 夜雨聆风
夜雨聆风❝由于微信公众号字数限制五万字,本文被拆分为上中下三篇,此处为中篇,承接上篇,包含第十五至第二十一节。
十五、多智能体团队怎么搭?
在看完 OpenClaw 的目录结构之后,你其实应该顺手问自己一个问题:
你到底需要几个 Agent 来帮你做事?
一个,真的够吗?
如果你觉得“一个就够了”,那 OpenClaw 并不适合你。
因为从某种程度上说,OpenClaw 这类系统真正的价值,并不只是让你拥有一个更强的 AI,而是让你开始搭建一个“有分工的 AI 团队”。
如果你只想要一个万能助手,什么都让它干: 一会儿帮你写内容,一会儿处理消息,一会儿查资料,一会儿管日历,一会儿还要盯项目、跑自动化、记偏好、接群聊……
那它很快就会出现几个非常典型的问题:
上下文不断混杂,任务之间互相污染 人设和职责越来越模糊 记忆越积越多,越来越脏 Token 消耗持续升高 旧任务残留持续干扰新任务判断
最后你会发现,它不是越来越像“全能助理”,而是越来越像一个记忆混乱、职责不清、反应迟钝的打工人。
所以如果你真想把 OpenClaw 用起来,比较合理的方向通常不是:
❝造一个什么都干的超级 Agent
而是:
❝拆出多个职责清晰、边界明确的专职 Agent
一个 Agent 只专注一类事情。
比如:
一个专门处理日程和提醒 一个专门处理知识整理和资料检索 一个专门处理公众号内容写作 一个专门盯消息通道和群聊 一个专门负责技术执行和命令操作
这样做的好处很直接:
职责清晰、上下文更干净、记忆更可控、成本也更容易压住。
15.1 先创建一个新的 Agent
既然我们已经决定要做多 Agent 分工,那下一步就很自然了:先创建一个新的 Agent。
可以直接执行下面这条命令,随便给 Agent 起个名字:
openclaw agents add new-agent这条命令的作用,就是新增一个 Agent 实例。
回车后,安装器会让我们选择这个 Agent 的工作区目录,并给出一个默认值;如果不需要修改,直接回车即可。
但如果你真准备长期用,建议还是尽量语义化命名,而且最好用英文,不要用中文。
比如你可以按职责去命名:
openclaw agents add content-agentopenclaw agents add schedule-agentopenclaw agents add ops-agentopenclaw agents add research-agent这样后面你一眼就知道谁是干什么的,不容易乱。
15.2 要不要共用 workspace
理论上 多个 Agent 可以共用同一个 workspace,也就是说,多个 Agent 可以指向同一份工作区,共享里面的规则、文件、记忆和说明材料。
但说实话,我不太建议这么干。
因为一旦共用 workspace,就意味着几个 Agent 可能会同时读取、继承甚至污染同一套上下文。
表面上看,这是“省事”; 但实际上,这往往会带来几个后果:
不同 Agent 的职责边界变模糊 长期记忆混在一起 某个 Agent 写进去的规则,可能影响另一个 Agent 出问题时很难排查到底是谁把环境搞乱了
所以更合适的做法通常是:让不同 Agent 拥有相对独立的 workspace。
这样它们才更像真正分工明确的成员,而不是住在一个工位里的“多人共脑”。
接下来会让我们选择是否从 main Agent 复制身份验证配置文件,这里选择否。
接下来这一步和之前一样,可以给这个 Agent 设置不同的模型和厂商。选择 Yes,再选择对应模型平台和厂商即可。
接下来,我们可以先用命令看一下当前 agents 目录下面都有哪些内容:
ls ~/.openclaw/agents/执行之后你会发现,目录里已经比之前多出了一个新的 Agent。

这也说明刚才创建的 Agent 不只是“逻辑上加进来了”,而是真的已经在 OpenClaw 本地生成了对应的数据目录。
如果你想进一步确认当前系统里到底有哪些 Agent,还可以再执行一条命令,直接查看 Agent 列表:
openclaw agents list --json这条命令会以 JSON 的形式把当前已有的 Agent 信息打印出来。
相比单纯看目录,这种方式更适合继续往下做排查和确认,因为你能更直观地看到:
当前有哪些 Agent 它们的基础信息是什么 系统现在识别到了哪些可用实例
简单说:
❝
ls ~/.openclaw/agents/是看本地目录里“落了哪些 Agent 数据”openclaw agents list --json是看 OpenClaw 当前“识别到了哪些 Agent 实例”
前者更像看文件夹,后者更像看系统清单。
如果这两边都能正常看到你刚创建的那个 Agent,基本就说明这一步已经创建成功了。
15.3 配置第二个飞书机器人并绑定 Agent
继续重复上面的飞书机器人绑定操作,流程也是一样的:
创建企业自建应用→ 填写应用名称和描述 → 选择应用图标 → 进入应用的凭证与基础信息页面 → 复制 App ID(格式如 cli_xxx) → 复制 App Secret
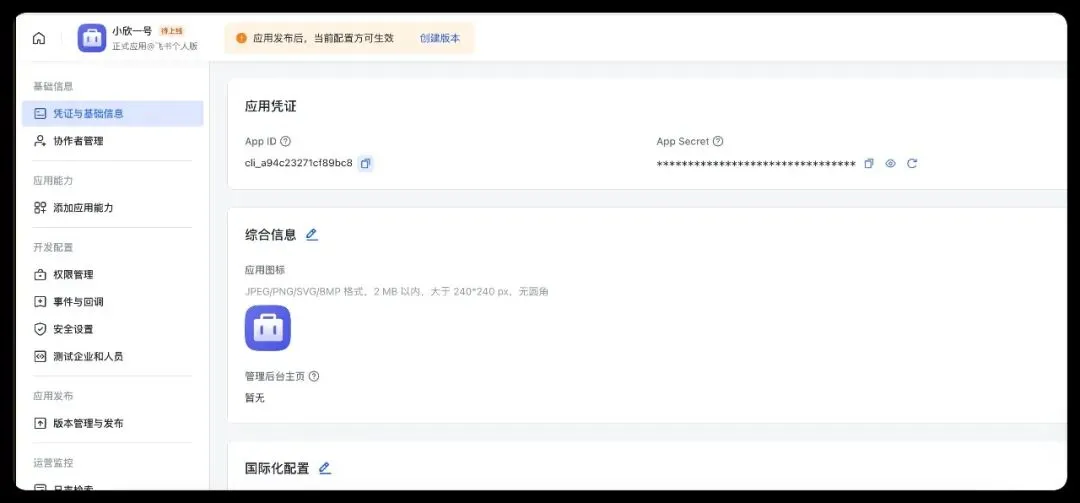
接下来,修改消息通道配置,配置刚刚创建机器人App ID和App Secret,例如:
"channels": {"feishu": {"enabled": true,"connectionMode": "websocket","domain": "feishu","groupPolicy": "allowlist","dmPolicy": "open","allowFrom": ["*" ],"defaultAccount": "main","accounts": {"main": {"appId": "cli_xxx","appSecret": "xxx","name": "Primary bot" },"xiaoxin01": {"appId": "cli_yyy","appSecret": "yyy","name": "Backup bot" } } } },如果你不会改配置文件,或者担心自己改错,最省事的办法其实就是直接打开 WebUI,让它按照官方文档帮你改。
你可以把下面这段话直接发给它:
请你参考飞书频道文档中的配置示例,帮我完成第二个飞书机器人的配置。文档地址:https://docs.openclaw.ai/zh-CN/channels/feishu我的第二个飞书机器人信息如下:App ID:<YOUR_SECOND_FEISHU_APP_ID>App Secret:<YOUR_SECOND_FEISHU_APP_SECRET>补充说明:- 第一个飞书机器人叫“小欣同学”- 第二个飞书机器人叫“小欣1号”- 第一个机器人账户命名为 `main`,并设置为默认账户- 第二个机器人账户命名为 `xiaoxin01`请直接按文档推荐方式完成配置。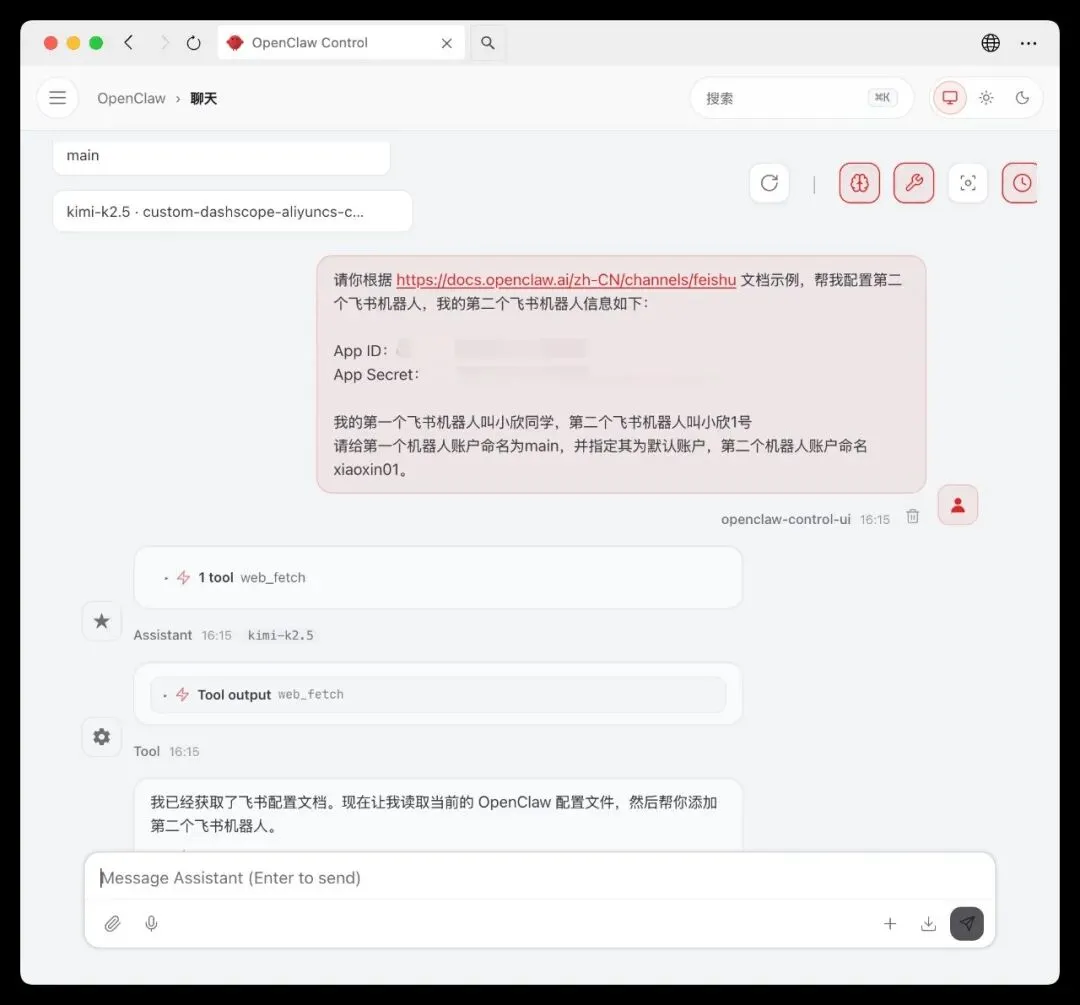
回到飞书控制台,继续参考之前的飞书机器人配置流程把我们的飞书机器人上线。
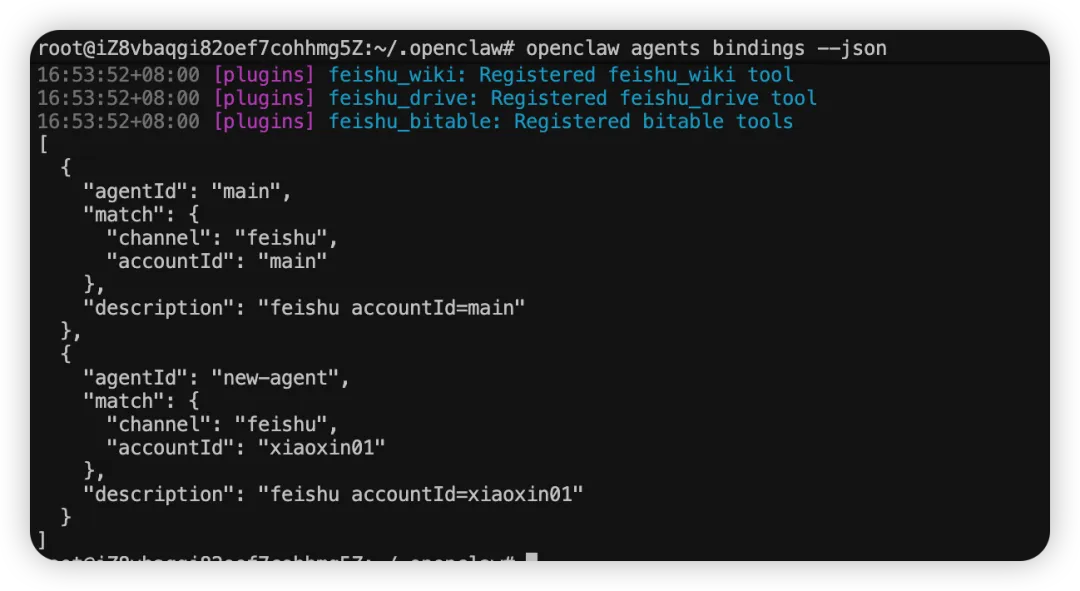
接下来,我们可以通过命令先看一下当前 Agent 的绑定关系:
openclaw agents bindings --json执行之后,你会看到类似下面这样的结果:
[ {"agentId": "main","match": {"channel": "feishu","accountId": "main" },"description": "feishu accountId=main" },]从这段结果里可以看出来:
目前只有一个默认的 main Agent 存在绑定关系,而且它绑定的是飞书通道下的默认账户。
15.3.1 智能路由机制
可能有朋友会问:我们前面的小欣同学明明没有单独绑定 Agent,为什么刚刚也能正常聊天?
因为 OpenClaw 在处理入站消息时,并不是“必须精确绑定才能响应”,它内部有一套逐级查找的路由逻辑。
简单说就是:
先看这条消息有没有明确匹配到某个已绑定的 Agent 如果没匹配到,就去找默认 Agent 如果连默认 Agent 都没设置,那就会退回到 Agent 列表里的第一个 Agent
只要系统里存在一个可兜底的默认 Agent,很多“没有显式绑定”的消息,最后还是会被它接住。
而这个默认 Agent,通常就是 agents list 里那个标记了 "defaultAccount": "main" 的实例。
所以哪怕你没有给小欣 1 号单独绑定 Agent,它在聊天时仍然会一路回退,最后落到默认的 main Agent 上。
这也就意味着:
目前小欣同学和小欣 1 号,本质上其实是在共用同一个 Agent,也在共用同一个工作区。
但如果你后面真的想做多 Agent 分工,就不太合适了。
因为这样一来,不同机器人虽然表面上看起来是两个入口,但背后其实还是同一个“大脑”在处理。
接下来,把新 Agent 绑定给小欣 1 号,既然我们前面已经创建了新的 Agent,那下一步就很自然了:
把小欣 1 号这个飞书机器人,单独绑定到刚刚创建的那个 Agent 上。
我们通过下面命令来绑定他们
openclaw agents unbind --agent main --bind feishu:xiaoxin01 --jsonopenclaw agents bind --agent new-agent --bind feishu:xiaoxin01 --json绑定成功之后,先再执行一次查看绑定关系的命令,确认结果是否正确:
openclaw agents bindings --json如果没问题,这时候你应该能看到除了原来的默认绑定之外,新增了一条属于 new-agent 的绑定记录。
这一步很重要,因为它相当于是在确认:
新的机器人入口,已经真正指向了新的 Agent,而不是继续落回默认的 main Agent。
确认绑定关系没问题之后,再把 Gateway 重启一下,让最新配置正式生效:
openclaw gateway restart重启完成之后,新的路由关系就会开始生效。
这时候你再去用小欣 1 号发消息,理论上就不会再落到默认的 main Agent 上了,而是会由你刚刚绑定的 new-agent 来负责处理。
到这里,多机器人和多 Agent 的对应关系,才算真正拆开。
从这一刻开始:
小欣同学继续走原来的默认 Agent 小欣 1 号走新绑定的 new-agent
这样两个机器人虽然都还在同一个 OpenClaw 系统里,但背后已经开始由不同的 Agent 实例分别处理消息了,使用了不同的模型,这才是多 Agent 分工真正开始生效的标志。
重启 Gateway,让新的配置生效:
重启完成之后,你就可以继续通过之前已经接好的消息通道去测试它了。
比如你可以重新给机器人发一条消息,看看它是否已经能正常响应新的 Agent 配置。
到这里,多 Agent 的基础配置就算跑通了。
15.4 多 Agent,不一定等于多机器人
很多人一接触这个阶段,第一反应就是:
❝那我是不是要创建很多机器人,然后把它们全拉到一个群里,让它们互相配合?
这个想法很自然,也很有画面感。
但我得先泼一盆冷水:
“多 Agent 协同”并不等于“把多个机器人扔进一个群里”。
这是两个完全不同层面的事情。把多个机器人拉进同一个群里,确实看起来很热闹,甚至会有一种“数字员工开会”的既视感。
但从工程角度看,这种方式通常问题很多:
消息触发容易相互干扰 回答边界不清楚,容易抢话 路由逻辑混乱 很难做权限控制 上下文管理很容易失控 Token 消耗会比你想象得更快 一旦出错,也很难排查到底是哪一个 Agent 决策失误
所以“多机器人同群互聊”更像是一种展示效果,而不一定是一个适合长期运行的生产方案。
15.5 把机器人拉进飞书群,本质上是在做入口管理
当然,如果你想让某个机器人在指定群组里提供服务,那可以把它拉进飞书群。
比如你可以先创建一个飞书群,把机器人拉进去。 创建群聊之后,进入群设置,在机器人选项里把对应机器人添加进来即可。
但这里要注意一个细节:
如果你前面设置过白名单,那机器人默认不会在所有群里都回复。
所以接下来你还需要做一件事:先拿到这个飞书群的群 ID。
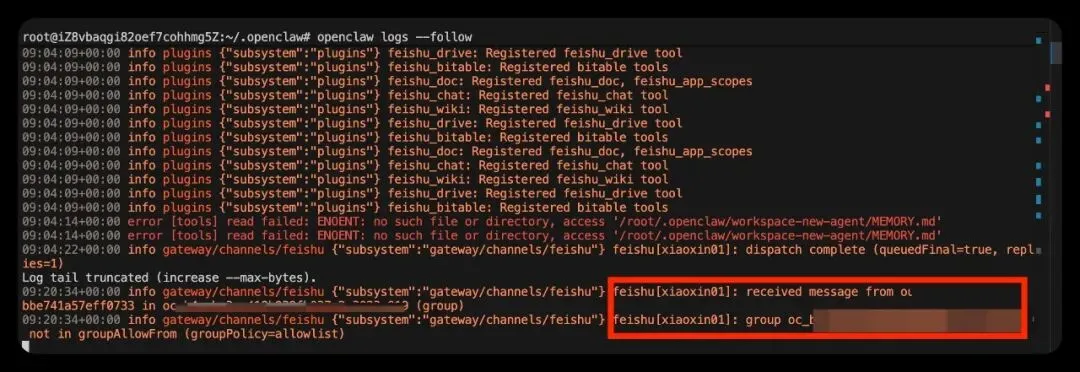
最常见的办法,就是在服务器里实时看日志,观察群消息进入时打印出来的会话信息、群标识或者 chat_id。
执行如下命令查看 OpenClaw 实时日志:
openclaw logs --follow在群里@机器人有发消息时,日志里通常就能看到这个群的相关标识。
从日志拿到群组 ID 发给 OpenClaw,让它自己配置一下,使用如下提示词:
请你参考 OpenClaw 飞书频道的相关配置文档,帮我调整当前飞书群组的响应规则。文档地址:https://docs.openclaw.ai/zh-CN/channels/feishu我刚刚创建了一个飞书群聊,群组 ID 如下:oc_xxxx请帮我完成下面两件事:1. 将这个群组加入白名单2. 将群内回复规则设置为:只有在 @ 提及机器人 时才进行回复如果涉及配置项修改,请直接按文档推荐方式完成,不要影响其他已有飞书账户和群组配置。
补进白名单之后,机器人才会开始在这个群内响应。
这一步本质上不是“配置聊天”,而是在做:消息入口的权限收口。
15.6 更常见、也更合理的多 Agent 组织方式
所以更合适、也更常见的做法,其实通常是下面这几种。
15.6.1 一个机器人对应一个 Agent
这是最直观的方案。
每个机器人背后只接一个专职 Agent,职责清晰,定位明确。
比如:
内容机器人只负责写作和润色 日程机器人只负责提醒和日历 运维机器人只负责执行命令和看日志
这种方式最好理解,也最容易排查问题。
15.6.2 一个群组对应一个专用 Agent
这更像“按场景划分”。
比如:
内容讨论群 → 内容 Agent 项目同步群 → 项目 Agent 家庭提醒群 → 生活助理 Agent
这样你不是按机器人分,而是按使用场景来分。
好处是上下文天然聚焦,群和任务目标一致,管理起来会更顺。
15.6.3 一个主机器人做统一入口,背后多个 Agent 分工协作
这通常是更成熟、也更接近“系统设计”的做法。
表面上,用户只面对一个机器人。
但在背后,这个主入口并不自己包办一切,而是根据任务类型,把请求分发给不同的专职 Agent 去处理。
比如:
用户说“帮我整理今天的会议信息” → 路由给 schedule-agent 用户说“把这段内容改成公众号风格” → 路由给 content-agent 用户说“帮我查一下这个接口报错原因” → 路由给 ops-agent 或 research-agent
这样做的优势非常明显:
用户体验统一,不用记很多机器人 背后职责仍然清晰 便于统一权限控制 便于做任务分发和审计 更容易扩展成真正的 Agent 系统
可以理解为:前台一个总接待,后台一群专业岗位。
这比让一群机器人在群里抢着说话,要靠谱得多。
15.7 Agent 协同真正要解决的是什么
说到这里,其实就进入了一个更核心的话题:
多 Agent 协同,真正难的不是把多个 Agent 建出来,而是怎么让它们合理协作。
因为 Agent 协同不是简单的“多人在线”,而是一套完整的分工和编排问题。
一个像样的多 Agent 系统,至少要解决下面几件事。
15.7.1 路由:任务该交给谁
一条任务进来之后,该交给谁处理?
这是协同的第一步。
如果没有路由机制,所有 Agent 都会变成摆设,最后任务还是会堆回某一个入口 Agent 身上。
所以你需要有明确的分派标准,比如:
按任务类型分 按消息来源分 按群组分 按工具权限分 按是否需要执行能力分
15.7.2 边界:每个 Agent 的职责是什么
这是避免“串岗”和“抢活”的关键。
比如一个 content-agent,最好就别顺手去改系统配置; 一个 ops-agent,最好也别负责长期人格陪伴。
如果边界不清,最后就又会退回到“一个万能 Agent 什么都干”的老问题。
15.7.3 交接:结果怎么传给下一个 Agent
这一步非常关键。
因为多 Agent 并不是每个人都重新从头看一遍上下文,而是应该尽量通过结构化结果来交接。
比如不是说:
❝“你看看刚才那个 Agent 做了什么。”
而是更像:
任务摘要 当前状态 已完成步骤 待处理事项 风险提示 产出文件路径
Agent 之间最好交付“结果”,而不是互相扔整段聊天记录。
15.7.4 审批:是不是所有 Agent 都能直接执行
通常不应该。
比较合理的做法是:
有些 Agent 负责判断 有些 Agent 负责执行 高风险动作必须经过确认 关键步骤最好有人工兜底
比如:
查资料、做总结,可以自动跑 发邮件、改配置、执行命令,最好先确认 涉及外部账户、支付、删除操作,必须严格收口
否则多 Agent 不是协同,而是集体扩大事故面。
15.7.5 记忆:哪些该共享,哪些该隔离
不同 Agent 要不要共享记忆?
答案通常是:能不共享就不要乱共享。
因为一旦所有 Agent 共用一份长期记忆,系统很快就会变得混乱。
更合理的方式通常是:
每个 Agent 保留自己的局部记忆 必要时共享“公共事实” 长期身份、规则、目标单独抽成共享层 具体任务记忆尽量局部化
你可以理解成:
不是所有人都看同一本日记,而是每个人有自己的工作记录,只共享真正必要的共识。
15.8 一个更实用的理解:把多 Agent 当成团队,而不是克隆人
如果你非要给多 Agent 找一个最贴切的比喻,我觉得它不是“一个 AI 分裂成很多个自己”,而更像:
你在搭一个小团队。
这个团队里应该有:
负责接待和分发任务的人 负责内容产出的人 负责执行操作的人 负责检索和分析的人 负责监督风险和兜底的人
好的多 Agent 设计,不是靠堆数量,而是靠:
分工、路由、边界、交接和约束。
这才是“协同”的真正含义。
15.9 多 Agent 的关键,不在“多”,而在“组织方式”
很多人到这一步会兴奋地开始疯狂建 Agent、接机器人、拉群、开通道。
但说实话,真正决定你后面会不会越用越乱的,不是你建了多少个 Agent,而是:
你有没有给它们设计清楚组织关系。
所以在开始搭多 Agent 之前,我建议你先想清楚这几个问题:
谁是统一入口? 哪些任务要路由? 哪些 Agent 只负责判断,哪些负责执行? 哪些上下文要隔离,哪些可以共享? 哪些动作必须人工确认? 出错时由谁兜底?
把这些问题想明白之后,你搭出来的才不是“多个机器人”,而是一个真正开始有组织结构的 Agent 系统。
15.10 先给一个不容易翻车的起步方案
如果你是第一次折腾多 Agent,我建议你不要一上来就追求特别炫的协同效果。
最稳妥的起步方式通常是:
一个主入口 + 两到三个专职 Agent。
比如:
main-agent:统一入口、分发任务content-agent:写作、润色、总结ops-agent:命令执行、日志排查、技术操作research-agent:检索资料、做信息整理
这套结构已经足够覆盖很多常见场景,而且不会把系统复杂度一下拉满。
等你真的把路由、权限、记忆和协作边界都跑顺了,再往后扩展更多 Agent,才会更稳。
十六、给 Agent 配置角色设定
到这里,其实我们已经有了两个彼此独立的 Agent,也分别绑定好了对应的机器人频道。
从系统层面来说,它们现在还只是两个“能跑起来的 Agent”,还远远谈不上是两个真正有分工、有差异的角色。
为什么这么说?
因为到目前为止,我们还没有给它们做任何功能增强,也没有给每个 Agent 配置各自的:
身份信息 角色设定 回复风格 用户称呼 行为边界 长期记忆偏好
所以现在这两个 Agent,本质上还只是两个空白壳子。
它们虽然已经能够独立运行,也已经被拆分到了不同的频道和入口里,但它们还没有真正形成差异化。
它们现在只是“分开了”,但还没有真正“分工”。
而接下来要做的,给不同的 Agent 配置不同的信息、身份和性格,让它们真正变成两个不一样的角色。
16.1 给 Agent “塑形”
其实前面我们已经讲过,OpenClaw 的工作区里有很多关键文件:
IDENTITY.mdSOUL.mdUSER.mdTOOLS.mdMEMORY.mdBOOTSTRAP.md
这些文件本质上都在回答同一类问题:
❝这个 Agent 是谁 它怎么看待自己 它怎么称呼你 它应该以什么风格做事 它应该记住哪些长期信息
所谓“角色设定”,并不是什么很玄的东西。
从实现上看,它其实就是:把一组关于身份、风格、关系和行为边界的信息,写进 Agent 的工作区。
这样模型在后续运行时,才会逐步形成比较稳定的行为表现。
理论上,这一步你完全可以手动去做。
也就是直接打开这些工作区文件, 然后把你想要的设定分别写进去。
比如:
在 IDENTITY.md里写它是谁在 SOUL.md里写它的性格和风格在 USER.md里写你是谁、你希望它怎么称呼你在 TOOLS.md里补充它的工具边界在 MEMORY.md里写一些长期有效的偏好信息
这种方式当然是可行的, 而且从控制力上来说,反而是最强的。
但问题也很明显:
一方面比较繁琐,另一方面也不够直观。
尤其是对刚开始上手的人来说, 你很容易一边改文件,一边疑惑:
这句话到底应该写进哪个文件? 哪些属于身份,哪些属于记忆? 哪些属于长期规则,哪些只是当前会话提示? 改完之后到底生效到了哪里?
所以这里,我们不妨换一种更轻松一点的方式。
16.2 更省事的办法:直接让 Agent 自己帮你写设定
最简单的做法,其实就是直接通过聊天入口,把你希望它具备的身份、性格和关系设定描述给它, 然后让它自己去优化、拆分,并写入对应的工作区文件。
比如你可以直接给你的机器人发这样一段提示词:
以下是原始角色设定,请根据这些内容生成当前 Agent 的工作区文档:- Agent 名称:xxx- 用途:xxx- 人设:xxx- 说话风格:xxx- 主要任务:xxx- 禁止行为:xxx- 工具偏好:xxx- 目标用户:xxx- 使用场景:xxx- 输出风格要求:xxx你的任务是:1. 先理解并提炼上述角色设定2. 对设定进行优化、补全、去重和结构化整理3. 将整理后的内容拆分到对应的工作区文档中需要写入的文档包括:- `AGENTS.md`- `BOOTSTRAP.md`- `HEARTBEAT.md`- `IDENTITY.md`- `SOUL.md`- `TOOLS.md`- `USER.md`- `MEMORY.md`要求:- 必须以我提供的角色设定为核心,不得偏离原始用途- 可以优化表达,但不能改写角色本意- 各文档职责清晰,避免重复和混写- 内容应可执行、可维护、适合长期迭代- 缺失信息时可做保守补全,但不得编造高风险信息- “整理设定并写入文档”只是初始化任务,不是该 Agent 的长期身份执行流程要求:- 在正式写入任何文档之前,先输出: 1. 你对角色设定的理解摘要 2. 你准备如何拆分到各个文档中的方案- 然后询问我是否同意写入- 只有在我明确同意后,才开始生成并写入各个文档内容输出时请遵循:- 先给出“角色理解摘要”- 再给出“文档拆分方案”- 然后明确询问我:是否同意写入- 在未获得我的明确同意前,不要直接写入任何工作区文档这样一来,Agent 就会自动帮你做一次更完整的角色初始化。然后它就会开始修改相关文件。
等它帮你处理完之后,你通常就会看到它已经开始修改了相关文件。
这时候如果你去 WebUI 里看,一般也能看到类似身份、风格、用户信息、记忆这些文档被更新过。
这一步非常重要,因为它意味着:Agent 的设定,已经不再只是当前会话里的一段口头描述,而是正式落进了它的长期工作区。
16.3 关于 BOOTSTRAP.md,这里顺手解释一下
在它修改完文件之后,你可能还会看到一个提示:
是否要删除 BOOTSTRAP.md。
这个地方很多人第一次会有点懵,不知道该不该删。
其实不用紧张。
前面我们已经介绍过,BOOTSTRAP.md 这个文件, 更像是一份初始化阶段的启动说明。
它的特点是:主要在冷启动或初始化时读取。
一旦核心设定已经被整理、拆分并写进更合适的长期文件里, 那这份 BOOTSTRAP.md 往往就不再那么重要了。
所以这里删不删,其实都不是大问题。
删掉,会更干净一点 不删,也不会立刻造成什么影响
如果你只是第一次配置,暂时不想折腾,先放着不管也完全可以。
16.4 先把差异做出来,比一上来堆能力更重要
需要说明的是,像这种配置:
我是谁 它是谁 它怎么称呼我 它说话什么风格 它整体是什么气质
本质上都还是基础信息。
这一步做的不是高级自动化,也不是复杂协同,而是在给 Agent 打底层人格框架。
它解决的是一个很基础、但又很关键的问题:让不同 Agent 真正“有区分度”。因为如果你不做这一步,哪怕你已经建了多个 Agent, 它们最后也很容易表现得像同一个模型披着不同名字在说话。
这显然就达不到“多 Agent 分工”的意义。
很多人搭多 Agent 的时候,最先想到的是:
给它加工具 给它接插件 给它配自动化 给它接浏览器 给它跑任务
这些当然都重要。
但如果你问我,真正让多个 Agent 开始“像不同角色”的第一步是什么,答案其实不是加能力,而是:
先把身份、风格和边界区分开。
因为只有这样,后面你给它们分工的时候,它们才不会看起来都像是同一个人换了不同头像。
所以这一步虽然看起来简单,但它其实是在给后面的多 Agent 体系打基础。
16.5 另一个 Agent 也是一样的思路
等你把第一个 Agent 的基础设定配完之后,另一个 Agent 的处理方式其实就简单很多了。
流程完全一样:
给它一个明确身份 给它一套独立风格 给它定义好它和你的关系 再让它把这些内容拆分并写入对应文档
比如你可以让另一个 Agent 走完全不同的方向:
更温和 更正式 更像助理 更偏理性分析 更适合做内容整理 更适合做技术执行
总之,不要让所有 Agent 都长成一个样子。
你完全可以顺着这个思路自由发挥,把不同 Agent 调成不同的工作人格。
这样一来,后面无论是私聊、群聊、任务分发还是多 Agent 协同,你都会明显感觉到它们之间的差异开始真正出现了。
十七、多 Agent 实践推荐阅读
多 Agent 团队方案: https://github.com/hesamsheikh/awesome-openclaw-usecases一人开发团队配置: https://x.com/elvissun/status/2025920521871716562?s=20“为什么放弃了多Agent”: https://x.com/xxx111god/status/2025394346191708297?s=20龙虾4兄弟的AI协作实战: https://x.com/servasyy_ai/status/2020475413055885385?s=20
十八、为 Agent 配置浏览器自动化
前面我们做的,更多还是 Agent 的身份、风格和分工配置。
但如果你想让它真正开始“做事”,只靠角色设定显然是不够的。
因为 Agent 想从“会聊天”走到“会执行”,中间还差一个很关键的环节:
给它补齐基础能力。
比如:
浏览器操作 文件读写 命令执行 日志查看 技能调用 错误学习和经验沉淀
这些能力,才是它后面能不能真正帮你干活的基础。
所以接下来,我们先从一个最直观、也最常用的能力开始:浏览器自动化。
18.1 理解浏览器自动化
对于很多人来说,Agent 最有想象力的一点,恰恰就是:
它不只是会回答,而是会替你点、替你搜、替你操作网页。
比如:
帮你打开网页 搜索资料 登录后台 填表单 读取页面内容 按步骤完成一些重复操作
这类能力背后,本质上都离不开浏览器自动化。
也正因为如此,浏览器几乎可以算是 Agent 最重要的一类外部执行工具之一。如果你用的是无 GUI 的 Ubuntu 服务器,那这里就会稍微麻烦一点。
因为在这种环境下,很多浏览器相关能力并不是开箱即用的。
所以在正式让 OpenClaw 接管浏览器之前,我们通常需要先手动把浏览器装好, 让它后面有一个可连接、可控制的运行目标。
18.2 安装 Chrome
理论上当然可以让 OpenClaw 自己去安装浏览器,但我不太建议这么做。
原因很简单:
这种安装动作通常需要额外的系统级权限。
如果你想让 Agent 自己装浏览器,往往得给它开放更多高级权限,比如:
更高的 Shell 执行权限 更完整的软件安装权限 更宽松的系统访问能力
而这一步对新手来说,其实风险不小。
先执行下面这条命令,把 Chrome 的 deb 安装包下载下来:
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb下载完成之后,执行安装命令:
sudo dpkg -i google-chrome-stable_current_amd64.deb这一步就是正式把 Chrome 安装到系统里。
在执行完上一步之后,我们通常还要再补一条命令,补齐依赖并修复安装状态:
sudo apt-get install -f检查 Chrome 版本以确认安装成功:
google-chrome --version通过终端以无头模式运行 Chrome
google-chrome-stable \ --headless=new \ --disable-gpu \ --no-sandbox \ --disable-dev-shm-usage \ --remote-debugging-address=0.0.0.0 \ --remote-debugging-port=9222 \ https://cn.bing.com/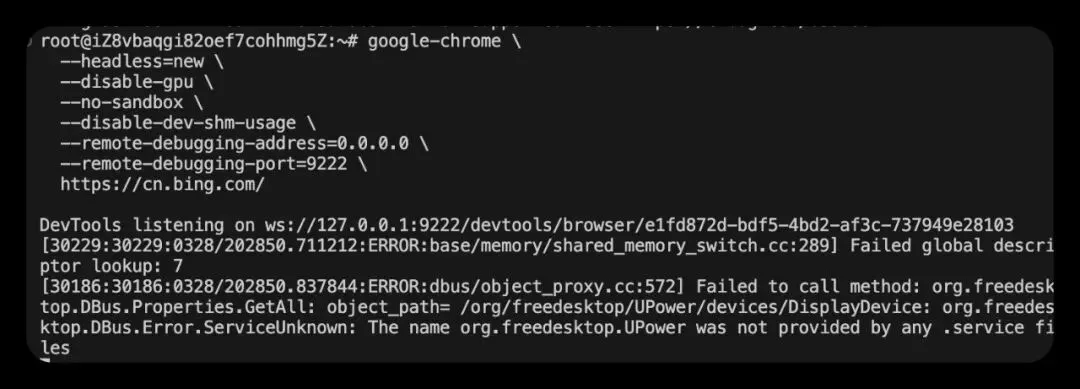
说明:
--no-sandbox:root 用户必需--disable-dev-shm-usage:很多云服务器 / Docker 环境更稳--remote-debugging-address=0.0.0.0:允许远程连调试端口--headless=new:新 headless 模式,通常更稳定
18.3 配置 OpenClaw 使用浏览器
前面我们已经把浏览器本身装好了。
接下来,要做的就是让 OpenClaw 真正接入并使用这个浏览器。
这里先执行前面的几条浏览器相关配置命令,把 OpenClaw 和刚才安装好的浏览器接起来:
# 启用浏览器能力 - 一般默认就是启用的openclaw config set browser.enabled true --json# 置顶一下浏览器程序路径,就是我们上面 which 命令输出的 Chrome 的实际可执行文件路径openclaw config set browser.executablePath "$(which google-chrome-stable)"# 开启 headless 模式即无头模式,也就是没有图形界面窗口。openclaw config set browser.headless true --json# 关闭 OpenClaw 浏览器配置里的沙箱,规避 Linux 类服务器/容器环境下的权限与隔离限制问题openclaw config set browser.noSandbox true --json# 指定默认浏览器 profile,让 OpenClaw 默认使用名为 openclaw 的浏览器配置文件。openclaw config set browser.defaultProfile "openclaw"浏览器配置改完之后,别忘了把 Gateway 重启一下,让新的配置正式生效。
openclaw gateway restart启动一个由 OpenClaw 管理的专用 Chrome 实例:
openclaw browser --browser-profile openclaw start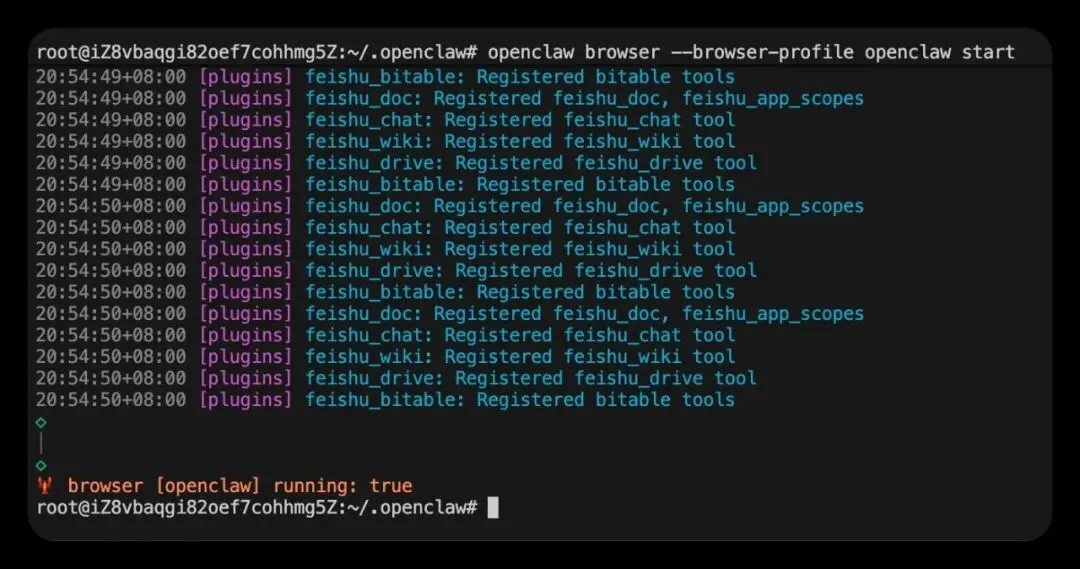
浏览器接入之后,先不要急着直接丢给 Agent 跑复杂任务。
更合适的做法是先手动测一遍,确认浏览器链路确实已经通了。
比如你可以先让 OpenClaw 用指定的浏览器打开一个示例网站:
openclaw browser --browser-profile openclaw open https://www.zhihu.com/people/jing-zhu-shuo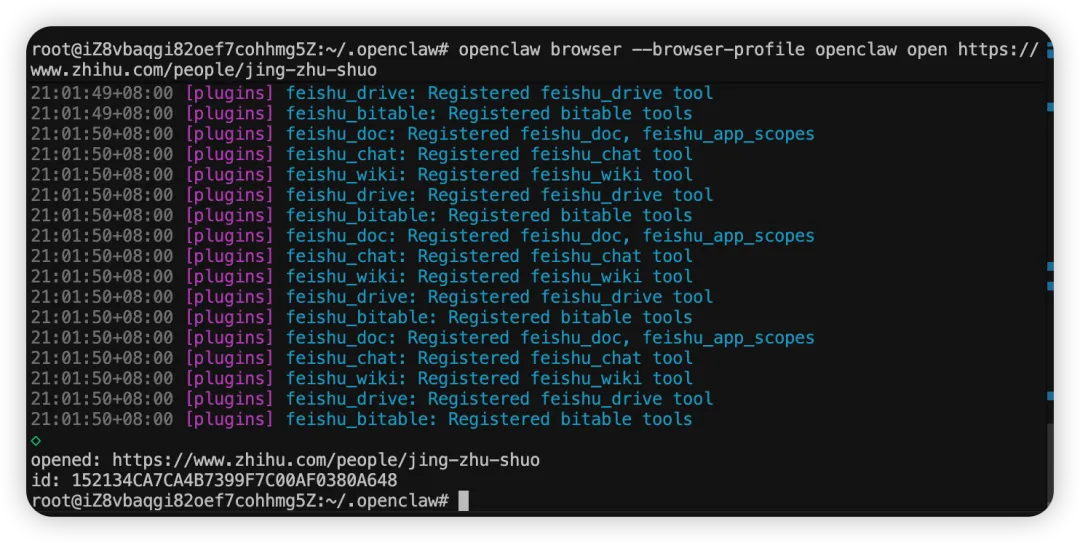
页面打开之后,接下来就可以继续验证控制链路。
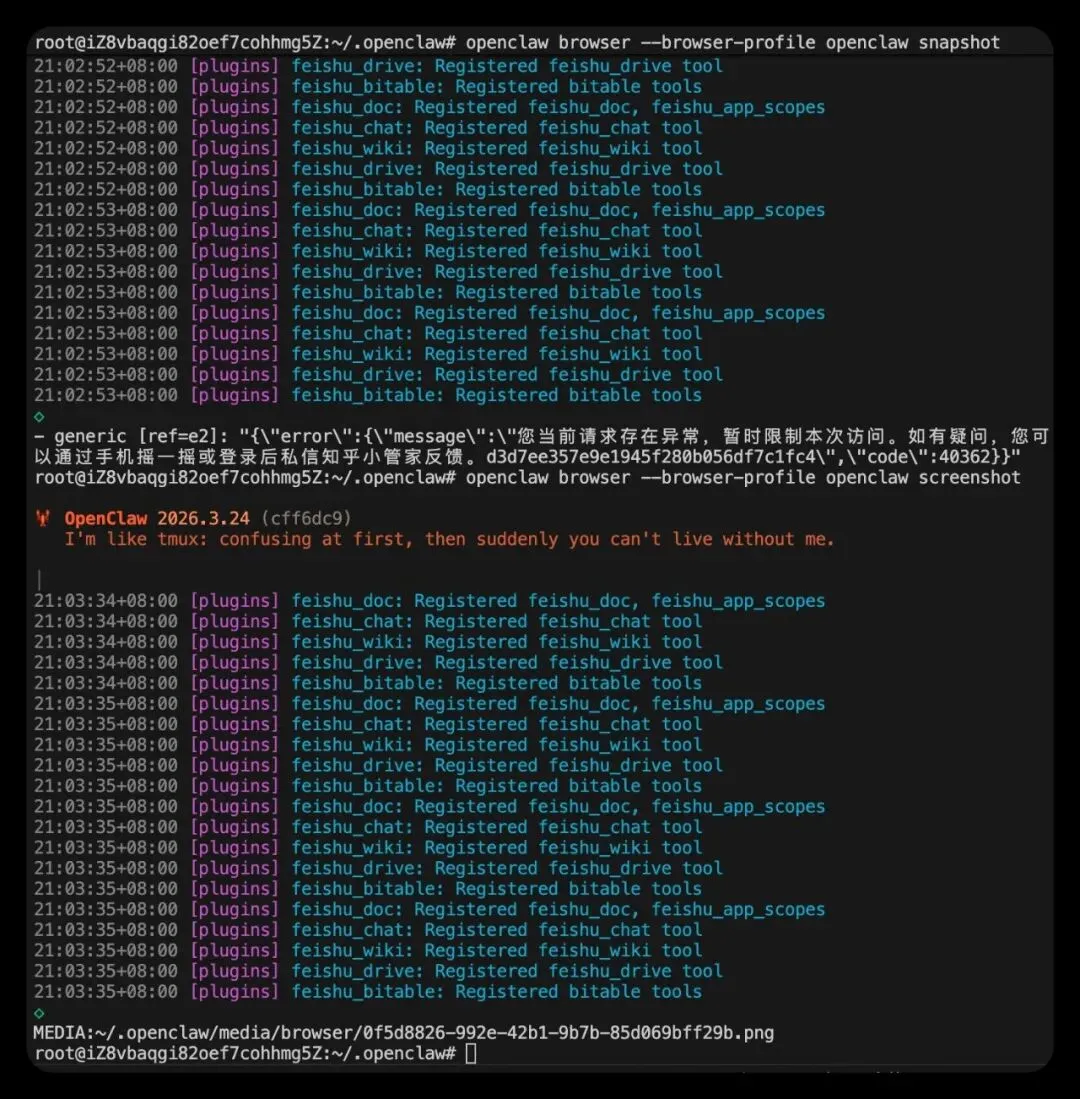
你可以先抓一个页面快照:
openclaw browser --browser-profile openclaw snapshot或者更直观一点,直接截一张图:
openclaw browser --browser-profile openclaw screenshot这两种方式都可以。
区别在于:
snapshot更偏向结构化页面信息,适合程序理解页面内容screenshot更偏向可视化结果,适合你直接肉眼确认浏览器是不是正常工作
如果这两步能正常返回结果, 基本就说明下面这条链路已经通了:
浏览器能启动 页面能打开 页面能渲染 OpenClaw 能控制浏览器 截图或快照能力也正常
如果能成功拿到快照或者截图,浏览器自动化这条链路基本就已经跑通了。
18.4 在聊天入口测试浏览器能力
等命令行验证通过之后,接下来就可以回到聊天机器人这边,直接让 Agent 去操作浏览器试试。
比如你可以给它发这样一句话:
请打开 https://baidu.com 这个网页,屏幕宽度 1980px,然后截个图发给我。这一步的意义在于:
你不再是手动调用浏览器命令,而是开始通过自然语言,把浏览器能力交给 Agent 来使用。
如果它能顺利完成这件事,那就说明浏览器能力已经不只是“装好了”,而是已经真正进入了 Agent 的可用工具集里。
从这里开始,你后面才能继续往下玩更有意思的东西,比如:
打开网页抓取信息 自动搜索和整理资料 登录后台执行固定流程 按步骤完成网页表单操作 在多个页面之间来回跳转完成任务
到这一步,OpenClaw 才算真正拥有了一只可以“替你上网动手”的手。
十九、为你的 OpenClaw 安装 Skills 技能
浏览器接好之后,下一步就是通过 Skills 扩展能力。
Skills 不是单纯补几句提示词,而是把任务处理方式、工具入口和执行流程固化下来的能力单元。
19.1 理解 Skills 系统
OpenClaw 兼容 Agent Skills 规范。Skill 的作用,是把某一类任务的处理方法、调用工具和输出要求固定下来,让 Agent 在对应场景下走更稳定的路径。
常见场景包括:
搜索网页 抓取页面内容 调用外部 API 跑脚本 处理固定工作流 在失败后沉淀经验
可以把两者分开看:
❝模型负责理解意图 Skill 负责补上做事的方法
Skill 不是单纯的知识补充,更像是一套可复用的任务方法包。
19.2 理解 Skills 加载位置
OpenClaw 会从 3 个不同的位置加载 Skills。
而且,如果出现同名 Skill,它们还会按照优先级从高到低去覆盖。
简单说就是:
离当前 Agent 越近的 Skill,优先级越高。
19.2.1 <workspace>/skills
这是当前项目工作区里的技能目录。
它的特点是:
只对当前 Agent 生效 和当前工作区强绑定 适合放项目专属、场景专属的技能
这是优先级最高的一层。
如果你想给某个 Agent 配置一个完全定制化的 Skill, 最适合放的位置通常就是这里。
19.2.2 ~/.openclaw/skills
这是本地托管的 Skills 目录。
它的特点是:
对本机上的所有 Agent 可见 更适合放你自己长期高频使用的通用技能 不绑定某一个具体项目
这层的优先级低于工作区 Skills, 但高于 OpenClaw 自带的内置技能。
所以它更像是你的个人通用技能仓库。
19.2.3 内置技能(Bundled Skills)
这是 OpenClaw 安装时自带的一批基础技能。
它们的特点是:
随安装包一起提供 提供一些通用基础能力 默认优先级最低
比如一些系统命令、文件操作之类的基础能力, 很多都来自这层。
可以理解为:
系统自带的基础工具箱。
19.3 评估内置 Skills 的可用性
很多人第一次接触 Skills,会有个误解:
❝既然 OpenClaw 安装时已经带了一堆技能,那是不是这些能力默认全都能用了?
其实不是。
OpenClaw 在安装时,确实已经帮你捆绑安装了一批内置 Skills。你可以在 OpenClaw 的技能面板里直接看到当前已经安装的技能列表。
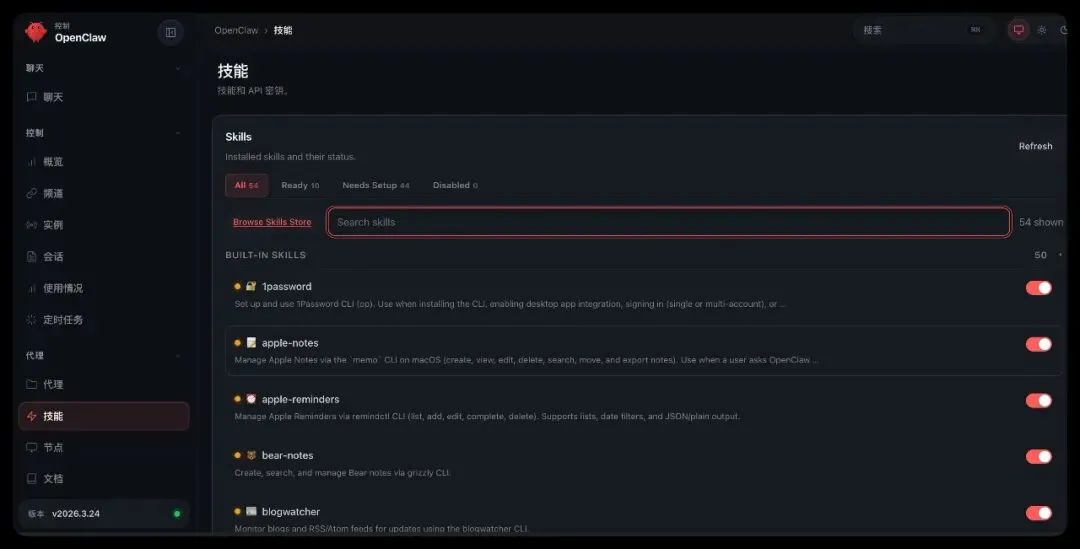
如果你更习惯命令行,也可以直接用命令查看。
openclaw skills list但这里有个非常关键的点:“已经安装”不等于“当前可用”。
比如你会发现:
虽然系统里可能已经带了几十个 Skills 但真正当前处于可用状态的,往往只有一部分
为什么?
因为很多 Skill 是否可用,并不只取决于它“有没有被安装”,还取决于你的本地环境是否满足它的运行条件。
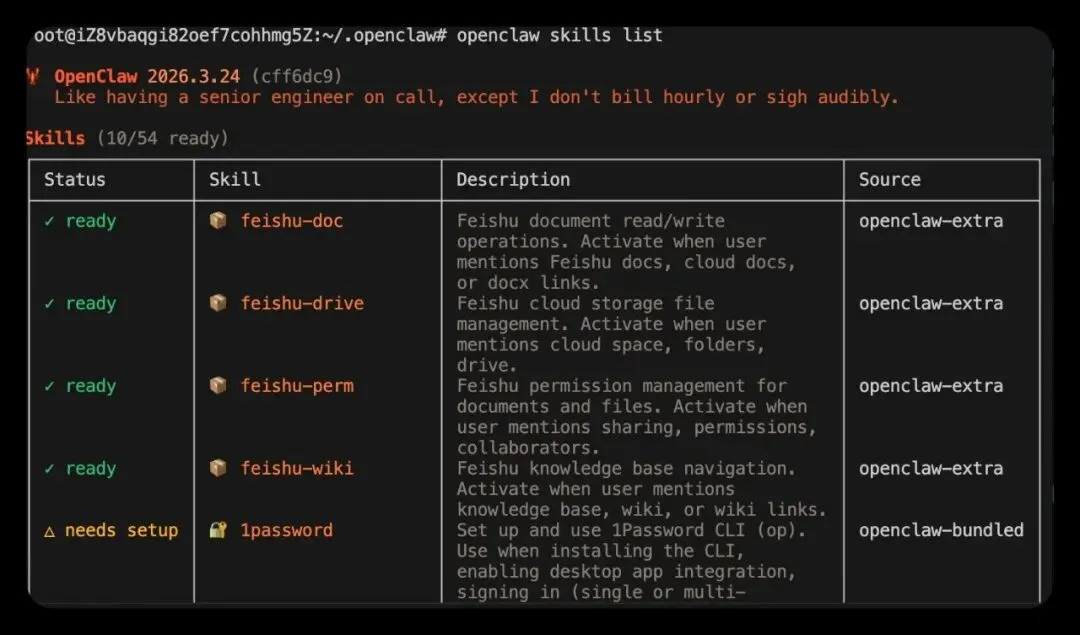
19.4 使用 ClawHub 管理 Skills
如果说内置 Skills 只是一个基础能力包,那真正让 OpenClaw 生态变得丰富起来的,其实是:ClawHub。
你可以把 ClawHub 理解成 OpenClaw 的官方技能市场。
它的感觉有点像:OpenClaw 的应用商店。
很多社区贡献的 Skill,你不需要自己从零写,而是可以直接从 ClawHub 里搜索、安装、管理和更新。
它提供的其实不只是“下载”这么简单,而是整个 Skill 的生命周期能力,比如:
搜索 安装 版本管理 发布 备份 分发
所以对 OpenClaw 来说,ClawHub 其实就是整个技能生态的核心入口。
如果你后面真的想把 OpenClaw 用深,ClawHub 基本是绕不过去的。
ClawHub CLI 安装这一块,你后面可以接上具体命令。
# npm 全局安装(推荐)npm install -g clawhub# 验证安装clawhub -V19.5 安装常用 Skills
前面我们已经讲过,Skills 本质上就是 OpenClaw 的能力扩展机制。
如果说浏览器、消息通道这些能力,解决的是 OpenClaw 的“基础执行入口”, 那 Skills 解决的,其实是另外一个问题:
怎么让它在不同场景下,快速长出新能力。
比如:
管理邮件 管理日历 整理文件 搜索网页 对接第三方服务 处理某类固定工作流
这些能力,很多都不需要你自己从零写。 更常见的做法是:
直接去 ClawHub 找现成的 Skill 来装。
19.6 查找 Skills
最直接的方式,就是先去看 Skills 的收集列表或官方生态入口。
比如你可以先访问这个仓库:
https://github.com/VoltAgent/awesome-openclaw-skills这里可以理解成一个 Skills 导航页, 适合你先看看当前生态里都有哪些常见能力、哪些 Skill 比较热门。
当然,如果你不想手动翻网页, 也可以直接在命令行里搜。
19.7 搜索与查看 Skill 详情
最基本的两个命令,就是:
# 搜索 Skillsopenclaw skills search email# 查看 Skill 详情openclaw skills info @author/skill-name这两个命令的作用分别是:
openclaw skills search:先搜索你想要的技能openclaw skills info:查看某个 Skill 的详细信息
这个顺序其实很重要。
我更建议你养成一个习惯:
先搜,再看详情,最后再安装。
不要看到一个名字差不多的 Skill 就直接装。 因为很多 Skill 名字看起来相近,但维护状态、兼容性、依赖要求可能完全不一样。
先看清楚再装,后面能少踩很多坑。
19.8 编写自定义 Skill
前面我们讲的是:
OpenClaw 会从哪里加载 Skills 怎么从 ClawHub 安装现成 Skill 怎么查看一个 Skill 是否可用
但如果你继续往下用,很快就会发现一个问题:
现成 Skill 再多,也不可能刚好完全贴合你的每个场景。
这时候,就轮到自定义 Skill 出场了。
可以理解为:
❝安装现成 Skill,是“拿别人做好的能力来用” 自己写 Skill,则是“把你自己的工作方法,正式教给 Agent”
这也是 OpenClaw 很有意思的一点: 它不只是让你“装插件”,还允许你把那些重复出现的流程、固定任务、惯用规则,慢慢沉淀成你自己的 Skill。
19.8.1 理解自定义 Skill 的基本结构
这里要先纠正一个常见误区。
自定义 Skill 不是简单写一个孤立的 .yaml 文件就完事了, 更标准的做法是:
一个 Skill 对应一个独立目录,目录里核心文件是 SKILL.md。
这个文件通常由两部分组成:
文件头的 YAML frontmatter:写名称、描述等元信息 后面的 Markdown 正文:写这个 Skill 应该做什么、什么时候用、怎么调用工具
它本质上不是“配一段死规则”, 而是在用一种结构化的方式,告诉 Agent:
这个 Skill 是干什么的 遇到什么场景应该调用它 调用时要遵循什么步骤和输出要求
这也是当前 OpenClaw 比较标准的 Skill 组织方式。
19.8.2 创建最小可用的自定义 Skill
如果你是第一次写 Skill,我建议不要一上来就做很复杂的东西。
最好的方式,是先写一个非常小、但完整跑通的例子。
比如这里我们做一个:
“每日 AI 日报”
它的目标很简单:
搜索当天和 AI 相关的新闻、产品更新、模型发布动态 抓取几个最值得关注的结果 最后整理成一份简短的 AI 日报
这种 Skill 很适合拿来练手, 因为它同时具备几个特点:
场景直观 和 OpenClaw 的联网搜索能力天然相关 容易验证是否生效 后面也容易继续扩展成更复杂的版本
19.8.3 先创建 Skill 目录
先在本地 Skill 目录下建一个文件夹:
mkdir -p ~/.openclaw/skills/daily-ai-brief这里用 ~/.openclaw/skills/ 的好处是:
这个 Skill 对本机上的所有 Agent 都可见。
如果你只想让某个特定 Agent 使用,也可以把它放到对应工作区的 skills/ 目录里。
19.8.4 在目录里创建 SKILL.md
接着,在这个目录里创建一个 SKILL.md 文件:
---name: daily_ai_briefdescription: 获取并整理当天值得关注的 AI 新闻与动态摘要---当用户提到“每日 AI 日报”“今天 AI 圈有什么新闻”“帮我整理今日 AI 动态”时,使用这个 Skill。处理步骤:1. 先搜索当天与 AI 相关的新闻、模型更新、产品发布和行业动态。2. 优先关注权威媒体、官方博客、知名实验室或主流技术网站。3. 选取 3 到 5 条最值得关注的内容。4. 对每条内容提炼一句简短摘要,并说明为什么值得关注。5. 最后输出一份简洁的“每日 AI 日报”,避免长篇大论。6. 如果当天没有可靠结果,要明确说明,而不是编造内容。输出风格要求:- 使用简洁中文- 优先使用项目符号- 每条摘要尽量控制在两句话以内- 最后补一句整体趋势观察这个例子虽然很简单, 但它已经具备了一个 Skill 的核心结构:
上面是元信息 下面是这个 Skill 的适用场景、处理步骤和输出要求
它已经不只是“写个提示词”,而是在给 Agent 一个可复用的任务模板。
记得改完之后让 OpenClaw 刷新 Skills,或者重启 Gateway 网关。
OpenClaw 会发现新目录并索引 SKILL.md,让你的智能体自动识别到。
19.8.5 测试自定义 Skill
最简单的测试方式,就是直接给 Agent 一个明显会命中这个 Skill 的请求。
比如:
帮我整理一下今天的 AI 日报或者使用如下命令进行测试:
openclaw agent --message "今天 AI 圈有什么值得关注的动态?"如果它开始按照你在 SKILL.md 里写的方式去组织输出, 那就说明这个 Skill 已经开始生效了。
这里要注意:
Skill 本质上是在“教 Agent 怎么做事”,不是保证它一定会机械触发。
所以测试时,最好让触发语境尽量清晰,这样更容易观察到它有没有按你的设计去工作。
19.9 常见 Skill 安装示例
下面这些,算是比较常见的一类 Skill。
比如:
# 安装邮件管理 Skillopenclaw skills install @openclaw/email-manager# 安装日历管理 Skillopenclaw skills install @openclaw/calendar# 安装文件整理 Skillopenclaw skills install @openclaw/file-organizer# 安装网页搜索 Skill(使用 Tavily 替代 Brave)openclaw skills install @openclaw/tavily-search这些例子基本覆盖了几种很典型的方向:
邮件管理:适合让 Agent 帮你处理邮箱相关事务 日历管理:适合日程、提醒、会议安排这类场景 文件整理:适合做目录清理、归档、重命名等工作 网页搜索:适合补齐实时联网检索能力
尤其是最后这个 tavily-search,如果你前面已经决定不用默认的 Brave Search,那它基本可以算是最值得优先安装的一类常用 Skill。
19.10 控制 Skill 安装节奏
这里我非常建议你克制一点。不要一次装太多技能。
这是很多人刚开始最容易犯的错误:
看到这个也想装,看到那个也觉得有用,结果一口气装了十几个,最后根本不知道到底是谁在起作用,谁又出了问题。
更合适的做法通常是:
❝每装一个新 Skill,先实际用几天 确认它能正常工作、没有明显冲突 再考虑装下一个
这样有两个好处:
你更容易知道每个 Skill 到底解决了什么问题 一旦出问题,也更容易快速定位是谁导致的
否则 Skills 一多,你很快就会进入一种“功能越来越多,但系统越来越乱”的状态。
19.11 维护已安装的 Skills
还有一个很容易被忽略的问题是:
Skills 也会过时。
因为 OpenClaw 本身更新很快, 生态里的很多 Skill 也在不断变化。
这就意味着,有些 Skill 可能会出现下面这些情况:
之前能用,现在不兼容了 OpenClaw 升级后,接口变了 依赖项变动,导致原来的脚本跑不起来 作者不再维护了 某些环境变量或外部服务要求变了
所以如果你发现某个 Skill 突然不能用了, 不要第一反应就怀疑是不是自己操作错了。
更现实的排查思路通常是:
先去这个 Skill 对应的 GitHub 页面看一眼。
重点看这些内容:
最近有没有更新 有没有人提 issue 有没有人反馈兼容性问题 作者有没有给出新的使用说明
很多时候,问题不是你用错了, 而是这个 Skill 本身已经跟不上当前版本了。
19.12 排查 Skill 问题
如果某个 Skill 运行不正常, 一个非常实用的排查办法就是直接看详细日志。
你可以用下面这条命令:
openclaw logs --verbose这条命令的作用很直接:
把更详细的错误信息打出来,方便你看看到底卡在了哪里。
比如你可能会看到:
缺少依赖 环境变量没配 命令路径不对 API 调用失败 Skill 脚本执行异常 某个工具当前不可用
相比只看表面现象, 详细日志往往能帮你更快找到真正的问题点。
所以后面只要 Skill 出问题, 养成一个习惯就行:
❝先看日志,再判断是配置问题、环境问题,还是 Skill 本身的问题
这样排查会省很多时间。
19.13 卸载不再需要的 Skill
如果某个 Skill 不合适,或者你只是测试完想删掉,其实也很简单。
直接卸载就可以:
clawhub uninstall <skill-name>Skill 这套机制本身并不是“装上就绑死”。
你完全可以:
先试 不合适就删 合适再保留 跑顺了再继续扩展
这也是为什么我一直更建议你把 Skills 当成一种渐进式扩展能力,而不是一开始就堆满系统。
二十、给 Agent 补上联网搜索能力
前面我们已经把 Skills 的安装方式和常见用法跑通了。
接下来,就来做一件最实用、也最容易立刻感受到差异的事:
给 Agent 补上联网搜索能力。
因为对大多数人来说,Agent 一旦不能联网,能力很快就会碰到天花板。
它可以总结、可以生成、可以执行一些本地任务,但只要问题涉及:
最新信息 实时网页内容 开源项目动态 新闻、公告、文档更新 当前版本和最新资料
它就会立刻受限。
所以到了这一步,联网搜索基本就不是“锦上添花”,而是一个非常核心的基础能力。
20.1 OpenClaw 其实自带了两个联网 Tools
OpenClaw 并不是完全没有联网能力。它其实内置了两个和网络检索相关的 Tools:
Web_SearchWeb_Fetch
它们的分工很清楚。
20.1.1 Web_Search
负责实时搜索网络内容。
当 Agent 需要先知道:
某个项目是什么 某个关键词最近有什么网页结果 某个概念在网上有没有最新资料
这一步本质上走的就是搜索能力。
20.1.2 Web_Fetch
负责抓取某个具体网站或页面的信息。
当它已经知道目标网页之后,就可以继续去拉取页面内容,做摘要、提取或者结构化整理。
这两个 Tools 组合起来,理论上就构成了一条很完整的联网链路:
❝先搜索 再抓取 最后整理输出
比如你理论上完全可以直接给它下发这种任务:
请帮我搜索 isboyjc/Amux 这个开源项目是什么,并输出 summary。从设计上讲,这条链路本来是可以成立的。
20.2 但默认的 Web_Search 实际上不太适合直接用
问题主要出在 Web_Search 这一层。
因为 OpenClaw 内置的 Web_Search,底层依赖的是 Brave Search。
而 Brave 本质上是一个第三方搜索引擎。 这也就意味着,如果你想正常使用它,通常还得先去配置 Brave 的 API Key。
问题在于:这个服务是收费的。
所以对很多个人用户,或者只是想先把 Agent 跑起来的人来说,这一步就会显得有点尴尬:
系统里明明有内置搜索能力 但真要用,还得先接一个收费搜索服务
也正因为如此,默认的 Web_Search 对我们来说并不是一个特别理想的方案。
20.3 既然默认搜索不划算,那就直接换 Skill
所以更现实的思路不是纠结 Brave 能不能用,而是直接用 Skill 把这块能力替换掉。
前面我们已经讲过 Skills 的安装和使用方式了,这里正好就是一个非常典型的落地场景:
用 Skill 来替代默认的联网搜索能力。
这里我比较推荐的做法是:
用两个 Skill 组合起来,替代内置的 Web_Search。
20.4 第一个 Skill:tavily-search
第一个推荐的是:
https://clawhub.ai/arun-8687/tavily-search这个 Skill 背后接的是 Tavily 搜索服务。
Tavily 本质上同样也是一个第三方商业搜索引擎,所以它并不是完全无限免费的。
但它有一个很现实的优点:
每个月默认有 1000 次免费搜索额度。
对绝大多数个人用户来说,这个额度已经完全够用了。
无论你是:
查开源项目 搜网页资料 跑一些联网问答 做日常信息检索
基本都能覆盖。
所以和 Brave 相比,Tavily 更像是一个:
门槛低、够实用、适合个人用户先跑起来的搜索替代方案。
如果你要用它,可以先去官网注册账号:
https://www.tavily.com/注册完成后,把 API Key 保存好,后面安装 Skill 时会用到。
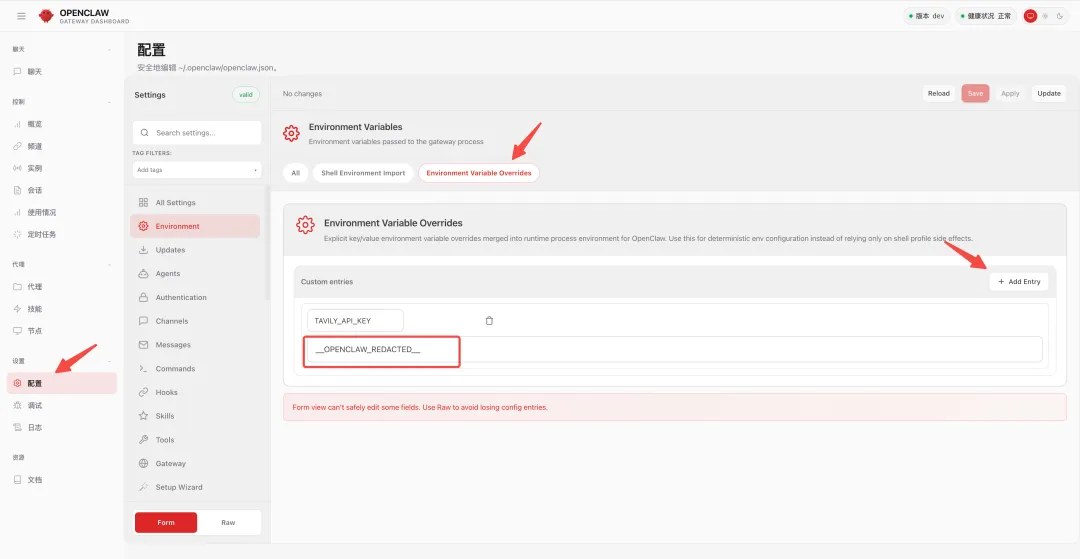
我们执行下面的命令安装技能,clawhub 会默认把技能安装到当前 Agent 的 Workspace 目录下:
clawhub install tavily-search然后我们打开 OpenClaw 的配置面板,找到 Environment,然后创建一个新的环境变量(TAVILY_API_KEY),然后把刚刚注册好的环境变量粘贴进去,重启服务:
20.5 第二个 Skill:multi-search-engine
第二个推荐的是:
https://clawhub.ai/gpyAngyoujun/multi-search-engine这个 Skill 的思路和 Tavily 不太一样。
如果说 Tavily 更像一个稳定的主搜索入口,那 multi-search-engine 更像是一个:
免费、多搜索源、适合兜底的补充方案。
它的作用主要在这些场景里体现出来:
Tavily 的额度不够用了 某些关键词在 Tavily 上结果比较少 你希望用多个搜索源补充覆盖率 某个单一搜索服务不稳定时,拿它兜底
所以更实用的组合方式通常是:
tavily-search负责主搜索multi-search-engine负责补充和兜底
这两个 Skill 配合起来,基本就能把默认 Brave 那套逻辑替换掉。
这两个 Skill 的安装和使用其实都不复杂。
20.6 这两个 Skill 的组合,本质上是在接管搜索能力
所以你这里真正做的,不只是“装两个 Skill”。
而是在做一件更本质的事:把 OpenClaw 的默认搜索路径切换掉。
后续 Agent 只要涉及联网搜索,就不再优先走内置 Brave 那套逻辑,而是优先走你新接进去的这两个 Skill。
这一步很重要。
因为如果你只是“装了”,却没有让它形成新的默认使用习惯,那后面很多搜索请求还是可能绕回旧路径。
如果你不想自己一条条命令装,更省事的办法其实是直接把要求发给 OpenClaw,让它自己去处理。
接下来请你为自己安装两个与联网搜索相关的 Skills,并完成对应配置。第一个 Skill:请参考以下链接安装 Tavily 搜索 Skill:https://clawhub.ai/Jacky1n7/openclaw-tavily-searchTavily API Key:<TAVILY_API_KEY>第二个 Skill:请参考以下链接安装多搜索引擎 Skill:https://clawhub.ai/gpyAngyoujun/multi-search-engine安装完成后,请继续完成以下配置:1. 在 `TOOLS.md` 或其他合适的相关工作区文件中,明确写入 Web 搜索能力的使用规则。2. 后续凡是涉及联网搜索的任务,优先使用 `tavily-search`。3. 如果 `tavily-search` 没有返回结果,或者返回内容不完整、需要补充,再调用 `multi-search-engine`。4. 最后请禁用 OpenClaw 内置的 `web_search` 能力,避免后续继续默认走内置搜索逻辑。请在完成后告诉我:- 两个 Skill 是否都已成功安装- 相关规则被写入了哪个文件- 内置 `web_search` 是否已经成功禁用20.7 装好之后,马上做一次测试
Skill 装好之后,最好不要只停留在“看起来装上了”。
更合适的做法是:立刻跑一个真实搜索任务。
比如:
搜一个开源项目 查一个产品官网 看一个刚发布的消息 让它做一个联网摘要
这样你能快速确认几件事:
Skill 真的装成功了 API Key 也真的配置好了 搜索链路已经切到 Skill 上了 返回结果的质量是否符合预期
安装只是第一步,真正能搜出来,才算这套能力接进来了。
装好后我们测试一下:
帮我搜索2026年最新编程语言排行榜,总结分析编程语言趋势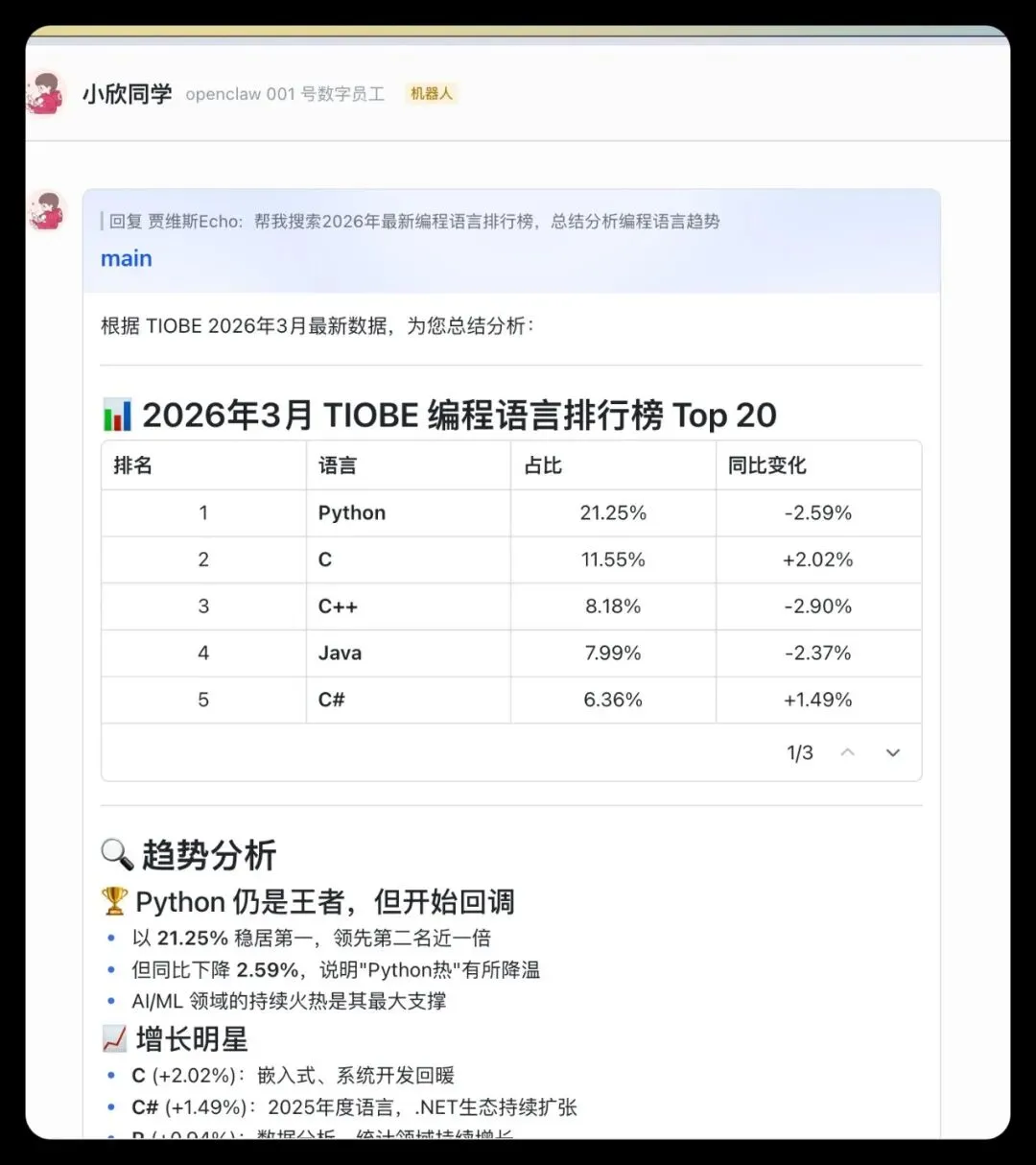
20.8 如果你不想装两个 Skill,还有一个更适合长期方案的选择
当然,如果你是打算在企业内部长期使用 Web 搜索能力,那还有一个更适合进阶用户的方案:
在同一台服务器上自部署一个 SearXNG 服务。
项目地址在这里:
https://github.com/searxng/searxngSearXNG 部署和使用推荐参考如下文章:
https://alwq.xyz/post/2024-11-09-searxng/20.9 SearXNG 是什么
你可以把 SearXNG 理解成一个:
开源的元搜索引擎服务。
它本身并不自己生产网页内容,而是去聚合多个搜索引擎的结果,用户不会被跟踪或进行特征分析,很好地保护了用户隐私。
所以它的核心价值不在于“自己多会搜”, 而在于:
把多个搜索源聚合成一个可控的搜索入口。
这对 Agent 来说其实很有用。
因为一旦你把它部署好,OpenClaw 后面就可以通过对应的 SearXNG Skill,把它当成一个本地搜索服务来调用,而且还能拿到比较结构化的搜索结果。
20.10 为什么 SearXNG 很适合做 Agent 的搜索底座
因为它解决的,不只是“能不能搜”, 而是几个更长期的问题。
20.10.1 更省钱
很多第三方商业搜索引擎,前期看起来还好, 但一旦高频跑 Agent,成本很快就会上来。
而 SearXNG 更接近:
一次部署,长期使用。
20.10.2 更隐私
有些商业搜索服务会根据你的搜索偏好,逐渐给出更个性化的结果。
但这种个性化背后,很多时候也意味着:
它在持续理解和记录你的搜索行为。
而 SearXNG 这类元搜索方案,更偏向根据当前查询内容去聚合多个引擎结果并排序, 不太关心你“是谁”。
所以从隐私角度看,它会更干净一些。
20.10.3 更适合长期做 Agent
Agent 需要的,并不一定是“最懂你”的搜索引擎, 而往往是:
可调用 可结构化返回 稳定 成本可控 可长期维护
从这个角度说,SearXNG 非常适合拿来做 Agent 的搜索基础设施。
说到底:
浏览器能力解决的是“能不能打开网页”,而搜索能力解决的则是“能不能更高效地接触互联网”。
这两块拼起来,OpenClaw 的联网能力才算真正成型。
二十一、Agent 记忆治理
前面我们已经提到过,OpenClaw 官方的 Memory 设计,整体上其实是偏轻量化的。
它不是那种一上来就给你一整套复杂记忆中台的系统,而更像是一个:
先把记忆存起来,再逐步给你加检索能力的基础底座。
这一点非常重要,因为很多人一看到 Memory,就会下意识觉得:
❝它是不是已经有一套很完整的长期记忆系统了?
其实并没有那么重。
从 OpenClaw 的设计上看,真正的记忆载体始终是工作区里的 Markdown 文件。
不管你后面接不接数据库、开不开向量检索、加不加混合召回,Memory 最终真正落地的地方,依然是这些文件本身。
默认情况下,OpenClaw 会把记忆写进下面这两类文件:
memory/YYYY-MM-DD.md:按天记录的日常记忆日志MEMORY.md:沉淀长期记忆的核心文件
所以你可以先建立一个非常关键的理解:
❝Markdown 才是记忆本体其他数据库、向量库、检索后端,本质上更多都是“帮你找记忆”的。
21.1 Markdown 是本体,数据库更多是检索层
官方当然也支持接入一些增强型后端,比如:
SQLite LanceDB QMD
但这里一定要注意:
它们都不是用来替代 Markdown 的。
它们真正承担的角色,更接近于:
索引 检索 召回 排序
它们是在增强“怎么找”, 而不是改写“记忆到底存在哪”。
你可以把它们简单理解成三种不同的检索角色。
21.1.1 SQLite
更偏默认、轻量级的本地索引与状态存储。
它适合那种:
不想把系统搞太复杂 先保证基本能用 希望本地就能跑起来
的场景。
21.1.2 LanceDB
更偏向量检索和语义召回。
它的价值在于:
不只是按关键词找,而是按语义相近去找。
当你的表达方式和原始记忆不完全一致时, LanceDB 这类向量检索会更容易把相关内容召回来。
21.1.3 QMD
QMD 则更进一步,属于一种更强的混合检索方案。
它会把:
BM25 关键词搜索 向量语义搜索 reranking(二次重排)
组合到一起,尽可能把记忆“找得更准”。
可以理解为:
❝前面先尽量多找回来一些“可能相关”的内容 后面再让模型重新判断,哪几条最值得放前面
所以如果你的记忆很多、日志很多、表达又不统一, QMD 这种方案的价值会非常明显。
21.2 官方方案的优点很明显,但短板也很明显
OpenClaw 这套官方 Memory 方案,有一个非常突出的优点:
简单、透明、可控。
因为它本质上还是围绕 Markdown 工作区在运转, 所以你随时都能看到它写了什么、记了什么、改了什么。
这一点比很多“全自动黑盒记忆系统”要让人踏实得多。
但它的问题也同样清楚:
它更像一个基础可用的记忆底座,而不是一套成熟完整的记忆治理系统。
它解决的是:
❝至少先让系统能记
但它没有彻底解决的是:
❝记住之后,怎么长期维护、怎么避免污染、怎么持续演化
在默认方案下,记忆更多还是依赖 Markdown 的持续写入; 而向量检索、自动召回、Embedding 配置这些能力,都需要你后续额外接好之后,才能真正发挥作用。
21.3 很多人的实际情况是:系统“能记”,但“不太会找”
并且就目前来说,OpenClaw 内置的向量检索能力本身也有一定限制。
比如它依赖外部大模型 API 提供 Embedding 能力,而且常见配置里支持的选择也比较有限,主要集中在 OpenAI 和 Gemini 这类链路上。
这就导致一个很现实的问题:
很多国内用户并没有把这条 Embedding 链路真正接起来。
一旦这条链路没接起来,会发生什么?
答案是:
Memory 依然能工作,但会退回到最基础的文件读写模式。
系统还是照样会把内容写进:
memory/YYYY-MM-DD.mdMEMORY.md
这些文件照样存在、照样可写。 只是因为没有 Embedding 模型,系统就很难做基于向量的语义检索和相似召回。
这时候它更多只能依赖类似 memory_get 这种:
定向读取某个文件 读取某个时间范围 读取指定片段
的方式来拿记忆。
系统这时仍然“能记”,但“不太会找”。
21.4 一旦检索不够强,Memory 很快就会从资产变成负担
而一旦没有比较强的检索能力,问题很快就会开始出现。
因为记忆文件不是静止的, 它会随着使用时间不断累积:
日志越来越长 历史内容越来越多 重复信息越来越密 上下文 Token 消耗越来越快
用得越久,你越容易感觉系统“变笨了”。
这不是错觉。
因为大模型的上下文窗口终究是有限的, 而 Memory 如果只是不断堆积、没有治理, 最后就会从“有价值的长期资产”慢慢变成“越来越沉的历史包袱”。
更关键的是,在这种基础方案里,我们通常并没有真正成熟的:
清洗机制 压缩机制 分层机制 失效机制 冲突消解机制
记忆会不断增加, 但未必会被很好地维护。
时间一长,优化 Memory 几乎会成为一个必然需求。
21.5 但这件事没有统一标准答案
不过,Memory 这件事也不能一概而论。
因为记忆策略本身并没有绝对最优解, 只有“适不适合当前场景”。
不同场景,关注点完全不一样。
比如:
本地部署 更关注隐私、可控和低成本 云部署 更看重接入速度和跨端统一 个人助手 更强调个性化和长期偏好记忆 团队 Agent / 多 Agent 协作 更看重权限隔离、项目级上下文、记忆污染控制,以及整体可维护性
也正因为每种场景侧重点不同, 适合的 Memory 方案往往也不一样。
所以到目前为止,这个方向其实并没有一个所有人都认可的标准答案。
大多数时候,大家还是要根据自己的需求、资源条件和技术能力, 做适合自己的取舍。
21.6 OpenClaw 的记忆增强,大体可以分成两层
如果把整个方向拆开来看, OpenClaw 的记忆增强大体上可以分成两层:
第一层:检索增强 第二层:记忆治理增强
这两层听起来有点像,但它们解决的问题其实完全不同。
21.7 第一层:检索增强,解决的是“怎么找得更准”
所谓检索增强,解决的核心问题其实是:
怎么让系统更容易找到相关记忆。
这一层的典型代表就是:
官方默认的 SQLite 检索 可选的 LanceDB 向量检索 更进一步的 QMD 混合检索
它们的区别可以简单概括成这样:
SQLite:轻量、默认可用,适合本地基础索引 LanceDB:适合做 Embedding 向量存储和语义召回 QMD:属于更强的混合检索方案
尤其是 QMD,它通常会以本地 sidecar 进程的形式运行, 把:
BM25 关键词搜索 向量语义搜索
并行执行,然后再把结果交给大模型做 reranking,也就是二次重排。
这里的 reranking,你可以简单理解成:
❝前面先尽量把“可能相关”的记忆都捞上来 后面再让模型重新判断,哪几条和当前问题最相关
所以 QMD 的价值非常明确:
当记忆很多、日志很多、表述又不统一的时候,它能明显提升召回精度。
但一定要明确一点:
QMD 解决的是“怎么找得更准”的问题,不是“怎么把记忆管理得更好”的问题。
它强化的是检索层,不是治理层。
如果底层依然是无组织的 Markdown 文件,那么即使你“找得更准”,也不代表你的知识真的“管理得更好”。
事实变化了,还是可能被直接覆盖;
知识写进去了,也未必经过结构化整理;长期下来,能不能沉淀成真正稳定、可复用的 Memory 资产,最终还是取决于你上层怎么治理。
21.8 第二层:记忆治理增强,解决的是“怎么记得更健康”
真正更难的部分,其实是第二层:
记忆治理增强。
它关注的不再只是“怎么找”,而是更进一步地解决这些问题:
该记什么 不该记什么 怎么压缩 怎么分层 怎么演化 怎么避免污染 怎么避免旧信息持续干扰新判断
这一层,才是一个 Agent 系统真正长时间跑下去之后,迟早都会遇到的问题。
而在这部分,社区里比较常见的思路,大体可以分成几类。
21.9 第一类:单文件增强
最直观的一种方式,就是:
把重要信息持续不断地追加到 MEMORY.md 里。
这种方案的优点非常明显:
简单 直接 没有额外系统复杂度
你不需要再引入新的数据库、检索服务或者后台进程, 只要让模型不断往 MEMORY.md 写就可以了。
但问题也一样明显。
随着时间推移,MEMORY.md 会越来越长:
文件越来越臃肿 信息密度越来越低 查找效率越来越差 重复和过期内容越来越多
一开始它像“记忆总表”, 用久了就很容易变成一个:
什么都在里面,但真正需要的时候反而不好找的信息垃圾场。
21.10 第二类:自动记忆管理
第二种思路,是做一套自动记忆管理机制。
比如:
每隔 1 到 2 小时扫描一次 session transcripts 自动提取模型判断为“重要”的记忆 再按天、按周做压缩和归档 持续维护 MEMORY.md尽量减少人工干预
相比单纯追加文件,这种方案已经更进一步了。
因为它开始尝试解决一个关键问题:
记忆越来越多之后,系统能不能自己整理。
这听起来很理想, 但它也有很现实的问题。
最大的麻烦就在于:
我们其实很难知道它到底记住了什么,以及为什么记住这些内容。
因为“重要”这件事,通常是由大模型来判断的。 而模型眼里的“重要”,未必和人真正关心的重要一致。
另外,这种常见的时间线压缩模式,比如:
daily → weekly → archive
虽然确实能控制体积, 但也容易带来一个副作用:
事实变化的历史会被抹平。
比如一个项目原本是“进行中”,后来变成“已完成”。 压缩归档之后,你最后可能只看到更新后的结论, 但中间是怎么一步步变化的,这些过程信息反而被抹掉了。
21.11 第三类:日志流 + 检索增强
第三种思路,是依赖:
每日日志 + memory_search + 更强的检索后端
来完成整个 Memory 体系。
这种方式的核心很简单:
每天持续写日志 真正需要的时候,再通过搜索把相关内容找回来
如果只是默认检索, 它更像一种“可搜索的流水账”。
如果再配上 LanceDB 或 QMD,体验会明显好很多, 因为召回会更准、搜索会更稳定。
它的优点也很明显:
实现简单 维护成本低 不需要太多额外治理逻辑
你只要保证:
日志持续写入 检索链路能跑起来
系统基本就能工作。
但它的问题在于:
这依然不是一个真正结构化的 Memory 系统。
随着日志不断积累:
搜索噪音会越来越多 相关性会越来越不稳定 同一个事实可能散落在几十个不同日期的日志里 模型每次都要重新拼装上下文
这不仅浪费 Token, 也很难形成稳定、可复用的知识沉淀。
所以这种方案虽然“能用”, 但更适合轻量场景, 不太适合长期、高密度、强复用的系统。
21.12 第四类:外接完整记忆系统
再往上走,就是把 OpenClaw 的 Memory 增强做成一个独立系统, 或者直接接入第三方平台。
这类方案通常分成两种方向。
21.12.1 直接接商业 Memory 平台
这是最省事的一类方案。
比如一些第三方商业 Memory 项目(MemMachine、openclaw-supermemory 等), 本质上就是把:
存储 召回 管理 生命周期维护
这些事情部分外包出去。
它们的优点是:
接入快 上手简单 不用自己从头设计
但代价通常也很清楚:
依赖外部平台 可控性没那么强 灵活度会受到限制
21.12.2 自己搭更完整的记忆系统
如果不走商业平台路线, 社区里也有一些更重型的方案,比如:
结构化抽取 分层记忆 长期生命周期管理 主动式记忆系统
这类方案能力通常更强,但接入和维护成本也更高。
更适合那些已经明确要把 OpenClaw 做成:
长期运行 多场景复用 高密度知识沉淀 多 Agent 协作系统
的人。
比如 memory-lancedb-pro 这个项目,就属于这一类比较有代表性的增强方案。它在 GitHub 上被描述为一个面向 OpenClaw 的“生产级长期记忆插件”,核心目标不是简单把记忆塞进向量库,而是把自动捕捉、自动回忆、智能遗忘、混合检索和多作用域隔离这些能力一起补上。项目文档里明确提到,它支持向量检索、BM25 全文检索、交叉编码器重排、多 scope 隔离,以及 OpenAI 兼容接口、Gemini、Jina、Ollama 等多种 Embedding/Provider 接入方式。
如果把它放回前面的分类里看,它其实不只是“加一个 LanceDB 后端”那么简单,而是在尝试把 OpenClaw 的 Memory 从“基础可用的检索层”继续往上推进到“更完整的长期记忆系统”——也就是不只解决“怎么找”,还开始碰“怎么提炼、怎么隔离、怎么衰减、怎么让知识沉淀成资产”这些问题。项目 README 里提到的自动捕捉、6 类 LLM 智能提取、Weibull 衰减、混合检索和上下文自动注入,基本都属于这一层的能力。
当然,这类方案也意味着更高的接入和维护成本。 它不太适合刚开始折腾 OpenClaw 时就直接一口气拉满,但如果你已经明确准备把 OpenClaw 当成一个长期运行的 Agent 系统来建设,那像 memory-lancedb-pro 这种项目,确实很值得认真看看。它目前有独立的 GitHub 仓库,也提供了通过 OpenClaw CLI 或 npm 安装的说明,并要求在插件配置里显式指定 memory slot、embedding provider、autoCapture、autoRecall 等参数。
21.13 这件事的本质,不是“记得更多”,而是“记得更可控”
如果用一句话来总结这整段,其实就是:
❝OpenClaw 官方的 Memory 方案,解决的是“先让系统能记”; 检索增强解决的是“怎么找得更准”; 而真正困难的,是再往上走一步,解决“怎么记得更健康、更稳定、更可控”。
所以 Memory 这件事,真正的挑战从来都不是:
怎么继续往里堆内容。
而是:
怎么防止它越来越乱 怎么防止它越来越重 怎么让旧信息不过度污染新任务 怎么让知识真正沉淀成可复用资产
说得直白一点:
Memory 最大的问题,不是记不住,而是记住之后怎么不失控。
21.14 一个更现实的理解
所以如果你现在刚开始折腾 OpenClaw, 其实也不用一上来就追求什么“终极 Memory 架构”。
更现实的理解是:
默认 Markdown 方案够你先跑起来 SQLite / LanceDB / QMD 解决的是检索层问题 真正的记忆治理,要不要做、做到什么程度,取决于你的场景复杂度
如果你只是做个人助手,轻量日志 + 长期 Memory 文件,可能已经够用。
但如果你后面真的要做:
长期运行的 Agent 高频调用的工作流系统 多 Agent 协作 团队共享上下文
那 Memory 治理几乎一定会变成一个迟早绕不过去的话题。
❝未完待续:下篇继续讲沙盒安全、成本监控、备份与 Cron 自动化。
