 夜雨聆风
夜雨聆风又是新的一天,大家好!我是Nice哥!唉!先别划走,我还没说呢!如果你有OpenClaw记忆问题困扰,这篇文章后你看了之后,一定能直击你的痛点,用一种最简单的方法解决你的龙虾记忆问题。有帮助请关注点赞转发,没帮助可以随时喷我。如果你不想看原理,只想看实操,请直接跳转到第十个要点介绍。
如果你最近在玩 OpenClaw,应该很容易遇到一种熟悉又恼火的感觉:你越用越觉得它强。
但你越用,也越会发现它有一个很致命的问题——昨天还聊得好好的,今天就不认识我啦!。
今天你告诉它,你在做电商项目;明天你问它之前那件事推进得怎么样;它一脸认真地回答你……然后完全答偏。
更离谱的是,有时候它会牢牢记住无关紧要的闲聊,却把真正重要的偏好、项目背景、配置细节忘得干干净净。
这不是 OpenClaw 一家的问题。这是几乎所有 AI Agent 正在集体面对的一道坎:
没有可靠的记忆系统,Agent 就很难真正从“会回答”进化成“会协作”。
而 MemOS,正在试图解决这件事。
我认真读了 MemOS 针对 OpenClaw 的几篇官方文档,包括云插件、本地插件、多智能体记忆隔离和记忆召回二次过滤。看完后的最大感受就一句话:
它不是给 AI 多塞一点上下文,而是在给 AI 补上“长期记忆基础设施”。
这件事,比大多数人想象中更重要。
一、为什么说“记忆”,才是 AI Agent 真正的分水岭?
很多人以为,Agent 的核心竞争力是工具调用、自动化执行、跨设备控制。
这些当然重要。
但当你真的开始把一个 Agent 用进真实工作流,你会很快发现:
能不能长期、稳定、低成本地记住重要信息,决定了它到底是玩具,还是助手。
OpenClaw 原生的记忆方式,本质上还是以本地 Markdown 文件为核心,配合向量检索和 BM25 做混合搜索。
这个思路其实并不差,甚至很有“文件即真理”的透明感。问题在于,一旦进入真实使用场景,三个问题几乎必然出现:
1. 全局记忆会越长越肿
随着长期记忆越来越多,系统上下文就会逐渐膨胀。你只是想问一个当前问题,它却可能把几个月前的历史都搬进来。
结果是什么?
Token 成本失控。
第一次对话可能几百 token,第二次破千,聊到第十次就轻松上万。若再叠加屏幕监控、定时任务、复杂工作流,Token 消耗简直像开了闸。
2. 每日记忆很难真正好用
理论上,daily memory 能记录每天发生了什么。
但现实是,当记录越来越多,检索反而越来越繁琐。你想找昨天提过的一句关键配置,结果得翻半天;你想维持跨会话连续性,也经常会断。
3. 记忆往往依赖模型“主动记”
这是最扎心的一点。
很多系统嘴上说有记忆,实际上是让模型自己决定“要不要记住”。问题是,模型并不总知道什么最值得记。
于是就出现了一个很荒诞的场景:
你以为你在和一个越来越懂你的 Agent 合作,实际上你在反复给一个会失忆的搭档做 onboarding。
二、MemOS 到底在做什么?不是“多记一点”,而是“记得更对”
MemOS 最吸引我的地方,不是它强调“记忆能力”,而是它对“记忆质量”这件事看得非常清楚。
它并不是粗暴地把更多历史塞给模型,而是试图把记忆这件事拆成几个真正可工程化的动作:
• 自动捕获 • 语义分片 • 去重摘要 • 向量化存储 • 结构化检索 • 相关性过滤 • 多 Agent 隔离 • 技能沉淀与复用
换句话说,MemOS 想做的不是“聊天记录备份器”,而是Agent 的长期认知层。
三、云插件:把 Token 消耗,从“历史长度函数”改成“任务相关性函数”
先说 MemOS 的 OpenClaw 云插件。
官方文档里有一句话很关键:
它要解决的,不只是记忆问题,还包括 60% 的 Token 消耗优化。
这背后的逻辑其实特别清楚。
以前的做法,是每轮都固定塞入 today、yesterday 和长期记忆。
现在的做法,是由 MemOS 按当前任务只召回最相关的少量记忆。比如每次只取 3 到 5 条真正相关的记忆,而不是把整本聊天史重新读一遍。
这意味着什么?
意味着 Agent 的成本模型被改写了。
过去,成本与“你们聊过多少”强绑定。现在,成本更多与“当前任务到底需要什么”绑定。
这个变化非常关键,因为它让 Agent 终于从“越用越贵”变成“越用越稳”。
更重要的是,相关性变高之后,模型反复试错的次数也会下降。
这点很容易被低估。
很多时候,Agent 不是不会做,而是因为召回的上下文太脏、太散、太吵,导致它推理时一直在错误材料里打转。MemOS 通过更强的结构化检索和筛选,让它更容易“一次命中”。
说得直白一点:
省下来的不只是 Token,还有模型的注意力。
四、本地插件真正厉害的地方:它让记忆、任务、技能,形成了闭环
如果说云插件解决的是“记忆召回更精准、成本更可控”,那么本地插件真正让我眼前一亮的,是它把记忆系统做成了一整套流水线。
官方文档里提到,本地版 MemOS OpenClaw 插件有四条智能流水线。我觉得这恰恰是它最像“下一代 Agent 基础设施”的地方。
流水线 1:记忆写入
每轮对话自动触发。
对话内容会经过角色过滤、系统提示剥离、语义分片、内容哈希去重、逐块摘要、向量化,最终落进 SQLite + FTS5 + Vector 的本地存储里。
这件事的意义在于:
记忆不再依赖模型的主观发挥,而是进入了自动、稳定、可复查的工程流程。
它甚至还会剥离插件自身的工具结果包装,避免“把记忆再记忆一遍”的反馈循环。
这很细,但也很专业。
流水线 2:任务生成
这是很多人会忽略、但我认为非常有价值的一层。
因为原始记忆其实是碎片化的。
你一次“部署 Nginx”的协作,可能跨越 20 个 chunk;如果只做普通向量检索,召回到的往往只是零碎片段。
于是 MemOS 做了一件更聪明的事:
把碎片整理成任务。
它会按用户轮次分组,判断当前消息是延续同一任务,还是进入新任务;如果间隔超过 2 小时,也会强制切分。最终,那些足够完整的任务会被总结成结构化摘要,保留目标、步骤、结果、关键细节。
这等于给 Agent 增加了一种更高级的记忆单位:
不是“我记得一句话”,而是“我记得你之前完整做过一件事”。
流水线 3:技能进化
这一层就更有意思了。
任务完成之后,系统不是简单存档,而是会继续判断:
这段经验,能不能沉淀成一个可复用技能?
如果能,就生成 SKILL.md、脚本、验证项;如果已有类似技能,就继续 refine、extend、fix,让版本号递增。
这背后体现的是一种非常强的产品思路:
记忆不是终点,复用才是。
真正有价值的 Agent,不是“记住你上次怎么做”,而是“下次遇到同类问题,它已经有了一套更成熟的做法”。
很多人谈 Agent,只谈自动执行。但 MemOS 这里让我看到的是另外一个方向:
Agent 会通过记忆沉淀出技能,再通过技能反过来提高未来执行质量。
这就不是普通意义上的“会话记忆”了,而更像一种轻量级的自我进化机制。
流水线 4:智能检索
最后才是检索。
但注意,这里的检索已经不是传统意义上的“搜一下文本”。
它是 FTS5 + 向量双路召回,再做 RRF 融合、MMR 重排、时间衰减、分数过滤,最后还要经过 LLM 相关性过滤,只把真正有用的内容注入上下文。
这套设计说明了一件事:
MemOS 不是在赌某一种检索技术,而是在拼命提高“最终注入内容的有效密度”。
这也是为什么它的思路会让我觉得很成熟。
因为长期记忆最怕的,不是“不够多”,而是“多而无用”。
五、记忆召回二次过滤:把小模型变成主模型前面的“安检门”
这是我特别喜欢的一个点。
在“记忆召回的二次过滤”示例里,MemOS 支持用一个额外的大语言模型,对已经召回的记忆候选再次筛选。
也就是说,流程不再是:
召回什么,就全塞给主模型。
而是:
先召回,再让一个过滤模型判断哪些该保留,只有被标记为 keep 的记忆才会真正注入。
这个设计太实用了。
因为很多时候,向量召回其实已经很强了,但它仍然会带来一些“看起来相关、实际上会干扰”的内容。尤其在长期对话、复杂工作流、多项目并行的情况下,这种噪音很常见。
如果前面能放一个低成本过滤器,比如本地跑的小模型,或者兼容 OpenAI 格式的第三方模型,那么主模型看到的上下文就会干净很多。
这就像在机场安检口前又加了一道智能筛查。
你真正想让大模型读的,不应该是“可能有关”,而应该是“高度相关”。
而且 MemOS 这里还做了一个很工程化的设计:
失败放行。
也就是过滤模型超时或故障时,系统会自动回退成不过滤,保证对话不中断。
这很重要。
很多系统的问题在于,它为了追求“更智能”,结果牺牲了可用性。MemOS 这点反而很务实:先保证工作流不断,再谈精度优化。
六、多智能体记忆隔离:别让你的营销 Agent 偷看到技术 Agent 的脑子
多 Agent 协作,是这两年 Agent 领域最容易被讲得很热血、但最容易被做得很混乱的一块。
因为多智能体一旦真的落地,一个最现实的问题立刻就来了:
谁该记住什么?谁又不该看到什么?
MemOS 对这件事的处理很清晰。
在云插件里,只要开启多 Agent 模式,它就支持根据 ctx.agentId 自动隔离不同 Agent 的记忆空间。每个 Agent 只看到自己的记忆,不会“串台”。
而在本地插件里,这件事做得更完整:
• 私有记忆,只允许当前 Agent 检索 • 公共记忆,所有 Agent 可见 • 私有技能,仅所有者可见 • 公共技能,可以被其他 Agent 搜索并安装
这意味着什么?
意味着你的技术 Agent 可以沉淀部署经验;营销 Agent 可以形成品牌语调;业务 Agent 可以保留行业判断;但它们又能通过“公共记忆”和“公共技能”共享真正值得共享的部分。
这其实已经很接近一个小型组织的知识流动机制了。
不是所有经验都公开,不是所有能力都封闭。
该隔离的隔离,该共享的共享。
这四个字,恰恰是多智能体系统能不能从 demo 走向生产的关键。
七、为什么我会觉得 MemOS 不是一个“小插件”,而是一层基础设施?
因为它解决的不是某一个局部问题。
它同时在处理下面这几件事:
• 让记忆自动写入,而不是靠模型临场发挥 • 让记忆可结构化组织,而不是堆成碎片 • 让检索更精准,而不是一锅乱炖 • 让上下文更干净,而不是越积越脏 • 让多 Agent 有边界,而不是相互污染 • 让任务经验变成技能,而不是只停留在“记得做过”
这本质上是在回答一个更大的问题:
如果 Agent 要成为长期协作者,它的大脑该怎么设计?
而 MemOS 给出的答案,不是哲学性的,而是工程性的。
它告诉你:
• 记忆怎么存 • 任务怎么抽 • 技能怎么长 • 检索怎么筛 • 多智能体怎么隔离 • 成本怎么控
这就是我为什么会觉得,它不像一个单点增强插件,而更像一层“Agent 记忆操作系统”。
八、谁最应该认真看 MemOS?
如果你只是偶尔和 AI 聊两句,MemOS 对你来说可能没那么刚需。
但如果你属于下面几类人,我觉得它非常值得研究:
1. 重度使用 OpenClaw 的个人用户
你已经开始让 Agent 参与持续性任务、自动化流程、项目协作,那你迟早会撞上记忆和 Token 的天花板。
2. 想做长期陪伴型 AI 的开发者
你会发现,所谓“懂用户”,不靠一个 prompt 写得多花,而靠一套真正稳的记忆基础设施。
3. 在做多 Agent 协作系统的团队
一旦多个角色并行工作,记忆边界、公共知识和技能复用,都会从“可选项”变成“必答题”。
4. 对本地化、隐私和数据控制有要求的人
本地插件的价值非常直接:所有数据留在本地,可离线运行,可视化透明管理,适合那些不愿把长期记忆交给云端的人。
九、如果你现在就想上手,可以怎么选?
看完文档后,我的建议很简单:
如果你想先快速体验
可以先看云插件。
它的优势是接入直接,能迅速感受到“精准召回 + Token 优化”的效果,尤其适合想低门槛验证记忆增强价值的人。
如果你更在意隐私、本地掌控、长期演化
优先看本地插件。
因为本地版不只是“把云端能力搬回本地”,它在任务总结、技能进化、可视化管理、多智能体协同这些维度上,明显更有野心。
如果让我用一句话来概括两者区别,那就是:
云插件更像快速接入的记忆增强器,本地插件更像完整的 Agent 认知底座。
十、实操指南:云端版和本地版,到底该怎么安装、设置和使用?
如果你读到这里已经有点心动,下面这部分可以直接收藏。
我把文档里最核心的安装、配置和使用路径,整理成了一个尽量好上手的版本。
方案 A:MemOS 云端版
适合谁?
• 想尽快体验记忆增强 • 希望跨设备、跨实例共享长期记忆 • 想优先验证“精准召回 + 降低 Token 消耗”效果
1. 安装 OpenClaw
先确保本机已经装好 OpenClaw:
npm install -g openclaw@latestopenclaw onboard2. 获取 MemOS API Key
去 MemOS Cloud 后台申请 API Key:
MemOS Cloud:https://memos-dashboard.openmem.net/cn/apikeys/
3. 配置 API Key
插件会优先从以下 env 文件读取:
• ~/.openclaw/.env• ~/.moltbot/.env• ~/.clawdbot/.env
最小配置可以写成:
MEMOS_API_KEY=YOUR_TOKEN如果你喜欢直接配系统环境变量,也可以这样做。
Windows PowerShell 示例:
[System.Environment]::SetEnvironmentVariable("MEMOS_API_KEY", "mpg-...", "User")4. 安装云插件
推荐命令:
openclaw plugins install @memtensor/memos-cloud-openclaw-plugin@latestopenclaw gateway restart如果你是 Windows 用户,官方文档特别提醒:有时会遇到 spawn EINVAL 这样的插件安装问题。这种情况下,建议改用手动安装方案。
手动安装的大意是:
• 从 NPM 下载最新 .tgz包• 解压到本地扩展目录 • 在 ~/.openclaw/openclaw.json中把插件路径加入plugins.load.paths• 重启 gateway
5. 检查插件是否启用
在 openclaw.json 中,至少要看到类似配置:
{ "plugins": { "entries": { "memos-cloud-openclaw-plugin": { "enabled":true } } }}6. 怎么开始用?
其实很简单。
你只需要正常和 Agent 聊天、做任务、交代偏好。MemOS 云插件会把长期记忆放到云端,并在后续会话中按任务相关性召回。
最直观的测试方法是:
第一轮告诉它:
• 我最喜欢的编程语言是 Python • 我正在开发一个电商项目
下一轮重新开会话再问:
• 你还记得我喜欢用什么编程语言吗? • 我之前说的项目进展如何?
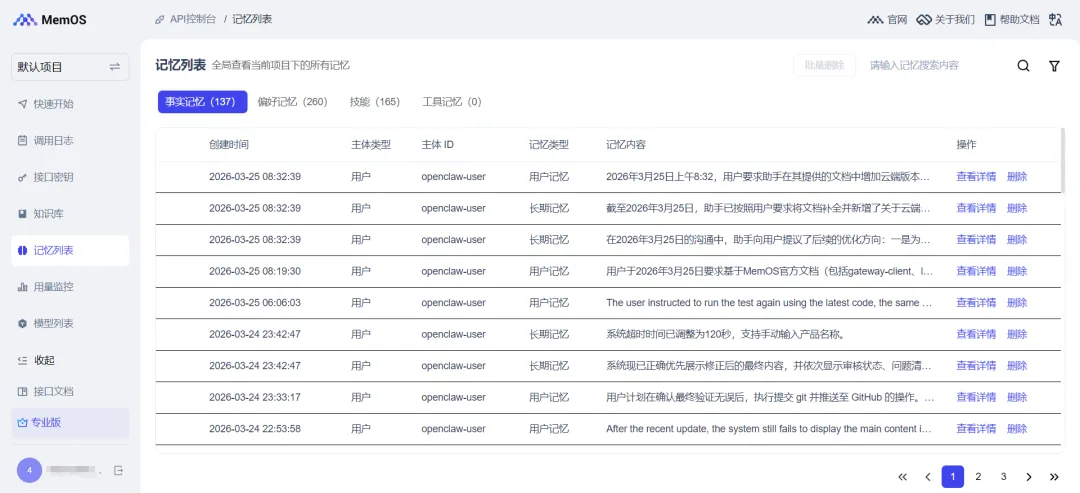
如果配置正确,它就会开始调用云端记忆来回答。访问https://memos-dashboard.openmem.net/cn/memoryList,可以查看记忆记录,它还贴心地帮你进行分类:事实记忆、偏好记忆、技能、工具记忆。
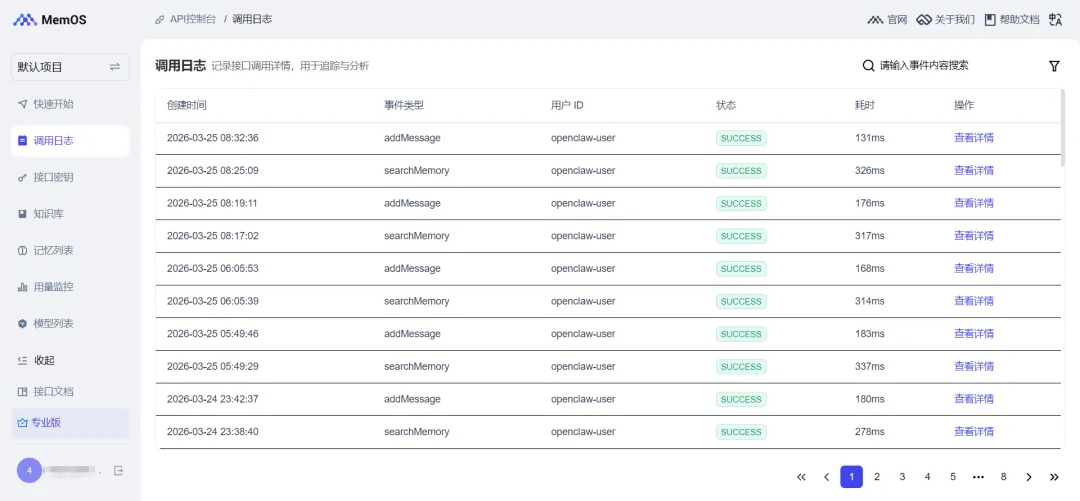
访问https://memos-dashboard.openmem.net/cn/requests/,可以查看记忆的请求日志记录。
7. 云端版的进阶功能
云端版还有两个很值得开的高级能力:
第一,多 Agent 记忆隔离。
如果你有多个 Agent,可以在openclaw.json设置中开启:
{ "plugins": { "entries": { "memos-cloud-openclaw-plugin": { "config": { "multiAgentMode":true } } } }}或用环境变量设置(推荐):
MEMOS_MULTI_AGENT_MODE=true这样系统会根据 ctx.agentId 自动隔离不同 Agent 的记忆。
第二,记忆召回二次过滤。
如果你想让注入上下文的记忆更“干净”,可以增加 recall filter:
{ "plugins": { "entries": { "memos-cloud-openclaw-plugin": { "config": { "recallFilterEnabled":true, "recallFilterBaseUrl": "http://127.0.0.1:11434/v1",# 可以更换为云端模型 "recallFilterApiKey": "sk-...", "recallFilterModel": "qwen2.5_7b" } } } }}也可以进一步配置超时和失败策略,比如:
• recallFilterTimeoutMs• recallFilterFailOpen
其中 failOpen: true 的好处是:过滤模型挂了,对话也不会中断。
方案 B:MemOS 本地版
适合谁?
• 更在意隐私和数据控制 • 希望离线运行 • 想要任务总结、技能进化、记忆可视化等完整能力 • 想把 MemOS 当作长期本地认知底座来用
1. 安装本地插件
官方给出的安装方式很直接。
macOS / Linux:
curl -fsSL https://cdn.memtensor.com.cn/memos-local-openclaw/install.sh | bashWindows:
powershell -c "irm https://cdn.memtensor.com.cn/memos-local-openclaw/install.ps1 | iex"安装完成后,插件会被放到:
~/.openclaw/extensions/memos-local-openclaw-plugin
它会以 memos-local-openclaw-plugin 的名字注册。
2. 打开 Memory Viewer
本地版一个很实用的点,是自带 Web 管理面板。
启动后通常可以直接访问:
http://127.0.0.1:18799
你可以在这里查看记忆、任务、技能和设置。
查看记忆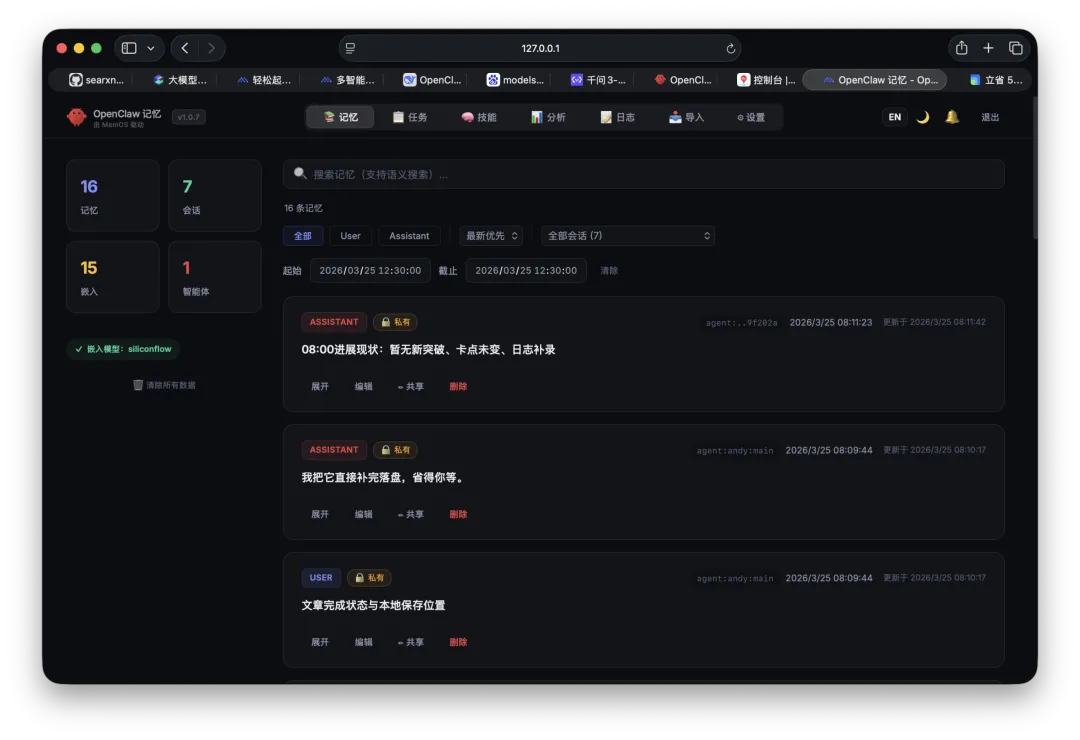
查看任务
查看技能
使用分析
查看日志
导入本地已有记忆
3. 配置模型
本地版至少要配置 Embedding。
官方支持很多提供者,比如:
• OpenAI / OpenAI compatible • SiliconFlow(硅基流动) • 智谱 • 阿里百炼 • Gemini • Cohere • Voyage • Mistral • 本地离线 embedding
模型设置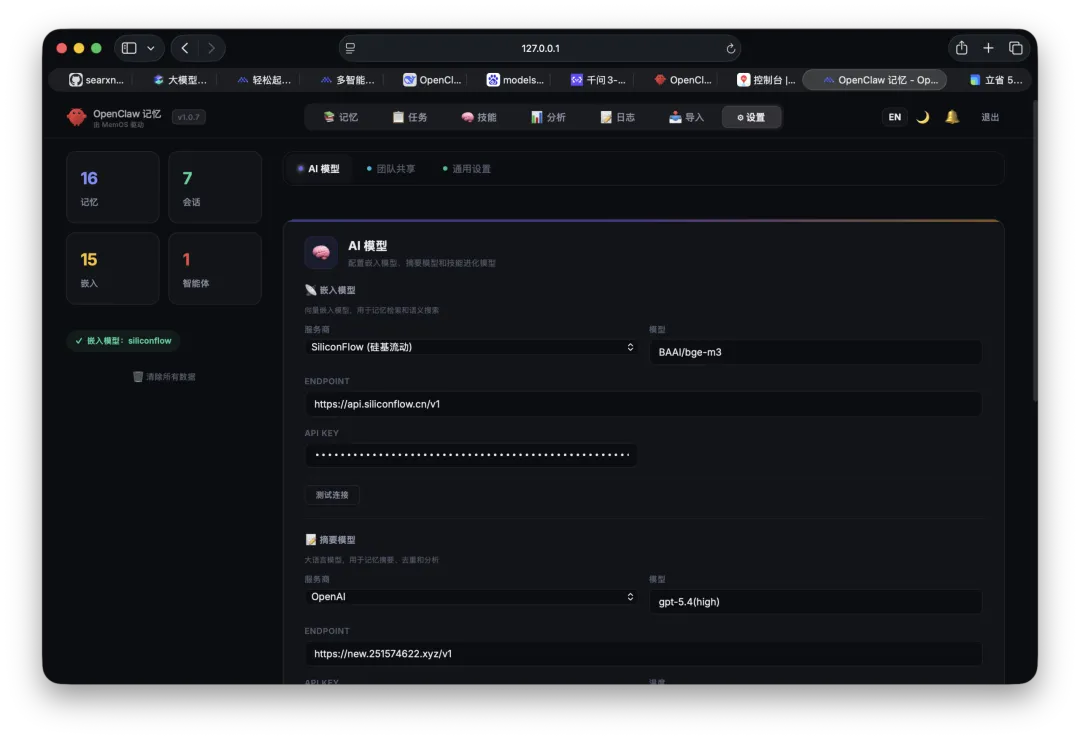
一个典型配置长这样:
{ "plugins": { "allow": ["memos-local-openclaw-plugin"], "slots": { "memory": "memos-local-openclaw-plugin" }, "entries": { "memory-core": { "enabled":false }, "memory-lancedb": { "enabled":false }, "memos-local-openclaw-plugin": { "enabled":true, "config": { "embedding": { "provider": "openai_compatible", "model": "bge-m3", "endpoint": "https://your-api-endpoint/v1", "apiKey": "sk-••••••" }, "summarizer": { "provider": "openai_compatible", "model": "gpt-4o-mini", "endpoint": "https://your-api-endpoint/v1", "apiKey": "sk-••••••" } } } } }}如果你不想把密钥硬编码进 JSON,也可以使用环境变量占位符:
{ "apiKey": "${OPENAI_API_KEY}"}这点对长期维护更友好。
4. 可选开启技能进化
如果你希望 MemOS 自动把任务经验沉淀成技能,还可以给 skill summarizer 单独配一个更高质量的模型,配置路径:设置>AI模型,最低部找到“技能进化”。
skill summarizer设置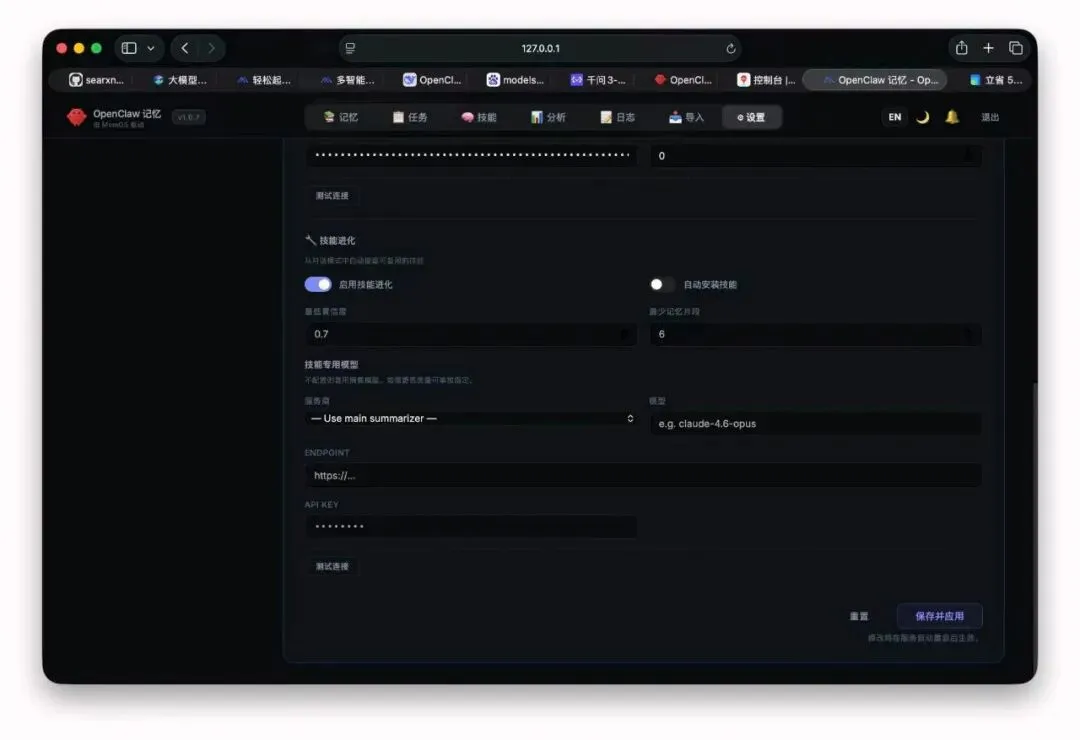
这样系统就能在任务完成后判断:
• 要不要新建技能 • 要不要升级已有技能 • 要不要自动安装
5. 启动或重启 Gateway
常见操作是:
openclaw gateway stopopenclaw gateway installopenclaw gateway start启动后,Memory Viewer 会跟着起来。
6. 验证是否安装成功
官方文档建议看日志。
如果你在日志里看到类似下面的信息,基本就说明插件正常启动了:
• memos-local: initialized• memos-local: started• MemOS Memory Viewer -> http://127.0.0.1:18799
7. 怎么开始用?
本地版的使用方式,其实和云端版一样自然:
你只需要正常与 Agent 对话、让它执行任务、长期协作。
不同的是,它会在本地持续完成这些事:
• 自动记录对话并写入记忆 • 生成任务摘要 • 在适合时进化技能 • 检索私有记忆、公共记忆和共享技能
最简单的验证方式依然是:
• 先随便聊几轮 • 打开 Memory Viewer 看内容是否已经入库 • 新开一个会话,让 Agent 回忆之前做过的事情
如果它能回忆出来,而且 Viewer 中也能看到结构化内容,说明本地记忆链路已经跑通了。
最后一个选择建议
如果你现在问我:到底先装哪个?
我的建议是:
• 想快、想省事、想先验证价值:先上云端版 • 想稳、想掌控、想长期深用:优先本地版
如果你本身就在折腾多 Agent、自动化工作流、个人知识库,那我甚至会说:
MemOS 本地版更值得你认真搭起来。
因为它已经不只是“给 OpenClaw 增加记忆”,而是在帮你搭一个会持续积累经验的 Agent 底座。
十一、最后说一句:AI 的下一场竞争,可能不是模型参数,而是谁先拥有“像样的记忆”
过去我们谈 AI,最爱比模型能力。
谁更聪明,谁更快,谁上下文更长,谁工具更多。
但当 Agent 真正开始接管复杂任务,我们会越来越清楚地看到:
“能不能持续记住、理解、提炼、复用”,才是决定体验上限的关键。
没有记忆的 Agent,再强也像临时工。
有了记忆,但记得乱、记得脏、记得贵,也很难成为真正可靠的搭档。
而 MemOS 最值得关注的地方正在于:
它不是单纯帮 OpenClaw “记更多”,而是在帮它建立一种更像人的长期工作方式——
记住重要的,过滤无关的;隔离私有的,共享公共的;把做过的事,变成以后做得更好的能力。
如果你问我,MemOS 记忆系统最打动我的一句总结是什么。
我的答案会是:
它让 AI 不再只是“这一轮会回答”,而开始具备“下一轮会成长”的可能。
这,才是真正的记忆系统。
文中涉及的官方资料
• OpenClaw 云插件:https://memos-docs.openmem.net/cn/openclaw/guide • OpenClaw 本地插件:https://memos-docs.openmem.net/cn/openclaw/local_plugin • 多智能体记忆隔离:https://memos-docs.openmem.net/cn/openclaw/examples/multi_agent • 记忆召回的二次过滤:https://memos-docs.openmem.net/cn/openclaw/examples/recall_filter
