 夜雨聆风
夜雨聆风目录
1. 什么是 Agent Skills? 2. 核心设计哲学:渐进式披露机制详解 3. 技术规范:SKILL.md 格式详解 4. 目录结构与可选资源 5. Skill 的生命周期:发现、激活、执行 6. 在 Skill 中使用脚本 7. 编写高质量 Skill 的最佳实践 8. 优化 Skill 的触发描述 9. 评估 Skill 的输出质量 10. 智能体如何添加 Skills 11. 对比anthropics和openai的skills设计 12. 总结
1. 什么是 Agent Skills?
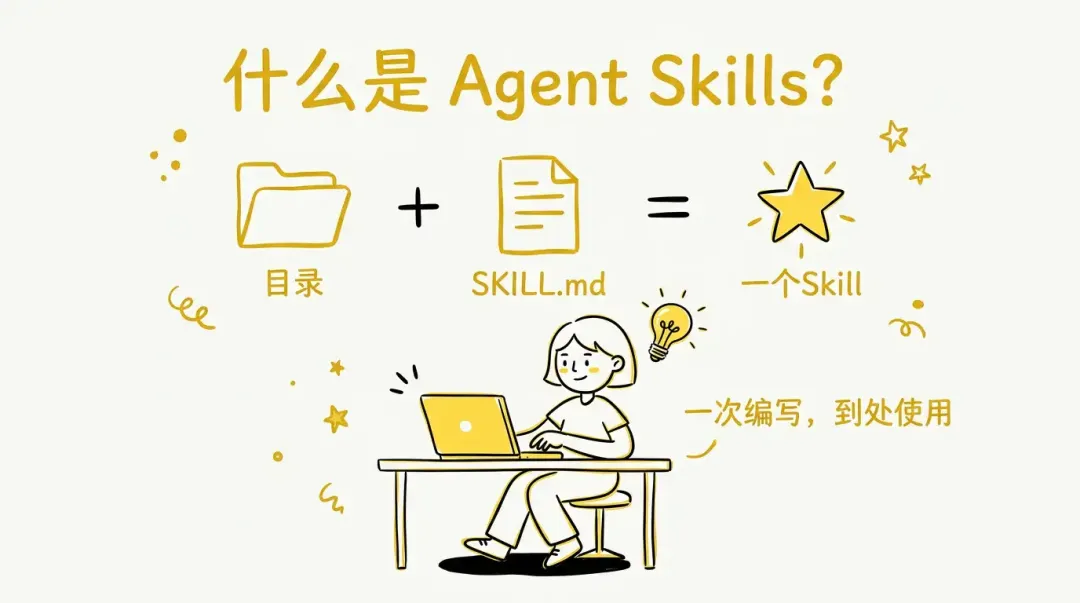
Agent Skills 是一种由 Anthropic 发起并维护的开放格式标准,用于为AI智能体赋予新的能力和专业知识。它的核心思想很朴素: **一个 Skill 就是一个包含 SKILL.md 文件的目录 ** 。这个 Markdown 文件里有元数据(名字 name 和描述 description ),以及告诉 Agent 如何完成特定任务的指令。按需要还可以捆绑脚本 scripts 、模板 assets 和参考资料 references 。
my-skill/
├── SKILL.md # 必需:指令 + 元数据
├── scripts/ # 可选:可执行代码
├── references/ # 可选:文档资料
└── assets/ # 可选:模板、资源
为什么需要 Agent Skills?
在没有 Skills 的情况下,AI 智能体只能依赖其训练数据中的通用知识。这带来了几个问题:
缺乏领域专业性 :智能体不了解你的项目约定、内部 API、特定工作流 知识无法复用 :每次对话都需要重新提供上下文 跨工具不兼容 :在不同 AI 工具间切换时,专业知识无法迁移
Agent Skills 通过”一次编写,到处使用”的理念解决了这些问题。同一个 Skill 可以在 Claude Code、GitHub Copilot、 OpenAI Codex 、 Cursor 等任何兼容的智能体中使用。
Agent Skills有几个显而易见的优势 :
自文档化 :任何人打开 SKILL.md就能看懂这个 Skill 做什么,方便审计和改进可扩展 :从纯文本指令到包含脚本、资源的完整工作流,复杂度可以按需递增 可移植 :Skill 就是文件,天然适合版本控制和团队共享
2. 核心设计哲学:渐进式披露机制详解
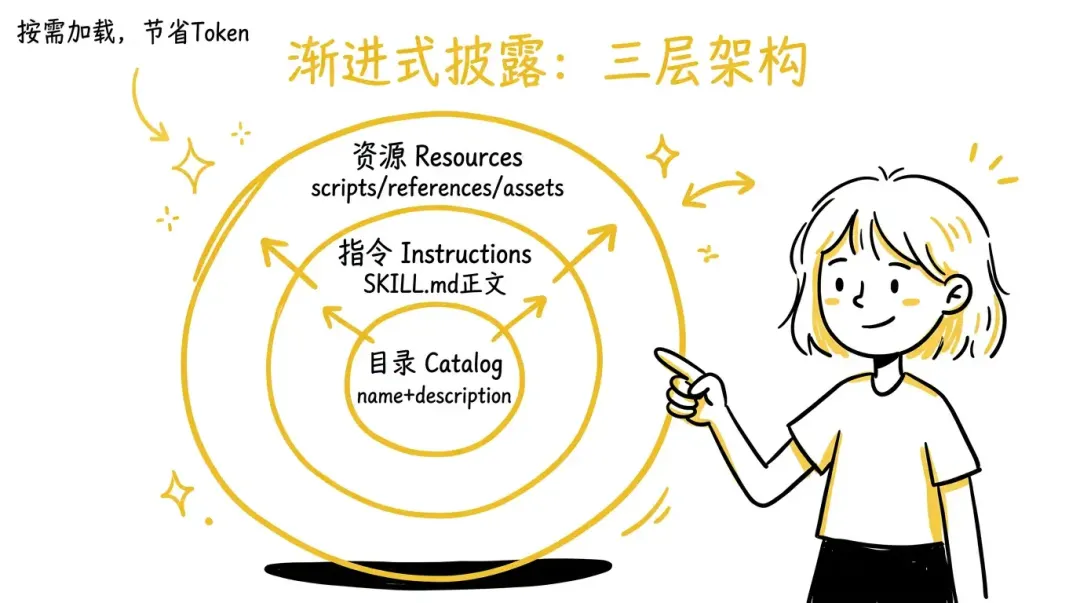
Agent Skills 的设计围绕一个核心原则展开: 渐进式披露(Progressive Disclosure) ,这是一种高效管理上下文的策略。Agent 的上下文窗口是有限的公共资源,不可能在每次会话中把所有 Skill 的全部内容都塞进去。渐进式披露通过分层加载来解决这个问题。
2.1 三层架构
2.2 工作流程
这三层在实际使用中对应三个阶段:
发现阶段(Discovery) :会话启动时,Agent 拿到的只是每个 Skill 的名字和一句描述——这足够让它判断”这个 Skill 可能跟当前任务有关”。就像你看书店的目录,不用翻开每本书就能大致知道哪本可能有用。
激活阶段(Activation) :当用户的任务和某个 Skill 的描述匹配时,Agent 把完整的 SKILL.md 正文读进上下文。这时它才拿到具体的步骤指引、代码示例和注意事项。
执行阶段(Execution) :Agent 按照指令干活。如果指令里提到”遇到 API 错误请参阅 references/api-errors.md “,Agent 才会去读那个文件;如果要执行某个脚本,它才去调用 scripts/ 里的代码。
这种设计的妙处在于,即使你安装了 20 个 Skill,每次会话的启动开销也只是 20 × 100 tokens 左右的目录信息。只有实际用到的 Skill 才会占用完整的上下文空间。
3. SKILL.md 格式详解
3.1 元数据内容
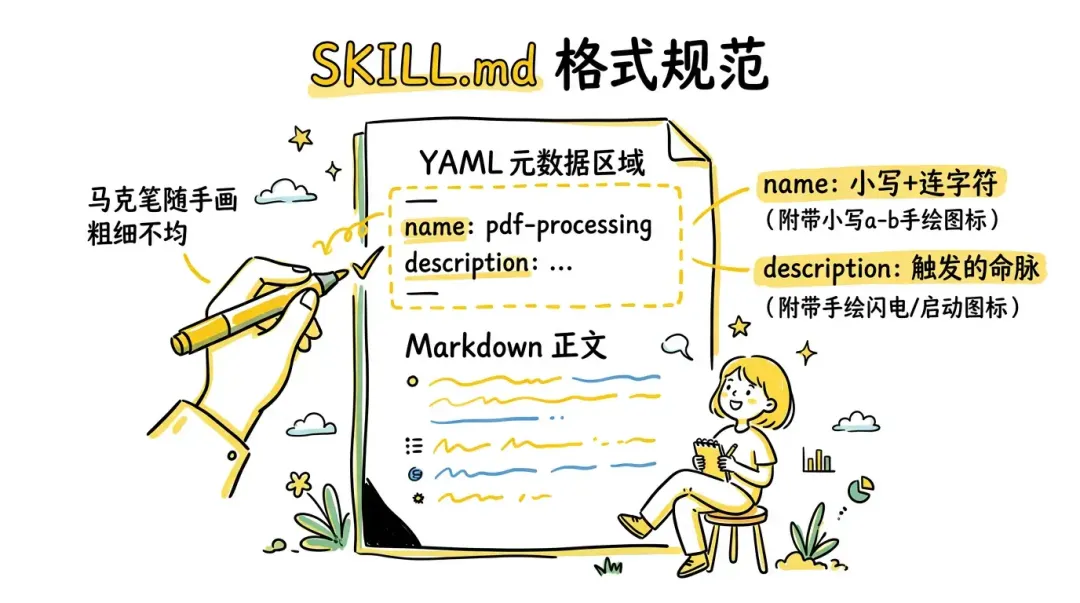
每个 SKILL.md 必须以元数据( YAML frontmatter )开头,用 --- 分隔符包裹。frontmatter 之后是 Markdown 正文。
3.1.1 必需字段
**name 字段 **
Skill 的标识符,规则比较严格:
长度 1–64 字符 只允许小写字母、数字和连字符( a-z、0-9、-)不能以连字符开头或结尾 不能包含连续连字符( --)必须与父目录名称一致
# 合法示例
name: pdf-processing
name: data-analysis
name: code-review
# 非法示例
name: PDF-Processing # 大写不允许
name: -pdf # 不能以连字符开头
name: pdf--processing # 不允许连续连字符
**description 字段 **
描述字段是 Skill 触发的关键机制:
长度 1–1024 字符 应同时描述 Skill 做什么 以及 什么时候该用它 应包含帮助 Agent 识别相关任务的关键词
# 好的描述 —— 说清楚做什么,也说清楚什么时候用
description: >
Extracts text and tables from PDF files, fills PDF forms, and merges
multiple PDFs. Use when working with PDF documents or when the user
mentions PDFs, forms, or document extraction.
# 差的描述 —— 信息量太少,Agent 很难判断何时触发
description: Helps with PDFs.
2. 可选字段
---
name: pdf-processing
description: Extract PDF text, fill forms, merge files. Use when handling PDFs.
license: Apache-2.0
compatibility: Requires Python 3.8+ and [pdfplumber](https://zhida.zhihu.com/search?content_id=775004642&content_type=Answer&match_order=1&q=pdfplumber&zhida_source=entity)
metadata:
author: example-org
version: "1.0"
allowed-tools: Bash(git:*) Read
---
3.2 正文内容
Markdown 正文没有格式限制。规范建议包含:
分步骤的操作指令 输入输出示例 常见边界情况的处理方式
4. 目录结构与可选资源
4.1 Skill的标准目录结构
一个功能完备的 Skill 目录通常长这样:
skill-name/
├── SKILL.md # 必需:元数据 + 指令
├── scripts/ # 可选:可执行代码
├── references/ # 可选:参考文档
├── assets/ # 可选:模板、静态资源
4.2 scripts/ 目录
存放 Agent 可以执行的代码。设计要点:
脚本应当自包含或者清楚地声明依赖 错误信息要对 Agent 友好,说清楚出了什么问题、期望什么、怎么修 优雅处理边界情况
关键优势 :脚本可以被执行而不需要读入上下文窗口。一个 200 行的 Python 脚本在上下文里会占用大量 Token,但如果 Agent 只是执行它、读取输出结果,Token 成本就大大降低。
4.3 references/ 目录
存放 Agent 按需读取的文档资料:
REFERENCE.md— 详细技术参考FORMS.md— 表单模板或结构化数据格式领域特定文件( finance.md、legal.md等)
规范建议每个参考文件保持聚焦。Agent 是按需加载这些文件的,文件越小意味着上下文消耗越少。
以 anthropics/skills 的 PDF Skill 为例,它把复杂内容拆分成了多个参考文件:
pdf/
├── SKILL.md # 主指令(核心工作流)
├── REFERENCE.md # 详细 API 参考
├── FORMS.md # 表单处理指南
└── LICENSE.txt # 许可证
SKILL.md 里会明确告诉 Agent 何时去读哪个文件:
For advanced form filling workflows, read FORMS.md.
For detailed API reference, read REFERENCE.md.
4.4 assets/ 目录
存放不需要读入上下文的静态资源——模板文件、图片、字体等。Agent 在生成输出时会引用这些文件,但不需要”理解”它们的内容。
5. Skill 的生命周期:发现、激活、执行
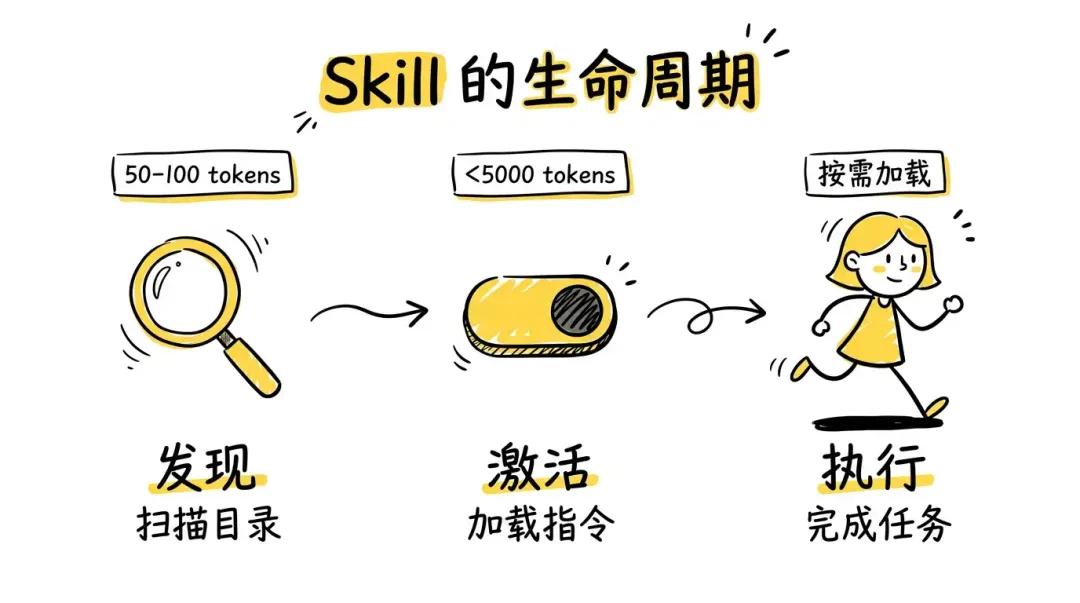
5.1 阶段一:发现(扫描与注册)
在会话启动时,Agent 客户端需要找到所有可用的 Skill。
扫描路径
规范推荐扫描两个层级:
.agents/skills/ 路径已经成为跨客户端共享 Skill 的事实标准。
扫描规则
跳过 .git/、node_modules/等不会包含 Skill 的目录可选择遵守 .gitignore以避免扫描构建产物设置合理边界(最大深度 4–6 层,最多 2000 个目录)
名称冲突处理
当两个 Skill 同名时,通用约定是 项目级覆盖用户级 。同一范围内的冲突,取先发现或后发现的都行,保持一致即可。冲突时应记录警告。
信任考虑
项目级 Skill 来自代码仓库,可能不受信任。规范建议:只有用户将项目标记为”受信任”时才加载项目级 Skill,防止恶意仓库注入指令。
5.2 阶段二:激活(从目录到上下文)
Agent 拿到 Skill 目录后,通过两种方式触发激活:
1.模型驱动激活(Model-driven) :Agent 读完目录,判断某个 Skill 与当前任务相关,主动加载它。有两种实现模式:
* **文件读取激活** :Agent 用文件读取工具直接读 ` SKILL.md ` ,不需要额外基础设施
* **专用工具激活** :注册一个 ` activate_skill ` 工具,Agent 传入 Skill 名字获取 ` SKILL.md ` 的内容
2. 用户显式激活 :用户通过斜杠命令( /skill-name )或 $ 语法( $skill-name )直接激活。
5.3 阶段三:执行(遵循指令执行)
Skill 被激活后,Agent 按照 SKILL.md 的指令工作,按需加载引用的资源文件或执行脚本。
这里有个重要的设计决策: Skill 内容应免于上下文压缩 。如果 Agent 的上下文窗口满了需要截断旧消息,Skill 指令应该被标记为”受保护”不被删除。丢失 Skill 指令会导致 Agent 静默退化——它继续工作但没了专业指导。
5.4 OpenAI 特有的分层发现机制
openai/skills 引入了一个独特的 Skill 分层体系:
skills/
├── .system/ # 系统预装(自动加载)
│ ├── skill-creator/
│ ├── skill-installer/
│ └── openai-docs/
└── .curated/ # 精选 Skill(需安装后使用)
├── pdf/
├── figma/
├── playwright/
└── ... # 35+ 个精选 Skill
.system/ 下的 Skill 随 Codex 自动加载,而 .curated/ 下的需要通过 skill-installer 安装到用户目录。
6. 在 Skill 中使用脚本
当现有工具包已经能满足需求时,直接在 SKILL.md 里引用即可,不需要 scripts/ 目录。
当需要可复用的复杂的代码逻辑时,可以把代码脚本放在 scripts/ 目录,让脚本自己声明依赖。
6.1 为 Agent 设计代码脚本接口
Agent 通过读取 stdout/stderr 来决定下一步行动。几个关键设计原则:
禁止交互式提示 。Agent 运行在非交互式 Shell 里,不能响应确认对话框:
# 错误:会永远卡住
$ python scripts/deploy.py
Target environment: _
# 正确:清晰的错误信息和用法提示
$ python scripts/deploy.py
Error: --env is required. Options: development, staging, production.
Usage: python scripts/deploy.py --env staging --tag v1.2.3
写有帮助的错误信息 。”Error: invalid input” 让 Agent 无从下手。”Error: –format must be one of: json, csv, table. Received: xml” 则能引导它自行修正。
使用结构化输出 。JSON、CSV 比自由格式文本更容易被 Agent 可靠地解析。
7. 编写高质量 Skill 的最佳实践
7.1 从真实专业知识出发
一个常见的陷阱是让 LLM 凭空生成 Skill,结果是一堆”处理好错误”“遵循认证最佳实践”之类的空话。真正有价值的 Skill 来自真实经验。
两种有效的知识来源:
从实际任务中提取 :在与 Agent 协作完成任务后,把可复用的模式抽取成 Skill。关注哪些步骤有效、你做了哪些修正、数据的输入输出格式、你提供了哪些 Agent 自己不知道的上下文。
从现有工件综合 :内部文档、API 规范、代码审查评论、故障报告——这些都是好的素材。用团队真实的事故报告和运维手册综合出来的数据来编写 Skill,远比从通用”数据工程最佳实践”文章生成的有用。
7.2 上下文使用原则
添加 Agent 不知道的,省略 Agent 已知的。 你不需要解释 PDF 是什么、HTTP 怎么工作。只提供项目特有的约定、领域特有的流程、非显而易见的边缘情况。
<!-- 太啰嗦 —— Agent 知道 PDF 是什么 -->
## 提取 PDF 文本
PDF(便携式文档格式)文件是一种常见的文件格式...
<!-- 更好 —— 直接切入 Agent 不知道的 -->
## 提取 PDF 文本
使用 pdfplumber 提取文本。扫描文档回退到 pdf2image + pytesseract。
设计连贯的功能单元。 Skill的功能范围设计类似于函数设计。Skill的功能范围太窄会导致一个任务加载多个 Skill,可能产生冲突指令;Skill的功能范围太广则难以精确触发。查询数据库并格式化结果可以作为一个Skill功能单元,同时包含数据库管理就太宽了。
SKILL.md 控制在 500 行以内。 详细参考材料移到独立文件 references ,并明确告诉 Agent 什么时候去读它们。
7.3 合适的自由度
不同的任务需要不同程度的指令精确度和自由度。
给 Agent 自由度的情况 (当多种方法都可行时):
## 代码审查流程
1. 检查所有数据库查询的 SQL 注入(使用参数化查询)
2. 验证每个端点的身份验证检查
3. 查找并发代码路径中的竞态条件
要求Agent严格按照规定执行的情况 (当操作脆弱或需要特定顺序时):
## 数据库迁移
严格运行此序列:
python scripts/migrate.py --verify --backup
不要修改命令或添加额外标志。
anthropics/skills 的 skill-creator 对此有一段精彩的阐述:”尽量解释 为什么 。今天的 LLM 很聪明,有良好的推理能力。如果你发现自己在写大写的 ALWAYS 或 NEVER,这是一个不好的信号——试试换个方式解释原因,让模型理解为什么这件事重要。”
7.4 有效指令模式
边界情况处理方法: 很多 Skill 里价值最高的内容是一份环境特有的边界情况处理方法:
## Gotchas
- `users` 表用软删除。查询必须包含 `WHERE deleted_at IS NULL`
- 用户 ID 在数据库里是 `user_id`,认证服务里是 `uid`,计费 API 里是 `accountId`
- `/health` 端点只要 Web 服务器运行就返回 200,即使数据库连接断了。用 `/ready` 检查完整服务状态
输出格式模板: 要求LLM按照格式输出的情况下,给输出格式模板比描述格式更可靠:
## 报告结构
使用此模板:
# [分析标题]
## 执行摘要
[关键发现的一段概述]
## 主要发现
- 发现 1 及支持数据
## 建议
1. 具体可操作的建议
验证循环: 让 Agent 在继续之前验证自己的工作:
## 编辑工作流程
1. 进行编辑
2. 运行验证:`python scripts/validate.py output/`
3. 如果验证失败:查看错误消息、修复问题、再次验证
4. 仅在验证通过后继续
Plan-Validate-Execute模式 —— 对批量或破坏性操作特别有用:先生成计划,用验证脚本对照源头检查,通过后才执行。
8. 优化 Skill 的触发描述
8.1 Skill触发机制的工作原理
Skill 只有被激活才有价值,而 description 字段承担了全部触发责任。Agent 在启动时只看到名字和描述,据此判断是否加载完整指令。
一个值得注意的细节:Agent 通常只在遇到超出自身能力的任务时才会求助 Skill。简单的一步请求(比如”读这个 PDF”)即使描述完美匹配也可能不触发,因为 Agent 用基础工具就能搞定。涉及专业知识、复杂工作流的任务才是 Skill 真正发挥作用的地方。
8.2 编写有效描述 description 的原则
用祈使语气 :用”当 …时使用这个skill” 而不是 “这个skill能做…” 聚焦用户意图 :描述用户想达成的目标,用户想要实现什么,而不是 Skill 的内部机制 倾向于主动触发 :明确列出skill的适用场景,包括用户没有直接提及领域名称的情况 保持简洁 :几句话到一个小段落,不超过1024个字符
对比优化前后的描述:
# 太保守 —— 容易被忽略
description: How to build a simple dashboard to display internal data.
# 更主动 —— 明确列出触发场景
description: >
How to build a simple fast dashboard to display internal data.
Make sure to use this skill whenever the user mentions dashboards,
data visualization, internal metrics, or wants to display any kind
of company data, even if they don't explicitly ask for a 'dashboard.'
8.3 根据触发情况评估描述的好坏
系统化测试skill描述的好坏,需要一组标注好的评估查询:标记了”应该触发”和”不应该触发”的真实用户提示。
[
{"query": "我老板刚发了个 xlsx 文件,叫 Q4 sales final v2.xlsx,要我加一列利润率...", "should_trigger": true},
{"query": "帮我写个 Python 脚本读取 CSV 然后上传到 PostgreSQL", "should_trigger": false}
]
建议 20 个查询,正负各半。
应该触发此skill的查询 要变化:有正式的有口语的有打错字的;有直接提到技能领域的也有需要推理才能关联的。
不应该触发此skill的查询 重点是”差一点就该触发”的近义场景,而不是明显无关的(”写个斐波那契函数”作为 PDF Skill 的负面用例毫无测试价值)。
8.4 优化循环
规范文档详细描述了一套系统化的优化流程:
分割数据集 :60% 训练集、40% 验证集,避免过拟合 评估当前描述 :对两个数据集运行测试,每个查询跑 3 次计算触发率 识别训练集中的失败 :哪些应触发的没触发?哪些不该触发的触发了? 修改描述 :关注泛化:不要添加失败查询里的特定关键词(那是过拟合),而是找到这些查询代表的通用类别 重复 直到训练集全部通过或不再有显著改善 以验证集得分选择最佳描述 :注意最好的可能不是最后一个
anthropics/skills 提供了自动化工具来执行这个循环:
python -m scripts.run_loop \
--eval-set <path-to-trigger-eval.json> \
--skill-path <path-to-skill> \
--model <model-id> \
--max-iterations 5
9. 评估 Skill 的输出质量
9.1 anthropics/skills 的评估体系
anthropics/skills 拥有非常完整的评估工具链,其核心流程是一个”运行→审查→改进”的闭环。
测试执行 :对每个测试用例同时启动两个子 Agent:一个带 Skill 一个不带(或带旧版本),形成对照。
量化评估 :每个测试用例都有可客观验证的断言(assertion),由专门的打分Agent评分。结果汇聚成 benchmark.json,包含通过率、耗时和 Token 用量的均值±标准差。
可视化审查 :生成交互式 HTML 查看器,包含两个标签页:
“Outputs” 展示每个测试用例的输出,支持内联渲染和逐条反馈 “Benchmark” 展示量化对比数据
盲审比较(Blind Comparison) :更严格的场景下,把两个版本的输出交给独立 Agent 评判,不告诉它哪个是新版,这样来排除偏见。
9.2 openai/skills 的验证工具
openai/skills 的方法更轻量,聚焦于格式验证而非输出质量:
scripts/quick_validate.py <path/to/skill-folder>
其核心验证逻辑检查:YAML frontmatter 格式、必需字段完整性、命名规则、字段长度限制。
此外, openai/skills 特有的 UI 元数据可通过 generate_openai_yaml.py 生成:
scripts/generate_openai_yaml.py <path/to/skill-folder> \
--interface display_name="Skill Name" \
--interface short_description="Short desc" \
--interface default_prompt="Use $skill-name to..."
9.3 评估工具对比
10. 智能体如何添加 Skills
agentskills 规范提供了一份详尽的客户端集成指南,覆盖了 Skill 的完整生命周期。
10.1 构建 Skill 目录
为每个发现的 Skill 在内存中维护记录:
用 name 做键存在 Map 里,方便激活时快速查找。
10.2 向模型披露可用 Skill
将 Skill 目录以结构化格式(XML、JSON 或列表)注入系统提示或工具描述:
<available_skills>
<skill>
<name>pdf-processing</name>
<description>Extract PDF text, fill forms, merge files. Use when handling PDFs.</description>
<location>/home/user/.agents/skills/pdf-processing/SKILL.md</location>
</skill>
</available_skills>
agentskills 参考库的 to_prompt 函数就是干这个的:
def to_prompt(skill_dirs: list[Path]) -> str:
lines = ["<available_skills>"]
for skill_dir in skill_dirs:
skill_dir = Path(skill_dir).resolve()
props = read_properties(skill_dir)
lines.append("<skill>")
lines.append(f"<name>{html.escape(props.name)}</name>")
lines.append(f"<description>{html.escape(props.description)}</description>")
skill_md_path = find_skill_md(skill_dir)
lines.append(f"<location>{str(skill_md_path)}</location>")
lines.append("</skill>")
lines.append("</available_skills>")
return"\n".join(lines)
10.3 处理格式异常的 YAML
实际中不同客户端编写的 Skill 可能有轻微的 YAML 格式问题。规范建议宽容加载:
名字与目录不匹配 → 警告,仍然加载 名字超过 64 字符 → 警告,仍然加载 描述缺失或为空 → 跳过该 Skill(描述是触发的核心) YAML 完全无法解析 → 跳过,记录错误
10.5 上下文管理
两个关键:
保护 Skill 内容免于压缩 :上下文满了需要截断时,Skill 指令应被标记为受保护 去重激活 :跟踪已激活的 Skill,避免重复注入相同指令
11. 对比anthropics和openai的skills设计
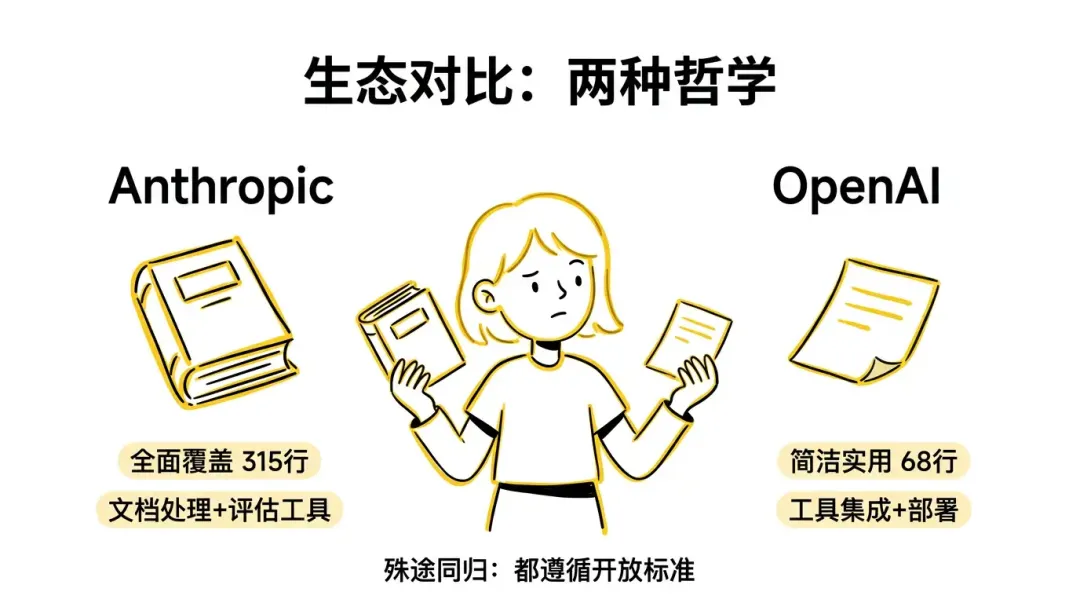
11.1 设计差异
anthropics/skills (Claude 生态)
强项在文档处理和创意设计:
文档处理 :PDF(文本提取、表单填写、合并分割)、DOCX、PPTX、XLSX 开发工具 :MCP 服务器构建(mcp-builder)、Web 应用测试(webapp-testing)、Skill 创建(skill-creator) 创意应用 :算法艺术、画布设计、主题工厂 企业场景 :品牌指南、内部沟通、文档协作
openai/skills (Codex 生态)
强项在工具集成和部署能力,拥有 38+ 个 Skill:
工具集成 :Figma(设计到代码)、Notion(知识管理)、Linear(项目管理)、Sentry(错误监控) 部署平台 :Vercel、Netlify、Cloudflare、Render 安全工具 :安全最佳实践、威胁建模、安全所有权映射 开发框架 : http:// ASP.NET Core、WinUI、Web 游戏开发
11.2 实际 Skill 对比:PDF 处理
同一个功能在两个生态中的实现差异很能说明问题。
anthropics/skills 的 pdf Skill :
约 315 行,非常详细 覆盖 Python 库(pypdf、pdfplumber、reportlab)和命令行工具(pdftotext、qpdf、pdftk) 描述极其详尽——列出了读取、合并、分割、旋转、水印、表单填写、加密解密、OCR 等每一种场景 专有许可
description: >
Use this skill whenever the user wants to do anything with PDF files.
This includes reading or extracting text/tables from PDFs, combining
or merging multiple PDFs into one, splitting PDFs apart, rotating pages,
adding watermarks, creating new PDFs, filling PDF forms,
encrypting/decrypting PDFs, extracting images, and OCR on scanned PDFs
to make them searchable.
openai/skills 的 pdf Skill :
约 68 行,简洁实用 强调视觉验证(先渲染成 PNG 再检查) 明确的目录约定( tmp/pdfs/做中间文件、output/pdf/做最终产物)包含质量标准
description: >
Use when tasks involve reading, creating, or reviewing PDF files
where rendering and layout matter; prefer visual checks by rendering
pages (Poppler) and use Python tools such as reportlab, pdfplumber,
and pypdf for generation and extraction.
这个对比清楚地展示了两种哲学:Anthropic 倾向于全面覆盖所有场景,OpenAI 倾向于简洁但加上独特的质量保障机制。
11.3 跨平台互操作性
二者都遵循 Agent Skills 开放标准,意味着:
一个为 Claude 编写的 Skill 可以在 Codex 中使用(可能需要微调) .agents/skills/路径是跨客户端共享的事实标准frontmatter 的核心字段(name、description)完全兼容
但也有几个需要注意的兼容性问题:
compatibility字段在 OpenAI 验证器中被视为未知字段OpenAI 的 agents/openai.yaml在其他平台中会被忽略Anthropic 的评估工具链依赖 claudeCLI,无法在其他平台运行
12. 总结
从三个代码库的演进方向来看,几个趋势比较清晰:
标准化持续深化 : agentskills规范会继续完善,特别是allowed-tools等实验性字段的定型评估工具的普及 :Anthropic 的评估体系(盲审比较、trigger 优化)很可能被其他方案借鉴 Skill Marketplace 生态 :类似 npm 或 pip 的 Skill 分发机制会逐步成熟 跨平台互操作性增强 : .agents/skills/约定的广泛采用会让同一套 Skill 在更多 Agent 产品间无缝流转垂直领域深化 :从通用能力扩展到更多行业特定的专业 Skill

作者:回旋托马斯x
原文:https://www.zhihu.com/question/1998417930208188232/answer/2021013782487466858
参考资料
Agent Skills 官方文档 Agent Skills 规范 anthropics_skills GitHub openai_skills GitHub skills-ref 参考库
