 夜雨聆风
夜雨聆风 我们致力于探索、分享和推荐最新的实用技术栈、开源项目、框架和实用工具。每天都有新鲜的开源资讯等待你的发现!
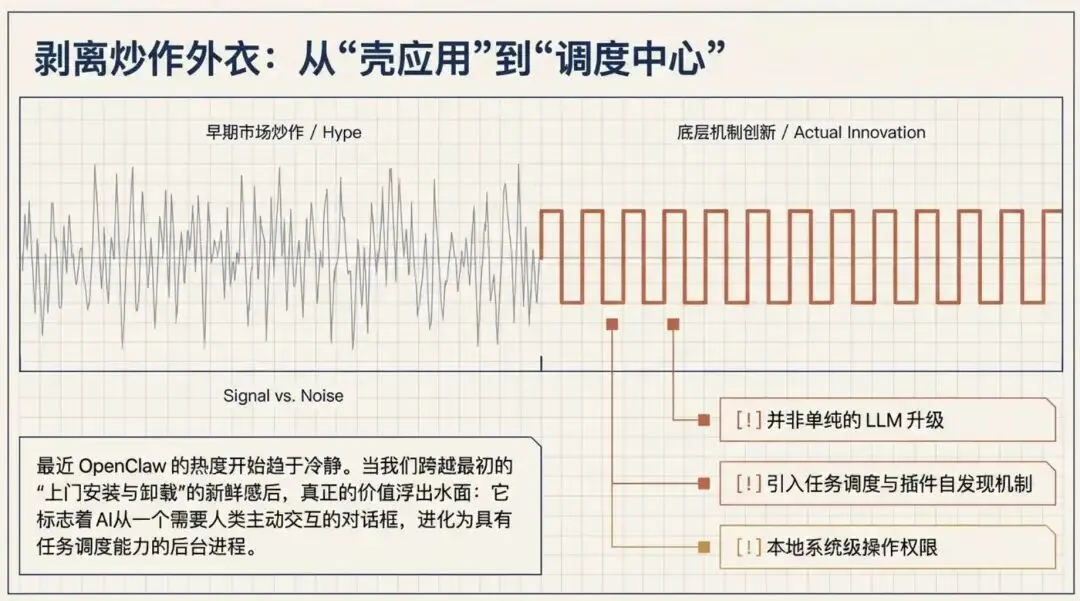
我们致力于探索、分享和推荐最新的实用技术栈、开源项目、框架和实用工具。每天都有新鲜的开源资讯等待你的发现!大家好,最近是不是 OpenClaw 消停了一下?!冲击性的文章少了很多,从原来的上门安装和卸载服务,到现在开始有人在吐槽 OpenClaw 也就那样了!
1. AI 如何与实际场景结合
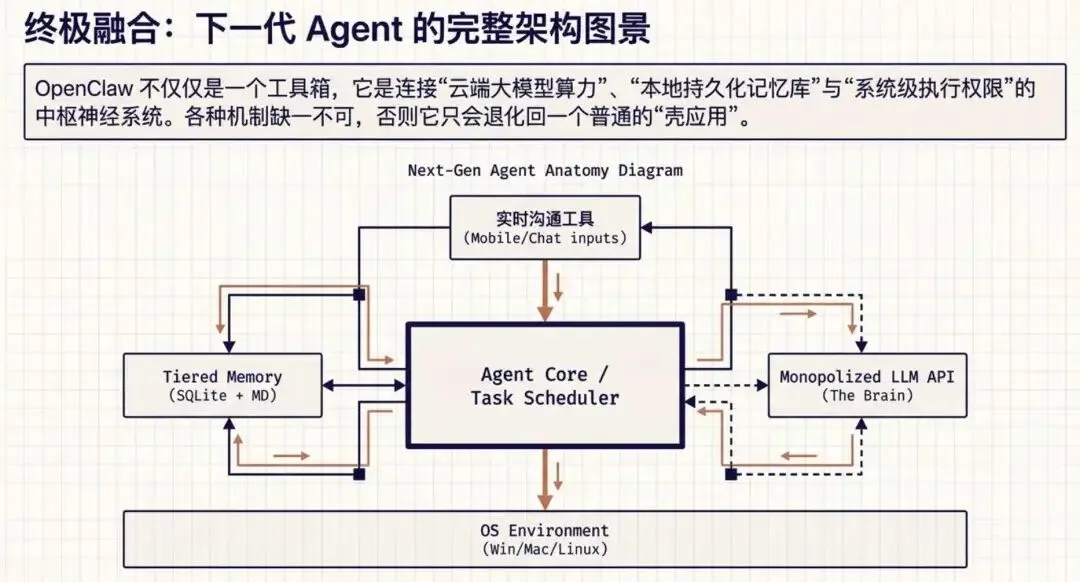
其实,从对 OpenClaw 的深入研究及使用过程来看,OpenClaw 确实相比之前的大模型AI工具是有了创新,从原来要依靠人的主动交互,必须你当面与之沟通,到创新引入任务调度机制、插件机制、Skills 集成机机制、本地文件记录机制等。
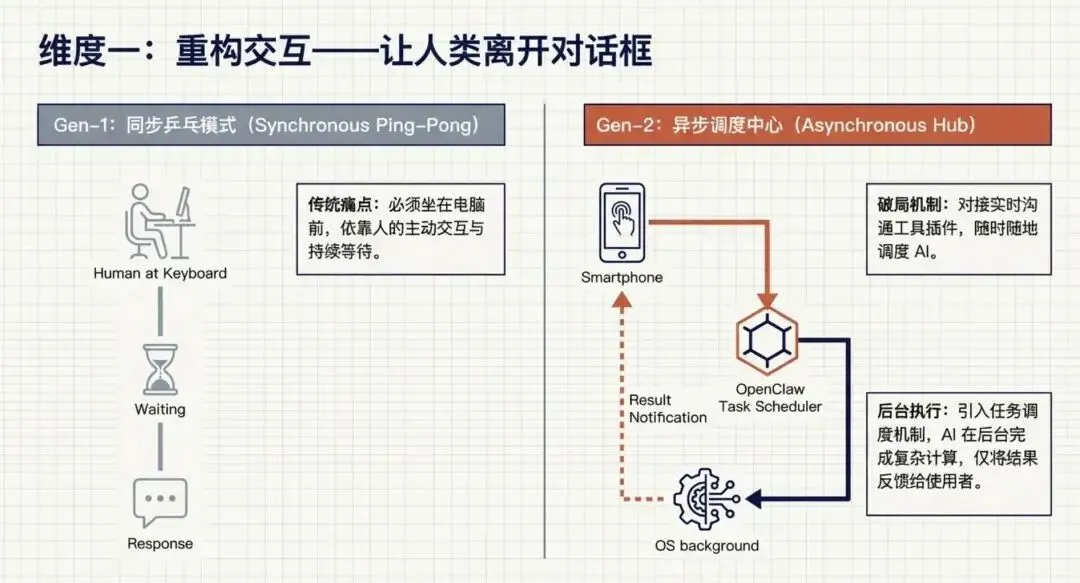
而这里最重要的它改变了交互机制,它考虑到了当代互联网场景下,人与人之间不是时时坐在电脑前,来与AI进行输入与输出的等待,融入了对接实时沟通工具的插件机制,让人能随时随地去调度AI,并通过任务机制将结果反馈给到使用者,这是一个很好的创新点,因为很多的工作是需要电脑端的计算来完成,而不是单纯只要个手机应用。
当然,OpenClaw为了实现这一目的,也研发了其他的配套功能,像前面我说的各种机制,如果没有这些机制,那它也只是壳的Agent。
2. AI 要有哪些能力
AI 工具或应用,相信大家都使用过很多,如Claude Code、OpenCode, Codex、Trae等等,它们都具有各种集成能力,如集成MCP、集成插件、集成SKills等,这些集成能力才是让 AI 工具 更出色的基础,也是相较于早期网页对话式AI的改进。当然,OpenClaw 除了具备这些能力外,它还具有自发现自安装能力,相比于过去的AI工具,你要自己下载插件或Skills,然后手动配置。
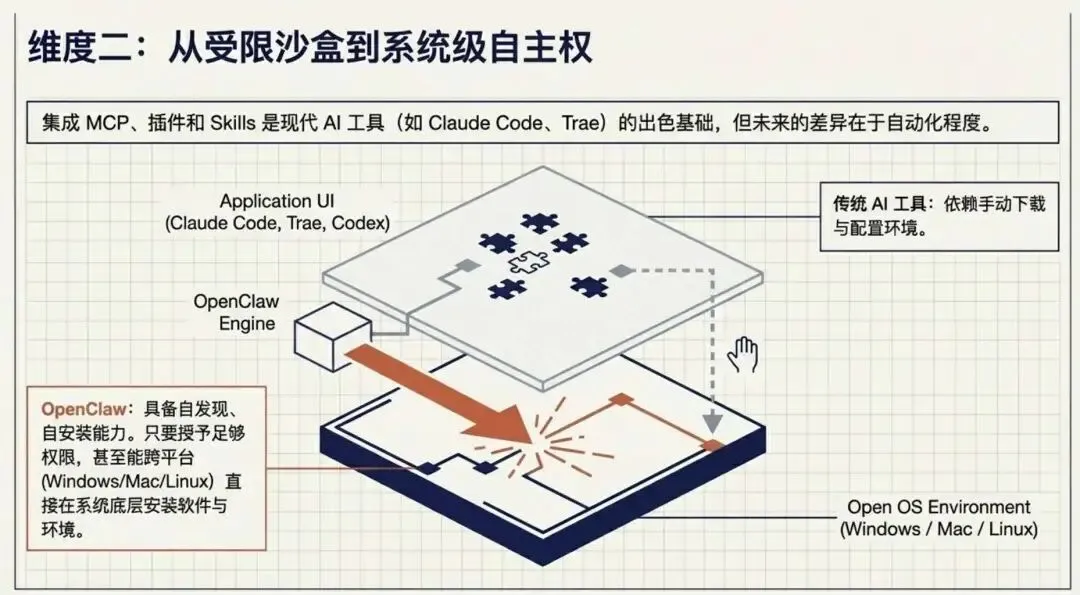
而 OpenClaw 只要你跟它说,它就能自行安装,而且只要你给的权限够大,它还可以帮你在系统上(windows/mac/linux)上安装软件,这些能力是其他工具所不具备的。
3. AI的上下文要如何发展
A I的上下文,可以理解为其记忆,如果在与AI对话中,AI 不记录这些上下文,它就不能关联到之前的对话,而只是输入当前的沟通,那就乱套。 用过AI工具的童鞋应该者知道,很多AI工具的记忆是临时,而且是有限制的,这是因为这些AI工具的上下文都是存储在服务端(即企业端),比如使用Claude Code,OpenCode,Trae等,对话记录及操作记录都是被上传到服务端。而 OpenClaw 却采用了另一个方式,采用本地文件+sqlite来保存这些记录(持久化记忆能力),并且它采用了分层存储记忆,分出长久记忆(Memory.MD)、会话记忆(Session)和临时记忆。
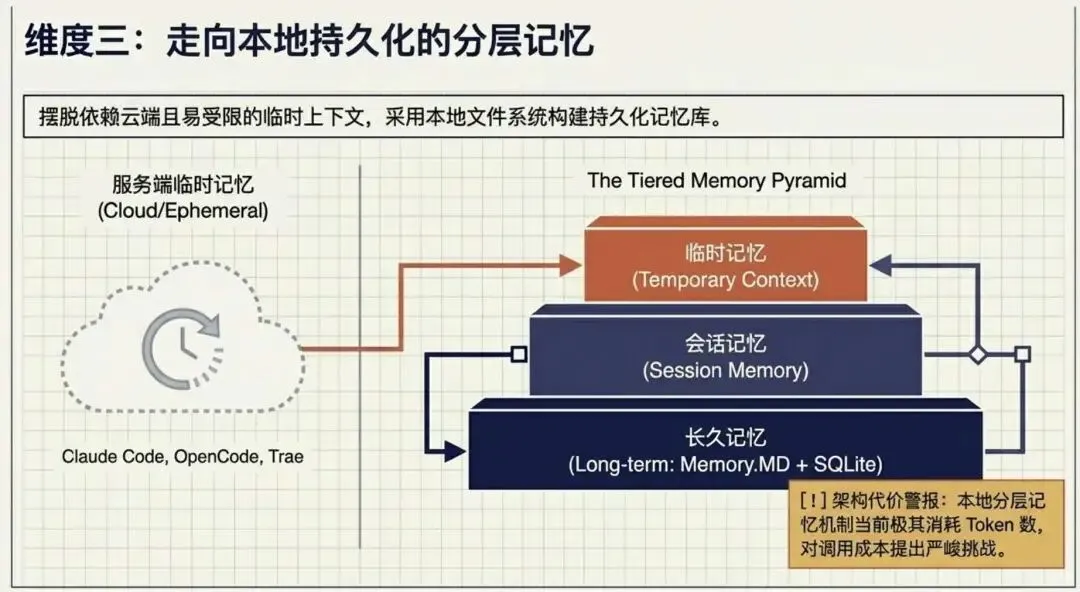
也是就说随着AI工具的发展,它要进化这种记忆机制,从无记忆、临时记忆、有限度的记忆、再到分层记忆,相信后面AI的上下文(记忆)还有会有更好的提升。但是,当前还是很耗 Token ,需要注意你的钱包。
4. AI “大脑” 要何去何从
无论是 OpenClaw,还是之前的各种AI 工具,都是需要接入“大脑”,但现在的“大脑”都是被各个大公司垄断的,也就是说你通过AI干的任何事情,都是被“大脑”所在的公司记录着,你是否感到可怕呢?其实,在现在的互联网中,只要你使用任何系统,或只是接入了运营商的网络,你的行为都是被记录的,所以不用害怕~~,但这事对于企业来说就很可怕,如果企业的所有业务和数据都接入到“大脑”,那信息相当于是透明的。当然,你可能会说本地搭建“大脑”不就行了,但有哪些企业很做到呢?
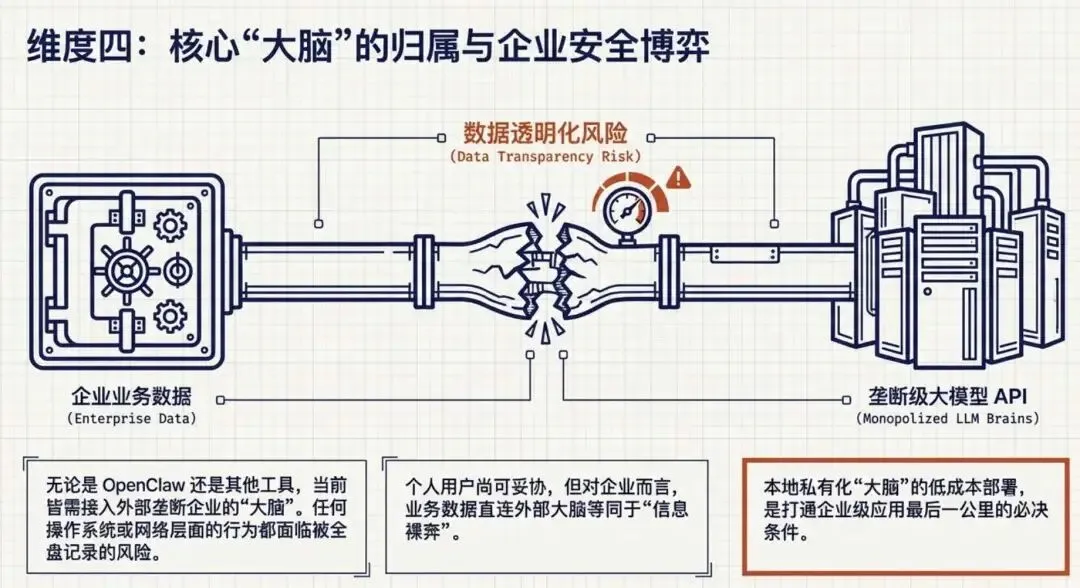
AI“大脑”的发展,未来应该会有更好改进,能让企业能安心使用而不担心数据泄漏的问题。
5. AI 时代数据如何存储
从人类的发展历程和文字的发展历程来看,无不体现对“数据”的掌控,从早期的“结绳”记事,到文字记录,到账本记录、到计算机的Excel、数据库、系统、移动应用等,人都是希望看到结构化的数据,并且数据是可以持久化的,历史是可查的,但当前AI产生的很多数据都非非结构化的,较难识别其中关键的数据。
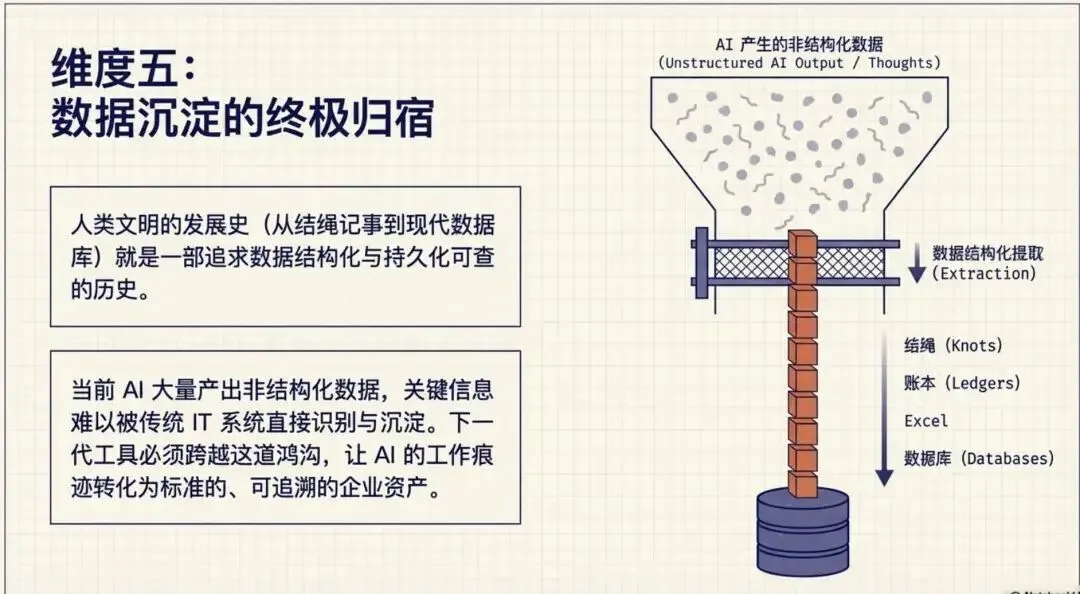
以上是根据AI的研究和使用过程的一些思考,权当碎碎记忆~~或者你有其他看法,也可评论区聊聊。
6. 总结
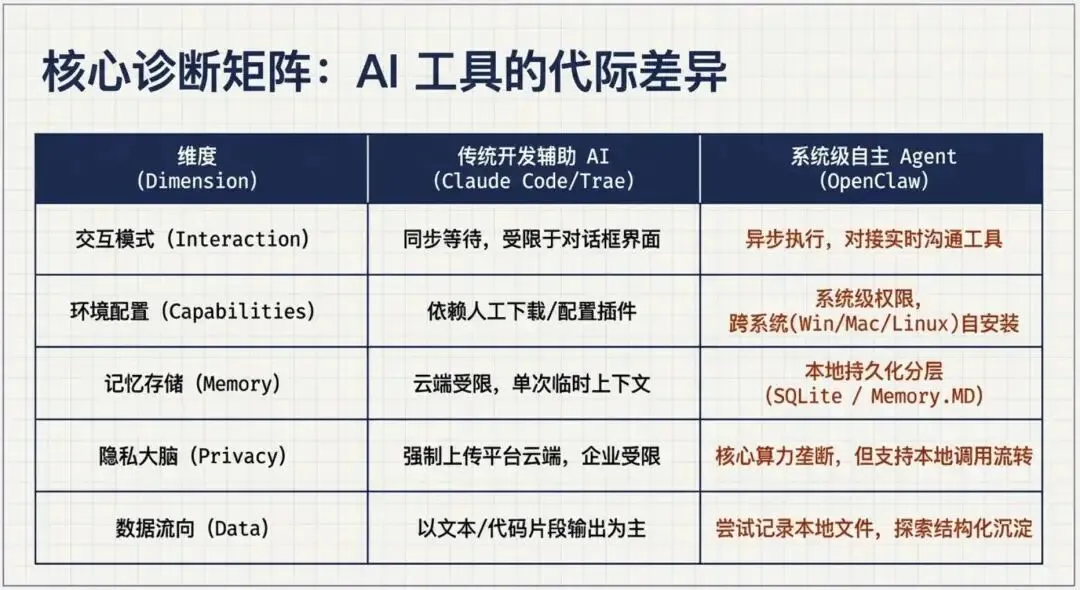
从使用AI工具如OpenClaw及其他工具,可以看到AI技术能力的进化,也可看到AI在一步步靠近工作与生活。
---全文完---

