 夜雨聆风
夜雨聆风从"会话孤岛"到"记忆贯通":一套完整的记忆管理实战指南 + self-improving-agent 技能深度解析

一、那个让人抓狂的瞬间
你有没有遇到过这样的情况?
场景一:你在飞书对话框里跟 AI 助手聊了半小时,让它帮你分析了一份项目文档。然后你切换到微信,问它"刚才分析的结论是什么?"——它一脸茫然:"您在说什么?"
场景二:你在和小创(内容官)讨论公众号选题,聊得正嗨。突然想问问小智(程序员)技术实现细节。切过去一问,小智完全不知道你们在聊什么,你不得不从头解释一遍。
场景三:今天和 AI 聊了很多重要信息,你希望它记住。明天新开一个窗口,它仿佛被"格式化"了,昨天的一切归零。
如果你遇到过以上任何一种情况,恭喜你——你踩中了 OpenClaw 龙虾(多 Agent 系统)最常见的坑:多会话窗口失忆问题。
根据我们的观察和社区反馈,90% 的 OpenClaw 用户都曾遇到这个问题,但只有不到 10% 的人真正理解背后的原因,并找到解决方案。
今天这篇文章,我会从技术原理到实战方案,手把手教你解决这个困扰。
二、为什么会失忆?—— 90% 用户不知道的架构真相
2.1 不是 Bug,是设计架构目前的缺陷
首先要澄清一个误区:这不是 Bug,而是openclaw架构设计的问题。
OpenClaw 龙虾采用多通信渠道 + 多 Agent 的架构:
• 通信渠道:自带网关、飞书、微信、Discord、Telegram... • Agent 团队:大宇(主控)、小创(内容)、小智(编程)、小闻(情报)、小彩(设计)...
每个渠道、每个 Agent,默认都是独立的会话上下文。
为什么这样设计?
但副作用也很明显:
• ❌ 用户视角:"我刚说过的话你怎么不记得了?" • ❌ 跨平台切换:飞书聊完切微信,一切归零 • ❌ Agent 协作:小创和小智像两个陌生人
2.2 记忆的三种形态
理解 OpenClaw 的记忆机制,是解决"失忆"问题的关键:
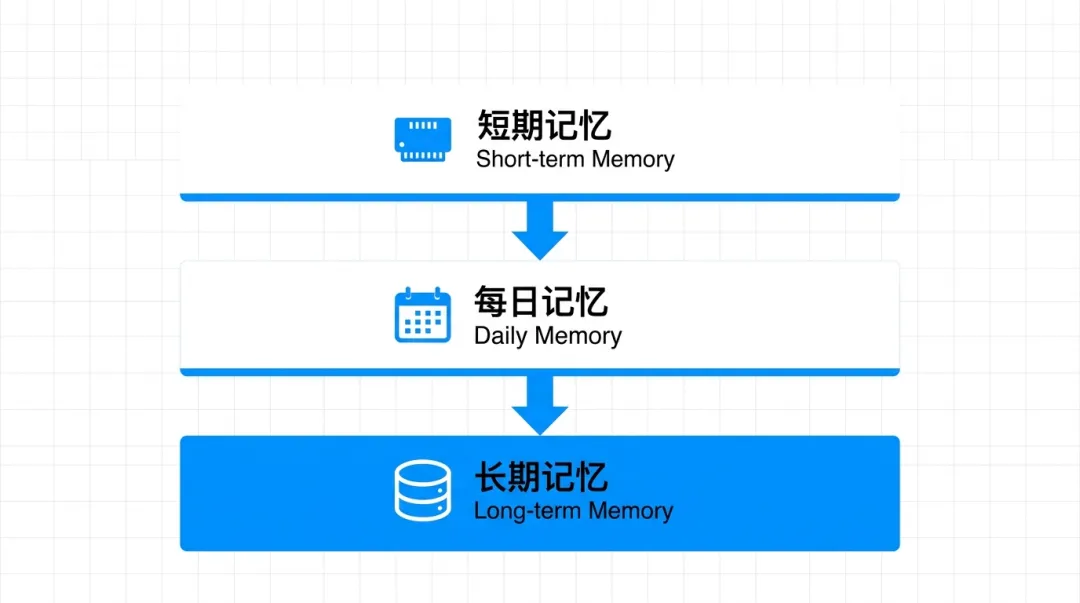
┌─────────────────────────────────────────────────────────┐│ 记忆层级架构 │├─────────────────────────────────────────────────────────┤│ Level 3 │ MEMORY.md │ 长期记忆 │ 永久保存 ││ Level 2 │ memory/2026-03-28 │ 每日记忆 │ 当日有效 ││ Level 1 │ 会话上下文 │ 短期记忆 │ 当前会话 │└─────────────────────────────────────────────────────────┘| 短期记忆 | ||||
| 每日记忆 | memory/YYYY-MM-DD.md | |||
| 长期记忆 | MEMORY.md |
核心问题:短期记忆不会自动变成长期记忆,各 Agent 之间也不会自动同步。
三、我的解决方案——定时任务 + 记忆整理系统
经过 2 周的实践迭代,我搭建了一套自动化记忆管理系统。
3.1 系统架构
┌─────────────────────────────────────────────────────────┐│ 定时任务 (每天 07:30) ││ Job ID: a8cb08fc-b941-4cf1-b96d... │└────────────────────┬────────────────────────────────────┘ ↓┌─────────────────────────────────────────────────────────┐│ 大宇 (调度中心) ││ 为 7 个 Agent 创建子任务 (timeout=180s) │└────────────────────┬────────────────────────────────────┘ ↓ ┌────────────┬────────────┬────────────┬────────────┐ ↓ ↓ ↓ ↓ ↓ 小智 小创 小闻 小彩 ... (编程) (内容) (情报) (设计) ↓ ↓ ↓ ↓ 读取会话历史 读取会话历史 读取会话历史 读取会话历史 更新 MEMORY 更新 MEMORY 更新 MEMORY 更新 MEMORY 记录 ERRORS 记录 ERRORS 记录 ERRORS 记录 ERRORS └────────────┴────────────┴────────────┘ ↓┌─────────────────────────────────────────────────────────┐│ 同步到 workspace/memory/ ││ 各 Agent 记忆汇总存档 │└─────────────────────────────────────────────────────────┘3.2 执行 Agent 团队
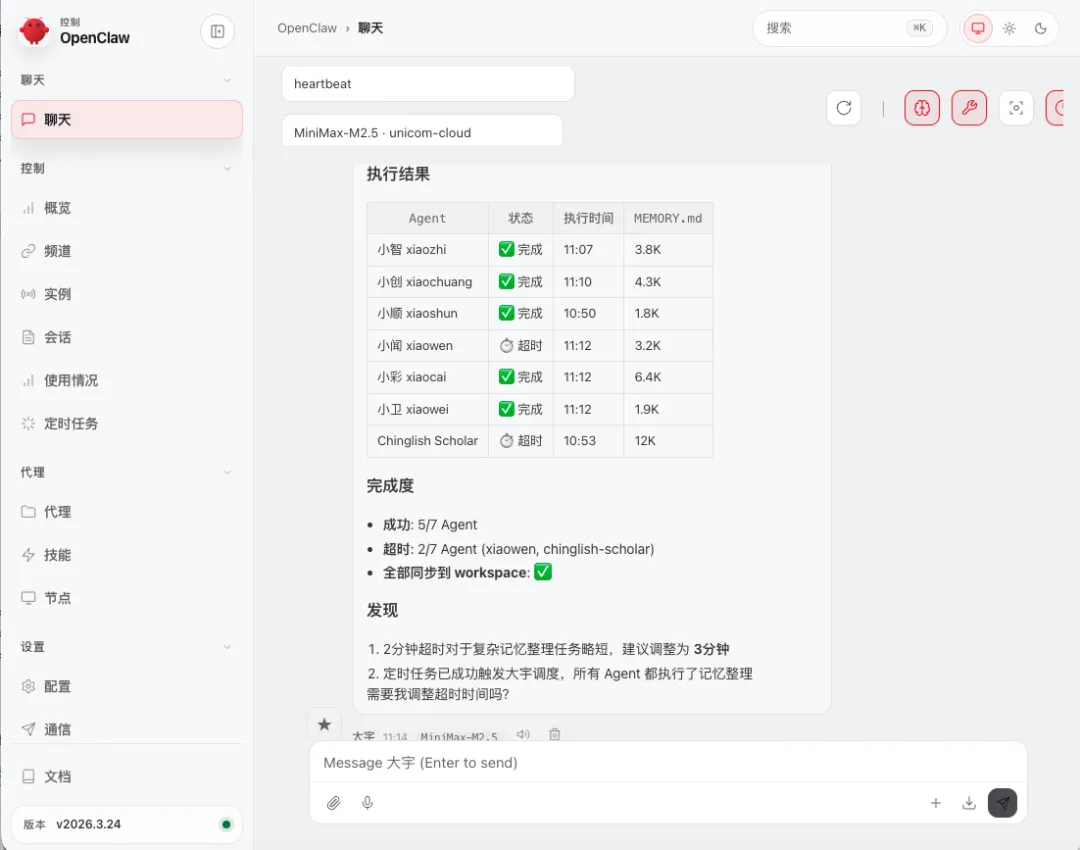
3.3 真实执行记录
我们的定时任务从 2026-03-18 开始运行,以下是今天的执行数据:
任务启动: 2026-03-28 07:30:00├── xiaozhi-memory-evolution [done] 108s├── xiaochuang-memory-evolution [done] 69s├── xiaoshun-memory-evolution [done] 32s├── xiaowen-memory-evolution [done] 65s├── xiaocai-memory-evolution [done] 104s├── xiaowei-memory-evolution [done] 68s└── chinglish-memory-evolution [done] 132s状态: 全部完成 | 平均耗时: 82s | 超时阈值: 180s关键优化:我们将超时从 120s 调整为 180s,确保复杂记忆整理有足够时间完成。
3.4 记忆整理流程(每个 Agent 执行)
Step 1:读取会话历史
• 回顾昨日所有对话 • 提取关键决策、重要信息、用户反馈
Step 2:读取 .learnings/ 目录
• 整理昨日记录的学习点 • 归类:correction(纠正)、knowledge_gap(知识缺口)、best_practice(最佳实践)
Step 3:更新 MEMORY.md
• 将重要经验沉淀为长期记忆 • 更新"已掌握技能"、"待进化技能" • 记录关键洞察和认知升级
Step 4:更新 ERRORS.md
• 记录昨日遇到的错误 • 分析原因,标注解决方案 • 避免重复踩坑 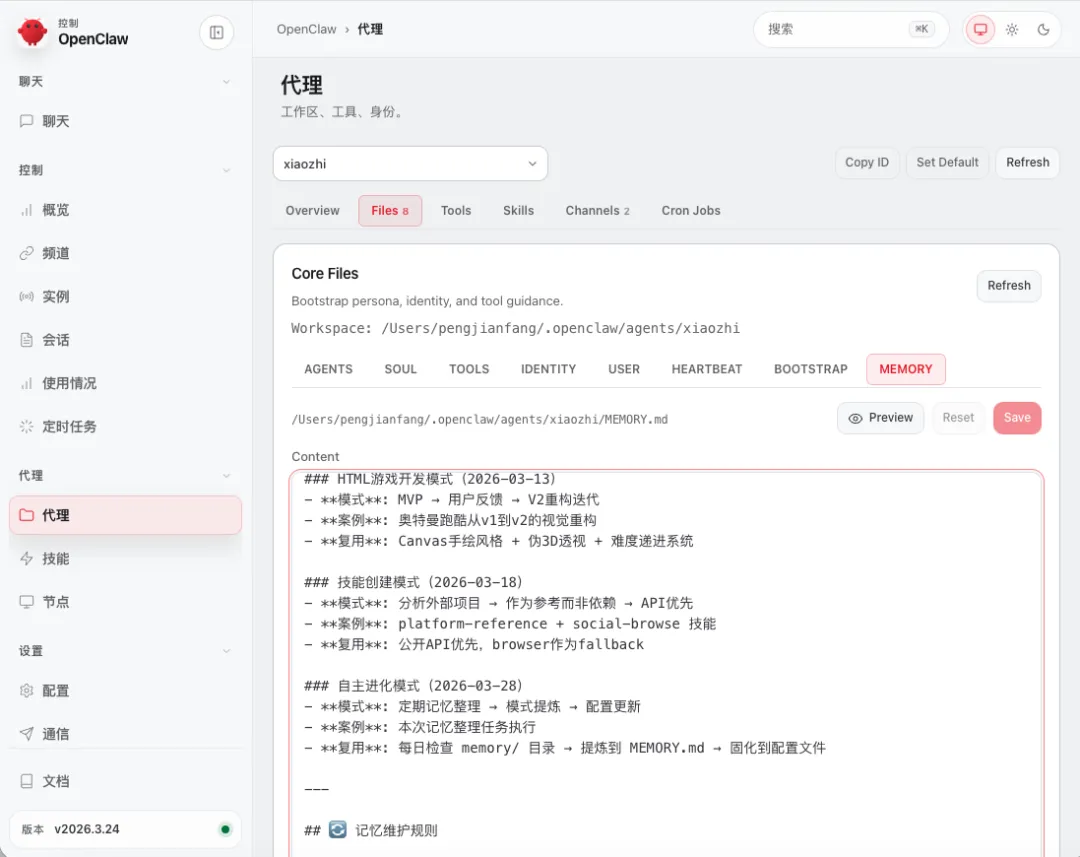
四、核心技能深度解析——self-improving-agent
4.1 为什么单独介绍这个技能?
self-improving-agent 是 OpenClaw 生态中一个极其重要的技能。它与记忆系统相辅相成,是解决"失忆"问题的关键拼图。
没有 self-improving-agent:
• 记忆只是"存档",不会进化 • 错误会重复发生 • 经验无法沉淀为能力
有了 self-improving-agent:
• 记忆成为"学习材料" • 错误被记录、分析、避免 • 经验转化为行为准则
4.2 技能核心能力
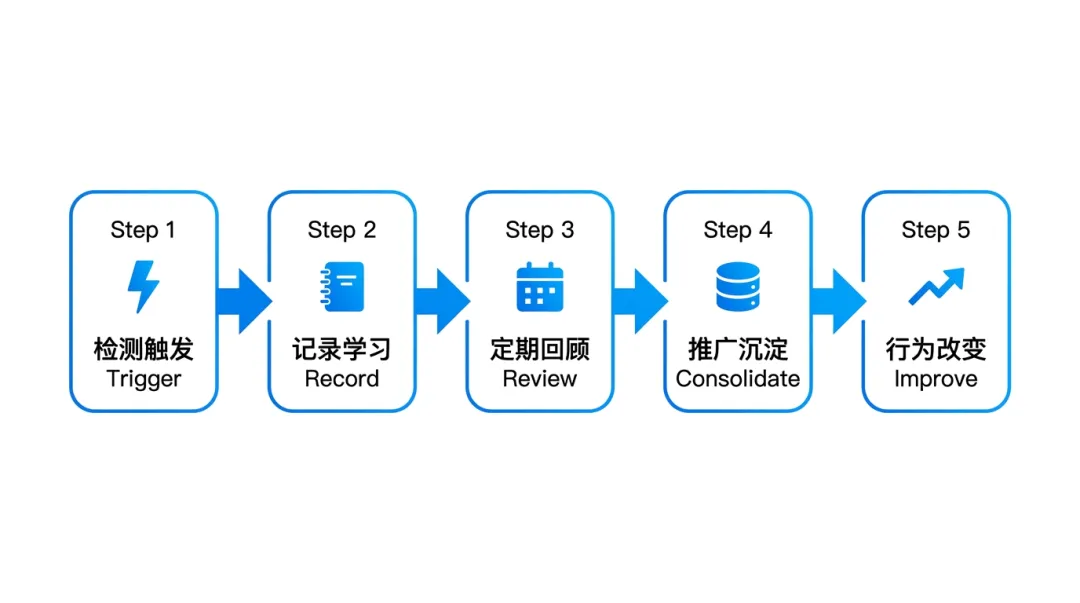
┌─────────────────────────────────────────────────────────┐│ self-improving-agent 工作流程 │├─────────────────────────────────────────────────────────┤│ 检测触发 → 记录学习 → 定期回顾 → 推广沉淀 → 行为改变 │└─────────────────────────────────────────────────────────┘.learnings/ERRORS.md | ||
.learnings/LEARNINGS.md | ||
.learnings/FEATURE_REQUESTS.md | ||
.learnings/ERRORS.md | ||
.learnings/LEARNINGS.md |
4.3 学习记录格式(实战示例)
以下是我们真实的学习记录:
## [LRN-20260328-001] correction**Logged**: 2026-03-28T11:30:00+08:00**Priority**: high**Status**: pending → promoted**Area**: content### Summary用户纠正:小红书文案字数不足 300 字,不符合平台要求### Details原文案仅 180 字,用户明确要求 300-500 字未严格遵守 SKILL.md 中的字数规范### Suggested Action1. 创作前重读 SKILL.md 规范2. 完成后自检字数3. 低于 300 字必须扩充### Metadata- Source: user_feedback- Related Files: skills/xiaohongshu-ops/SKILL.md- Tags: 小红书, 字数规范- Pattern-Key: content.word_count_check- Recurrence-Count: 2- First-Seen: 2026-03-14- Last-Seen: 2026-03-28### Resolution- **Promoted**: SOUL.md (小红书字数规范已加入行为准则)- **Date**: 2026-03-284.4 从学习到进化的路径
第一次犯错 → 记录到 .learnings/ERRORS.md ↓第二次遇到类似问题 → 搜索 .learnings/ 发现关联 ↓第三次重复 → 识别为"重复模式" (Recurrence-Count >= 3) ↓推广到 SOUL.md / TOOLS.md → 成为行为准则 ↓未来自动避免4.5 实际效果数据
运行 10 天后,我们的 AI 团队数据:
| 83%↓ | |||
| 约 70%↓ | |||
五、手把手教你搭建记忆系统
5.1 快速启动(3 步搞定)
Step 1:创建目录结构
# 创建工作区学习目录mkdir -p ~/.openclaw/workspace/.learnings# 为每个 Agent 创建记忆目录mkdir -p ~/.openclaw/agents/{your_agent}/memorymkdir -p ~/.openclaw/agents/{your_agent}/.learningsStep 2:创建记忆文件模板
~/.openclaw/agents/{your_agent}/MEMORY.md:
# MEMORY.md - 长期记忆## 我是谁- **名字**: {agent_name}- **专长**: ...## 已掌握技能 ✅- [技能 1]- [技能 2]## 待进化技能 ⏳- [技能 3]## 关键洞察> "记录你的核心认知"~/.openclaw/workspace/.learnings/LEARNINGS.md:
# 学习记录## [LRN-YYYYMMDD-001] category**Logged**: ISO-8601 timestamp**Priority**: low | medium | high | critical**Status**: pending**Area**: frontend | backend | content | ops### Summary一句话描述学到了什么### Details详细上下文### Suggested Action具体改进建议### Metadata- Source: conversation | error | user_feedback- Related Files: path/to/file- Tags: tag1, tag2Step 3:配置定时任务
在 OpenClaw 配置中添加:
{ "cron": { "jobs": [ { "id": "memory-daily", "schedule": "0 30 7 * * *", "agent": "main", "prompt": "触发记忆整理流程:调度各 Agent 执行每日记忆整理,读取昨日会话历史,更新 MEMORY.md,记录错误教训,同步到 workspace" } ] }}5.2 手动触发记忆整理
如果某天聊得特别多,想立即整理:
提示词:"请进行记忆整理:读取今日会话历史,更新 MEMORY.md,记录重要经验和错误教训到 .learnings/"
5.3 关键最佳实践
| 每天固定时间 | |
| 区分优先级 | |
| 链接相关条目 | See Also 关联相似问题 |
| 定期推广 | .learnings/ 中的内容推广到 MEMORY.md |
| 团队共享 |
5.4 💡 成本优化建议:本地模型 vs 云端模型
当前我们的方案:使用云端 AI 模型(kimi-k2.5、qwen3-max、MiniMax-M2.5 等)
原因:目前 Token 消耗在可接受范围内,云端模型理解能力更强,记忆整理质量更高。
但最优解应该是:本地模型 + 云端模型混合
┌─────────────────────────────────────────────────────────┐│ 成本优化策略 │├─────────────────────────────────────────────────────────┤│ 定时记忆整理 │ 本地模型 (Ollama/LM Studio) ││ 复杂分析任务 │ 云端模型 (GPT-4/Claude/Kimi) ││ 紧急重要任务 │ 云端模型 (保证质量) ││ 日常轻量任务 │ 本地模型 (节省成本) │└─────────────────────────────────────────────────────────┘本地模型推荐:
• Ollama: llama3.2:3b或qwen2.5:7b• LM Studio:加载 Qwen2.5-7B-Instruct• 要求:能流畅处理中文,理解长文本
配置示例:
{ "cron": { "jobs": [ { "id": "memory-daily", "schedule": "0 30 7 * * *", "agent": "main", "model": "ollama/llama3.2:3b", // 使用本地模型 "prompt": "触发记忆整理流程..." } ] }}5.5 ⏰ 定时任务时间调整建议
我们的配置:每天 07:30
但你应该根据以下因素调整:
| 工作节奏 | ||
| 使用频率 | ||
| 成本敏感 | ||
| 数据量 |
多时段配置示例:
{ "cron": { "jobs": [ { "id": "memory-morning", "schedule": "0 30 7 * * *", // 早上 7:30 "agent": "main", "prompt": "早间记忆整理..." }, { "id": "memory-evening", "schedule": "0 0 23 * * *", // 晚上 23:00 "agent": "main", "prompt": "晚间记忆整理..." } ] }}我们的建议:
• 🌱 新手:每天 1 次(07:30 或 23:00) • 🚀 进阶:每天 2 次(中午 + 晚上) • 💰 成本敏感:使用本地模型,每天 2-3 次 • ⚡ 高频用户:每 6-8 小时一次,防止记忆堆积 |
六、进阶技巧:诊断与调试
6.1 如何诊断"失忆"问题
当你发现 AI"不记得"时,按以下步骤排查:
Step 1:确认会话窗口
问题:飞书聊的内容,微信窗口不知道原因:不同渠道是独立会话解决:在当前窗口提示"请查看当前飞书会话窗口记忆"Step 2:检查记忆文件
# 查看 MEMORY.md 是否存在cat ~/.openclaw/agents/{agent_name}/MEMORY.md# 查看今日记忆cat ~/.openclaw/agents/{agent_name}/memory/2026-03-28.mdStep 3:手动触发整理
提示词:"请读取今日会话历史,更新 MEMORY.md,确保记住以下内容:..."6.2 常见误区
七、写在最后
AI 失忆不是因为"笨",而是因为架构设计选择了隔离而非共享。
理解这一点,你就不会责怪 AI"记性差",而是会主动管理记忆:
• ✅ 切到另一个窗口?先让 AI 整理当前会话记忆 • ✅ 跨 Agent 协作?先同步上下文 • ✅ 聊了很多重要内容?手动触发记忆整理 • ✅ 长期积累?搭建定时任务自动沉淀
记忆管理,本质是知识管理。
当你的 AI 助手开始"记得"你们聊过什么、"知道"自己擅长什么、"明白"什么该避免——它就不再是一个简单的对话工具,而是一个真正在成长的智能伙伴。
而 self-improving-agent 技能,就是让这种成长自动化、系统化、可持续的关键。
附录 A:我们的演进时间线
附录 B:self-improving-agent 技能安装
# 通过 ClawdHub 安装(推荐)clawdhub install self-improving-agent# 或手动安装git clone https://github.com/peterskoett/self-improving-agent.git \ ~/.openclaw/skills/self-improving-agent完整文档:https://github.com/peterskoett/self-improving-agent
附录 C:推荐阅读
• OpenClaw 官方文档[1] • Agent Skills 规范[2] • 我们的记忆整理实践[3]
💡 互动话题:你遇到过 AI"失忆"的情况吗?是怎么解决的?欢迎在评论区分享你的经验!
引用链接
[1] OpenClaw 官方文档: https://docs.openclaw.ai[2] Agent Skills 规范: https://agentskills.io/specification
