 夜雨聆风
夜雨聆风大家好,我是青澈君,一个喜欢捣鼓openclaw的80后,顺便学学Vibe Coding,也在坚持写日记。
之前写过两篇关于 OpenClaw 记忆系统的文章,一篇讲三层文件结构怎么配,一篇讲记忆文件怎么瘦身。配完能用,瘦完能跑,但有个问题我一直没展开说:
助理是怎么"想起来"的?
你在 memory/ 下存了十几个文件,助理收到一个问题,它怎么知道该翻哪个文件、哪一段?你跟它聊了两个小时,上下文快撑满了,它怎么处理之前的对话内容?
这两个问题,对应的是 OpenClaw 里两套完全不同的系统。搞清楚它们各自干什么、怎么配合,是理解整个记忆机制的关键。
正好最近 OpenClaw 4.1 在记忆这块做了不少升级,我把底层逻辑和新功能一起拆一遍。
一、先分清两套系统:笔记本和录音笔
很多人以为 OpenClaw 的"记忆"是一套东西。其实是两套,解决的是完全不同的问题。
Memory 系统,管"知识文件"。 它负责的是 MEMORY.md 和 memory/ 下的所有 Markdown 文件。这些文件里存的是结论性的信息:你的名字、你的规矩、项目当前状态、历史踩坑经验。每次开新会话,MEMORY.md 自动注入;memory/ 下的文件通过搜索按需召回。
LCM,管"对话历史"。 它负责的是你当前这轮对话本身。你跟助理聊了两个小时,上下文快撑满了,LCM 把早期对话压缩成摘要,腾出空间让你继续聊。原始对话不删除,存成压缩树,需要时可以展开还原。
打个比方:Memory 是笔记本,LCM 是录音笔。 笔记本记结论——"上次 cron 时区搞错,解决方案是在配置里显式指定 Asia/Shanghai"。录音笔存过程——你和助理来回讨论了 40 分钟怎么排查这个问题的完整对话。
两套系统各管各的,但设计上是配套的。后面会讲它们怎么配合,先分别拆开看。
二、Memory 系统:怎么存、怎么找
Memory 系统分两个部分:存储和检索。
存储很简单,就是文件。
MEMORY.md 是长期记忆索引,每次开新会话自动注入,上限 2KB。memory/ 下是主题文件,按需搜索召回,每个文件 3KB 上限。存什么、怎么控制大小,之前两篇文章讲过,不重复了。
检索是重点,靠的是 embedding。
embedding 这个词听起来很技术,其实做的事很直觉:把一段文字转换成一组数字,这组数字代表这段文字的"意思"。
打个比方。你家书架上有 100 本书,你想找"上次那本讲团队管理踩坑的"。如果书架按书名首字母排,你得挨个看标题来判断内容。但如果有人把每本书按"主题"和"类型"标了坐标——横轴是技术到管理,纵轴是理论到实践——你只要找"管理 + 实践"那个象限,三秒就定位到了。
embedding 做的就是这个"标坐标"的事。只不过坐标不是两个维度,而是几百上千个维度。
实际跑起来是这样的:
你往 memory/ 里写了一个文件,比如记录了"上次 cron 配置时区搞错,凌晨的推送跑到了中午" OpenClaw 把这段文字切成小片段(大约 400 tokens 一块),发给 embedding 模型(我用的是 Google 的 gemini-embedding-001),模型给每个片段返回一组 768 个数字 这组数字存进本地的 SQLite 向量数据库 下次你问助理"之前定时任务出过什么问题",这句话也会被转成一组 768 个数字 系统在向量库里算距离,找到"意思最接近"的几个片段,返回给助理
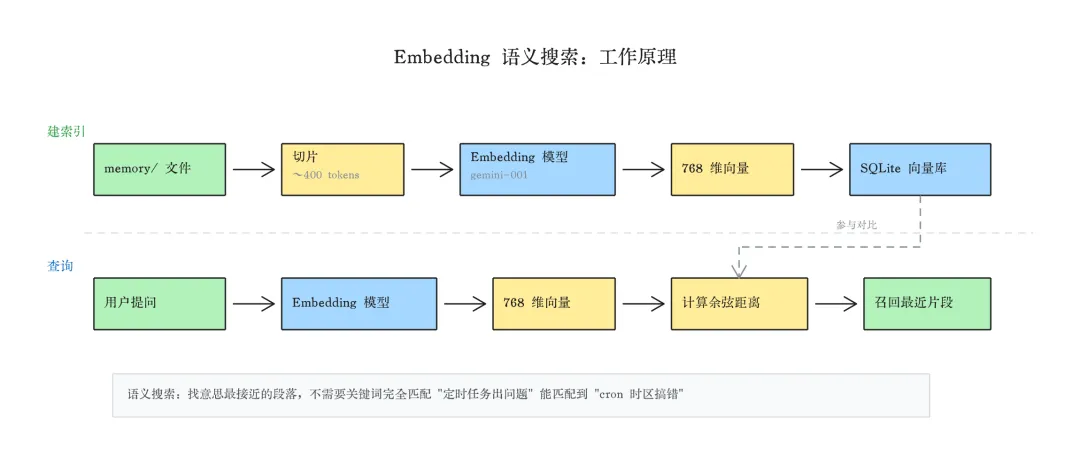
关键点:它找的不是"包含相同关键词的段落",是"意思最接近的段落"。 你说"定时任务出问题",它能匹配到"cron 时区搞错",虽然两句话没一个词重复。这就是语义搜索和关键词搜索的根本区别。
我今天刚踩了一个 embedding 的坑。Google AI 的 API 有免费配额限制,每天 1000 次请求。我的 memory 文件加起来 154 个,全量重建索引一次就要几百次请求。之前用的项目配额用光了,新建了一个 Google Cloud 项目,启用了 Generative Language API,绑了结算账号,结果发现配额升级不是即时生效的,得等几个小时。
教训是:embedding 不是免费的无限资源,建索引有成本,规划好重建频率。
三、LCM:对话太长了怎么办
Memory 系统管的是跨会话的"知识",LCM 管的是当前这次对话本身。
大语言模型有上下文窗口限制。Claude 的窗口是 200K tokens,听起来很大,但你跟助理聊两三个小时,中间涉及文件读写、代码执行、工具调用,上下文很容易就逼近上限。
没有 LCM 的时候,OpenClaw 的做法是粗暴截断——窗口快满了,把最早的对话直接扔掉。信息丢失不说,助理可能突然"忘了"你两小时前说的一个关键决策。
LCM 的做法是压缩而不是截断。具体机制:
系统监控当前对话的 token 消耗 接近阈值时,把早期的对话内容交给模型做摘要 摘要替换掉原始对话,占用的 token 量大幅减少 原始对话不删除,存成压缩树(DAG 结构),需要时可以逐层展开还原
打个比方:你的工位只有一张桌子,放不下所有文件。LCM 做的不是把旧文件扔进垃圾桶,而是把它们装订成摘要放进抽屉,桌面只留最近在用的。抽屉里的东西随时能拿出来翻。
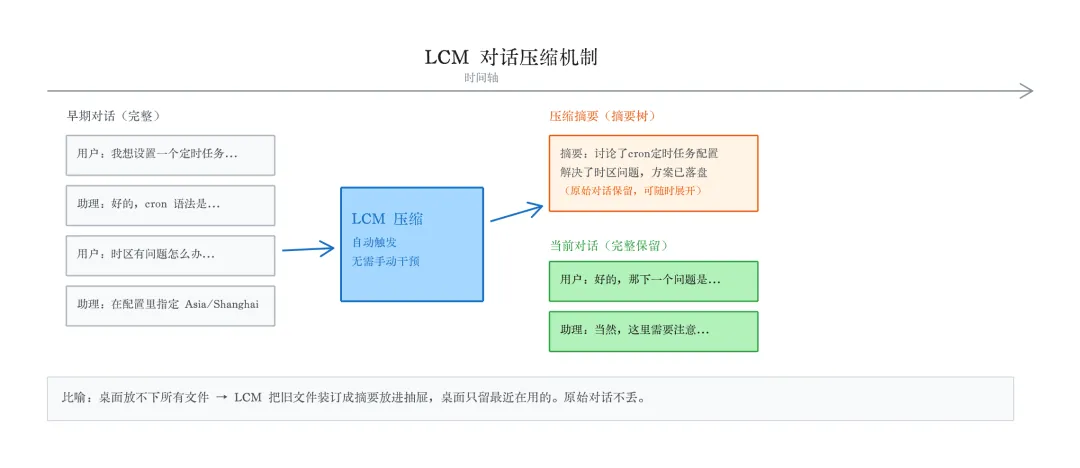
实际使用中,LCM 的压缩是你完全无感的。你不会收到"正在压缩上下文"的提示,也不需要手动触发。聊到一定长度,系统自动处理。你能感知到的区别就是:以前聊久了助理开始犯迷糊,现在不会了。
回到"笔记本和录音笔"的比喻:Memory 记的是你主动整理过的结论,LCM 存的是完整的对话过程。 你问"上次那个 cron 为什么改成 sonnet?",答案在对话过程里,LCM 能找到。你问"MindLM 项目现在什么状态?",答案在知识文件里,Memory 系统负责。
两个都要有,缺一个都不完整。
四、4.1 做了什么:两套系统都升级了
OpenClaw 4.1 对两套系统都做了升级,我按系统拆开说。
Memory 系统的升级:搜索从"能用"到"准"
第一个,混合搜索。之前 memory_search 只走向量搜索这一条路。但纯语义搜索有盲区:你想找一个具体的错误码 "ERR_QUOTA_EXCEEDED",语义搜索找到一堆跟"配额"相关的段落,但不一定精准命中这个错误码。
4.1 加了第二条路:BM25 关键词搜索。两条路同时跑,结果加权合并。语义理解和精确匹配互补,不需要额外配置,配了 embedding 模型就自动启用。
第二个,时间衰减。跑助理跑几个月,memory/ 里攒了上百条日记,搜索经常碰到旧笔记抢排名的问题。4.1 加了时间衰减,默认半衰期 30 天——一个月前的笔记权重降到 50%,两个月前降到 25%。MEMORY.md 这种常驻文件不受影响。
第三个,MMR 去重。以前搜索返回的 5 条结果里可能有 3 条说的是同一件事。4.1 的 MMR 机制自动去重,保证结果覆盖不同主题。
第四个,多模态记忆。如果你用 Gemini 做 embedding 模型,memory/ 下的图片和音频也能被索引。用文字搜索,能匹配到图片内容。比如你存了一张报错截图,下次遇到类似报错能直接召回。
LCM 的升级:压缩更安全
第一个,压缩前自动落盘。以前 LCM 压缩是直接开始的,对话里有重要信息还没存到 memory 文件,压缩成摘要后细节可能丢失。4.1 在压缩前加了一个静默步骤:先提醒助理把重要内容写入 memory 文件,写完再压缩。
这一步是把两套系统串起来的关键——LCM 压缩前,主动往 Memory 系统里"备份"重要信息。录音笔整理之前,先把关键结论抄到笔记本上。
第二个,压缩模型可配置。默认用主模型做压缩摘要,现在可以指定更强的模型。比如日常对话用 Sonnet,压缩摘要用 Opus,保证摘要质量。
两套系统之间的桥梁:会话记忆索引
4.1 还做了一件事,把两套系统的边界打通了一点:session memory search。
之前 memory_search 只能搜 memory/ 下的文件(笔记本),搜不到历史对话(录音笔)。开启会话记忆索引后,过去的对话记录也会被 embedding 索引,memory_search 能从历史对话里找到信息。
这是实验性功能,需要手动开启。但方向很清楚——让"记过什么结论"和"聊过什么内容"都能被搜到,记忆的边界不再局限于你手动存下来的文件。
五、两套系统怎么配合:走一遍完整场景
用一个实际场景把完整链条串一遍。
我今天下午跟助理聊了两个小时,讨论一个项目方案,中间做了三个关键决策。
对话进行中,LCM 在后台管上下文。前半小时的闲聊和试错已经被压缩成摘要,但三个关键决策因为时间较近,还在完整保留区。我继续聊,完全感知不到压缩在发生。
对话快结束时,上下文再次逼近阈值,LCM 准备做新一轮压缩。压缩前,4.1 的自动落盘机制先跑了一步:助理把三个关键决策写进了 memory/ 下的主题文件。录音笔里的重要内容,先抄进了笔记本。写完之后,压缩才开始。就算摘要丢了某些细节,完整版已经安全落盘了。
落盘的同时,Memory 系统的索引在后台更新。新写入的决策内容被切成片段、转成向量、存进 SQLite。1.5 秒后索引就绑好了,随时可以被搜到。
第二天开新会话,助理先读 MEMORY.md,拿到核心上下文和文件索引。我问"昨天那个方案最后定的什么?",助理触发 memory_search。混合搜索同时跑两条路:向量路径通过语义匹配找到"项目方案决策"相关的段落,BM25 路径通过关键词匹配找到包含项目名的精确条目。两组结果加权合并,时间衰减让昨天的笔记排在三个月前类似话题的旧笔记前面,MMR 保证返回的三条结果覆盖三个不同的决策点而不是同一个决策的三种表述。
助理拿到召回结果,完整回顾了三个决策。
如果开启了会话记忆索引,还有一层兜底:即使昨天的对话中有些讨论细节没来得及落盘,对话原文本身也被索引了,memory_search 也能从历史对话记录里找到。笔记本里没记到的,录音笔里也能翻出来。
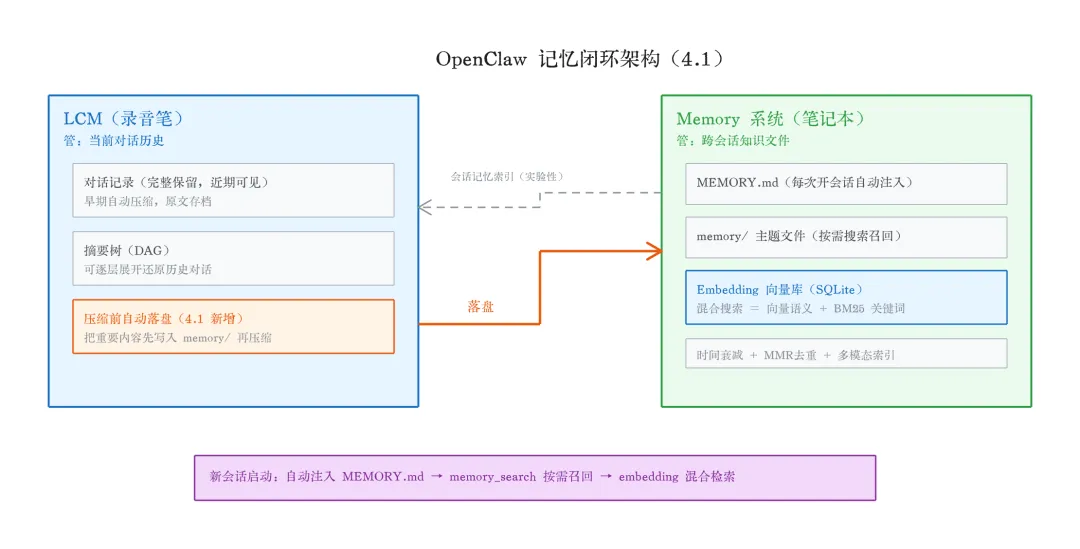
这就是 4.1 之后完整的记忆闭环:
- LCM
(录音笔)保证当前对话不丢信息,压缩前自动往 Memory 系统落盘 - Memory 系统
(笔记本)通过 embedding 混合搜索让历史知识能被精准找到 - 会话记忆索引
打通了两套系统的边界,对话和文件都能被搜到 - 落盘规则
防止冗余:对话细节 LCM 已经存了不重复写,只记跨会话的长期价值信息
记忆系统不是装完就不管了的东西。文件要控制大小,索引要定期维护,落盘要有规矩。但底层逻辑就两句话:笔记本记结论,录音笔存过程。embedding 让笔记本能被翻到,LCM 让录音笔不会爆。
4.1 让这套系统从"各管各的"变成了"配套联动"。混合搜索让检索更准,压缩前落盘让两套系统有了交汇点,会话记忆索引让搜索边界不再割裂。如果你之前配过记忆系统但觉得效果一般,升级到 4.1 之后值得重新试一下。
你的助理现在能"想起来"上周的事吗?如果不能,大概率不是它记性差,是检索这一环没通。
我拉了一个 OpenClaw 粉丝群,只收真正在用的人。加我微信备注「龙虾」,验证后你进来。欢迎一起踩坑、一起抄作业。

