 夜雨聆风
夜雨聆风
文|Hive硅基秩序编辑|Hive硅基秩序来源|Hive硅基秩序封面来源|图片来源网络
1 Agent 团队架构:别急着造“超级智能体”,先学会分工
很多人第一次搭 Agent / AI Agent / 智能体,思路都很一致:给它接上 LLM,再塞进一堆工具,最好还能顺手读文档、查网页、写文件、发消息。表面看,这很像“一个顶十个”的理想员工;但实际用起来,你大概率会遇到三个经典问题:上下文越来越乱,角色越来越混,权限越来越危险。说白了,就是你本来想造一个聪明助手,结果先造出了一个权限过大的“数码实习生”。
OpenClaw 官方文档本身就透露了一个很关键的信号:它的核心不是“云端多租户平台”,而是一个本地自托管的 Gateway 中枢,把聊天渠道、工具和 Agent 接在一起;同时,官方也明确提醒,系统应该从最小权限开始,而不是先把所有能力一股脑放开。 这句话翻译成人话就是:你真想把 OpenClaw 玩深,第一步不是“装更多”,而是“拆角色”。
所以更靠谱的结构不是一个全能 Agent,而是一个最小协作团队。你完全可以把它理解成一家很小但很能打的创业公司:有人负责接需求,有人负责拆方案,有人负责干活,有人负责检查,还有人负责把经验写进“组织记忆”。这一套听起来像是把简单问题复杂化,但实际恰恰相反,它是在把原本糊成一团的系统拆清楚。
Agent 是什么?可以把它理解成“会思考、会调用工具、会完成任务的 AI 智能体”。如果 Chatbot / 聊天机器人 更像一个会说话的窗口,那 AI Agent 更像一个能接任务的数字打工人。
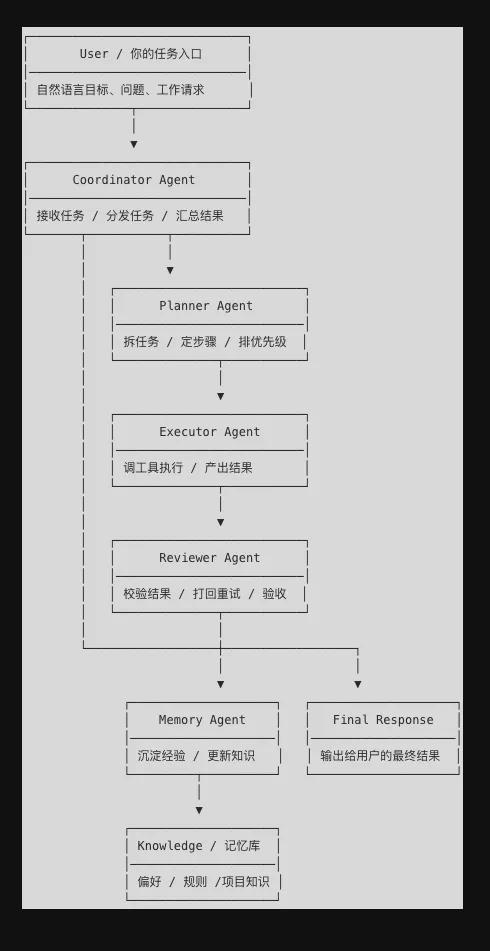
一个适合 OpenClaw 的最小团队,通常长这样:
你会发现,这套设计本质上不是炫技,而是在降低复杂度。因为当一个 智能体 既要理解需求、又要规划、还要执行、顺便审核,最后再把信息存起来时,它不是更强,而是更容易“精神分裂”。真正可用的 Agent 系统,不是能力都堆到一个脑子里,而是先学会像一个组织一样分工。
下面这个项目结构,就是一个很典型的 OpenClaw 团队化雏形:
openclaw-workspace/├── gateway/ # Gateway 配置:统一接聊天入口、模型与工具│ ├── config.yaml│ └── routes.yaml├── agents/│ ├── coordinator/ # 总控 Agent:接任务、分任务│ ├── planner/ # 规划 Agent:拆步骤、定优先级│ ├── executor/ # 执行 Agent:调用工具干活│ ├── reviewer/ # 审核 Agent:检查输出结果│ └── memory/ # 记忆 Agent:沉淀长期知识├── skills/ # 各类 Skill 能力包└── knowledge/ # 长期知识库与记忆文件这里最重要的不是目录名,而是这套结构背后的逻辑:角色和权限要分开,规划和执行最好分开,记忆也要独立出来。 你不一定非要一次上五个 Agent,很多个人场景下,先从三个开始就够了:Coordinator、Executor、Memory。
2 任务编排系统:让 Agent 会协作,不等于让它们“自己聊一会儿”
很多人理解中的“多智能体协作”,本质上是让几个 Agent 在那儿轮流发言。看起来很热闹,像一个 AI 版线上会议;但真到执行层面,这种方式经常效率很低。原因很简单:会对话,不等于会编排。前者像一群人开会,后者才像有人真把活排下去了。
所以第二步的关键,不是再造一个新角色,而是给整个 Agent 团队配一个任务编排系统。它的核心作用只有一句话:让任务从“需求”走到“结果”的每一步,都有状态、有责任人、有回退机制。换句话说,不要让 Agent 靠心情发挥,而要让流程像装了轨道一样往前走。
最适合 OpenClaw 起步的方案,不是上来就搞复杂 DAG 或工作流引擎,而是先用一个非常轻的状态机。比如一条任务从 new 开始,进入 planned,再到 running,之后走到 review,最终变成 done、retry 或 blocked。听起来很朴素,但好处是清楚,而且非常适合本地 Agent 系统。
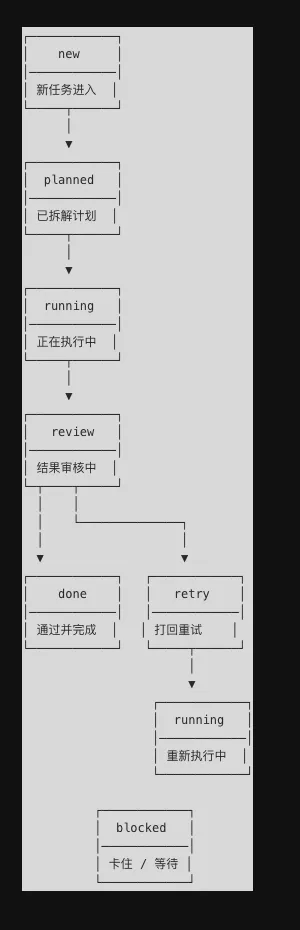
可以先把编排层理解成一个“任务交通警察”。用户说一句“帮我整理会议纪要并生成跟进邮件”,Coordinator 不应该自己全做,而是先让 Planner 把任务拆开,再让 Executor 去调用工具,最后让 Reviewer 看看结果够不够用。这样系统才不是“一个模型硬扛全部”,而是“多个 Agent 在同一条流水线上交接”。
一个极简编排目录,差不多这样就够用了:
orchestrator/├── task_schema.json # 任务结构定义├── task_queue.json # 当前任务队列├── state_machine.md # 状态流转规则├── runners/│ ├── dispatch.py # 按状态派发给不同 Agent│ ├── review.py # 审核逻辑│ └── retry.py # 重试逻辑└── logs/ └── tasks.log # 执行摘要日志任务本身也不用设计得太重,越轻越容易跑起来:
{"id": "task_001","goal": "整理客户会议纪要并生成跟进邮件","status": "planned","plan": ["提取会议重点", "识别行动项", "生成邮件草稿"],"artifacts": [],"review_score": null}对应的分发逻辑,甚至可以短到这种程度:
defnext_step(task):if task["status"] == "new":return"planner"if task["status"] == "planned":return"executor"if task["status"] == "running":return"reviewer"if task["status"] == "retry":return"executor"return"done"这段代码不高级,但它传达了一个很现实的原则:任务编排的价值,不在于代码有多花,而在于每一阶段的输入输出是不是足够明确。 Planner 输出的应该是结构化计划,而不是一大段“灵感散文”;Executor 输出的应该是“结果 + 日志 + 错误信息”;Reviewer 输出的应该是“通过 / 驳回 / 重试建议”,而不是一句“我觉得还行”。
这里有个很关键的边界感:Planner 负责想,Executor 负责做。这不是形式主义,而是防止模型在“想方案”的时候,顺手把高风险操作也做了。
如果说前一节是在搭组织架构,那这一节做的,其实是给组织装“流程骨架”。没有编排,多 Agent 只是多人群聊;有了编排,它才开始像一个真正能交付结果的系统。
3 Skill 工具生态:AI Agent 真正能不能干活,取决于它会不会“调能力”
说到底,Agent 再会思考,也不能只靠嘴。你让一个 AI Agent 规划得再漂亮,如果它不能读文件、发请求、写内容、调用真实工具,那它本质上还是一个比较积极的聊天机器人。也就是说,智能体的上限,通常不只取决于模型,而取决于它连接了什么能力。
这就是 Skill 的价值。根据 OpenClaw 官方文档,Skills 是兼容 AgentSkills 的目录结构,每个 Skill 的核心文件是一个带 YAML frontmatter 的 SKILL.md,系统会按环境、配置和二进制是否存在来决定是否加载;同时,Skills 可以来自内置目录、用户本地目录或工作区目录,工作区优先级最高。 换成更容易理解的话:Skill 就像给 AI Agent 装的“能力插件”,但它不是一个按钮,而是一份有规则、有输入输出边界的能力说明书。
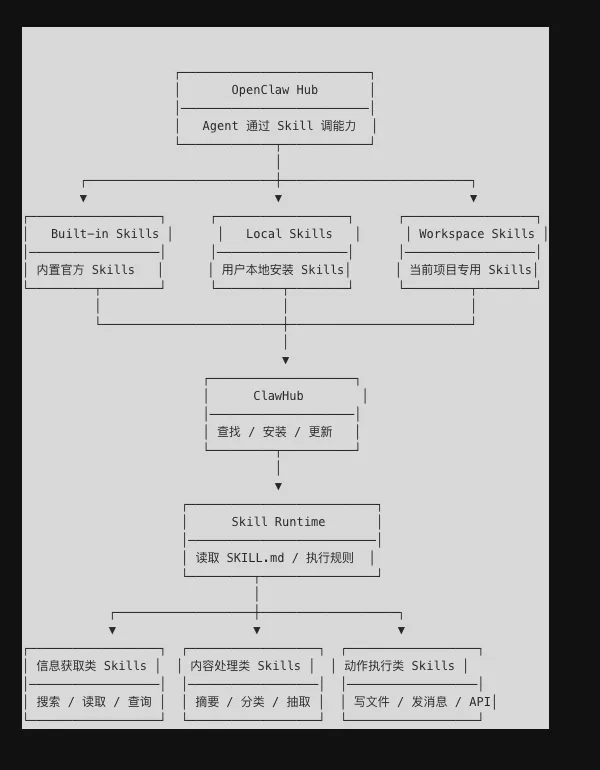
很多人刚开始写 Skill,容易把它写成“很长很长的一段提示词”。这当然也能用,但效果往往一般,因为它更像一篇说明文,不像一个可复用的能力模块。更实用的写法,是把一个 Skill 拆成三层:什么时候用、输入是什么、输出是什么。你可以把它看成一份写给模型看的 API 文档。
一个足够短、但已经能工作的 Skill 目录,大概长这样:
skills/customer_followup/├── SKILL.md # Skill 主文件:说明用途、输入输出与规则├── examples.md # 给模型看的例子,减少误用└── templates/ └── email.txt # 邮件模板资源而 SKILL.md 最小可以简到这种程度:
---name: customer_followupdescription: 根据会议纪要生成客户跟进邮件---# 何时使用当用户要求整理会议结论、生成跟进邮件、列出待办时使用。# 输入- meeting_summary- action_items- tone# 输出- subject- email_body# 规则1. 先总结结论,再列行动项。2. 邮件简洁,不复述会议全文。3. 时间信息缺失时,标记“待确认”。你看,这里面没有任何“神秘感”。它做的事情其实很朴素:告诉模型“什么时候该用我、拿到什么参数、应该吐出什么结果”。也正因为朴素,它才适合放进一个长期运转的 OpenClaw / AI Agent 系统里。
更进一步看,Skill 生态最好分层,不要一股脑堆一堆“万能工具”。比较实用的分法是四类:信息获取类、内容处理类、动作执行类、业务流程类。
这里有个容易被忽视但非常重要的现实问题。官方文档在 Skills 和安全说明里都强调了一个态度:第三方 Skills 应被视为不受信任代码,高风险工具应优先考虑隔离。 这件事的意思其实不复杂:别把 Skill 想得太“温柔”。它如果接到了真实世界能力,就不是“提示词装饰包”,而是一个可能会影响你文件、账户、系统环境的执行入口。
好用的 Skill 生态,不是“装得越多越厉害”,而是“每个 Skill 的边界越清楚,整个 Agent 系统越稳定”。
顺便说一句,如果你关心搜索关键词层面的表达,OpenClaw 和 Manus、MiniMax 常常会被放在同一个讨论语境里,但它们并不是同一类产品叙事。本文更关注的是 OpenClaw 作为一个 开源、自托管、可扩展的 AI Agent / 智能体框架,怎么把“能力调用”这件事做扎实,而不是停留在产品名词热度上。
4 长期记忆 + 知识库:没有记忆的智能体,只是在反复“重新做人”
一个很常见的误会是:只要模型够强,Agent 就会越来越聪明。现实通常没这么乐观。很多 AI Agent 看起来每次都很努力,但因为没有稳定的长期记忆,所以每次都像刚入职第一天。你昨天让它学会的偏好、模板、规则、项目背景,今天它可能又忘了。严格说,这不算“持续学习”,更像“持续重新开始”。
这也是为什么 长期记忆 + 知识库 会成为 Agent 系统里特别关键的一层。公开文档和社区资料经常会把 OpenClaw 归纳为支持本地持久化、可扩展工作区和多轮任务上下文的个人 AI 助手形态。 这意味着,你完全可以把记忆系统做在本地,并且保持可见、可审计、可修改,而不是把所有“学到的东西”都交给一个黑盒。
但这里一定要区分两个词:记忆 和 堆积。不是所有内容都值得长期保存。一个能用的知识库,关键不在“多”,而在“干净”。最实用的做法通常是三层结构:会话记忆、工作记忆、长期知识。前两者服务当前任务,后者服务未来复用。
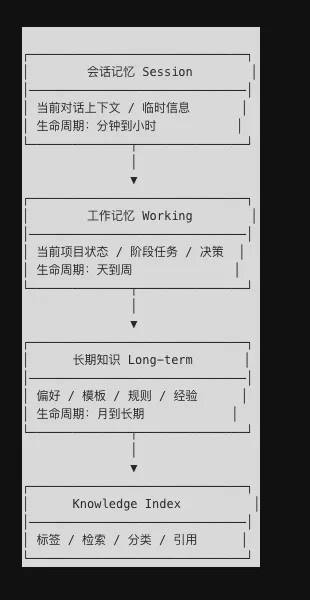
一个很适合 OpenClaw 的知识目录,大致可以这样组织:
knowledge/├── inbox/ # 临时信息,待整理├── working/ # 当前项目工作记忆├── long_term/ # 长期可复用知识│ ├── preferences.md # 用户偏好│ ├── workflows.md # 已验证工作流│ ├── contacts.md # 关键联系人与组织信息│ └── decision_patterns.md # 常用决策规则└── index/ └── tags.json # 检索标签与索引为什么这样分?因为不同信息的保鲜期不一样。比如“用户喜欢什么写作风格”这种,可能半年都有效;“本周项目优先级”这种,很可能下周就变了;而“刚才闲聊时顺口提到的一个想法”,大概率压根不该进长期库。你要的不是全记住,而是记住值得反复用的信息。
这里最容易踩的坑,是把“模型说过的话”直接当成“知识”。更稳妥的做法是:只有已验证、可复用、低噪声的信息,才写入长期记忆。
甚至在系统初期,你都不一定非要上向量数据库。很多个人或小团队场景里,先用 Markdown + 标签索引就已经很好用。原因很现实:它透明、可改、可审计,而且不会让知识库一开始就变成一个“你知道它在那儿,但你也不知道它里面到底是什么”的神秘黑箱。
可以用这样一个非常短的规则控制写入:
defshould_store(item):return item["verified"] and item["reuse_score"] >= 7and item["noise"] <= 3它简单得近乎粗暴,但逻辑是对的:长期记忆不是为了保存一切,而是为了减少未来重复劳动。 当你的 Agent 团队开始真的“记住一些对的东西”时,它才会从一个看起来很聪明的工具,变成一个越来越懂你工作方式的系统。
5 本地 AI 中枢:用 OpenClaw 接管数字工作流,这才是进阶玩法的终点
前面四部分拼起来,最后想实现的其实不是“一个更复杂的 Agent”,而是一个真正能工作的本地 AI 中枢。这听上去有点大词,但本质上很接地气:你用一句自然语言交代目标,它能够理解任务、调用合适的 Agent、调起相应 Skill、读取记忆与知识库,然后把结果产出来,再把经验回写回去。
如果把整个系统看成一家公司,那 OpenClaw Gateway 就像总机房。官方文档写得已经很直白:Gateway 是常驻进程,负责承接消息渠道、控制面和工具调用,一个 Gateway 通常就能服务多个消息渠道和多个 Agent;同时默认建议开启认证,并优先通过更安全的方式接入。 这意味着,OpenClaw 真正适合做的,不是“到处散着连工具”,而是做一个统一入口,再把能力通过编排层按需下发。
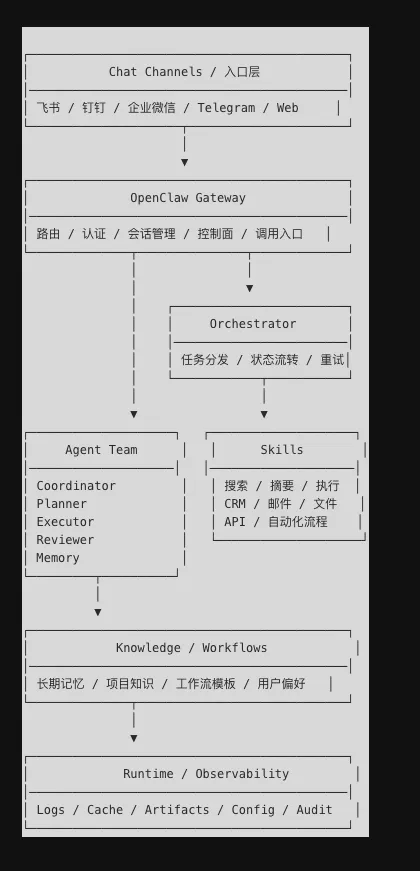
一个比较完整、但仍然克制的项目结构,可以长这样:
openclaw-hub/├── gateway/│ ├── config.yaml # Gateway 主配置│ ├── providers.yaml # 模型提供商配置│ ├── channels.yaml # 飞书、钉钉、企业微信、Telegram 等入口│ └── security.yaml # 认证、白名单、权限隔离├── agents/ # Agent 团队├── orchestrator/ # 任务编排层├── skills/ # Skill 能力层├── knowledge/ # 长期记忆与知识库├── workflows/ # 具体业务流程└── runtime/ ├── logs/ # 日志 ├── cache/ # 缓存 └── artifacts/ # 任务产物这里有个非常重要的现实判断:不是所有工作流都适合先交给智能体。 最值得优先接管的,通常不是最炫的,而是最重复、最结构化、最容易标准化的那些。比如晨间简报、会议纪要整理、客户跟进、周报生成、知识归档,这些都很适合变成 OpenClaw 的第一批流程。
这一步为什么重要?因为它把 OpenClaw、Agent、AI Agent、智能体、LLM 这些听起来很“概念化”的词,真正落到了业务动作上。不是再讨论“Agent 未来会不会颠覆一切”,而是先回答一个更朴素的问题:它今天能不能稳定帮你省下 30 分钟?
你可以把 OpenClaw 理解成一个“本地版 AI 中控台”。它不是替你思考所有问题,而是把那些重复、结构化、容易被规则化的数字劳动,一点点接过去。
当然,越接近“中枢”,就越要对风险有自觉。官方在安全文档里已经说得很明确:没有“完美安全”的 OpenClaw 部署,合理做法是从最小权限开始,随着信心再逐步放开。 这句话不夸张地说,几乎应该贴在每个 OpenClaw 工作区首页。因为一个会调用真实工具的 Agent,一旦接管了文件、消息、接口甚至系统命令,它犯错时带来的后果,就不只是“回答错了”,而是“真的做错了”。
AI Agent 最迷人的地方,是它开始像“同事”;AI Agent 最危险的地方,也正是它开始像“同事”。
结尾
OpenClaw 的进阶玩法,从来不是多接几个模型、多装几个 Skill,而是把 Agent 团队、任务编排、Skill 工具生态、长期记忆和本地 AI 中枢 五件事,拼成一个能长期运转的系统。 它大概率不是下一个“万能神奇入口”,但很可能会成为你数字工作流里,那个越来越像基础设施的东西。 至少现在看,真正有价值的,不是“AI 会不会取代人”,而是“你会不会先让 AI 接住那些本来就该被自动化的事”。

往期精选公众号:Hive硅基秩序
