 夜雨聆风
夜雨聆风养OpenClaw、跑Claude Code这类AI Agent时,你是不是也遇过这种糟心事?让Agent查个Notion定价,一次请求就烧掉几万词元(Token),钱花了不说,效率还低到离谱。
其实问题根本不在Agent本身,而在你用的网页抓取方案——传统抓取方式专为人类阅读和通用爬虫设计,完全没为AI Agent做优化,这才导致了大量无效词元(Token)的浪费。今天就给大家分享一套专属AI Agent的抓取优化方案,让你的词元(Token)消耗直接砍半再砍半,最高能省99%!

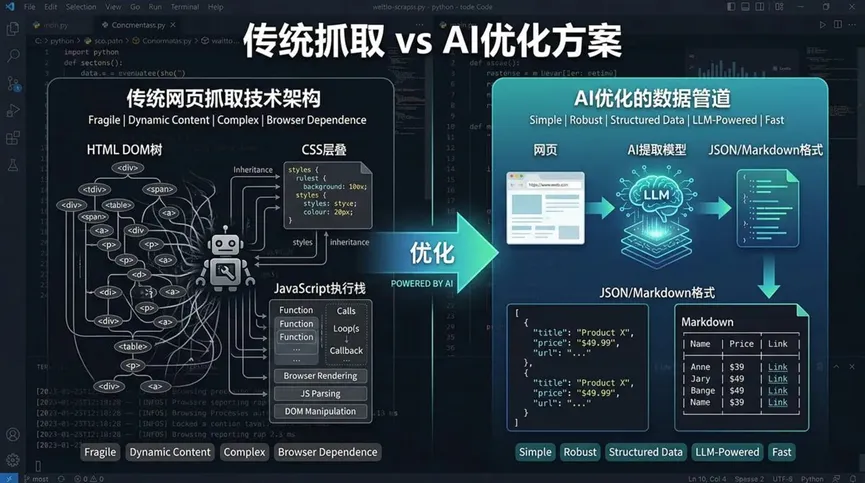
传统抓取手段(curl、web_search、浏览器自动化)在AI Agent场景里,有三个致命硬伤,每一个都在疯狂消耗你的词元(Token)。
用curl抓一个现代网页,拿到的是完整HTML结构、CSS样式、JS脚本,还有各种埋点、广告加载器,真正有价值的核心内容,往往只占1%-5%。Agent要从海量冗余代码里找信息,就像在垃圾堆里翻金子,词元(Token)全花在无意义的解析上。
现在很多网站对自动化访问敏感度拉满,Reddit、知乎直接403或弹人机验证,OpenAI、Cloudflare保护的站点只返回挑战页,动态渲染页面用curl抓下来就是个空壳。Agent拿不到有效数据,只能拿到错误页面,导致抓取的词元(Token)直接打水漂。
浏览器自动化能绕开部分反爬,但返回的是整页内容:正文混着导航栏、页脚、侧边栏、评论和推荐阅读。Agent还得再花一轮词元(Token),让模型充当“网页解析器”,过滤无用信息后才能提取核心内容,双重消耗得不偿失。

AI搜索方案的核心:量身打造的三层优化
传统方案需要开发者自己解决住宅IP轮换、浏览器指纹伪装、JS渲染重试、人机验证绕开等问题,耗时耗力还容易失败。AI搜索方案直接内置这些能力,无需额外开发,就能稳定应对知乎、Reddit、Cloudflare等各类风控页面,避免抓取失败导致的词元(Token)浪费。
传统方案返回整页HTML或文本,而AI方案会自动过滤导航、广告、页脚等噪音,仅提取核心内容,并输出Markdown(保留语义结构)、JSON(结构化数据)、Links(提取所有链接)、Screenshot(视觉验证)等格式,这些格式完全适配LLM,Agent无需二次转换,直接就能用。
针对定价页、更新页、讨论页等AI Agent高频使用场景,AI搜索方案能自动识别价格表、套餐卡片,提取版本号、更新点、发布日期,归纳评论观点、情绪倾向,把原本需要Agent完成的“网页理解”步骤前移,让Agent直接拿到可消费的结构化数据,彻底省去解析环节的词元(Token)消耗。

AI搜索方案带来的不只是词元(Token)的直接节省,更是从工程、失败、隐性成本等维度,全方位降低AI Agent的运营成本,这才是真正的“省钱”。
1.省词元(Token)(直接成本):过滤90%-99%的HTML噪声,新闻页省97%、定价页省99%,直接减少API调用费用;
2.省清洗(工程成本):Markdown/JSON格式直接可用,无需二次prompt做结构化处理,减少多轮对话的累积成本,也降低开发者的对接成本;
3.省重试(失败成本):90%+的抓取成功率,避免“抓取失败→重试→再失败”的恶性循环,搞定知乎403、Reddit验证、Cloudflare拦截等各类问题;
4.省推理(隐性成本):模型无需先充当“网页解析器”,直接处理结构化数据,推理效率大幅提升,同时减少模型幻觉和错误提取的概率,降低结果返工的成本。


传统网页抓取方案的设计前提,是默认使用者是人类——能看懂HTML结构、能忽略冗余信息、能手动提取关键内容。但AI Agent不是人类,它不需要完整的网页,只需要干净的、结构化的、可直接消费的数据。
与其在更便宜的模型上抠抠搜搜,不如从源头减少无效词元(Token)消耗——别让模型吃“垃圾”,让每一个词元(Token)都花在核心任务上,这才是AI Agent最极致的省钱攻略。
用好专为AI Agent设计的搜索方案,不仅能大幅降低成本,更能提升Agent的处理效率和结果准确性,让你的AI Agent真正发挥出最大价值。
