 夜雨聆风
夜雨聆风这两天如果你连续看 OpenClaw 的官方文档,会发现一个很有意思的现象:
它最核心的描述,已经不是“某个 Agent 会不会做事”,而是 Gateway、sessions、routing、nodes、bindings 这些词。
这说明一个变化。
OpenClaw 真正想做的,已经不是一个单点聊天机器人,而是一套把聊天入口、Agent 运行时、会话状态和多 Agent 路由统一收住的控制平面。
这也是为什么,今天如果只把 OpenClaw 理解成“一个能接飞书、钉钉、微信的 AI”,其实会低估它很多。
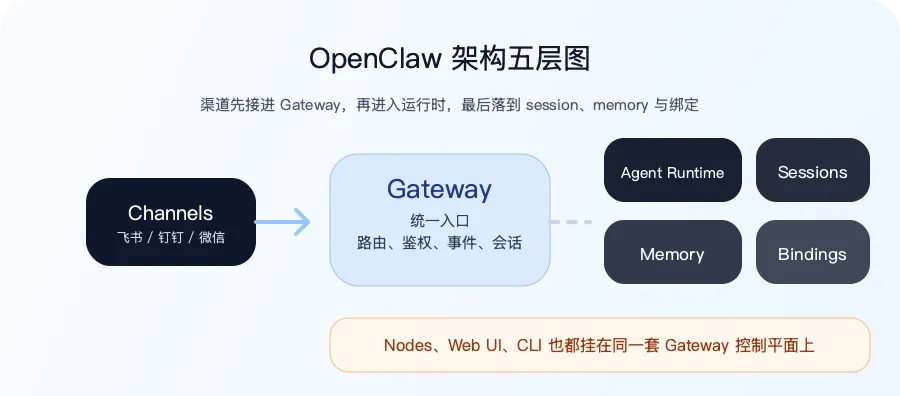
一、先说结论:OpenClaw 的架构核心不是模型,而是 Gateway
截至 2026 年 3 月 27 日,OpenClaw 官方文档里有一句话非常关键:
The Gateway is the single source of truth for sessions, routing, and channel connections.
这句话几乎已经把整个系统的架构重心说完了。
也就是说,在 OpenClaw 这套系统里,模型当然重要,Agent Runtime 当然也重要,但真正把全局拢住的,不是模型层,而是 Gateway。
如果把它翻译成人话,就是:
所有聊天渠道先接到 Gateway 所有客户端和节点也先接到 Gateway session、routing、channel connection 这些全局状态都先由 Gateway 统一管理 Agent 不是四散运行,而是在这套控制平面里被调度
这和很多人想象中的“本地起一个 AI 助手,顺手接几个插件”完全不是一回事。
二、为什么说它更像控制平面,而不是普通 Agent?
因为普通人理解“Agent 架构”时,脑子里往往是这一条线:
用户发消息 模型理解 工具执行 返回结果
这当然没错。
但 OpenClaw 的官方架构文档,把问题拆得更系统。
它至少明确了 5 层:
1. 渠道层:所有真实入口先被统一接住
官方首页和 Gateway Architecture 页面都强调,OpenClaw 的入口不是单一聊天框,而是多渠道:
飞书 钉钉 微信 以及其他消息渠道
这意味着它一开始就不是网页 demo 思维,而是:
先把真实通信入口统一起来。
一旦你从这个角度看,OpenClaw 就不再像“一个 App”,而更像“一个入口汇聚层”。
2. Gateway 层:它才是整套系统的总线
官方文档把 Gateway 定义得非常清楚:
它是一个 single long-lived Gateway 对外暴露 typed WebSocket API 负责 provider connection、请求响应和 server-push events 还负责 health、heartbeat、presence、cron这类系统事件
这意味着 Gateway 不是一个轻量转发器,而是系统的主控层。
你可以把它理解成三件事的结合:
通信总线 控制平面 状态协调器
这也是为什么我觉得,OpenClaw 真正难的地方不是“模型接没接上”,而是 Gateway 把没把全局状态收住。
三、Agent Runtime 在这套架构里,到底扮演什么角色?
很多人第一次看 OpenClaw,会把 Agent Runtime 当成“系统本体”。
但从官方文档看,它更像是被挂进控制平面里的执行核心。
官方的 Agent Runtime 页面确认了几件事:
OpenClaw runs a single embedded agent runtime 它有一个默认 workspace,当作工具和上下文的工作目录 首轮 session 会注入 AGENTS.md、SOUL.md、TOOLS.md、USER.md等 bootstrap 文件内建工具一直存在,但受 tool policy 约束 skills 来自 bundled、 ~/.openclaw/skills和 workspaceskills/
这里最关键的一点是:
OpenClaw 并没有把 Agent 当成一个孤立进程,而是把它放进 workspace、prompt 注入、tool policy、skills 加载这些边界里。
也就是说,Agent 不是赤手空拳直接面对世界。
它在一个被预先定义好的运行结构里做事。
这会直接带来两个结果:
运行行为更可控 用户更容易把 persona、规则、技能和工作目录做成稳定配置
四、为什么 session 和 memory 也是架构核心,而不只是附属功能?
因为 OpenClaw 不是一次性问答系统。
官方文档反复强调的一件事是:它是 stateful 的。
比如:
session transcript 会落到 ~/.openclaw/agents/<agentId>/sessions/<SessionId>.jsonl每个 agent 都有自己的 session store multi-agent routing 下,不同 agent 的 session 和 auth 是隔离的
这意味着在 OpenClaw 里,聊天记录不是“顺手存一下”。
它本身就是整个架构的一部分。
为什么这很重要?
因为一旦系统同时面对:
多渠道 多 agent 多个 accountId 多个 sender / peer
如果没有稳定的 session 设计,整个系统很快就会混乱。
你可以想一想一个非常现实的使用场景。
如果同一个 OpenClaw 同时接着:
你的微信 团队的飞书群 某个独立 agent 的专属入口 另一个 agent 绑定的自动任务
那系统每一条消息都必须先回答几个问题:
这条消息属于谁 它应该进入哪个 session 它该落到哪个 agent 它是否应该继承之前的上下文
如果这些边界不清楚,后果会非常直接:
上下文串台 身份混淆 一段聊天莫名继承另一段任务历史 某个 agent 读到了本来不该看到的上下文
所以 session 设计在 OpenClaw 里不是“用户体验优化”,而是 系统正确性 的一部分。
这也是为什么它把 transcript 落盘、把 session store 独立、把 auth 和 agent 身份隔离,都做得这么明确。
1. session 解决的,不只是记忆,而是边界
很多产品讲 session,喜欢把它包装成“连续对话更聪明”。
但 OpenClaw 这里更底层。
session 的第一个作用不是增强智能,而是定义边界:
哪一段消息算同一次交互 哪些历史可以继续继承 哪些上下文应该被切断 哪些 agent 可以继续访问这段历史
只有这层先明确,后面的 memory 才不会变成“越记越乱”。
换句话说:
memory 的价值成立,前提是 session 的边界先成立。
2. memory 在这里也不是“无限记住”,而是“按结构留下可复用状态”
很多人听到 memory,第一反应是:
“它是不是能一直记住我说过的话?”
但从架构角度看,真正重要的不是“记得久不久”,而是“记得稳不稳、归属清不清”。
因为对 OpenClaw 这种多渠道、多 agent 系统来说,memory 如果只是一个大杂烩缓存池,风险反而更高。
真正有价值的 memory,一定要回答这些问题:
记忆属于哪个 agent 它来自哪个 session 它和哪个身份绑定 什么时候该继续用,什么时候该丢弃
所以我会把 OpenClaw 这里的 memory 理解成:
不是单纯追求“更多记住”,而是让状态能被稳定归档、稳定继承、稳定隔离。
这件事听起来没有“超长上下文”那么炫,但它对真实系统更重要。
因为系统最怕的从来不是“忘了一点”,而是“记错了人、记错了场景、记错了归属”。
3. 从架构价值看,这一层决定了它能不能走向长期运行
如果没有稳定的 session 和 memory 结构,OpenClaw 顶多像一个会接渠道的 demo。
因为 demo 只需要回答一件事:
这次能不能跑通
但长期运行要回答的是另一组问题:
明天还能不能接着跑 这个 agent 的历史还能不能追 某次失败是不是能回放 某个身份的上下文是不是能单独保留
只要系统开始面对长期运行,这一层就会立刻从“附属功能”变成“基础设施”。
所以你会发现,OpenClaw 文档在讲多 Agent 时,首先讲的不是人格切换,而是:
workspace 隔离 agentDir隔离 session store 隔离 auth profiles 隔离
换句话说,它先解决的是状态边界,而不是表面上的“多几个角色”。
五、OpenClaw 的多 Agent,真正厉害的地方不是能分身,而是能绑定
前几天我们已经写过“三省六部制”那个角度。
但如果只从系统架构看,多 Agent 这部分还有一个更硬的点:
binding。
OpenClaw 的 Multi-Agent Routing 文档把这件事写得很清楚:
一个 agent 不是一段 prompt,而是一整套隔离出来的 brain 每个 agent 都有自己的 workspace、agentDir、session store inbound message 会通过 bindings 决定路由到哪个 agent bindings 还支持 channel、accountId、peer、guildId、teamId等多种匹配条件
这就意味着,OpenClaw 的多 Agent 不是“开几个小号一起讨论”。
而是:
先把不同 Agent 的边界划清楚,再用 routing rule 把不同入口稳定送进对应 Agent。
这个架构意义很大。
因为它让“一台 Gateway 对外服务多个入口、多个身份、多个工作脑”这件事真正成立了。
这里最值得注意的,其实不是“多 agent”这三个字,而是 binding 规则是架构级对象。
很多系统讲多 Agent,实际做法往往是:
先开几个角色 再在 prompt 里告诉它们怎么分工 最后临时决定某条消息该发给谁
这种方式做 demo 很快,但一旦进入真实环境,就会很脆。
因为它没有解决一个核心问题:
入口和 agent 之间,到底是什么关系?
OpenClaw 给出的答案不是“临时判断”,而是“先建立绑定关系”。
1. binding 的价值,是把“哪个入口归哪个脑子”固定下来
这件事非常关键。
因为真实世界里的 agent,不是漂浮在半空中的。
它总要挂在某个具体入口上:
某个微信号 某个飞书 bot 某个群聊 某个团队空间 某个 accountId 下的独立身份
如果没有 binding,每次收到新消息,系统都得重新判断:
这是给谁的 应该调哪个 agent 该不该继承某段旧上下文
这不仅成本高,而且非常不稳定。
binding 的作用,就是把这种不稳定判断前置成显式规则。
一旦规则成立,系统收到消息时就不是“猜”,而是“按绑定表路由”。
2. 这会把多 Agent 从“协作想象”变成“可运维结构”
为什么很多多 Agent 方案看起来很美,但落地很难?
因为它们更多停留在“认知分工”层:
这个负责规划 那个负责执行 另一个负责审查
这当然重要。
但如果没有入口绑定和状态隔离,这种分工很容易停留在论文图里。
OpenClaw 的多 Agent 更往前走了一步:
agent 有独立 workspace agent 有独立 session store agent 有独立 auth profile agent 通过 binding 挂到具体入口
这时它才不只是“几个角色一起演戏”,而是“几个真正可独立运行、可独立管理的工作脑”。
所以我会说,OpenClaw 的多 Agent 更像是 多租户系统设计,而不只是“多角色 prompt 工程”。
3. binding 还意味着系统可以长期长大,而不是越长越乱
你可以把它想象成一台总机。
如果没有 binding,这台总机每接一个新入口,复杂度都会上升:
新加一个飞书 bot,要重新写判断 新挂一个微信群,要重新定义上下文 新建一个专用 agent,要重新处理消息归属
系统会越来越像一团 if-else。
但如果 binding 是正式架构对象,扩展路径就会清楚很多:
新增一个入口,就新增一条绑定 新增一个 agent,就给它配置独立边界 新增一个团队或群组,就让路由规则按标识命中
这时候系统扩展的方式,就从“不断补例外”变成“不断加规则”。
这是两种完全不同的工程质量。
前者会越做越脆,后者才可能越长越稳。
4. 从产品视角看,这一层也决定了 OpenClaw 能不能真正服务多人
如果你只是自己本地玩一个 agent,其实不太会意识到 binding 有多重要。
但一旦场景变成:
一个团队同时用 多个渠道同时接 不同 agent 对外扮演不同身份 有的 agent 只服务某个群,有的只服务某个人
你就会发现,这层几乎决定了产品能不能上线。
因为多人系统最怕两件事:
消息发错脑子 上下文串错身份
而 binding 本质上就是在解决这两个问题。
所以我会说,OpenClaw 的多 Agent 设计,真正值钱的不是“能分身”,而是:
它把多 Agent 的入口归属、状态归属和身份归属都做成了明确结构。
六、Nodes 的加入,让 OpenClaw 不只是聊天系统
官方 Gateway Architecture 里还有一块很容易被忽略,但其实非常重要:
Nodes 也通过 WebSocket 接进同一个 Gateway。
文档里能确认的例子包括:
canvas.*camera.*screen.recordlocation.get
这意味着什么?
意味着 OpenClaw 不只是把“消息”接进来,它还在把“设备能力”也接进来。
从系统结构上看,这相当于又多了一层:
Channels 负责消息入口 Gateway 负责统一控制 Agent Runtime 负责推理和执行 Nodes 负责把设备能力挂进来
一旦把这层也看进去,你就会发现 OpenClaw 的目标远不止“做聊天”。
它更像是在做一个:
以 Gateway 为中心,把消息入口、Agent 脑、工作空间、设备节点统一编排起来的系统。
七、这套架构最值钱的地方,到底是什么?
我觉得不是“功能多”,而是 层次清楚。
如果只讲功能,很多项目都可以说自己支持:
多渠道 多 Agent 工具调用 会话记忆
但 OpenClaw 的架构价值在于,它没有把这些东西全堆在一个黑箱里。
从官方文档可确认的信息看,它至少把下面几层拆开了:
Gateway 负责全局控制 Agent Runtime 负责运行时 workspace / bootstrap files 负责行为边界 sessions / auth / state 负责隔离 bindings 负责路由 nodes 负责设备能力接入
这会让整套系统更适合往真实环境里长。
因为当系统开始面对多人、多号、多渠道、多设备时,真正先崩的,从来不是模型智力,而是:
路由乱不乱 状态串不串 身份混不混 权限清不清
OpenClaw 这套架构,本质上就是在先处理这些问题。
八、如果只用一句话概括 OpenClaw 的架构
我的概括是:
OpenClaw 不是“一个会接很多渠道的 Agent”,而是“一个以 Gateway 为中心,把渠道、会话、运行时、多 Agent 和节点统一起来的 Agent 控制平面”。
这也是为什么我觉得,分析 OpenClaw 时,不能只盯着某个功能点。
真正值得看的,是它怎么把系统层次搭起来。
因为只有这层搭稳了,后面的 skills、channels、delegates、cron、device nodes 才有可能越接越多,而不是越接越乱。
