解决的不是 AI 能不能理解世界,而是 AI 至少别先把你们昨天刚定好的东西忘了。
所以,如果你只是偶尔拿 OpenClaw 问两句,可能没感觉。但只要你已经开始拿它写代码、跑任务、做长链路项目,这类“记忆层”插件基本会越来越像刚需。模型能力大家都在卷,真正影响体验的,很多时候反而是这些不起眼的基础设施。
AI 不怕偶尔答错。 更怕的是,它一边很自信,一边把前情提要忘了。
而 lossless-claw 这种插件,至少是在认真补这个洞。
GitHub地址:martian-engineering/lossless-claw
