夜雨聆风
夜雨聆风
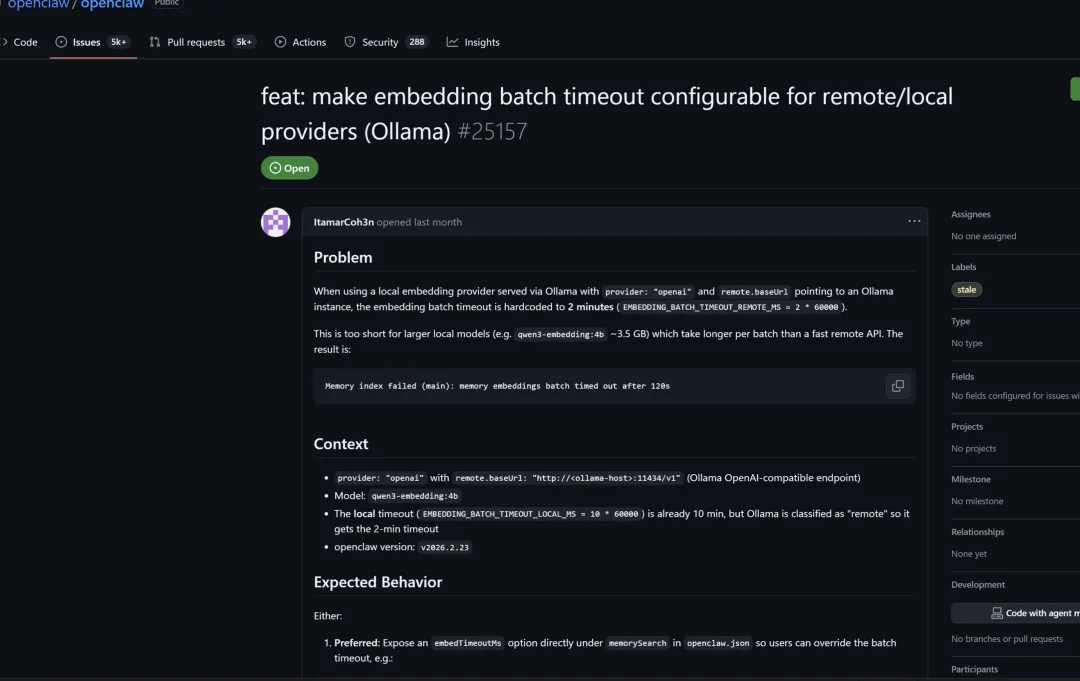

“养虾人”必看
故障描述Ollama本地部署模型超时无返回:
已有 issue 显示,OpenClaw 在接本地模型时,常见表现不是立即报错,而是一直等到超时边界才失败。有用户明确反馈:健康检查、models 接口、甚至直接 curl 都正常,但嵌入式 agent 还是会等满配置的 timeout 后失败,这更像是客户端请求处理、SSE/流式兼容、连接等待逻辑或 provider 适配路径有问题。
公开问题里已经出现了“配置的 timeout 不被正确尊重”的报告,也就是你以为自己调大了超时,实际上 agent/channel/tool 某一层仍然按内部默认时间截断。另一边,Ollama 自身在加载大模型或冷启动时,也存在 5 分钟级别的 runner 启动超时报错案例。两边叠加后,用户就会感知成“OpenClaw 一到 2 分钟左右就卡死”。
聊天推理是“单次长请求”,而 embedding / memory search 更像“一堆短文本连续批量向量化”。在这种模式下,只要存在以下任一问题,就会被迅速放大:
模型首次加载慢
CPU-only 或显存不足导致吞吐很低
OpenClaw 批量切片过大
provider 适配层对 Ollama 的 /v1/embeddings 或 /api/embeddings 处理不一致
runtime 路径与 CLI 路径不一致
这些问题在 OpenClaw 的 memory/Ollama 相关 issue 里都能看到侧面印证。
有些 case 不是直接告诉你 embedding 超时,而是表现成:
memory recall 为空
memory_search 被标记 disabled
模型像“失忆”一样回答
CLI 可用,runtime 不可用
这类问题对安全团队最烦,因为它会让研发误判为“数据没进库”或“模型能力差”,实际是向量检索链路已经失效。

一、问题表现
安全团队在排查 OpenClaw 本地部署方案时,发现 memory/embedding 链路存在典型“卡死级”问题:本地 Ollama 明明能正常响应 curl,但 OpenClaw 在 embedding 批处理阶段却会长时间阻塞,最终触发超时,严重时表现为 memory_search 静默失效、会话“失忆”、工具链响应中断。公开 issue 也显示,CLI、健康检查和 models 接口可用,并不代表运行时 agent 调用一定可用。
二、为什么本地 Ollama 更容易出问题
因为本地部署通常没有云端 embedding 服务那样的弹性和吞吐。Ollama 在冷启动、模型装载、CPU 推理或显存紧张时,单个 embedding 请求延迟会显著上升;一旦 OpenClaw 继续按批量方式提交文本切片,请求就会排队堆积。再叠加 OpenClaw 近期暴露出的 timeout 未完全按配置生效、runtime 与 CLI 行为不一致等问题,最终就形成了“2 分钟左右卡住然后失败”的典型故障画像。

三、根因拆解
根因至少包括四类:
第一,本地 embedding provider 适配不稳定,尤其是对 OpenAI-compatible / Ollama endpoint 的兼容路径;第二,批处理策略过于激进,文本切片过多时会把本地推理服务压满;第三,超时配置存在多层实现,用户调整某一层并不能保证整条链路都放宽;第四,错误反馈不透明,导致运维只能看到“无结果”而不是明确的 embedding 超时。

如果 CLI 正常而 runtime 不正常,基本就能锁定是 OpenClaw 运行时路径的问题,而不是 Ollama 服务挂了。
四、风险影响
这类问题对智能体系统的影响比普通聊天超时更大。因为 embedding 失败后,最先失效的是记忆检索、知识召回、上下文补全和长期记忆更新,最终让智能体看起来像“越来越笨”。对安全团队而言,这会直接影响告警归因、事件时间线还原、知识库检索和自动化分析链路。
Ollama默认配置为了更好让模型高效运行,默认加载到显存的实例为1,这样通过API访问是正常的不会超时。而Openclaw在于大模型交互的时候其实做了很多事,一部分是需要走TEXT文本大模型,这里本身需要大量的Token是典型的耗时操作,而Openclaw执行调用工具确实由embedding模型来调用,那么也就是说前期加载的单实例大模型比如Qwen3.5-122B参数,这时候还没有执行完,而embedding模型此时还没有记载,而Openclaw需要等待两个模型返回的结果做决策制定动作。需要我们对于Ollama配置进行优化调优,我们调优方案如下:
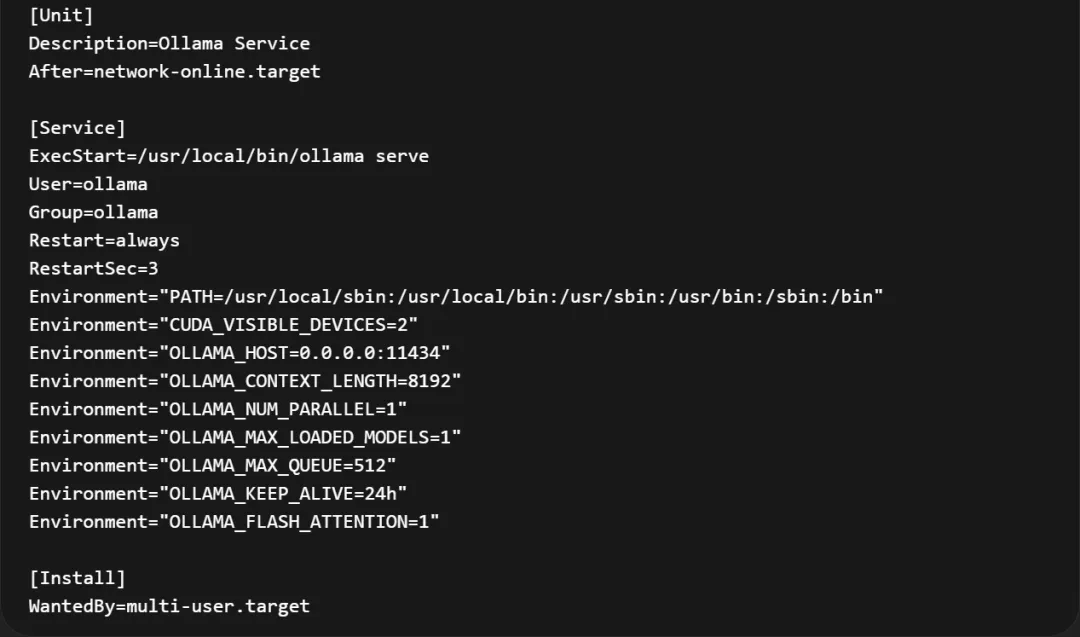
这里需要把一次能加载的最大模型模型记性调整,需要设置为>=2,然后让模型预加载到显存中。这样也就说文本生成与embedding

随着龙虾项目的持续爆火,人工智能与开源软件相关的安全问题也被迅速推上风口浪尖。无论是本地部署大模型、调用开源组件,还是构建智能体工作流,背后都伴随着权限管理、数据泄露、供应链投毒、模型滥用、提示词注入等一系列值得重视的安全风险。很多人开始意识到,真正决定项目能否长期稳定落地的,不只是功能强不强,更是安全做得够不够扎实。
如果你也对 AI 安全、开源软件安全、本地大模型部署、OpenClaw、Ollama、智能体攻防 等方向感兴趣,欢迎加入我们的交流群,一起学习交流、分享经验、讨论实战案例。这里不仅有一线技术讨论,也有部署踩坑经验、安全风险分析和解决思路分享。与其一个人反复踩坑,不如和更多同行一起成长。
扫码 进群一起学习 交流