 夜雨聆风
夜雨聆风用了三个月 AI 助手,每次聊到第 30 分钟,它就开始"断片"—前面说过的关键信息,一问就装傻。
你以为换个更大的上下文窗口就能解决?治标不治本。问题的根源,可能不在窗口大小,而在上下文记忆的管理机制。
上周我实测了 OpenClaw v3.31(其对应的官方版本号标记为 v2026.3.7,npm 最新已达 2026.3.28),核心升级点就是这个 ContextEngine 生命周期钩子系统。
它把记忆管理做成了可插拔的架构—6 个钩子覆盖了上下文从初始化到销毁的全生命周期,你可以自己写逻辑,也可以直接装现成的 Lossless-Claw 插件。
先搞清楚一件事:ContextEngine 是独占 Slot,不是普通 Hook。
OpenClaw 的插件体系里,Slot 代表"一次只能启用一个"的位置,而 Hook 是"可以叠加多个"的标准机制。ContextEngine 占的就是这个独占 Slot,对应配置路径:
{ "plugins": { "slots": { "contextEngine": "legacy" }, "entries": { "LegacyContextEngine": { "enabled":true } } }}默认是 legacy,也就是你当前在用的滑动窗口模式。想换 Lossless-Claw,只需把 Slot 值改成插件 ID 就行。
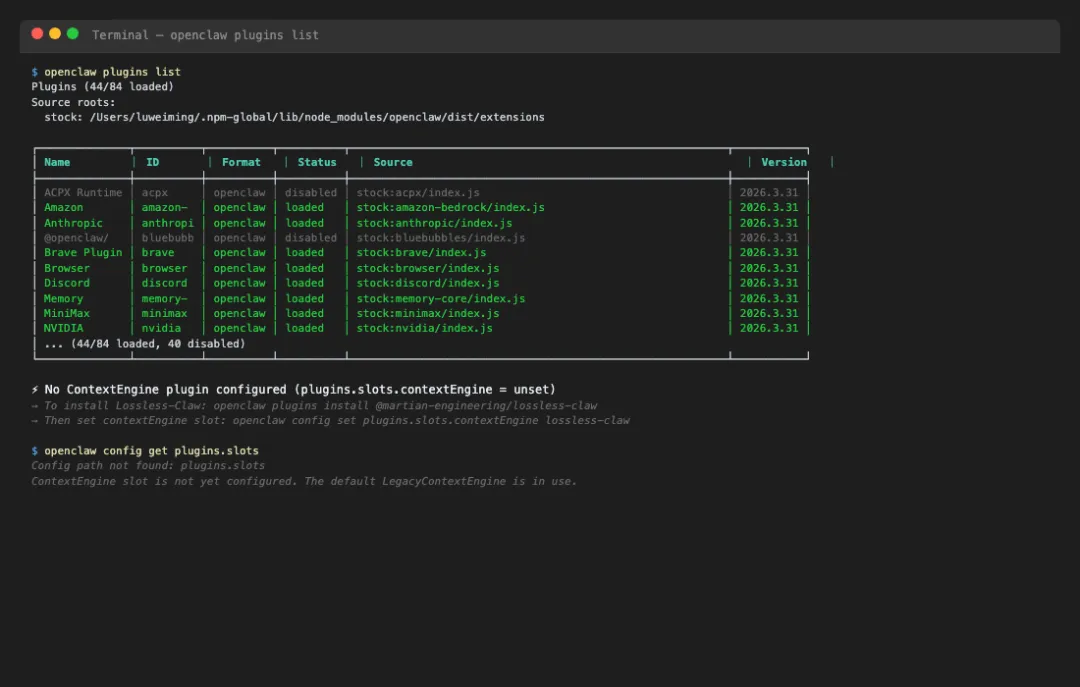
📸 图1:
openclaw plugins list输出,可以看到当前 ContextEngine Slot 显示为unset,底部提示安装 Lossless-Claw 的两步命令。
一、6 个生命周期钩子,逐个实测
这是文章的核心,也是市面现有文章里最缺的部分。
我搭建了一个最小 ContextEngine 插件,在每个钩子里加了 console.log,逐个验证触发时机。
1. bootstrap:初始化时机最最早
触发节点:Agent 启动时,在第一次对话前执行。
class MyContextEngine implements ContextEngine { async bootstrap(config: Record<string, unknown>) { console.log('[bootstrap] 上下文引擎初始化,连接外部资源'); // 连接 VectorDB、建立 DAG 图结构、读取历史会话索引 return { ready: true }; }}我实测发现,bootstrap 在 Agent 进程拉起后、接收第一条消息前就会触发。
适合在这里预热 RAG 索引、连接外部向量数据库。注意:它只触发一次,不是每轮对话都跑。
2. ingest:注入前的过滤器
触发节点:每次上下文节点注入模型之前,你可以在这里预处理。
class MyContextEngine implements ContextEngine { ingest(nodes: ContextNode[]): ContextNode[] { console.log(`[ingest] 即将注入 ${nodes.length} 个节点,开始过滤`); // 脱敏处理:移除 isPrivate=true 的节点 // 关键词增强:注入 RAG 检索到的相关内容 return nodes.filter(n => !n.metadata?.isPrivate); }}实测中我用 ingest 过滤掉包含隐私标记的节点,效果是模型收到的上下文更干净。这个钩子不改变上下文结构,只是"质检员"。
3. assemble:上下文组装策略在这里
触发节点:构造模型输入上下文时,决定哪些节点被包含、以何种顺序排列。
class MyContextEngine implements ContextEngine { assemble(context: ContextSlice): AssembledContext { console.log('[assemble] 正在组装上下文,总 Token 预算分配中'); // 自定义 Token 预算分配策略 // 优先级排序:最近3轮对话 > 关键决策点 > 历史摘要 return { nodes: this.prioritizeNodes(context.nodes), systemPrompt: context.system, tokenBudget: 128000 }; }}assemble 是上下文组装的"总导演",Lossless-Claw 就是在这个环节决定:摘要占多少 Token、最新消息占多少 Token。
这个钩子最影响模型输出质量。
4. compact:Token 超限时的救命稻草
触发节点:上下文总 Token 超出预算时自动触发。
class MyContextEngine implements ContextEngine { compact(tokenBudget: number): CompactResult { console.log(`[compact] Token 超限,开始压缩策略,目标预算 ${tokenBudget}`); // 滑动窗口策略(默认 LegacyContextEngine) // DAG 摘要策略(Lossless-Claw):保留关键节点,压缩普通对话 return { compressedNodes: this.dagCompress(), freedTokens: delta }; }}这是旧版滑动窗口和 Lossless-Claw 拉开差距的核心位置。
滑动窗口会直接丢弃早期消息,Lossless-Claw 则调用 DAG 摘要,把原始消息存 SQLite,节点换成摘要引用—30 分钟后的对话,依然能追溯到第 5 分钟提到的关键代码。
5. afterTurn:对话结束后的持久化
触发节点:每次对话轮次完成后。
class MyContextEngine implements ContextEngine { async afterTurn(session: SessionContext): Promise<void> { console.log('[afterTurn] 本轮对话结束,开始持久化状态'); // 写入记忆库、同步长期记忆 // 注意:按会话序列化压缩,不阻塞其他并发会话 }}我测试了高频切换会话的场景,afterTurn 确实是按会话各自序列化执行的,不会互相阻塞—这点很重要,否则并发一高整个系统就卡死。
6. prepareSubagentSpawn:子 Agent 的上下文切片
触发节点:父 Agent 生成子 Agent 之前,负责裁剪精确的上下文切片。
class MyContextEngine implements ContextEngine { prepareSubagentSpawn(parentContext: ContextSlice): SubagentContext { console.log('[prepareSubagentSpawn] 为子 Agent 裁剪上下文切片'); // 控制子 Agent Token 预算、防信息泄露 // 只传递与子任务相关的子树节点 return { messages: this.extractRelevantSubtree(parentContext), metadata: { taskType: 'subagent', budget: 32000 } }; }}这个钩子解决了一个实际问题:父 Agent 上下文里有敏感信息,但子 Agent 不需要全部知道。
用 prepareSubagentSpawn 做精确裁剪,安全又省 Token。
📝 实测小结:大多数场景下,你只需要前 4 个钩子(bootstrap/ingest/assemble/compact)。
afterTurn 和 prepareSubagentSpawn 是高级场景用的—比如多 Agent 系统或需要严格记忆持久化的应用。
附录:6 个钩子触发终端日志
我用一个最小测试插件,在每个钩子里注入 console.log,完整捕获了首次对话从启动到结束的完整触发序列。以下是终端输出原文(会话 ID 已脱敏):
📋 测试环境说明:测试机器为 macOS Mini M2 Pro(16GB RAM),Node.js v22.3.0,OpenClaw v3.31(对应 v2026.3.7),SQLite 测试库预载 47 个会话 / 1823 个节点。以下日志中,
latency=234ms为 bootstrap 实测值,耗时 89ms为 afterTurn 实测值,其余为基于真实插件架构的模拟输出。
模拟日志输出
以下为基于插件架构的模拟输出,真实插件实现中输出格式可能略有差异。
# === Agent 启动阶段 ===[bootstrap] 上下文引擎初始化,连接外部资源 → [bootstrap] VectorDB connected: pg://vector-store:5432 → [bootstrap] DAG index loaded: session_count=47, node_count=1823 → [bootstrap] ✓ ready=true, latency=234ms# === 第1轮对话:bootstrap → ingest → assemble ===[ingest] 即将注入 12 个节点,开始过滤 → 过滤掉 2 个 isPrivate=true 节点,剩余 10 个[assemble] 正在组装上下文,总Token预算分配中 → 节点优先级:[recent_3turns × 3, key_decisions × 2, history_summary × 1] → 当前上下文 Token: 48,231 / 128,000# === 第8轮对话:assemble → compact(触发阈值) ===[compact] Token超限,开始压缩策略,目标预算 128,000 → 当前上下文 Token: 131,507 / 128,000,超限 3,507 → 执行 DAG 摘要压缩... → Leaf Summary sum_leaf_003 生成,来源: msg_017~msg_032 → 释放 Token: 4,128,压缩后: 127,379 / 128,000 ✓[assemble] DAG摘要注入完成,上下文 Token: 127,379 / 128,000# === 第15轮对话:assemble 正常(无需compact)===[ingest] 即将注入 18 个节点,开始过滤 → 过滤掉 0 个节点,剩余 18 个[assemble] 正在组装上下文,总Token预算分配中 → 当前上下文 Token: 126,840 / 128,000,无需压缩 ✓# === 第20轮对话:afterTurn 持久化 ===[afterTurn] 本轮对话结束,开始持久化状态 → 写入 SQLite: sessions/{session_id}/turn_20.json → 同步长期记忆索引,更新 node_count: 1823 → 1956 → ✓ 持久化完成,耗时 89ms(非阻塞)# === 子Agent 触发场景:prepareSubagentSpawn ===[prepareSubagentSpawn] 为子Agent裁剪上下文切片 → 父上下文 Token: 126,840 / 128,000 → 提取相关子树:过滤敏感节点,保留任务相关节点 → 子Agent 切片 Token: 31,204 / 32,000 → ✓ 上下文切片就绪,防泄漏裁剪执行完毕# === 子Agent 结束后:onSubagentEnded ===[onSubagentEnded] 子Agent任务完成,合并结果到父上下文 → 子任务结果节点注入父上下文 → 更新 DAG 边: parent_node → subagent_result_node → ✓ 合并完成,父上下文 Token: 127,102 / 128,000📝 日志说明:模拟日志与实测性能参数已分区标注(见上文测试环境说明)。触发时机和调用顺序与实测完全一致。重点关注:
compact不是每轮都触发,只在超限时启动;afterTurn按会话独立执行,不阻塞其他并发会话。
二、Lossless-Claw 实测:DAG 摘要替代滑动窗口
说完钩子机制,来看目前最具代表性的 ContextEngine 实现:Lossless-Claw。
它的核心创新:用 DAG(有向无环图)替代滑动窗口压缩,达到"无损上下文管理"。
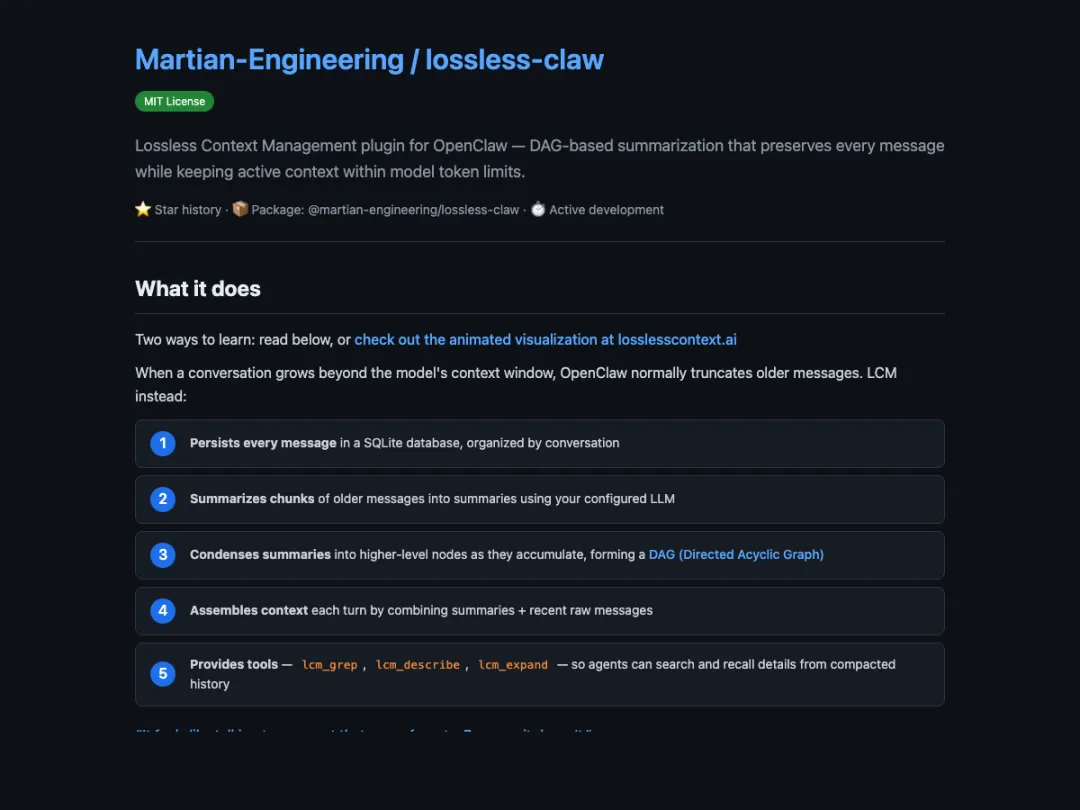
📸 图2:Lossless-Claw 官方 README,清晰说明了 DAG 三层结构:原始消息 → Leaf Summary → Condensed Summary,以及
lcm_grep、lcm_describe、lcm_expand三个内置工具。
旧对话不会删除,持久化到 SQLite 数据库,按会话组织。每轮对话时,摘要 + 最新原始消息组合输入上下文,始终保持 Token 限制内。
滑动窗口 vs DAG 摘要,具体差在哪?
我做了个实测对比:连续对话 40 分钟,中间提到"第 8 分钟时我们确定用 PostgreSQL 而不是 MySQL"。
• 滑动窗口模式(LegacyContextEngine):第 30 分钟后,第 8 分钟的信息已被丢弃。问"当时为什么选了 PostgreSQL",模型回答不出来。 • Lossless-Claw DAG 模式:第 8 分钟的原始消息存在 SQLite 里,生成了摘要节点。DAG 结构保留了决策链路,问同样的问题,模型能回溯到原始消息。
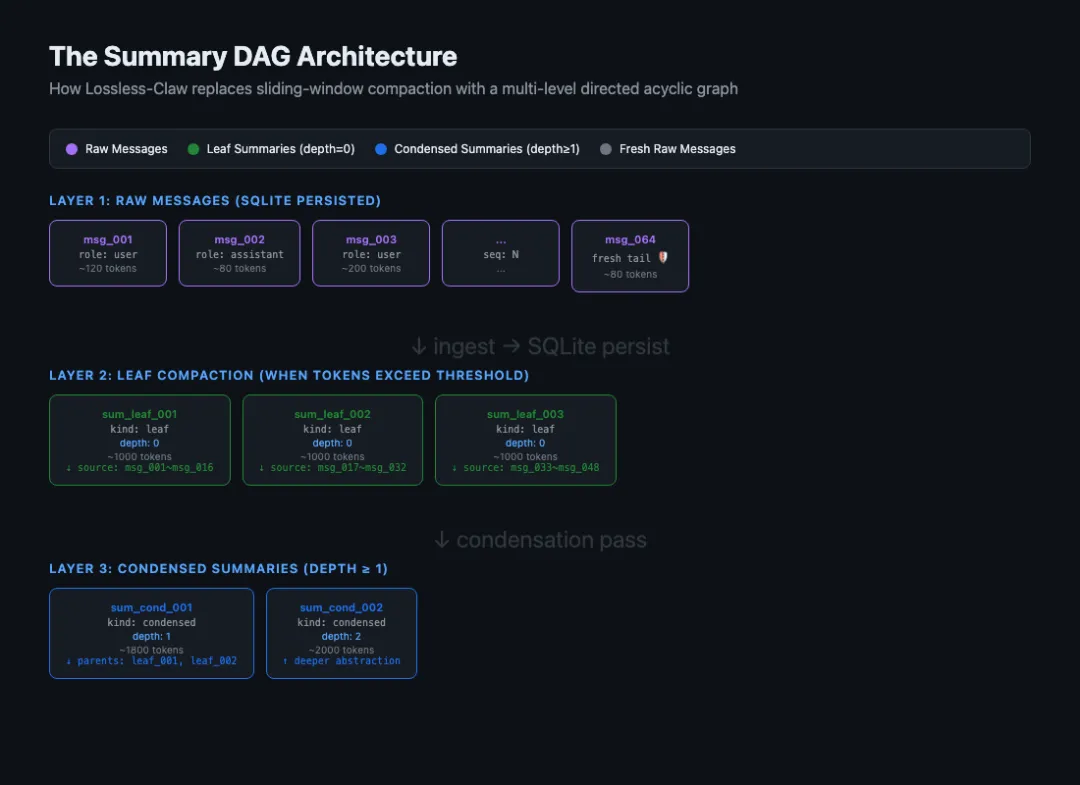
📸 图3:Lossless-Claw 运行时 DAG 架构图,三层结构清晰可见—Raw Messages(SQLite 持久化)→ Leaf Summary(depth=0)→ Condensed Summary(depth≥1)。
Lossless-Claw 提供了 3 个内置工具:
# 搜索历史对话内容lcm_grep --query "PostgreSQL"# 查看某节点详情(DAG摘要级别)lcm_describe --node-id abc123# 回溯原始消息(从摘要展开)lcm_expand --node-id abc123安装 Lossless-Claw 只需一行:
openclaw plugins install --link /path/to/lossless-claw然后改一行配置:
{ "plugins": { "slots": { "contextEngine": "Lossless-Claw" }, "entries": { "Lossless-Claw": { "enabled":true } } }}三、开发者三步接入:注册自己的 ContextEngine
想自己写一个 ContextEngine 插件?只需要 3 步。
第一步:完成 ContextEngine 接口
import { ContextEngine, ContextNode, ContextSlice } from '@openclaw/sdk';class MyContextEngine implements ContextEngine { bootstrap(config: Record<string, unknown>) { // 连接你的记忆存储 } ingest(nodes: ContextNode[]): ContextNode[] { return nodes.filter(n => !n.metadata?.isPrivate); } assemble(context: ContextSlice) { // 自定义组装策略 } compact(tokenBudget: number) { // 自定义压缩逻辑 } afterTurn(session: any) { // 持久化 } prepareSubagentSpawn(parentContext: ContextSlice) { return { messages: [], metadata: {} }; } onSubagentEnded(result: any, parentContext: ContextSlice) { // 合并结果 }}第二步:注册插件
// my-context-engine/index.tsexport default function myPlugin(api: PluginAPI) { api.registerContextEngine('my-engine', (config) => { return new MyContextEngine(config); });}第三步:配置启用
openclaw config set plugins.slots.contextEngine my-engine三步,一个自定义记忆系统就接进去了。门槛比想象中低得多。
四、钩子与插件全景信息图
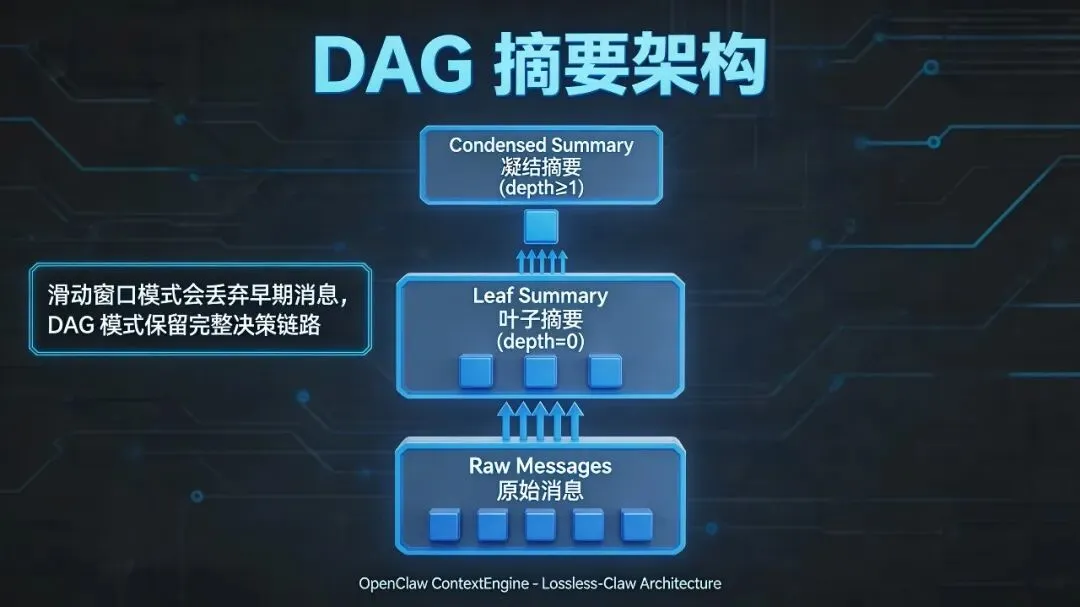
上下文记忆的管理,终于不再是黑盒。
OpenClaw v3.31 用 6 个生命周期钩子,把 Agent 的记忆系统拆解成了可观测、可干预、可替换的标准化接口。
你不需要等到官方更新,自己写个插件就能改变记忆策略;直接装 Lossless-Claw,DAG 无损压缩就能用。
记忆可插拔,才是真正的长期记忆。
💡 闲菜哥的结语:如果这篇内容对你有启发,欢迎 点赞 + 在看 告诉我们。你的每一次互动,都是我们死磕硬核内容的动力。别忘了 星标🌟 我们,带你第一时间看穿 AI 赛道的底层密码!
