 夜雨聆风
夜雨聆风月薪两万养不起“龙虾”,万亿Token消耗背后的隐忧
2026年,AI圈最火的话题莫过于OpenClaw,“全民养虾”成为现象级趋势。
与此同时,另一组数据同样引人注目,全球最大AI模型API聚合平台OpenRouter最新发布的数据显示,截至3月15日,中国AI大模型的周调用量达到4.69万亿Token,连续第二周超越美国。全球调用量排名前三的位置,更是被中国模型包揽。国产大模型MiniMax M2.5连续五周霸榜全球调用量冠军。
就在昨天,Token这一AI时代最基础、最核心的计量单位,正式被官方命名为“词元”。一词定名,既呼应了它在语言模型中的本质角色,也让公众对这一“吞金”单元有了更直观的认知。
OpenClaw的爆火正在吞噬海量Token,这些数据不仅印证了中国AI的蓬勃发展,也使得Token消耗问题成为业界关注的焦点:在享受AI带来巨大便利的同时,我们如何才能有效控制其高昂的Token成本,实现AI应用的可持续发展?
OpenClaw为何成了“吞金兽”?
4.69万亿Token,是个什么概念?
在AI的世界里,Token是模型处理信息的最小计量单位。一段文字、一行代码、一个指令,都要被拆解成Token来完成运算。就像汽油之于汽车,Token是大模型运转的燃料。
OpenClaw的火爆,让很多人第一次真切感受到Token消耗的痛感。
朋友圈里,有人晒“养虾日记”;职场人士发现,月薪两万似乎都养不起这只龙虾。为什么?
开源不等于免费。很多人没有预料到的是,OpenClaw的成本并不在软件本身,而在背后的模型调用。它天生就是一个“Token黑洞”,每执行一个任务,都要消耗大量Token与后端大模型交互,一旦任务链拉长、工具调用增多、记忆开启,消耗会迅速抬升。
有用户反映,搜索信息、写一篇2000字文档可烧掉700万Token;运行一个简单爬虫测试竟耗费2900万Token;单日烧掉5000万Token的案例屡见不鲜。
OpenClaw这类智能体之所以加剧Token消耗,核心原因是它不同于传统聊天AI,普通的对话式AI,你问一句,它答一句,Token消耗是线性的。但OpenClaw不一样,你给它一个目标,它会自己分解任务、多轮调用、反复思考、不断修正,然后再调用工具,再确认……每完成一件事,背后的Token消耗可能是普通对话的几十倍。
微信ClawBot刚刚正式上线,全民养虾时代真的来了。Token消耗的问题,已经不只是开发者的烦恼了。
Token消耗背后的四个"黑洞"
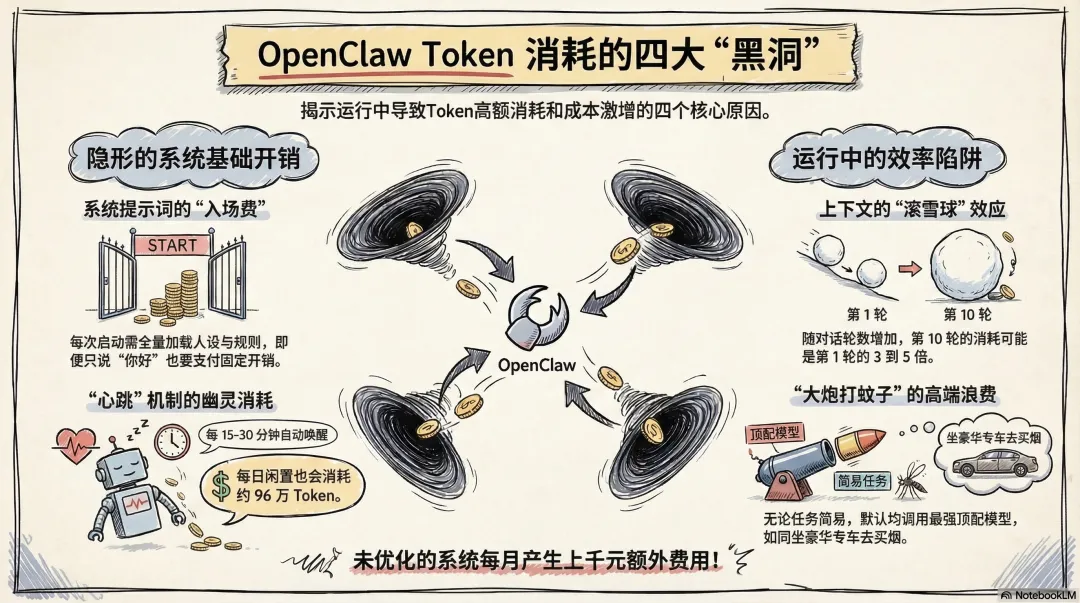
1.系统提示词的"入场费"
OpenClaw每次启动,都要把完整的人设设定、工具说明、行为规则全部加载一遍。即使你只是说一句"你好",它也要先付一笔固定开销。这就像每次进餐厅,不管点不点菜,先收你一份座位费。
2.心跳机制的幽灵消耗
OpenClaw有一个"Heartbeat"(心跳)机制,默认每隔15到30分钟自动唤醒一次,检查有没有待处理的任务。听起来很贴心,但代价是即使你在睡觉,它也在烧Token,据估算心跳机制每天消耗约96万Token。
3.上下文的滚雪球
对话轮数越多,上下文窗口越长。问同一个问题,在第10轮对话里消耗的Token,可能是第1轮的3到5倍。你以为AI在变聪明,实际上它只是越来越贵。
4.大炮打蚊子
OpenClaw默认调用最强的模型完成所有任务,不管是"帮我写一篇文章",还是"将搜集的数据整理成表格",统统是顶配出手。简单任务消耗高端算力,造成极大的Token浪费。就像每次出门,不管去楼下买包烟还是去机场,都叫最贵的豪华专车。
四个黑洞叠加,一只没有优化的龙虾,每月轻松烧掉上千元。
Token消耗困局如何破解?
这里有一个更深层的问题值得讨论。
OpenClaw的逻辑是目标驱动,你告诉它要做什么,它自己想怎么做。这种自主性是它最大的魅力,但也是它最贵的原因。
一个懂事的员工,不需要每次开口都重新介绍自己、背诵公司规章;不需要每隔半小时问老板有没有新任务;不需要为了找一个文件就把公司历史档案全翻一遍。
但OpenClaw现在就是这么干的。
原因在于大语言模型本身没有持久记忆,每一次调用都是从头开始。它不是在"运行",它是在"重生",每次调用时,它需要把所有上下文塞进来,才能装作自己知道发生了什么。
这个根本性的架构问题,短期内还没有完美解法。但有一些工程手段,已经可以大幅缓解。
面对Token消耗量激增的挑战,行业正在从多个维度寻找破解之道。
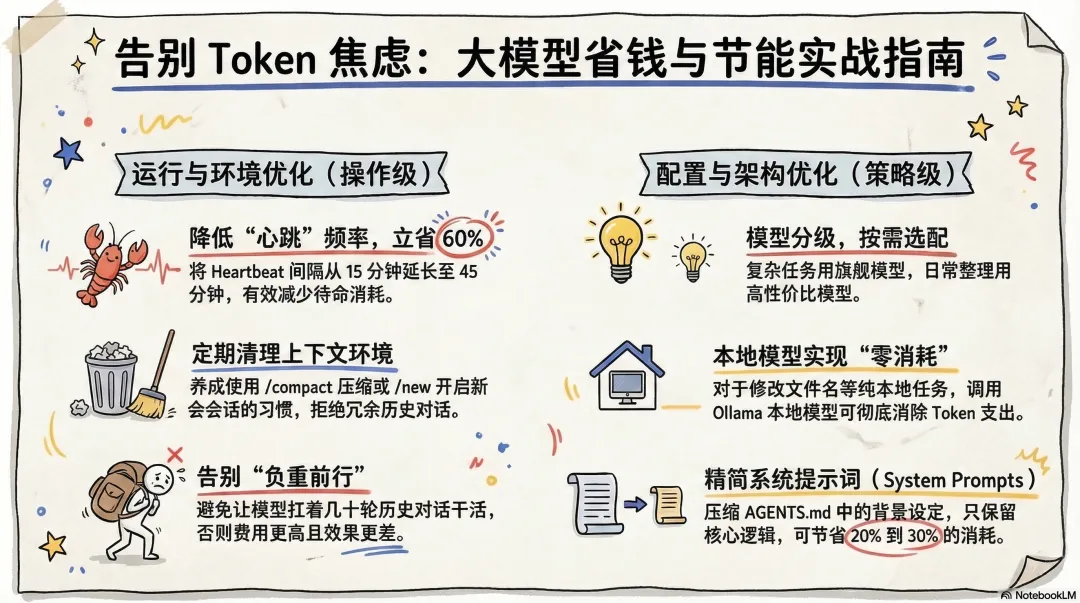
方向一:给心跳机制降频
把Heartbeat间隔从默认的15分钟改为45分钟,这一步最简单,5分钟搞定,预计节省60%以上的消耗。大部分任务并不需要龙虾随时待命。
方向二:定期清理上下文
OpenClaw提供了三个命令:/compact(压缩当前会话)、/reset(重置上下文)、/new(开启新会话)。
养成习惯,完成一个阶段的任务后,执行一次/compact;换一个话题时,用/new重新开始。不要让它扛着几十轮的历史对话继续干活,越来越贵,效果还越来越差。
方向三:模型分级,按任务选配
不是所有任务都需要最贵的模型。
复杂推理、代码设计、策略规划:用旗舰模型(Claude、Qwen3.5-Max)
日常对话、简单问答、文件整理:换DeepSeek-V3、Qwen-Turbo等高性价比模型
纯本地任务(改文件名、整理文件夹):用本地部署的Ollama模型,Token消耗归零
这一步需要配置模型路由规则,稍微有点门槛,但能节省30%到40%。
方向四:精简系统提示词
你的AGENTS.md、SOUL.md里写了多少东西?
很多人在设置龙虾人设的时候,写了大量详细的背景设定、行为规范、使用须知……每次调用都要全部加载。把这些内容压缩精简,只保留真正影响行为的核心设定,预计能节省20%到30%。
更长远的解法:国产模型的价格优势正在放大
回到最开始那个数字,4.69万亿Token,中国凭什么连续两周领跑全球?
答案藏在一个不太起眼的细节里:价格。
央视财经的报道里提到了一个对比:完成同样一个任务,海外顶级模型需要数十元,国产模型只需要3到5元。
这不是一个小差距,这是10倍以上的差价。
当养一只龙虾的成本降低到十分之一,使用频率自然就上去了。中国Token调用量领先,很大程度上是因为国产模型真的便宜,不是功能阉割版的便宜,是同等能力下的价格碾压。
而这个趋势还没有到头。摩根大通预测,中国AI推理Token消耗量到2030年将增长约370倍。一方面是使用量的爆发,另一方面,技术进步还在持续压低单Token成本。
这意味着,Token焦虑,本质上是一个时间问题。
短期内,养虾确实要精打细算;但两三年后,当模型推理成本再降一个数量级,今天花几百元的消耗,可能只需要几十元。
最后,可能有人会问,现在养虾,值不值?
这主要取决于龙虾能帮你做什么。如果你的日常工作中包含了大量重复性内容、信息整理收集等任务,你可以自行算一笔账,来判断要不要养这只虾。
参考:
https://news.cctv.com/2026/03/23/ARTIY9NK61T7g6W0jjQighKR260323.shtml
https://www.tmtpost.com/7914734.html

