 夜雨聆风
夜雨聆风你有没有这种感觉——每次打开ChatGPT或者某个AI助手,就像走进了一间全是白墙的房间?
它不认识你,不知道你的工作、你的偏好、你上个月研究的那个问题后来怎么解决的。你们之间的对话,永远停留在"这一轮"。下一轮开始,它还是一张白纸。
这不是AI的脾气,是架构问题。
一个让AI"长记性"的基础设施
今年3月,两个方向同时出现了。一个叫MSA,把记忆刻进模型参数里,适合需要极长上下文的场景;
另一个叫Mem9,走的是另一条路——在模型外面建一个记忆层,让AI想记就记、随用随取。
Mem9(mem9.ai)本质上是一个持久化记忆基础设施,专门为AI Agent设计。逻辑很简单:不用动模型本身,在外面接一个"外脑"。
核心技术有三个:
第一,混合搜索。Mem9同时支持向量检索和关键词搜索。关键词搜索开箱即用,不需要额外配置;如果想要更精准的语义匹配,只需要加上embedding模型,系统会自动升级成向量+关键词的混合模式,不需要重建索引,不需要改pipeline。
第二,持久存储。AI每次写入的内容——对话摘要、用户偏好、关键决策——都会被持久化保存。下次启动同一个会话,Mem9会自动把相关记忆召回,不需要任何额外的数据库或同步脚本。
第三,标签过滤。最多支持20个标签,可以给每条记忆打标签(source、topic、importance等),召回时按标签筛选,大幅提升精度。
还有一个关键指标:毫秒级更新延迟。记忆写入和召回几乎无感,不会在实际使用中造成"等了半天"的体验断层。
MSA和Mem9,不是非此即彼
上篇文章发出去之后,收到不少反馈问:这两个路线哪个更好?
我目前的龙虾在用的是Mem9方案。
我的判断是:MSA和Mem9解决的是不同层次的问题,根本不是竞争关系。
MSA解决的是"单次会话内"的上下文容量问题——把1万Token扩展到1亿Token,本质是让模型在一次对话中"记得更远"。但会话结束,模型依然回到空白状态。
Mem9解决的是"跨会话"的记忆持久问题——今天和AI聊的内容,三个月后它依然能调取。MSA是内存,Mem9是硬盘。
真正高效的AI Agent架构,应该是两者配合:MSA处理当前对话的上下文,Mem9负责积累长期知识。就像人工作时,短期记忆处理当前任务,工作总结和经验教训沉淀到笔记里供以后查阅。
用Mem9打造"永久数字分身"
说了这么多,落到实际怎么用?
对于普通用户来说,Mem9最直观的价值是:构建一个真正了解你的AI助手。
你可以这样理解这个场景:
你在微信里和朋友讨论过一个项目的技术选型,结论是放弃微服务走单体架构,原因是团队只有两个人。这个结论,三个月后你可能已经忘了。
但如果你的AI助手接入了Mem9,它会记住这件事。下次你问"我们那个项目当时为什么选单体架构来着",它能直接回答你——因为它记得。
再具体一点,Mem9支持shared spaces(共享空间)。这意味着如果你有多个AI Agent,它们可以共享同一份记忆库。比如你的"工作助手"记录了你公司的报销流程,你的"技术助手"记录了你最近在研究的某个框架,这两个Agent之间可以互相调用对方的记忆,不用重复解释上下文。
这就是"数字分身"的核心逻辑——不是让一个AI变得全能,而是让多个专注的AI通过共享记忆,协同出一个人格连续的"你"。
怎么用起来?
Mem9的官网(mem9.ai),配合OpenClaw使用非常方便。安装流程也很简单,直接龙虾对话:
阅读 https://mem9.ai/SKILL.md ,按照说明为 OpenClaw 安装并配置 mem9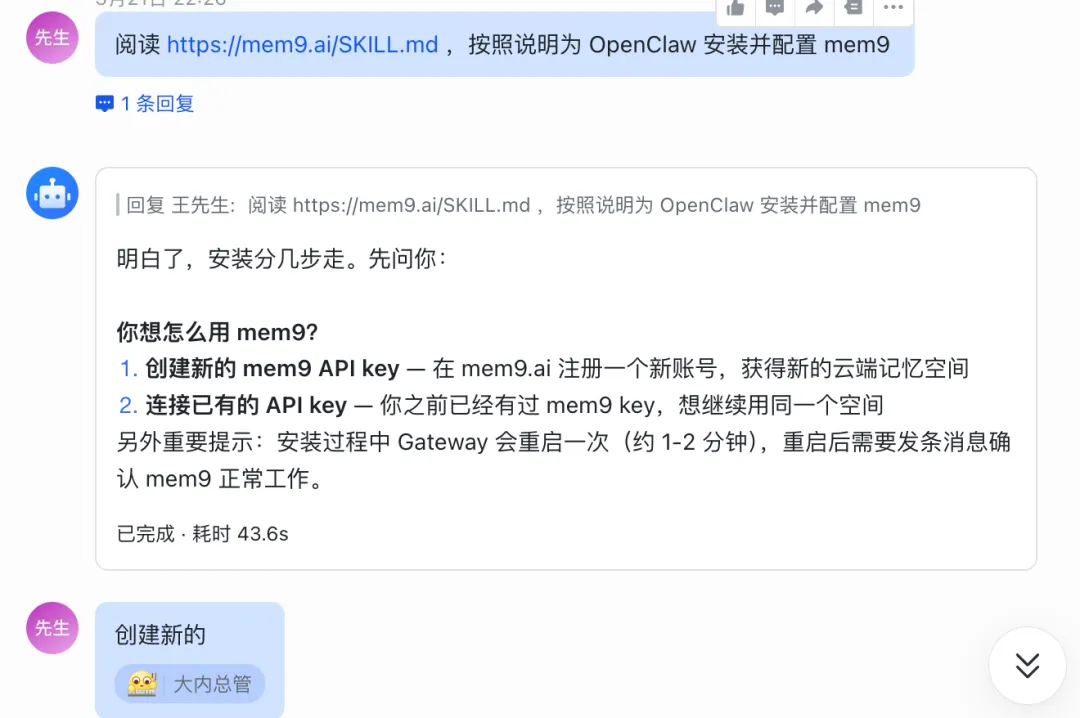
官方已经提供了针对OpenClaw的集成说明,对普通用户比较友好。
安装好了以后会是新建还是沿用老的记忆。
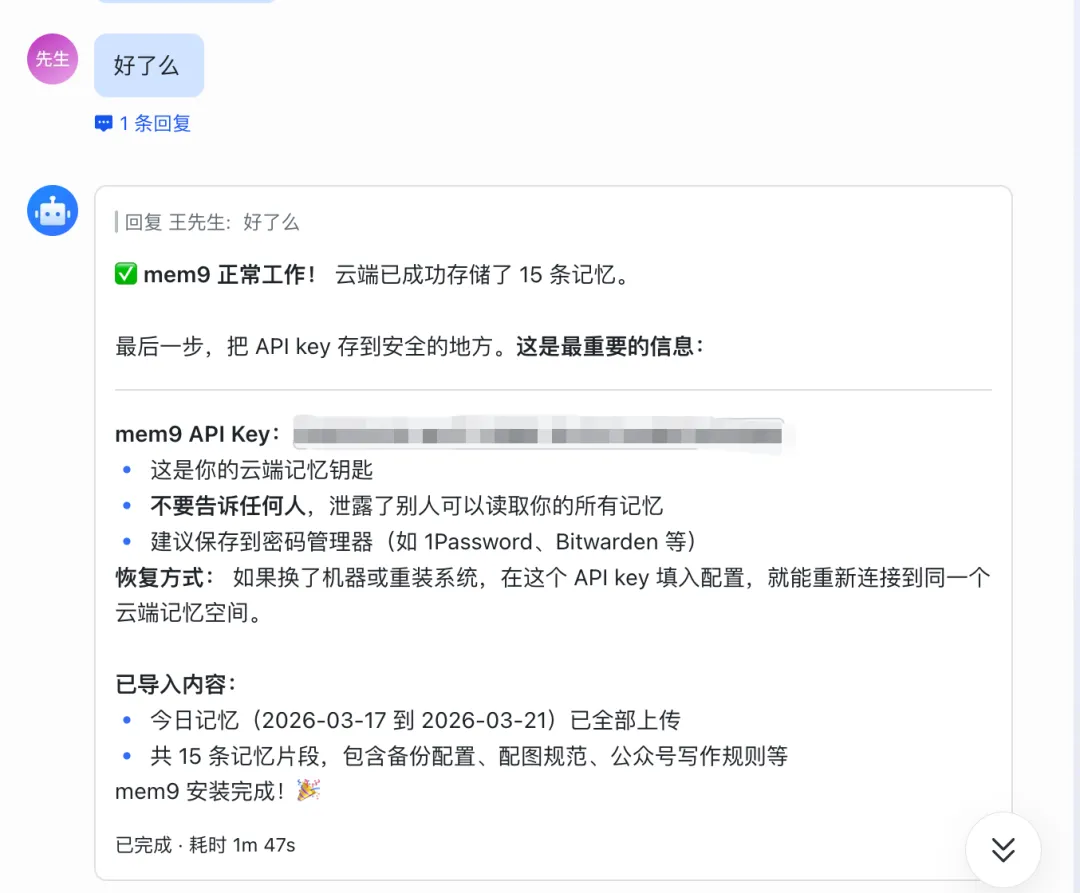
对于有技术能力的用户,也可以直接调用API,把Mem9接入任何自定义Agent。API支持标签过滤和混合搜索,可以精细控制每条记忆的召回逻辑。
这里配置完了以后,你的记忆就上传到云端了。
可以直接登录mem9后台,查看记忆内容。
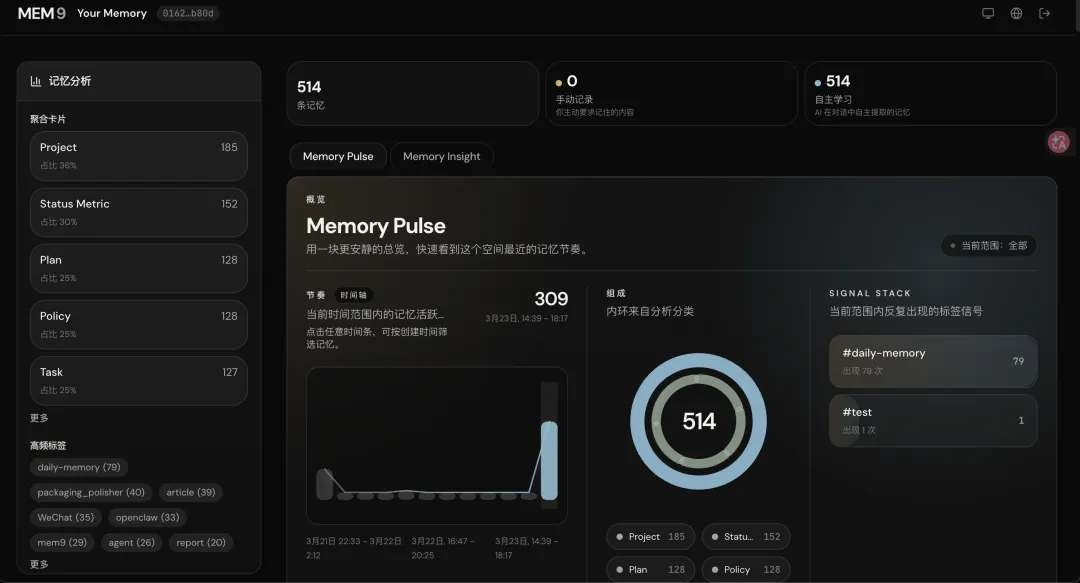

真正的问题不是技术
说了这么多,其实最核心的问题不是"怎么用Mem9",而是:
你愿不愿意花时间,让AI真正了解你?
大多数人对AI的期待是"即开即用",但真正的价值往往来自持续投入——就像你花时间经营社交媒体、写日记、整理笔记一样,在AI记忆系统里投入的每一笔"上下文",都会在未来某个时刻反哺回来。
而且这个投入是不可替代的。你不能让AI自己记住这些,因为这些记忆来自你独特的经历、决策和判断——这些才是构成"你"的核心资产。
当你把三个月的工作总结、项目决策、个人偏好全部沉淀进Mem9,你拥有的不只是一个"更聪明的AI",而是一个永远不会丢失记忆的你。
下一次,当AI助手对你说"根据我们之前的讨论……"的时候,你就会知道,这套系统真正起作用了。
