 夜雨聆风
夜雨聆风

1. NUS邵林团队发布Goal-VLA:生成式大模型化身世界模型,实现零样本机器人操作
牛喀网获悉,新加坡国立大学邵林团队提出了一种名为Goal-VLA的全新解耦式分层框架,该研究已被机器人领域顶级会议ICRA2026接收。当前VLA模型主要分为端到端与分层两大范式,前者严重依赖海量“指令-视觉-动作”成对数据,零样本泛化能力受限;后者引入VLM作为高层规划器,但生成的中间表示往往缺乏复杂操作所需的精确几何细节。Goal-VLA创新性地将图像生成式VLM作为“以物体为中心的世界模型”,使用物体目标状态表示连接高层语义推理与底层动作控制。
该框架的执行流程分为三个阶段:目标状态推理模块利用图像生成VLM将自然语言指令转化为具体视觉目标,并通过“合成-反思”迭代机制进行视觉审查与修正;空间基准模块将2D视觉目标转化为精确的3D空间变换;底层策略则基于无碰撞的最优接触位姿生成执行轨迹。实验结果显示,在RLBench仿真环境的8个任务中,Goal-VLA实现了59.9%的平均成功率,远超MOKA的26.0%。在真实机械臂的番茄入锅、桌面清扫等任务中,Goal-VLA达到60%的平均成功率,证明了其跨物体、跨环境、跨任务和跨本体的零样本执行能力。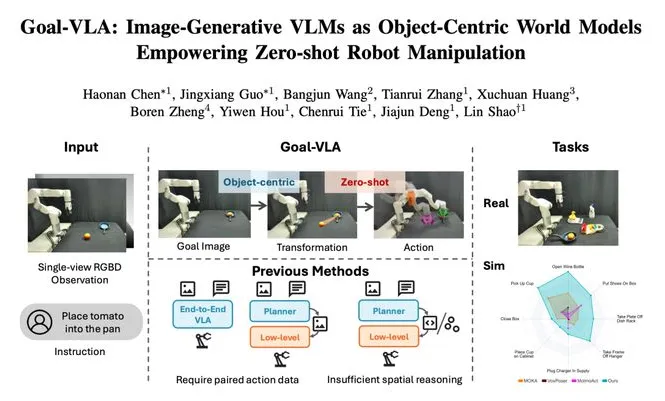
2. 迪士尼明星机器人雪宝当众死机,工作人员抱离现场
牛喀网获悉,迪士尼乐园发生了一起备受瞩目的机器人故障事件。此前凭借灵动互动表现爆火的《冰雪奇缘》雪宝机器人,在园区进行公开互动展示时突然出现死机状况。现场视频显示,原本正在与观众互动的雪宝机器人瞬间停止动作,眼睛不再转动,也无法对观众的呼唤做出回应,完全陷入静止状态。现场观众见状纷纷拿出手机拍摄,原本热闹的展示现场陷入短暂混乱。
据悉,该雪宝机器人是迪士尼联合英伟达、GoogleDeepMind共同研发的新一代角色机器人,其开发借助了名为Newton的开源仿真框架,经过大量模拟训练才实现流畅的互动效果。机器人的皮肤覆盖了虹彩纤维,能呈现出晶莹的雪质感。故障发生后,现场工作人员迅速上前查看情况,在尝试重启机器人无果后,为不影响现场秩序,直接将死机的雪宝机器人抱离展示区域。截至发稿,迪士尼方面尚未就此事发布官方声明,未说明故障具体原因及后续修复计划。

3. OpenClaw“赛博养虾”热潮背后:开源框架正在拉平具身智能技术门槛
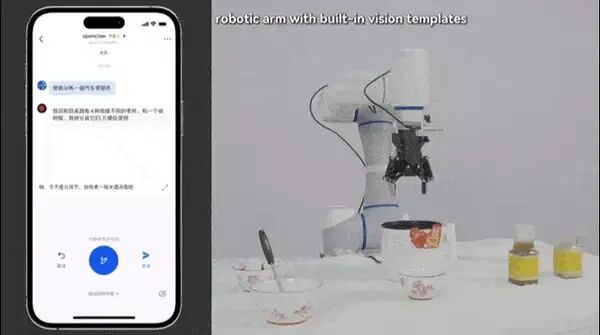
牛喀网获悉,近期社交媒体上掀起了一股“赛博养虾”热潮,大量开发者使用OpenClaw开源框架让普通机械臂“听懂人话”执行复杂任务。OpenClaw的核心价值在于利用现有多模态大模型的强大理解能力,将人类模糊的自然语言指令翻译成底层机器人可以执行的模块化技能。例如,当用户对机械臂说“今天是元宵节,给我煮点甜酒汤圆”时,系统能自动完成“寻找汤圆→取水→加热→下锅”的任务拆解与执行。
这一框架的行业影响被认为是颠覆性的。过去需要数月专项开发的视觉识别和任务编排能力,现在直接被通用大模型解决。一个有基础编程能力的工程师,周末就能搭建出一个能“听懂话”的机器人原型。然而,业内专家指出,OpenClaw并没有解决机器人底层控制的根本问题——当机器人伸手去抓一个软塌塌的纸杯时,力度多大才不会捏瘪?这些涉及物理规律和接触力学的“脏活累活”,仍是通用大模型无法解决的难题。
4. RoboClaw框架实现数据自循环,人工成本降低53.7%加速具身智能迭代
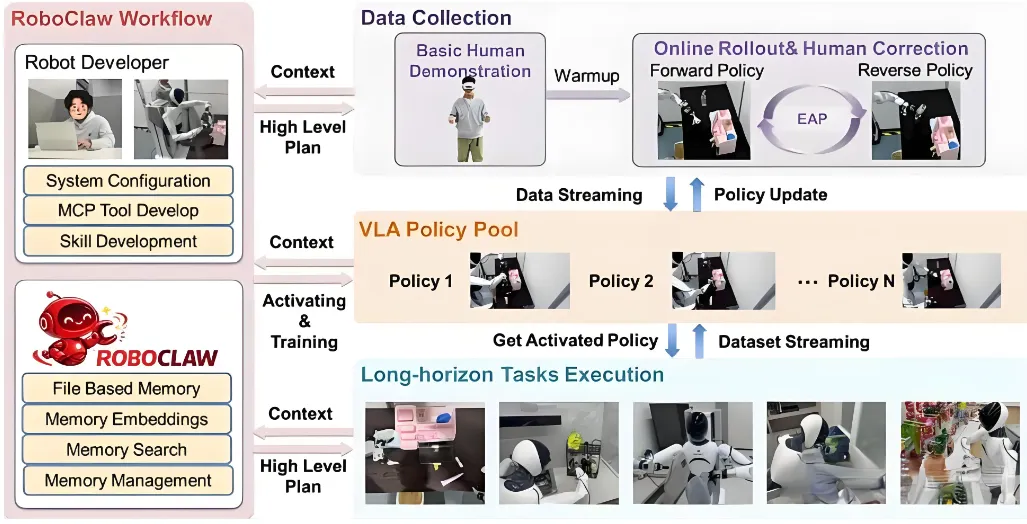
牛喀网获悉,继OpenClaw掀起“赛博养虾”热潮后,学术界推出了更为深入的RoboClaw框架。这项来自Agibot研究团队的工作,基于AgibotG01双臂移动机器人平台,构建了一个贯穿机器人全生命周期的统一框架。在该框架中,数据收集、策略学习和任务执行都在同一个VLM驱动的控制循环下进行,机器人具备了感知、记忆、规划、执行、反思、自我进化的完整智能体能力。
RoboClaw的核心创新在于“纠缠动作对”机制,即给机器人的每一个正向操作配对一个反向恢复动作,使机器人可以不断地“拿起—放下—拿起—放下”,形成自我重置的数据采集闭环。实验结果显示,在口红插入、乳液放置等精细化操作任务中,采用RoboClaw框架后收集同等数量数据所需的人工时间成本降低了53.7%,人工干预频率下降至原来的1/8.04。在长程任务成功率上,该框架比基线方法提升了25%。
5. 1X公司发布世界模型1XWM,机器人可从人类视频中自主学习新技能
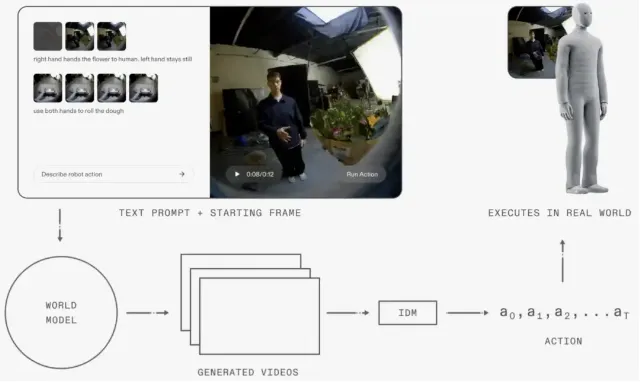
牛喀网获悉,人形机器人公司1X于正式发布了新一代世界模型1XWM,该模型能够理解现实世界的动态,帮助机器人自主学习新技能。1X公司在技术博客中表示,通过利用互联网规模视频中固有的世界动态特性,1XWM无需在大规模机器人数据或任何相关的遥操作演示上进行预训练,即可泛化到新的物体、运动和任务。这意味着机器人可以通过“观看”人类视频来学习操作技能。
该模型的骨干网络基于一个140亿参数的生成式视频模型构建。研究人员采用多阶段训练策略:首先使用900小时的以自我为中心的人类视频进行训练,使模型适应第一人称视角的操作任务;随后利用70小时的机器人数据进行微调,使模型适应NEO人形机器人的视觉外观和运动学特征。实验结果显示,1XWM在分布内和分布外任务上均能保持稳定的成功率。不过该模型目前存在推理延迟问题,骨干网络单次运行时间为11秒,生成的5秒视频中IDM提取动作需要1秒。
6. 道通科技连发两项具身智能成果:AutelClaw平台与0.5B轻量化SimVLA模型
牛喀网获悉,道通科技近日接连发布两项具身智能相关技术成果——机器人平台AutelClaw与轻量化模型SimVLA。AutelClaw聚焦工业场景中“感知与决策脱节”“安全门槛高”“多机型适配难”等现实问题,构建了一套“感知—理解—决策—执行—优化”的自动化闭环。该平台设计了“仅观测、人工审批、完全自主”三档可切换的自主度控制,并叠加沙箱隔离、紧急停机、指令检测等多层防护机制。
由道通科技旗下FrontierRobotics团队推出的SimVLA,则是一款面向通用机器人操作的视觉-语言-动作基准模型。该模型以0.5B参数量,在多项基准测试中与数亿至数十亿参数规模的主流模型表现持平或更优。SimVLA采用VLM骨干编码器加轻量级动作头的二元架构,训练显存压缩至9.3GB,可在普通消费级显卡上完成训练与微调。在实际机器人场景中,该模型已实现零样本部署,在收纳、插花、擦桌子等多阶段操作任务中成功率与更大规模模型相当,部分任务接近100%。

7. ABot-PhysWorld:140亿参数具身世界模型,物理真实性超越Sora
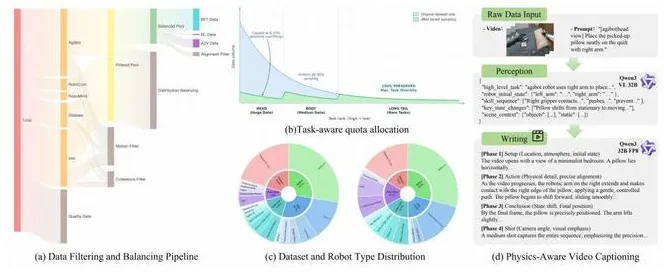
牛喀网获悉,阿里巴巴高德团队正式发布了ABot-PhysWorld,这是一个基于140亿参数DiffusionTransformer构建的物理对齐交互式世界模型。该研究直击当前视频生成模型的核心痛点——视觉美学与物理法则的背离,针对Sora等顶尖模型频繁出现的物体穿模、违反重力等物理谬误,从数据、训练、控制、评测四个维度进行了系统性革新。
该模型的突破性创新在于引入了“物理偏好对齐”机制,利用解耦的VLM判别器进行物理规则的“出题”与“打分”,通过Diffusion-DPO算法引导模型生成更符合物理规律的视频。实验结果显示,ABot-PhysWorld在PBench基准测试中的领域得分达到0.9306,显著超越Veo3.1和Sorav2Pro等顶尖模型。在自建的零样本评测基准EZSbench中,该模型同样拔得头筹,展现了强大的分布外泛化能力。
 点击“阅读原文”查看更多
点击“阅读原文”查看更多