 夜雨聆风
夜雨聆风大家好,我是小斐呀。
摸索了 OpenClaw 一段时间,上篇文章我在企业组织内新建了个运维机器人,主要对接我日常的运维工作,最近刚好有个很急切的需求就是在 VMWare 集群中经常需要新增虚拟机和删除虚拟机,这个动作实在是比较频繁,还有就是有些时候在路上或者身边没有电脑的场景中,我应该如何快速响应需求呢。
毕竟有些时候研发就是个急性子,非得马上就要,为了随时 7*24 小时响应需求,即使我在外面吃饭,我也可以发个话,然后就自动帮我创建好了,并且把这些信息发给需求人。
OpenClaw 不就是干这个事的吗,但是我需要单独自行开发一套关于 VMWare 的 Skills ,然后给小龙虾装个比较好使的脑子 LLM 这样可以很完美的搞定我这个场景,并且后续还有扩展空间,我只需要对 Skills 扩展即可。
技能实战
使用 Skills 之前我们需要明白,为何使用 Skills 有什么优势呢?
那首先我们需要明白 AI Agent 中, Skills 本质上是 AI 的 手 和 工具箱 可以扩展 AI Agent 能力,所以它有如下优势:
为特定领域任务定制能力 创建一次,自动使用 可组合 Skills构建复杂工作流
当然最核心的还是节省上下文的消耗,实际就是 token 成本降低。
工作原理
上面是怎么实现的呢,按照没有 Skills 的前提下,模型需要实现很多能力,必须价值你所有的上下文以及代码,但是有些能力是不需要加载的,现在 Skills 就通过 渐进式披露 这个技术实现,好像有点不说人话,我们先来看下一个 Skills 的基本结构:
my-skill/
├── SKILL.md # 必需:技能说明 + 元数据
├── scripts/ # 可选:可执行代码
├── references/ # 可选:参考文档
└── assets/ # 可选:模板或资源
我们按照 LLM 对文件加载分级策略来做个分层:
| 级别 1:元数据 | name 和 description,用于技能识别和快速索引 | ||
| 级别 2:指令 | SKILL.md | ||
| 级别 3+:资源 |
元数据级别(Level 1)
始终加载,保证系统可以快速识别技能。 信息量很小,不占用太多 Token。
指令级别(Level 2)
只有当技能被触发时才加载,可以包含较大文本( SKILL.md),保证技能逻辑完整。
资源级别(Level 3+)
不加载到对话上下文中,通过脚本/外部文件按需调用。 可存放模板、数据文件、可执行脚本等。
就是这个结构构成了 渐进式披露 的基本原则。
如何使用
在 OpenClaw 中,我们按照一个 Agent 处理一类事项,使用单独的 Agent 处理某类职能事项。
这里我就新建了一个单独的 Agent 就叫做 infra-ops 主要是对基础设施运维的一些实践。
现在我需要在 vCenter 上对内部虚拟机做资源调配到资源的全生命周期管理等,传统操作就是在 vCenter 控制台上操作点点点,第二个就是很多内部 API 集成到某个内部控制台上最终还是在页面点点点,所以这里就有两个方案:
第一个就是完全在自己内部平台集成 AI然后把需要的内容填写到内部参数中调用第二个就是自己写 Skill把这些对资源做生命周期管理的动作都原子利用Agent按需调用
我的方案肯定是通用型方案,把所有的动作都原子化啊,通过 OpenClaw 进行调度管理,在钉钉或者飞书里面建立运维机器人对话窗口,日常需求直接丢进去。
我这里自己先手写了个 vcenter-ops 的 Skill 目前主要功能如下:
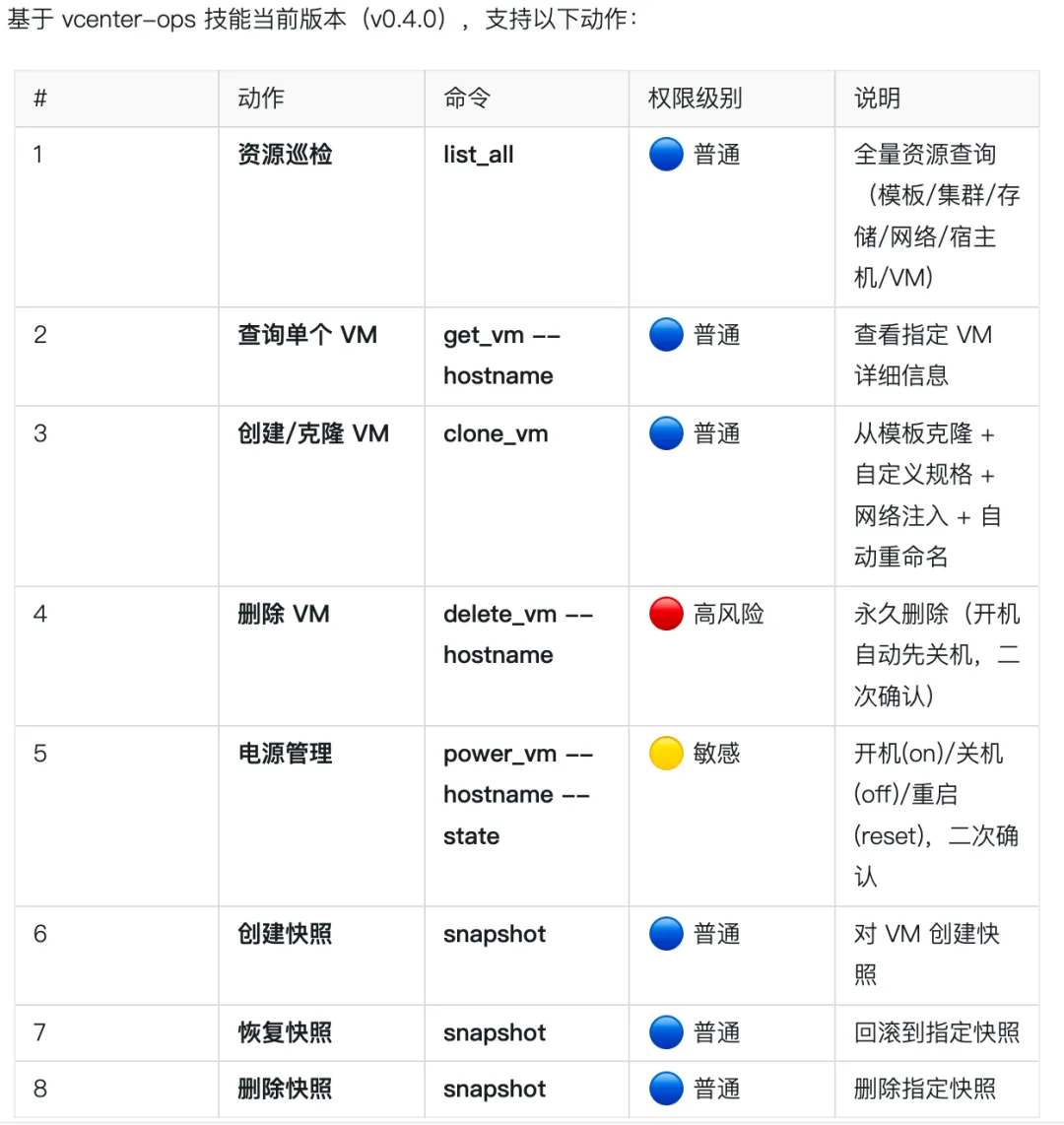
如何使用呢,首先需要 OpenClaw 并且网络访问登录 vCenter Client 然后 OpenClaw 对接某个 IM 平台机器人,挂一个比较好用的脑子 LLM 注意,这种运维执行类的动作最好用毕竟好的模型。
安装直接和机器人对话,让它把这个技能安装到当前 Agent 目录下:
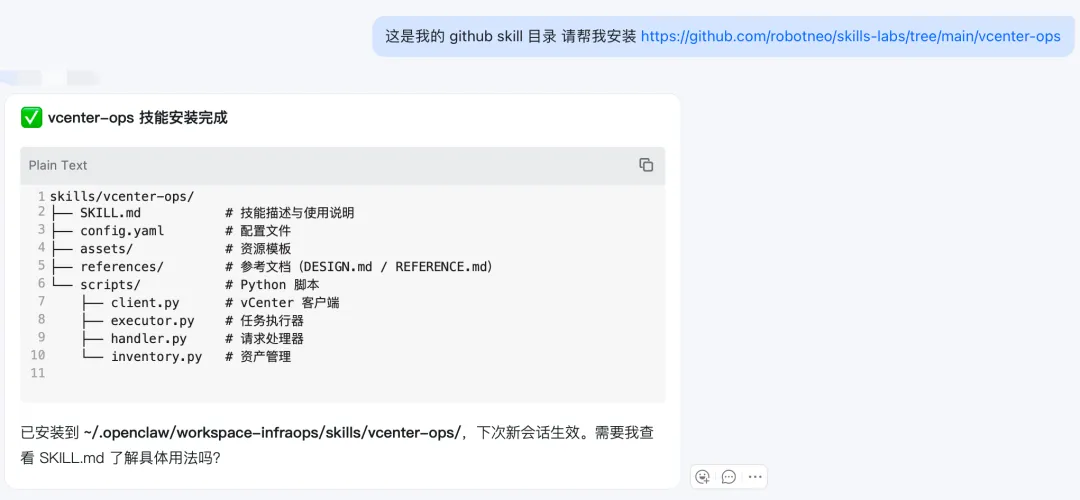
当然你也可以直接下载这个技能目录放在对应的 skills 目录下。
我们首先来看看创建虚拟机流程吧:
我们可以这么和它对话,只要触发虚拟机、VMWare、vCenter那么就可以进入这个 SKILL 的流程。
有两种方式,交互式创建,以及发送基本参数直接触发创建,首先我们来看看交互式创建:
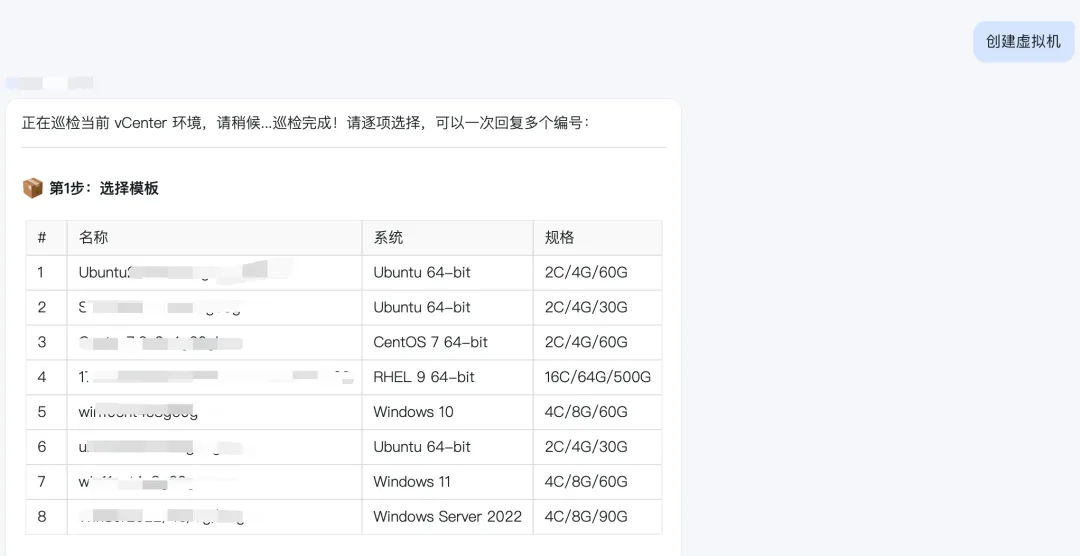
交互式创建的时候,会列出集群内的一些基础参数,创建虚拟机需要选择的基本信息,你可以根据需求选择对应的序号:
第一步:选择模版 第二步:选择集群 第三步:选择存储 第四步:选择网络
然后填写一个自定义的主机名即可,如下所示:

接下来就是定义 CPU 、 内存 、 硬盘 、以及 IP 信息:
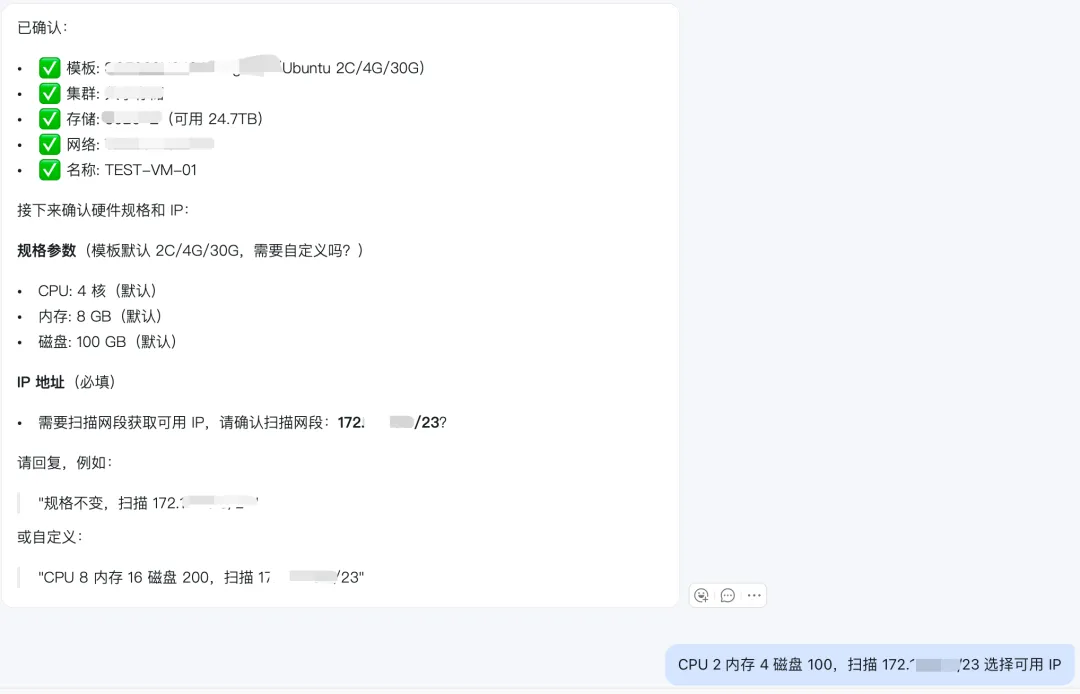
IP 选择的时候有一些明确的,可以直接指定,也可以根据现网未用的 IP 加扫描集群的 IP 结合自动选择一个,反正方式很多,根据实际需求。
最终有个克隆确定环节:
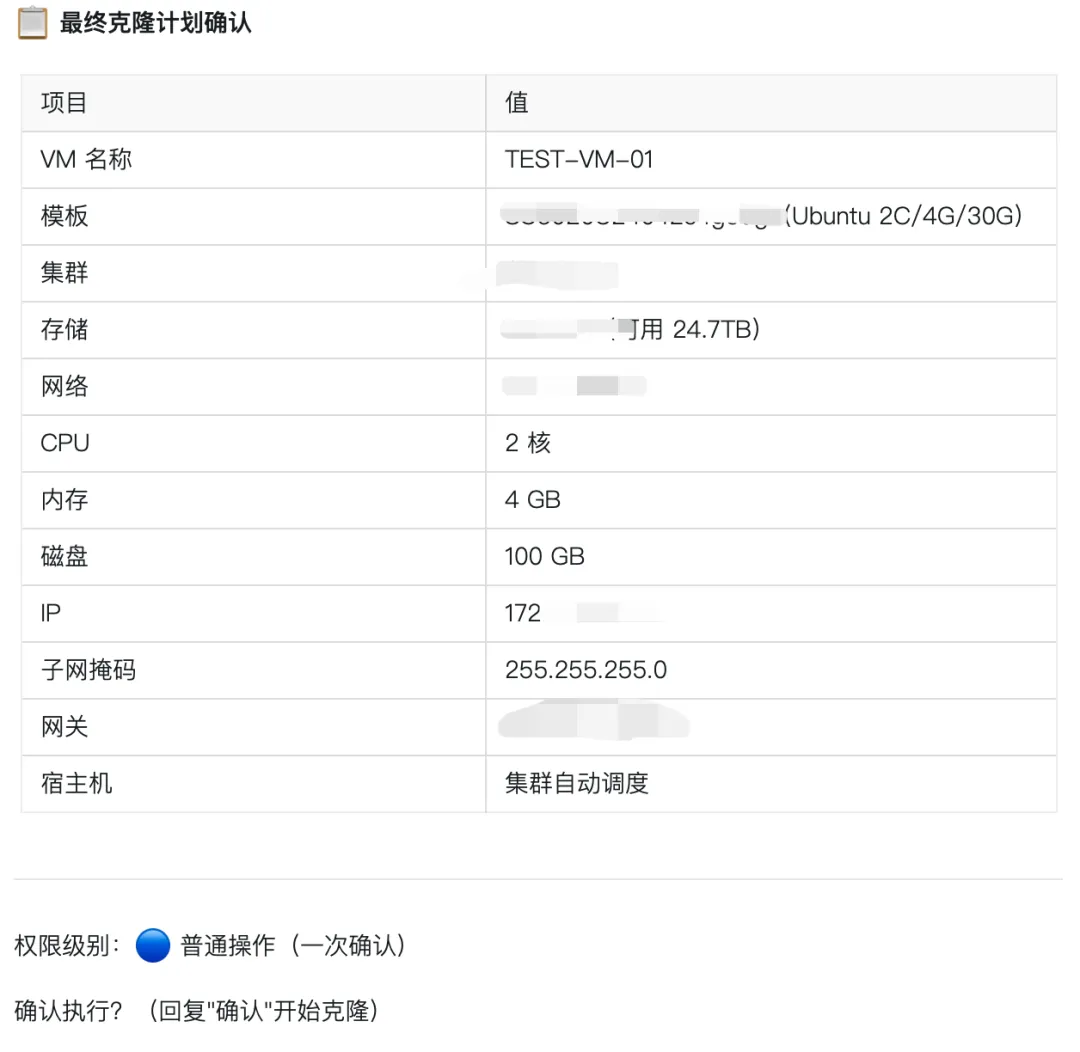
由于克隆是普通权限,只需要一次确认即可,如果是删除的动作是需要二次确认(防止手贱),如果为了安全可以对接审批流,这个就是后话了。
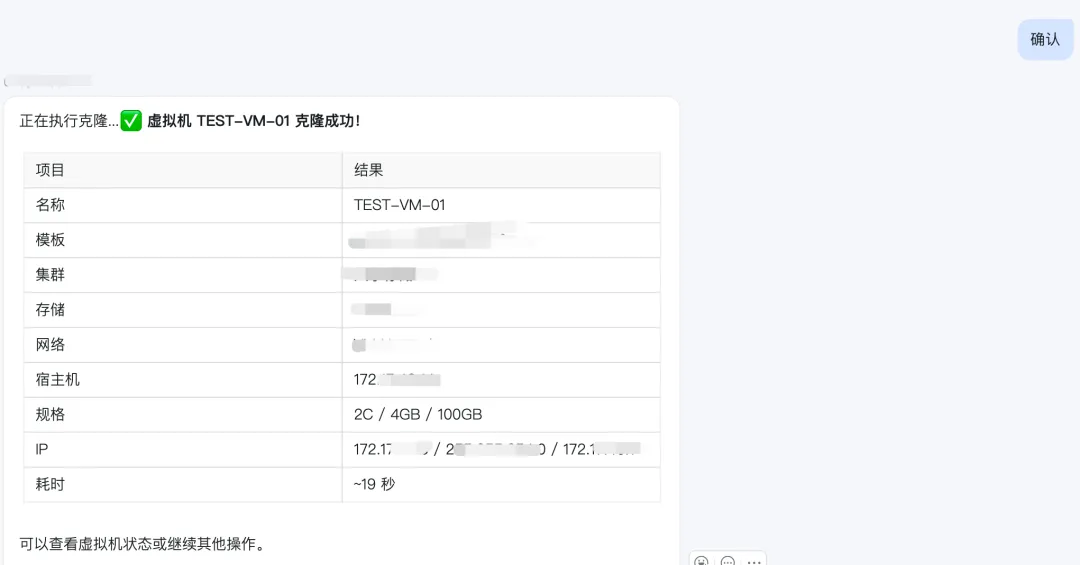
只需要等待几秒,一台机器就克隆好了,基本上就直接可以交付了。
优化查询
这里目前只是创建虚拟机,但是在实际使用的时候发现,只要涉及到查询全量信息的时候就很慢,而且 token 消耗快,查询 vCenter API 是个效率低的事情,那这个问题如何解决呢?
我的解决办法就是,每查询都很慢,我可不可以第一次对话(一个会话 session 的时候)把查询到的全量信息保存到本地中,格式可以用 json 保存,后续的对话可以优先去读取这个当前本地的信息,加速后续的对话信息读取和展示,也节省模型 token 没想到这个方案大大提速了,比如优化前 30s 优化后直接提速 1s 了,这是万万没想到的,后续只要是新会话就会先全量查询保存在本地 json 中,这个可不可以理解为本地缓存。
除了创建操作,还有其他查询类操作,我们可以看集群的很多信息,如果不想交互创建,可以直接一个模版内容发过去,确认即可:
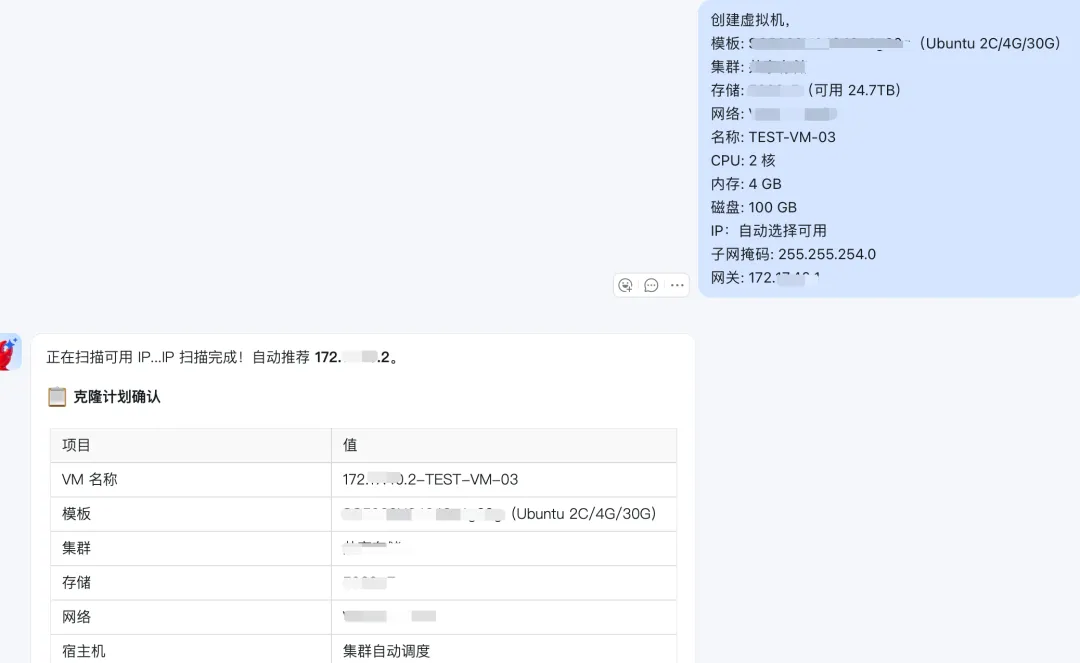
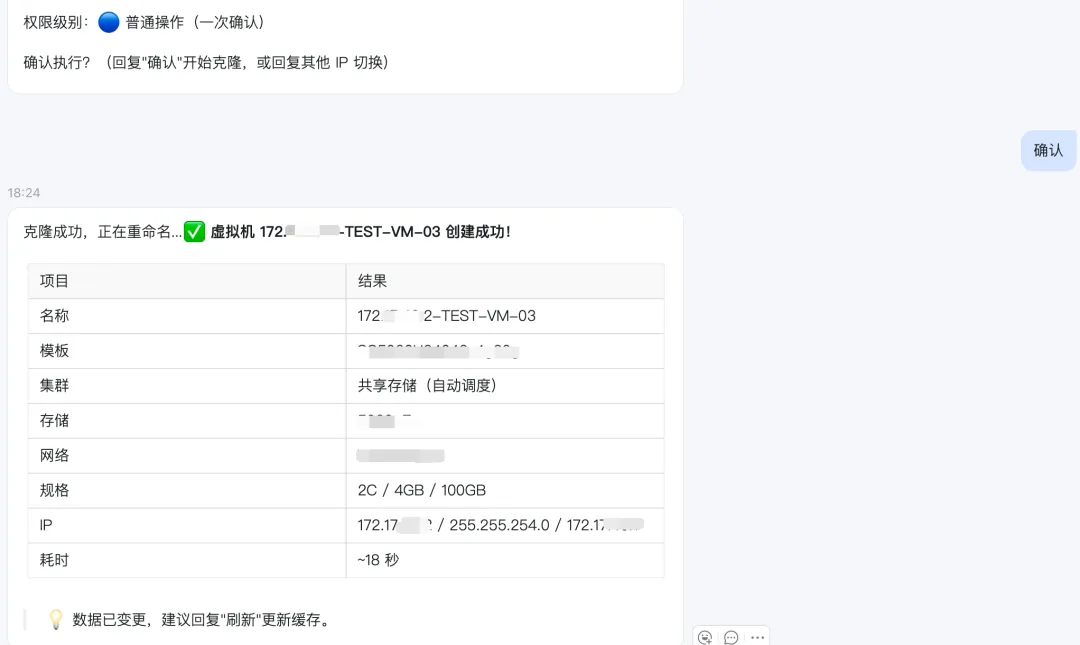
在后台看到正常创建并且启动了,一点问题都没有,非常方便。
日常实际只需要 AI 提供一些常用创建模版,基本上就可以马上新建,如果对资源不确定,就叫 OpenClaw 推荐这个虚拟机落在那个集群,那个存储最优即可。
现在我们删除虚拟机测试一下,删除的权限需要二次确认的:
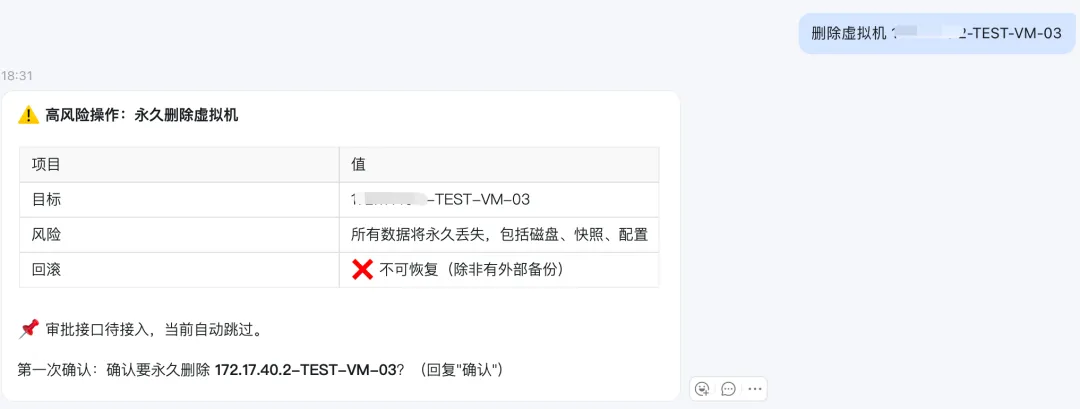
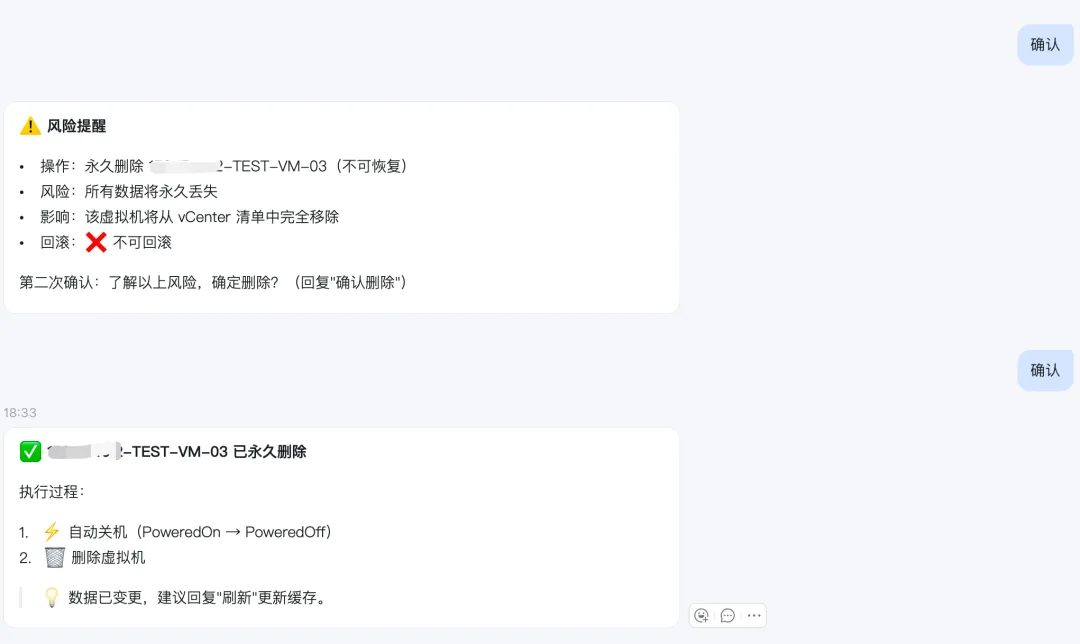
其实这些高危动作可以直接二次确认,第一是为了防止手贱,第二也是为了再次确认。
其实后续可以接入审批环节,这些都可以自定义,接入内部的审批,直接把这个流程转到对应审批人审批即可,这个就是后话。
还有就是 IP 的管理,目前是通过扫描集群用到的 IP 和 ping 测试进行判断可用 IP 如果需要更加严谨可以接入内部维护的文档,比如飞书或者钉钉文档,然后对文档内的 IP 做检查(这个就是单独的 Skills ),其实像钉钉和飞书都已经有了,或者有 IPAM 也可以对接写个 Skills 加入这个工作流即可。
扩展需求:
服务器创建好后,需要对接 JumpServer故我下一篇还要对接JumpServer的流程,虚拟机创建好后,咨询是否加入JumpServer或者直接就加入,后续研发或者运维即可直接在JumpServer上进行虚拟机的操作。
总体还有优化的空间,可以把更多操作接入进来,优化流程,提高响应速度,前提是模型要差不多,这个任务不复杂,基础模型基本上可以应付。
end
如果您也想 OpenClaw 使用,并且后续尝试小团队协作使用的话,可以加我沟通,我们一起交流一下心得。
我建立了一些对关于网络和基础设施等相关的监控告警群,也可以聊聊 OpenClaw 在我们运维监控场景的应用,针对这块的有需求或者想沟通交流,可以加入到群里交流即可,可公众号后台私信加我,我拉你进群。
📣欢迎朋友们关注公众号📢📢:【网络小斐】!
🙋♂️有想法的朋友也可以加我沟通,朋友🔘做个点赞之交!😂😂
欢迎点赞 👍、收藏 💗、关注 💡 三连支持一下,我们下期见~✨
