 夜雨聆风
夜雨聆风
OpenClaw昵称“小龙虾”,是一款开源、可自主执行任务的 AI 智能体执行网关。近期“小龙虾”的爆火,让不少企业尝试将它打造成属于自己的AI员工。
相对于通用大模型的泛化能力,OpenClaw的核心价值在于可迭代的Skill能力体系,它的技能覆盖文档智能解析、业务流程自动化、多轮客户咨询等等这些高频场景,就如同企业雇佣了可灵活调整分工、7×24小时在线的“AI数字员工”。

训练“小龙虾”:试用期转正所面临的挑战
要让“小龙虾”真正融入企业运营体系,需要经历一段“训练期”。然而,高成本的token消耗与有限的记忆能力成为了两大瓶颈。
企业希望Openclaw能像正式员工一样熟悉业务规范、掌握流程细节、累积历史经验,但基于公有云大模型的“训练”方式消耗的Token成本高居不下,同时由于基础的记忆力功能薄弱,还存在“小龙虾”突然失忆的情况。
所以训练“小龙虾”的正确方式,不是重新预训练大模型,而是围绕业务场景进行Skill精调与知识注入。通过投喂企业制度文件、历史工单与最佳实践案例,并结合人类反馈机制(RLFH),持续优化其任务判断、话术表达与逻辑流程,让数字化员工真正成长为“懂业务”的专家型AI助手。
成本破局
选对方案私有化部署,token成本省到底
绝大多数用户使用 OpenClaw 时,都会优先选用云服务商的在线模型。这种方式虽便捷开箱即用,但对刚入职的“小龙虾”而言,仅仅熟悉工作带来的 tokens 消耗与成本就已经相当惊人。
作为英伟达 NPN 合作伙伴,华讯网络基于Nvidia DGX Spark 算力设备,在本地完成了 NVFP4 量化精度的 Qwen3.5-122B 大模型部署。该方案在充分保障模型推理速度的同时采用大参数量模型,彻底打破了 token 成本枷锁,让 OpenClaw 能更智能地优化工作流程,助力 “小龙虾”低成本培训,快速通过试用期!
令人振奋的是在本次2026 NVIDIA GTC 大会上,NVIDIA 为 DGX Spark 推出全新集群功能,可让最多四台Spark通过ConnectX网络组成 AI 集群!同时官宣了专为 OpenClaw 生态优化打造的搭配 NemoClaw 软件栈,与 DGX Spark 深度整合形成全栈式 AI 开发平台降低 AI 研发门槛,适配智能体时代需求,助力企业本地化开发与扩展,彰显其全栈 AI 生态布局。

依照华讯网络的私有化部署与算力优化方案部署,企业可在确保数据安全的前提下,将单次推理成本降至云上模型的1%以下,在全生命周期内实现显著的TCO优势。
培训质量保障
底层记忆基建 + 上层规范治理
打造“过目不忘”的数字化员工
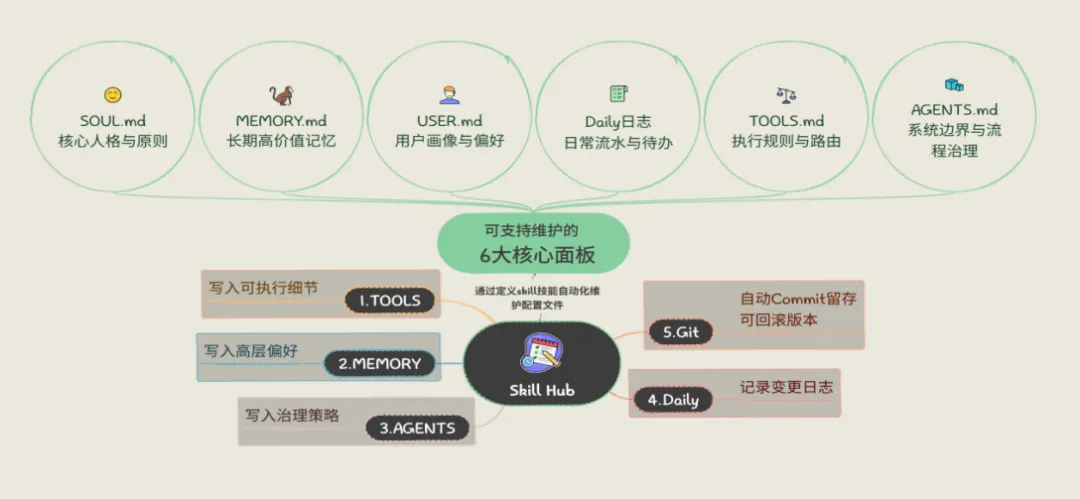
OpenClaw出现记忆缺失与 token 消耗过高的核心问题,根源在于两方面:一是原生架构无持久记忆模块,上下文窗口超限后就会丢失过往调试细节、任务经验,多智能体协作时无法共享背景,重复沟通大幅拉低效率;二是使用者普遍存在使用误区,将人格设定、用户偏好、执行规则、日常流水等全部内容塞入单一 MEMORY.md 文件,导致核心信息检索混乱、模型频繁 “失忆”,同时每轮对话全量加载冗余内容,直接造成 token 消耗激增,尤其给新人带来极高的使用成本。
针对该痛点,华讯网络探索出了两套成熟的解决方案:
1、为 Openclaw添加MemOS 开源专属记忆插件,采用 MIT 免费开源协议,支持本地 + 云端双存储模式,通过双通道检索提升记忆精度,可自动沉淀可复用技能、实现多智能体记忆共享,实测 token 消耗大幅降低,部署便捷且配套可视化管理面板,兼顾隐私安全与使用效率。
2、对Openclaw进行记忆体系优化,拆分 8 层交互配置文件,明确各文件职责与内容入库标准,搭配 QMD 检索系统仅注入核心命中片段,最高可降低 88% token 消耗,同时配套记忆同步、自动审核的自动化 Skill,实现配置合规管控与自动化运维,彻底解决失忆与资源浪费问题。
经实测两套方案可以搭配使用,能够形成「底层记忆基建 + 上层规范治理」的强互补全链路优化体系,实现 1+1>2 的效果。


华讯网络:让每一个AI员工都能创造真实价值
OpenClaw这只“小龙虾”,为企业尝试培养数字化员工提供了解决方案,而支撑这一转变的核心,正是成本可控的算力基座与高质量的知识记忆体系。华讯网络作为可信赖的行业数字化服务商始终携手厂商生态,致力于为企业客户提供紧贴业务场景中的AI解决方案,助力千行百业实现AI时代下的快速转型。







