 夜雨聆风
夜雨聆风我用 OpenClaw 打造了真正的第二大脑,连父母都夸智能!
核心提示:这不是另一个笔记软件,而是一个真正懂你的 AI 助手
一个让我无言以对的问题
2026 年春节,豆包做了很多广告,我父母也跑来问我:"这个豆包是啥?有什么用?"
我就在他们手机上都安装了豆包,教他们:"有什么问题就用语音发过去,豆包就能回答。"
他们用得还挺不亦乐乎的。
过了一段时间我回老家,无意中看到他们在问豆包:"能不能把我春节时拍的照片找给我?"
豆包"啪啪啪啪"地给他们一段回答,但是,并不是他们想要的。
然后他们说:"也不行呀,我明明拍了那么多照片,我问豆包,它为什么不能给我找到呢?也不是很智能嘛。"
我一时还没有想好怎么回答他们。

这个问题,其实所有人都有
其实我自己日常生活中也有这样的问题。
有的时候,一些拍的照片、一些想法、过去做的一些文案,或者是某个会议上提到的一些文稿、PPT,想用 AI 帮我去找,结果可想而知。
AI 回答一些问题,现在已经做得很好了。但是想用 AI 做到把你工作和生活中方方面面的点点滴滴的东西都能够找出来,确实还没有实现。
这个问题可能是所有人都碰到过的。
这几年的 AI 火热,有 ChatGPT、Gemini、Cloud,或者是元宝、豆包还是千问,很多人玩得不亦乐乎。但是想让它做一个最基本的事情,比如说"把上个星期我跟王总聊的一个产品文档找出来分析一下",很难。
我们现在的人工智能,还是需要人工。我们需要自己手工把这些文件找出来,然后再发给这些 AI 工具,AI 工具可以帮我们处理,没问题。但是如何把它们找出来,还是需要我们自己去做。

我相信很多人,数据都是分散的:手机上有、电脑上有、QQ 里有、微信里有、邮件里有,还有很多是散落的——拍的照片、随手写的文字、手写的笔记,也可能是电子版的。这些零零散散全是信息,想让 AI 把这些数据有效地整理起来、管理起来,挺难的。
我的探索之路
AI+NAS 的尝试
去年我在公司主导的一个产品,用一句话来描述,就是"有 NAS 功能的 AI 终端产品"。
NAS 就是网络附加存储的意思,它起到的是数据中心的作用——个人或者小团队的数据中心。我们通过手机、电脑上传或者数据同步,把这些数据都自动同步到 NAS 里面。
NAS 存储了我们这些数据之后,传统的模式只是把它们保存一下,有可能会做一些简单的图片整理,比如人脸识别、按时间地点做一些简单的分类。
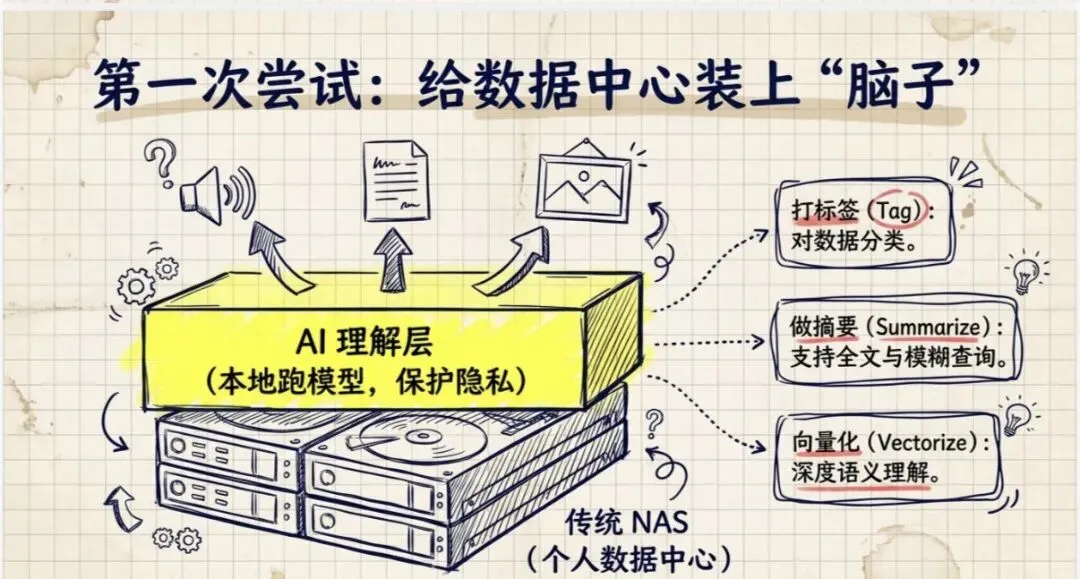
但是我们想的是:使用一个能够跑在本地的 AI 模型,把用户所有的数据都整理一遍。整理出哪些东西呢?简单来说,就是:
- •打标签:对数据进行分类
- •做摘要:根据摘要信息做快速检索,支持全文检索、模糊查询
- •向量化:用于语义理解
当然这些文件本身还有一些元数据,从元数据里面我们可以提取更多的信息,包括文件本身的内容。基于这些信息,所有的文件都可以被 AI 整理过。
我们把这一层叫做**"AI 理解层"**。在传统 NAS 的基础上增加了一层 AI 理解层,并且是本地 AI 模型运行的,所以数据安全和隐私不需要担心。
理解、整理你的所有数据之后,有了这个基础,就可以提供我们之前想要的检索查询,甚至在检索查询的基础上做分析、做输出。
这个整体的思路是非常清晰的:
- 1.数据集中存储:存储在个人的 NAS 上
- 2.本地 AI 模型:打标签、做摘要、向量化
- 3.AI 理解:相当于用 AI 理解过所有数据
- 4.自然语言混合检索:支持文字、图片、语音等多模态检索
- 5.检索准确度:至少达到 85% 以上
- 6.理解解读:把文件和数据串联在一起
- 7.输出结果:通过文字、语音方式输出想要的结果
- 8.应用场景:基于文件做 PPT、分享给其他人
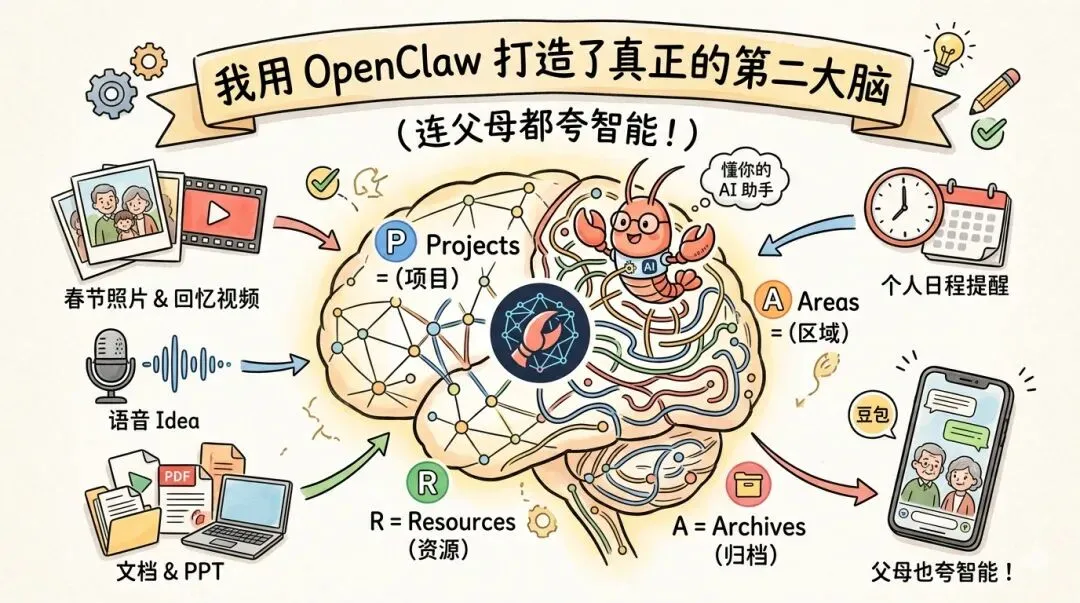
这就好比有了一个**"第二大脑"**。
这个东西就是我们一直想要做的,这个就是我一直想要做的第二大脑。
技术挑战
这个虽然说起来容易,但是做起来其实困难重重。
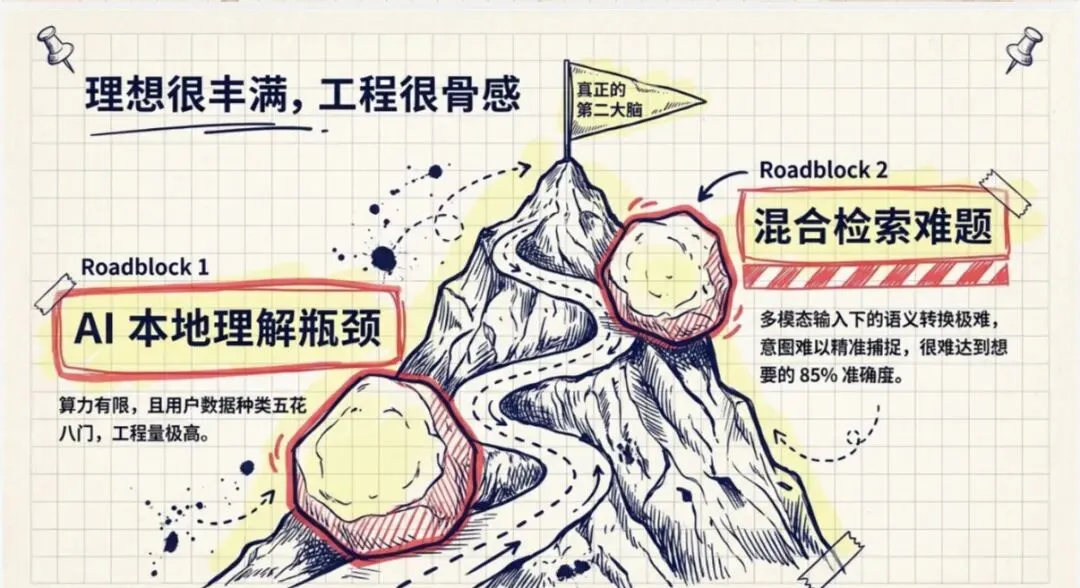
挑战一:AI 理解
对于任意文件和数据做本地模型的 AI 理解,并不是一件很容易的事。
为什么不容易呢?那是因为:
- • 本地模型的处理能力有限
- • 用户的数据五花八门,种类特别多
- • 想要非常准确地将它们整理好,工程化工作量不小
挑战二:检索
检索这里又涉及到很多工程化的东西:
- • 多模态输入:文字、语音、图片
- • 需要精确转换
- • 准确的语义和意图理解
- • 与上下文、历史记忆相关联
- • 准确理解用户意图
- • 基于意图理解做混合检索
这块工程化的难度也是挺大的。我们花了不少时间和人力,但一直没有做到心里想要的那个标准。
遇见 OpenClaw
过完年之后,互联网上 OpenClaw 突然火热了起来。
我自己也是一个从事 AI 开发和应用多年的老兵,也是第一时间做了深度的应用。我在云服务器上面——比如说阿里云、腾讯云、火山引擎都部署了;自己家里的电脑、小服务器,甚至在一台树莓派(Raspberry Pi)上也部署了一台 OpenClaw。
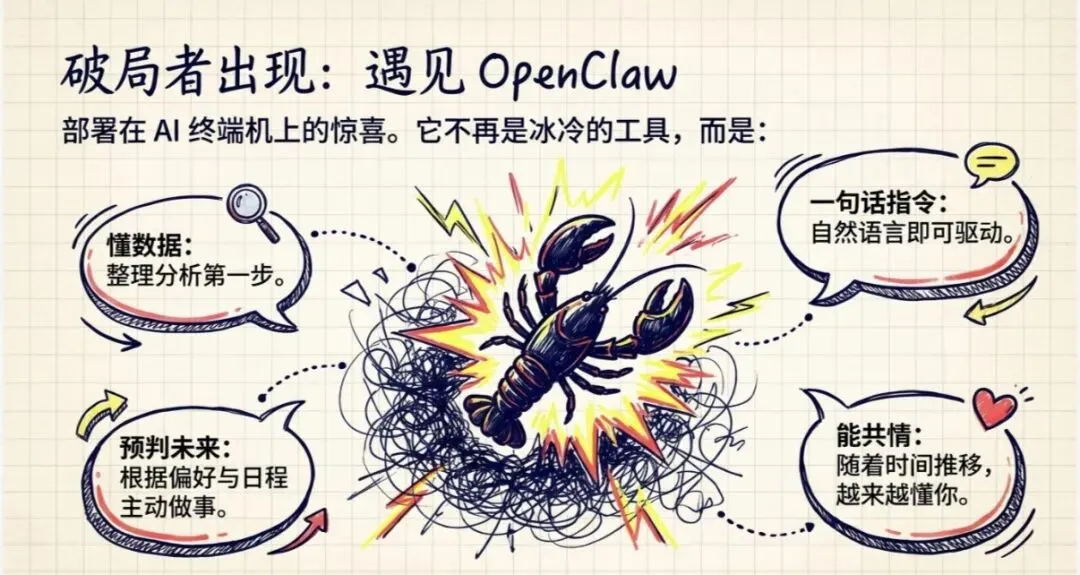
但是让我感受最深的,还是在我们去年那台有 NAS 功能的 AI 终端机上面部署了。我突然发现,这个东西也许就是我们一直想要做的那个:
- • 能够理解你所有数据的
- • 并且知道你个人偏好的
- • 随着时间的增长越来越懂你的
一个 AI 助手。
就是我们去年说的:
- 1.懂数据:懂数据是第一步
- 2.一句话:一句话说一句话让它执行一些指令
- 3.未来事:可以根据你的偏好、你的日程提醒,主动给你做一些什么事
- 4.能共情:因为它越来越懂你
你可以调教它,最后变成你个人非常个性化的一个 AI 助手。
尤其是在解决"理解用户的需求、找到相关的数据和文件"的能力,这个需求是可以满足的。我自己也做了这方面的尝试,感觉非常好。
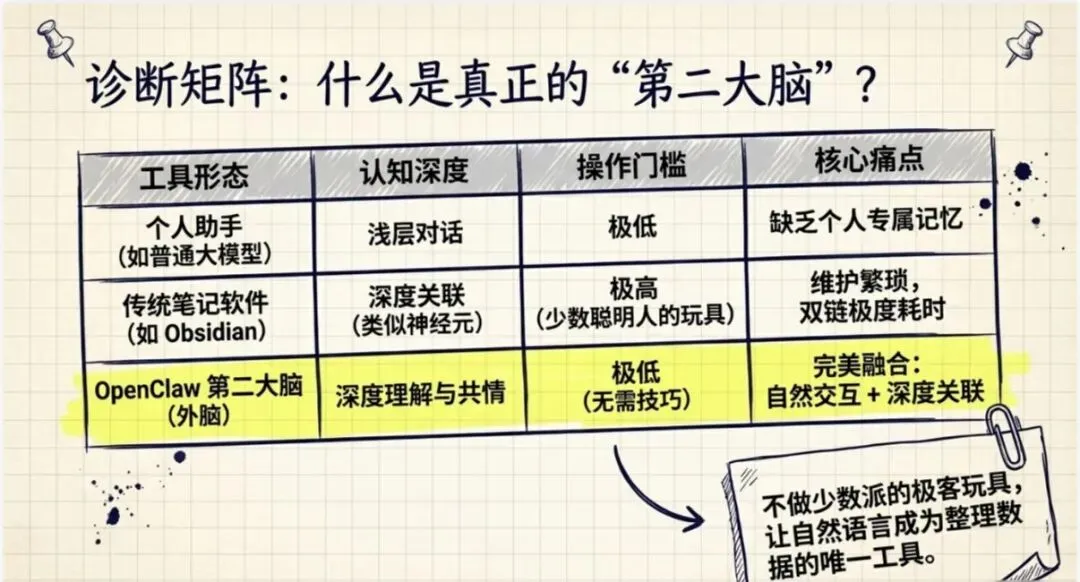
第二大脑 vs 个人助手
我这里之所以说它是"第二大脑",没有说是"个人助手",那其实是又深入了一层。
因为个人助手的话,它有可能在理解你的基础上没有第二大脑更为深入。就像那个仙侠修仙的一些武侠小说里一样的,对吧?有第二元婴,它其实就是你自己,是你的外脑。
说实话呢,我在没有用 AI 之前啊,也用了比如说像印象笔记、Notion 或者是 Obsidian 这些笔记类的软件,它们也是宣称可以作为你的第二大脑。尤其是 Obsidian,它的双向链接啊、反向链接这种方式啊,相当于是把零碎的东西通过链接的方式连接起来,非常像这个大脑神经元。
但是呢,使用起来还是非常非常麻烦。所以说这些工具也都挺小众的,也就是一群——一小撮人吧,自以为聪明的一小撮人在用。
但是这一次有了 AI 大语言模型,这个"龙虾"OpenClaw,哎,你不需要有什么技能,你也可以做到。
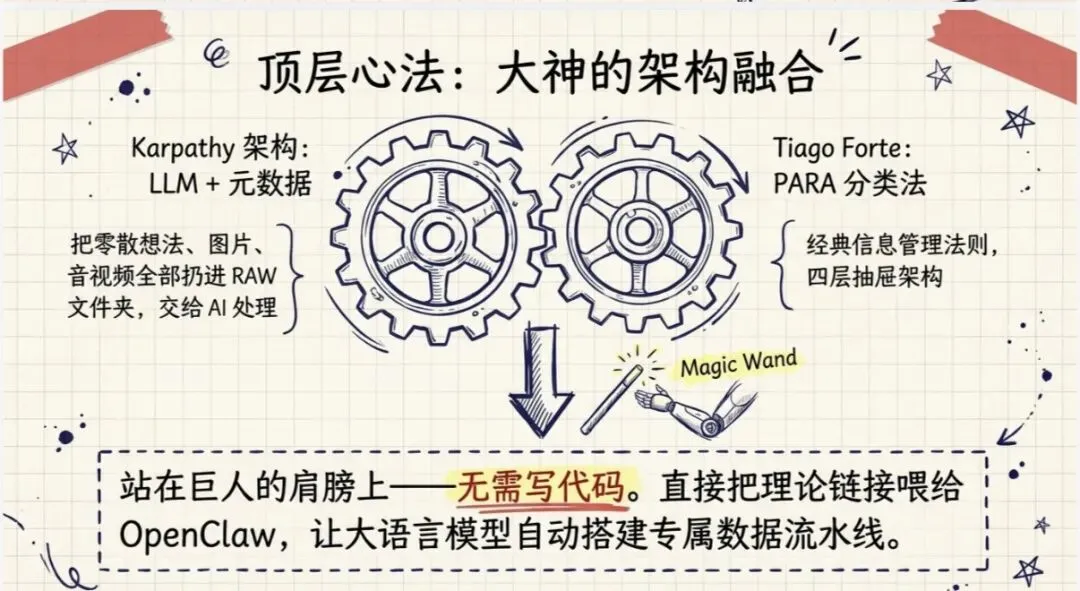
方法论:LLM + 元数据 + PARA
首先呢,我是看到了卡帕西大神——就是前 OpenAI,还有在很多知名 AI 公司做过主开发的这么一个人,叫卡帕西(Andrej Karpathy)。
他就说用这个LLM + 元数据,他把各种数据啊,包括图片呀、音视频呀、文档呀、链接呀、自己的一些想法呀,都扔给大语言模型啊,扔给他的这个 OpenClaw。
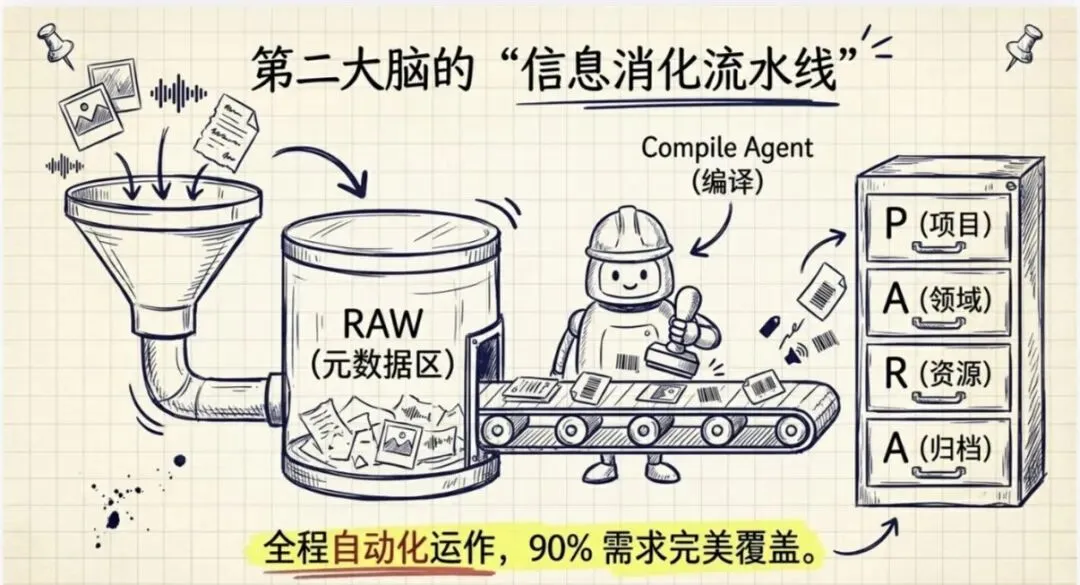
然后 OpenClaw 呢会把它们存到一个叫RAW这样的一个文件夹里,就是元数据文件夹。
然后这个文件夹呢,就会由一个专门做数据处理的 Agent 去做处理,他的意思叫编译(Compile)。
然后编译之后啊,自己会生成相关的索引和向量,然后他就可以进行自然语言检索,然后检索出来之后再做一些二次加工啊,非常方便。
第二个呢,就是有一个非常出名的第二大脑的架构,叫做PARA:
- •P= Projects(项目)
- •A= Areas(区域)
- •R= Resources(资源)
- •A= Archives(归档)
通过四层的这个处理,跟那个卡帕西的差不多啊。这个呢会形成你的数据的整理。
我把这两个合并在一起啊,一起用了一下。
当然我没有编程啊,我就把这两套理论的相关链接都发给我的龙虾机器人,然后告诉我的龙虾,也就是 OpenClaw,我说我要搭建这个第二大脑,要实现什么什么样的功能,我有什么什么需求都告诉它。
然后我实际使用了一个月,我发现真的是非常非常方便。基本上能够满足我大部分的需求啊,不能说百分之百吧,90% 也是没有问题的。
实际案例:真的很好用!
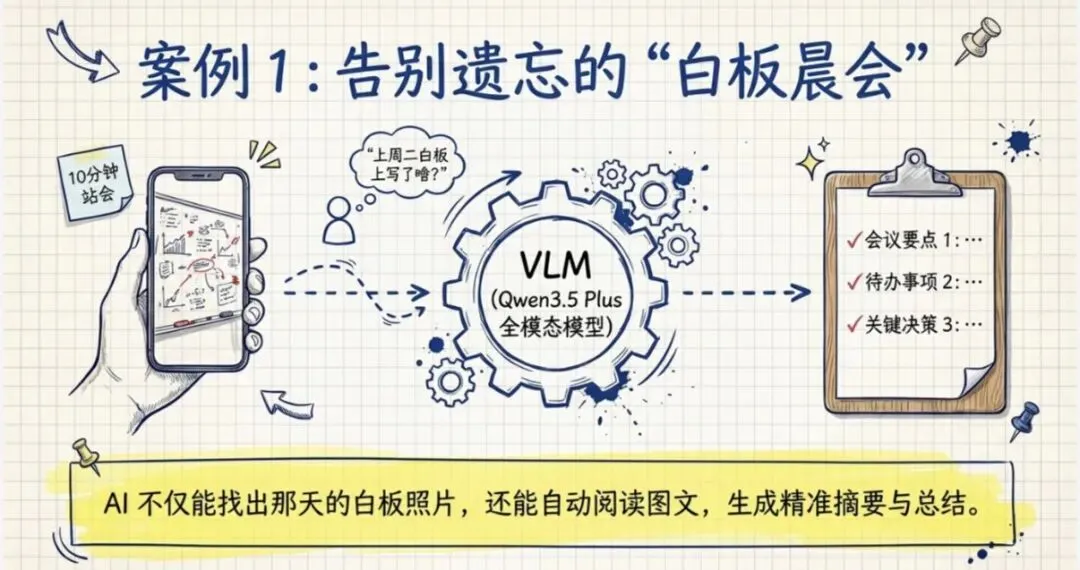
案例 1:白板晨会管理
比如说我可能经常带团队去开那个晨会啊,每天十分钟的站会,然后我们都会在白板上面写些东西,然后我就会把这个白板拍下来,然后发给 OpenClaw。
这个 OpenClaw 呢,它就会把我白板上这些内容啊,用这个VLM 模型(视觉语言模型),它自己会知道怎么调的。我给它配的也是那个 Qwen3.5 的 Qwen3.5 Plus 全模态模型,然后它就会理解这个内容,然后给我存好。
存好之后,我经常会隔一段时间就会查,说比如"上周二我们站会的那个白板上写了啥",然后它就会把那天的白板的图片找出来,然后根据白板上的内容啊,给我做一些摘要、做一些总结啊。
这个是我感觉用处挺大的。
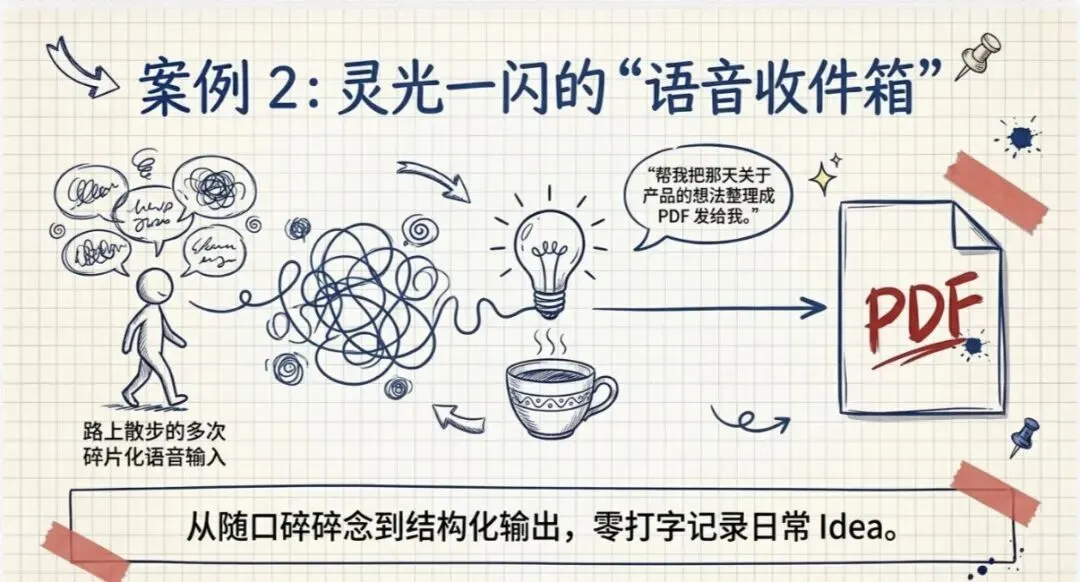
案例 2:语音 Idea 管理
还有呢,我经常会有一些 Idea 或者是想法,就包括我现在写的这篇文章啊,那我也是懒得打字嘛,我就直接发语音告诉它。
这个语音呢,你可以分多次发送,然后我告诉它呢,我写的这个、发这些语音,你要帮我做一个什么事啊,可以帮我先存下来,整理后我存下来啊,存下来之后再整理。
然后哎,过了几天对吧,突然跟朋友聊天,说到一个什么事,然后突然我就想起了我这个事,我就可以拿出手机对着我的 OpenClaw 输出一个语音,说:
"把我那天有关于这个产品的一个什么想法,这个我当时给你发录音了,你帮我找出来,把这个想法的内容整理好啊,整理成一个 Word 文件或者是 PDF 文件,然后发给我。"
哎,它就真的找到,并且把这个 PDF 文件发给我,然后我就发给你,呃比如说一些同事或者朋友。
这个也是我觉得非常方便,它可以把你这种日常的一些 Idea 给记下。
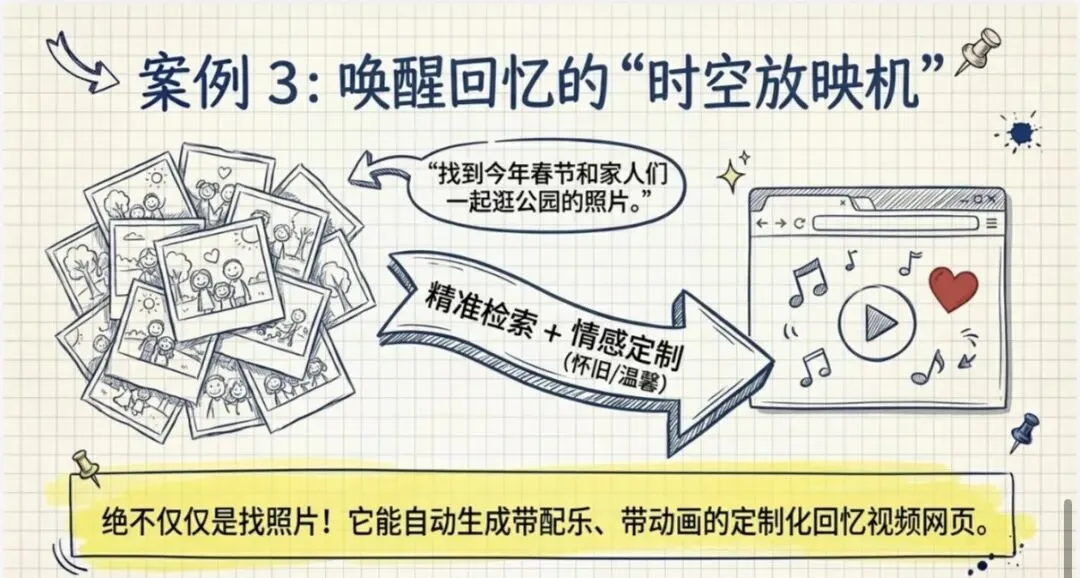
案例 3:NAS 照片检索 + 回忆视频
当然啊,我们呃我这个龙虾机呢,本身呢,我们之前做过花了很大力气做的这种本地模型的图片、视频、音频、文档的理解,其实做的也还挺好。
但是呢,我跟它说,我说我那个把一个目录下面啊,就是我这个 NAS 的哪一个目录下面存了很多很多什么图片,而且这个图片呢,它被整理到那个向量数据库或者是那个索引数据库里去,然后给它们权限。
我说帮我找到什么什么样的图片啊,比如说"找到今年春节和家人们一起在公园逛年会的这个照片",它就帮我找出来。
这还没有完啊,找出来之后,我想干嘛呢?我说把这些图片帮我做一个那个智能播放的这种回忆小视频吧。
哎,它就用了它这个做了一个网页,把这个图片啊做了一个网页,这个网页就直接可以播放。就包括配乐也好,说那个动画也好,做的还是挺好看。
我可以告诉它,说要帮我做一个怀旧的,还是帮我做一个温馨的,这些它都可以帮我做。
这个也是我觉得非常好用,可能对普通用户更为适用的一个。
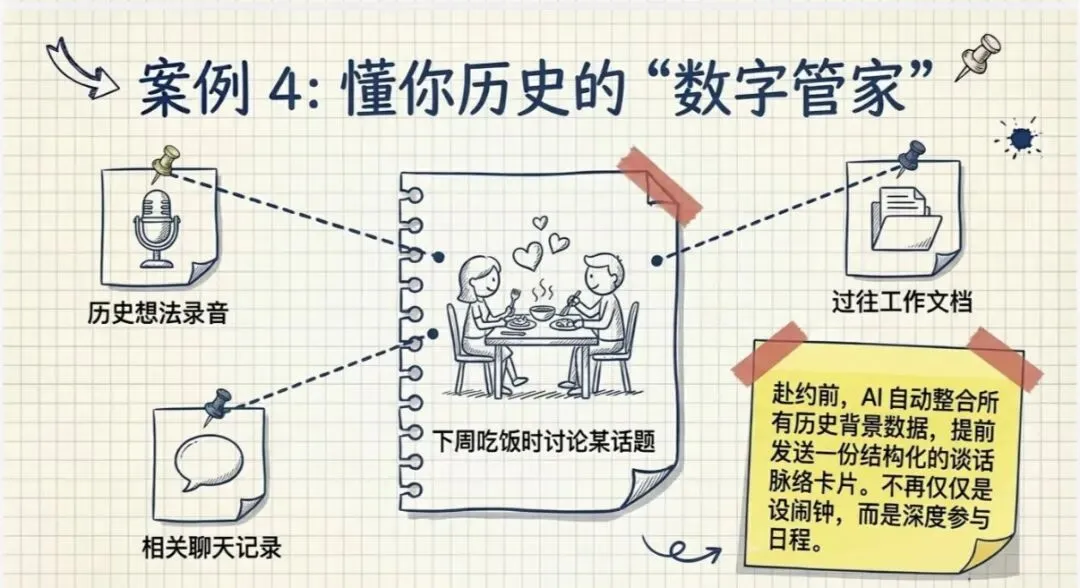
案例 4:个人日程提醒
哦,补充一下,其实我觉得还有一些非常能用的,觉得好用的就是做一些个人的日程提醒。
这个你可以用比如说手机的日程管理啊,这开了的 Teams 或者是邮件里面日程管理去做没问题。但我觉得我只有直接都告诉它,告诉我,我说:
"下周什么时候提醒我跟谁去吃饭,然后吃饭的时候讨论什么话题,然后这个话题对吧?你可以搜索一下我之前相关的想法,你整理。"
哎,它就可以把我这些信息跟我的历史的那个相关的数据帮我整理好,然后到那天对吧?它就提前给我发个信息,说:
"今天你要跟谁去吃饭,讨论什么话题,然后这相关的话题和你之前的工作呀,或者什么想法呀,有一些关联,他都给你整理好。"
这个我觉得也非常实用啊。
数据管理和备份
随着这个时间啊,就这段时间这个深入应用。我现在基本上已经是把我日常生活中的工作和生活中的点滴的这个文件啊、想法呀、照片啊,都去扔给它,然后它会把我整理在不同文件夹里。
就是等一会我会把这个文件夹的截图发给大家啊,整理的井井有条的。而且呢,它有一些元数据,它也不是马上处理的,它会在后台慢慢去整理。那个我只需要定时地去检查一下它有没有什么问题就行了,就确保它一定是稳定工作。
还有这些像我跟它对话聊天的这些数据,那都是非常宝贵的、跟我相关的、独一无二的这种数据资产了,这个一定要能够保存好。
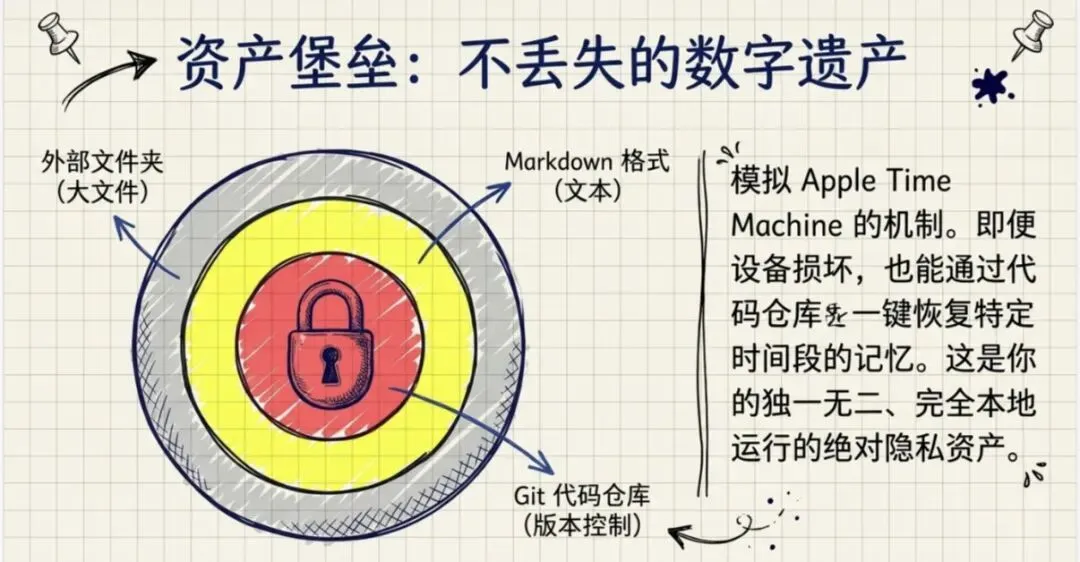
这个我也做了一些设计:
- •大文件管理:比如说这种图片呀、文档啊,就是比较大的这种文件嘛,我就单独让它保存到一个某一个外面的文件夹去。
- •文本数据:然后我跟它聊天啊,然后它整理的这些数据啊,全部都是 Markdown 格式啊,以 Markdown 格式为主,这些数据基本上都是文本的啊。
- •版本管理:你跟他这个文本就不是很大嘛,那我就是用 Git 来管理。Git 是什么呢?就是一个编程代码的一个版本管理的东西,就是我每次跟它对话,它会给我保存一个这个版本管理,然后它会我可以设置它让它自动提交到一个代码仓库去。
- •数据恢复:虽然是代码仓库,它是可以去存我的这些数据嘛,然后一旦比如说你换一台机子,或者是这个出到什么问题,我就可以从我这个代码仓库里面,把某一个时间段的版本给恢复下来。这个就确保了我的这个数据不会丢失。
但是我们现在也在想做一个在我们的这个产品里面做一个内部的这样的工具,让那些不懂技术的啊,它也就自动有这个功能啊,就像那个苹果电脑的 Time Machine 一样是自动,因为都是这些从文字的这种文件嘛,所以他也不会占很大地方。
啊,这样就确保了数据不会丢失,而且这个这个我觉得是对个人对未来非常非常重要的一个数据资产。
开源分享
好了,今天就暂时说到这些吧。
其实要打造自己的这个第二大脑,并不是说只有我这个方法。但我这个是经过了一些实践的。
呃,我也把这个卡帕西和那个 PARA 框架的这个架构,就是代码架构和相关的这个提示词啊,也开源了。嗯,大家可以直接下载下来就可以直接用啊,分享的下载下来就直接用。
呃,只要把这个东西下载到你的龙虾里,让跟龙虾读一说,呃,打开这个然后帮我做一个第二大脑怎么做呢?都在这个我的文档里都写好。
绝对的安全啊,嗯,没有任何风险,大家放心使用。
嗯,后那个呃当然这个我不能说它是非常完美的,我会定时去更新。
你想要这部分资料的呢,可以在评论区留言,我可以分享给大家。

这就是我用 OpenClaw 打造第二大脑的完整实践。
你觉得怎么样?欢迎在评论区留言交流!
