 夜雨聆风
夜雨聆风
你好,我是桑小坨,一个在 AI 世界里疯狂踩坑的普通人。
早上玩 OpenClaw 玩得正起劲呢,小龙虾突然给我来了个"罢工"。
输入指令,只会回复我:API rate limit reached. Please try again later.
这是一大早就开始摆烂?我连着追问了好几遍,仍旧是这个答复。
没办法,只好翻出另外一个平台的 API Key,继续干活。
后来一直在琢磨龙虾这是怎么了,直到晚上听老师直播才恍然大悟——原来百万 Token 是被自己一点点耗没的。
01 罪魁祸首:/status 命令揭开真相
老师讲了一个超级简单的命令:/status
输入后,小龙虾唰唰唰给我回了一大串数据。
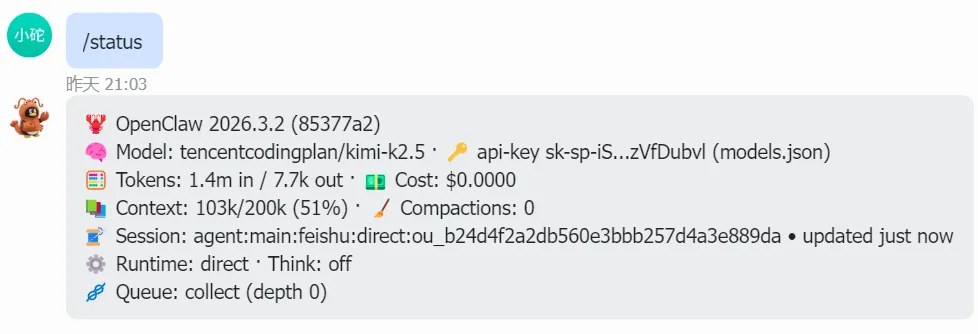
说实话,第一眼看上去全是英文和数字,头都大了。我让龙虾逐个解释一下:
🦞 OpenClaw 2026.3.2 —— 这是小龙虾的版本号,就像手机 App 的版本一样。
🧠 Model: tencentcodingplan/kimi-k2.5 —— 这是它现在用的"大脑",调用的是腾讯云的 Kimi 模型。
🧮 Tokens: 1.4m in / 7.7k out —— 这就是今天的"天价账单"!我发给它 140 万个 Token(大概 100 多万字),它回复了 7700 个 Token。
💵 Cost: $0.0000 —— 显示 0 是因为 Coding Plan 是包月制,不按 Token 计费,这个一般不准。
关键要看 Context!
📚 Context: 103k/200k (51%) —— 这就是上下文!103k 是已经用掉的记忆空间,200k 是上限,51% 是用了一半多。当这个占比在50%~70%以上时,就要使用compact指令进行压缩。
🧹 Compactions: 0 —— 这是我用了多少次 /compact 压缩命令。Compaction的作用是当对话历史很长时,把早期消息总结成摘要,腾出上下文空间。
我的压缩次数是 0,说明从来还没压缩过,每次上下文都会把历史记录带进去,白花花的 Token 就这么流走了……
02 我是怎么"作死"的
回头看我的操作,简直是教科书级的浪费示范。
首先,我特别喜欢在一个对话里一直聊,从来不用/new命令开启新的会话,导致上下文越堆越多。
Context: 103k/200k (51%),每次发新消息,小龙虾都要把前面八竿子打不着的内容全看一遍,Token 能不多吗?
其次,Compactions: 0,从来不压缩上下文,活该 Token 用得快。
第三,前面包月套餐用惯了,我有点大手大脚,从不节约。
养了两只龙虾进行赛马,一个问题本地部署、云端部署龙虾同时问,相当于2倍的消耗,所以换成kimi-code模型后使用额度很快爆表。
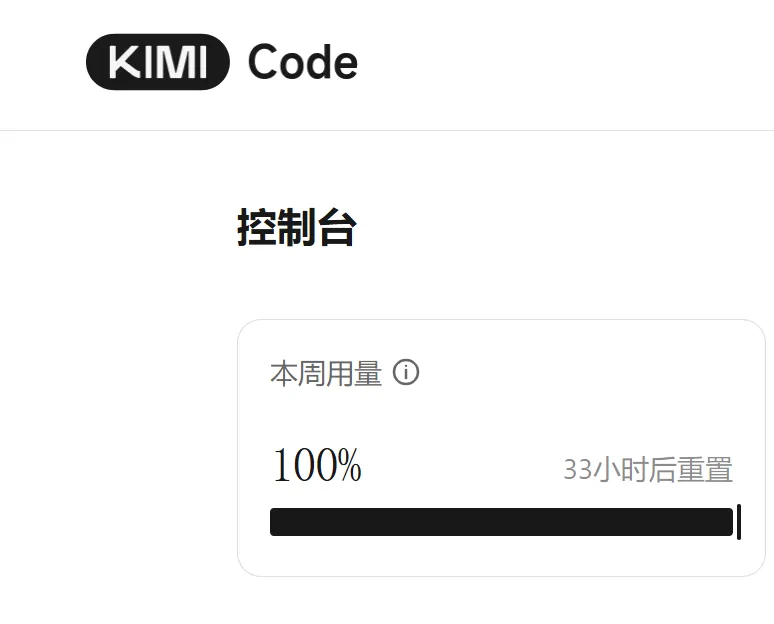
百万 Token 就是这么耗没的。不是养小龙虾太贵,是我太不会用了。
03 两个救命命令:compact + new
知道了问题,解决起来其实很简单。
第一个:/compact
这个命令可以帮你腾出上下文空间。当你感觉对话越来越长、回复越来越慢的时候,输入 /compact,小龙虾会把之前的对话压缩成一份简洁的摘要。
压缩完之后,再看 Context里的百分比会变小, Compactions 数字会从 0 变成 1、2、3……每多一次,就表示你又省了一笔 Token!
第二个:/new
完成一件大事之后,别犹豫,直接 /new 开启新对话。比如写完一篇文章、查完一个资料、调试完一段代码,马上 /new。
别让旧对话的包袱拖累你。
写在最后
说实话,养龙虾还是得学点东西,不能瞎养。
我现在过段时间总会记得 /status 看下最新的消耗,/new一下,根据context占比,/compact一下。
这些简单的小技巧,让我觉得,我再也不是那个乱花Token的小白啦。
我在做一个面向普通人的 AI 智能体入门社群。
我会把我学习智能体的笔记、配置步骤、踩过的坑、调教 AI 的实战经验,全部分享出来。
AI 时代,一个人走得快,但一群人走得远。
欢迎关注我的后续动态,也可联系我的地球号 candyzh914 进行链接。
我是桑小坨,关注我,获取更多 AI 实用技巧!
往期文章:
