 夜雨聆风
夜雨聆风这几天我越来越强烈地意识到一件事:
如果想真正把 OpenClaw 里的“龙虾”用成一个高频、长期、敢放开调度的 AI 搭子,只靠云端模型是不够的。
很明显在一些简单的命令场景,逻辑能力要求不高的情况下。采用本地 token 是最佳的选择,先上我的 openclaw 本地模型效果截图:
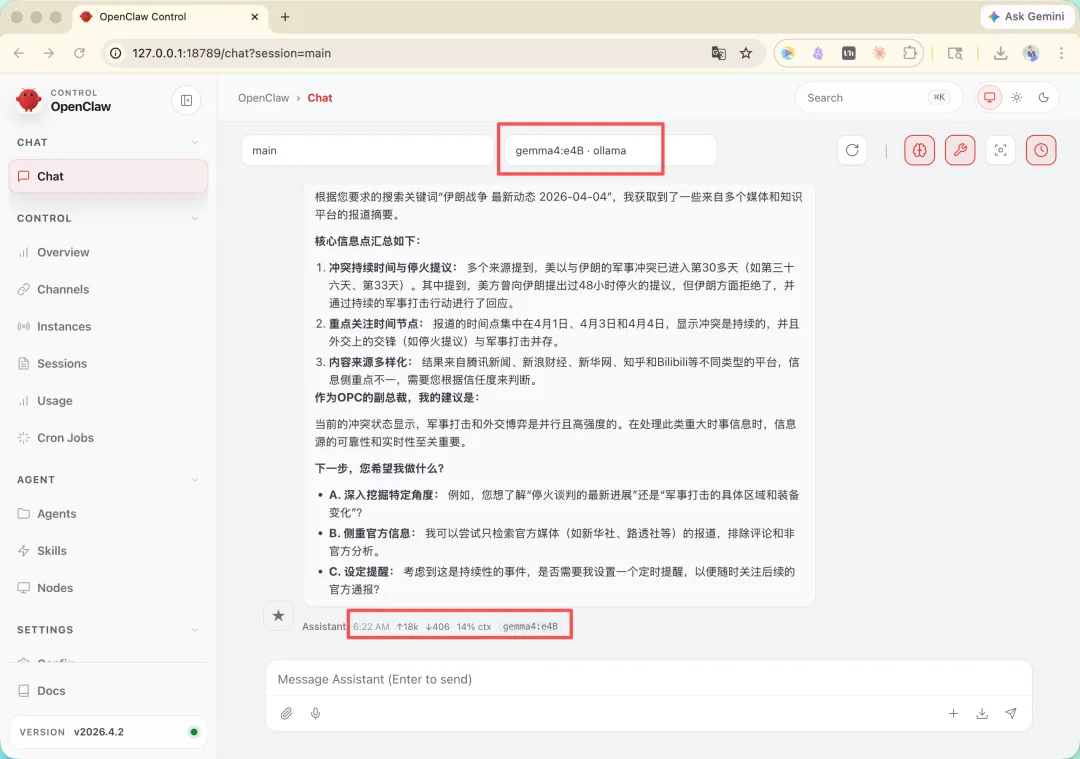
其实这么做原因很简单。
不是模型不够强,而是 token 成本会悄悄反过来塑造你的使用习惯。
你会开始犹豫: - 这段长文本要不要让它再总结一遍? - 这个流程要不要多跑两轮? - 这个草稿要不要再让它重写三版? - 这个知识库问答要不要把上下文喂满?
表面上你是在“理性控制成本”,本质上你已经开始被 token 预算训练了。
我不太喜欢这种感觉。
因为我想要的不是一个“偶尔用一下的 AI”,而是一个可以稳定接流程、长期跑任务、真的敢高频调用的数字搭子。
所以我最近做了一件很具体的事:
为了让 OpenClaw 龙虾实现 token 自由,我开始在 Mac 上本地部署 Google Gemma 4 。
这篇文章,我就把整个过程完整写下来:

我为什么会开始折腾“龙虾的 Token 自由”
先说最直接的原因:我已经不满足于把 AI 只当成一个聊天窗口。
我现在更希望 OpenClaw 里的龙虾,能帮我做的事情包括: - 持续抓热点 - 写公众号 - 改文章 - 反复生成不同风格版本 - 做知识整理 - 跑更多工作流类任务
这些动作一旦真的高频起来,你就会发现, token 不是一个抽象数字,而是一个很真实的使用边界。
尤其是像我这种已经开始把 AI 往“长期生产工具”方向用的人,最怕的不是模型偶尔慢一点,而是每次想多跑两轮时,脑子里都自动冒出一个声音:
“这次会不会又烧掉不少 token ?”
这会严重影响你对 AI 的使用深度。
因为很多高价值使用方式,本来就不是“一问一答”型的,而是: - 多轮迭代 - 长上下文 - 工作流反复调用 - 试错式生成 - 批量处理
这些动作一旦被 token 成本卡住,龙虾再聪明,也没法真正放开手脚干活。
所以我越来越觉得,让龙虾实现 token 自由,不只是省钱,而是在为它争取真正进入工作流的自由度。
为什么我选的是 Gemma 4 ,而不是别的本地模型
本地模型其实已经很多了,为什么偏偏是 Gemma 4 ?
我自己的判断很简单:
第一, Gemma 4 已经不是“能跑”而已,而是“能用”
我对本地模型最看重的,不是跑分,也不是参数表,而是它到底能不能接真实任务。
至少在我关心的这些场景里: - 日常问答 - 内容写作 - 资料总结 - 简单代码辅助 - 工作流节点调用
Gemma 4 已经不是那种“看起来能运行、其实只能演示”的模型了。
它的意义在于:本地部署不再只是极客折腾,而是已经能进入实际使用。
第二,它适合做“本地底座”
我并不要求一个本地模型,一上来就完全替代最强云端模型。
我真正想要的是一个: - 成本稳定 - 可长期调用 - 可以接进 OpenClaw 生态 - 能承担一部分常规任务 - 让我敢把龙虾更多动作放到本地去跑
从这个角度看, Gemma 4 很像一个靠谱的本地底座。
第三, Mac 上已经有比较成熟的部署路径
如果今天本地部署还停留在“装一堆依赖、编半天、最后报错”,那这件事就不适合多数人。
但现在不是了。
在 Mac 上,尤其是 Apple Silicon 机器, Gemma 4 已经有比较清晰的本地部署路线: - Ollama:最适合先跑通 - llama.cpp:更适合进阶控制 - MLX 路线:值得关注,但更偏技术流
所以我最后的策略很明确:
先用 Ollama 让 Gemma 4 跑起来,先把龙虾的本地底座搭住,再考虑进阶优化。
我在 Mac 上本地部署 Gemma 4 ,实际就是这么做的
这里我尽量不写成那种只会堆命令的教程,而是按“你真的要跑通”这件事来说。
第一步:先判断自己的 Mac 适合跑什么级别
这一步特别重要,很多人失败,不是因为不会装,而是一上来选错模型。
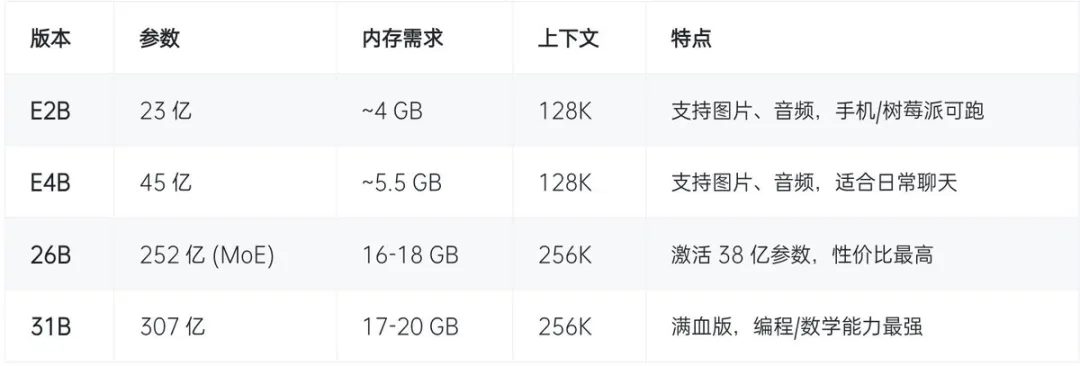
我的建议很直接:
这件事的核心不是“能不能跑”,而是“跑起来以后好不好用”。
如果只是勉强能启动,但速度很慢、风扇狂转、上下文一长就卡,那它就很难真进入你的日常工作流。
第二步:先装 Ollama ,而不是一上来就折腾最复杂的方案
我自己的选择是:先用最稳的路径把事情跑通。
因为如果你本来是为了让龙虾多干活,就不应该先把自己困在底层折腾里。
安装好 Ollama 之后,先检查:
ollama --version 只要这一步通了,后面就顺很多。
第三步:拉 Gemma 4 模型下来
接下来就是把 Gemma 4 真正拉到本地。
通常思路就是:
ollama pull gemma4:26B 或者按不同规格拉不同版本。
这一步我最大的体感是:模型真开始落到你自己的机器上时,心态会不一样。
因为那一刻你就知道,后面这套能力,不再完全依赖外部 API 了。
第四步:先跑起来,再谈优化
模型拉完之后,我先做的不是接工具链,而是最基础的一步:
ollama run gemma4:26B 能交互,能问答,能出内容,就说明这条路跑通了。
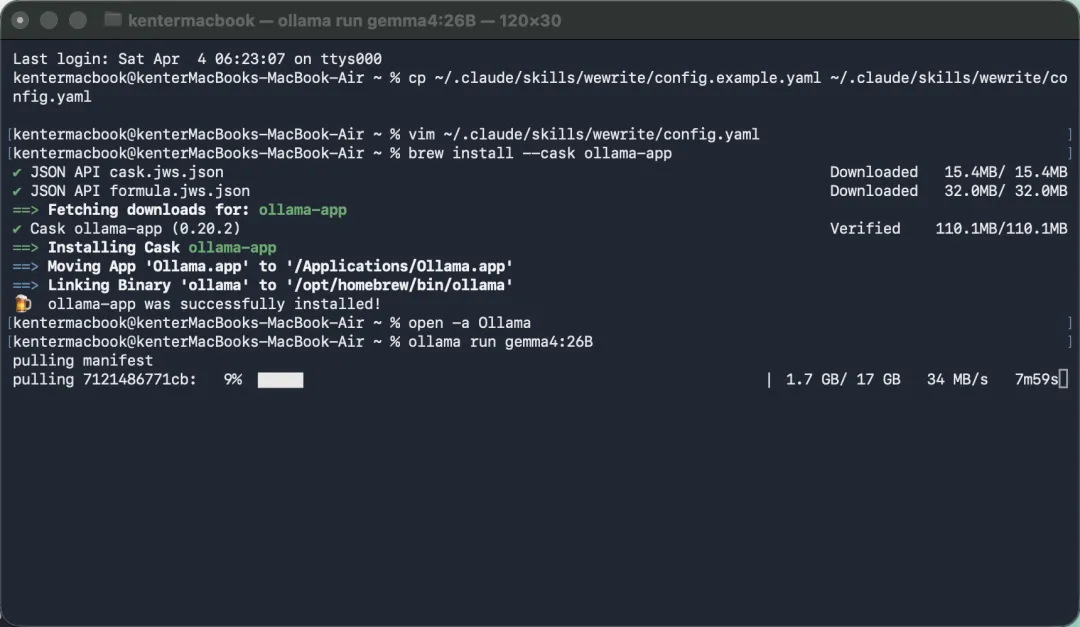
这一步看起来很简单,但其实特别关键。
因为很多人本地部署失败,不是技术上失败,而是战略上失败——总想一口气做到“最优”。
我的经验反而是:
先得到一个可用结果,再慢慢把它变成一个更好的系统。

本地模型跑起来之后,龙虾会发生什么变化
这部分我觉得才是最值得讲的。
因为本地部署的意义,不是“哦,我会了一个命令”,而是你会开始重新定义龙虾的工作边界。
变化 1 :可以更放心地高频调用
以前很多动作我会自然收着点。
现在如果有本地底座兜着,我就更愿意让龙虾: - 多改几轮 - 多试几版 - 多跑几次摘要 - 多做一些本来会觉得“有点费 token”的操作
这就是最直接的变化。
变化 2 :更适合承接重复任务
不是所有任务都值得动用最强云端模型。
很多任务其实是: - 重复 - 高频 - 有固定格式 - 对极致推理没那么敏感
这些任务如果交给本地模型,其实很划算。
比如: - 初步清洗内容 - 基础总结 - 多版本改写 - 常规分类 - 局部工作流节点
这就意味着,龙虾以后可以形成一种更合理的分层: - 高价值、高难度任务 → 云端强模型 - 高频、重复、可标准化任务 → 本地模型
这个结构一旦搭起来,整个使用成本和自由度都会变。
变化 3 :真正有机会把 AI 接成系统,而不是只当聊天工具
我越来越确定一件事:
未来最有价值的 AI 使用方式,不是“问它一个问题”,而是“让它接住一个流程”。
而流程这件事,一旦每一步都靠外部 token 计费,很多人就会本能地缩手。
但一旦本地底座稳定了,很多流程型任务你就敢真的接进去。
这才是“龙虾 token 自由”的真正含义。
不是为了省小钱。
而是为了让它真正从“会聊天”进化到“会干活”。
中间有哪些坑,是我觉得你最好提前知道的
1. 别一开始就追最大模型
很多人最大的误区就是:
既然要本地部署,那就一步到位,直接上最大的。
结果通常就是: - 下载很久 - 跑得很慢 - 使用体验很差 - 最后怀疑人生
不是模型不行,是策略有问题。
你真正要追求的,不是“我本地跑了多大模型”,而是“这个模型是不是能稳定进入我的日常流程”。
2. 别把“能启动”当成“能用”
模型能启动,只是开始。
真正要判断的是: - 中文表现够不够自然 - 总结能力够不够稳 - 速度你能不能接受 - 长上下文会不会明显掉体验 - 它能不能接你的真实任务
这一步一定要用你自己的实际任务测,而不是只看别人跑分。
3. 别以为装完就结束了
本地部署最值钱的部分,其实是装完之后: - 接 OpenClaw - 接本地知识库 - 接自动化工作流 - 接你自己的固定任务链路
如果只是装完跑一句 hello ,那它对你来说还是演示。
只有当它开始替龙虾分担真实工作,它才变成生产力。
如果你也想让自己的龙虾实现 token 自由,我建议你这样开始
我给一个最实际的顺序:
第一阶段:先跑通
第二阶段:先分担简单任务
第三阶段:再逐步接进 OpenClaw
这条路的好处是:
你不是为了炫技去部署一个模型,而是为了让你的 AI 搭子,真正获得更大的使用自由。
最后说句实在话
我现在越来越不相信那种“未来某一天,一个模型会包打天下”的叙事。
现实一点看,更可行的路其实是:
而我这次在 Mac 上本地部署 Gemma 4:26B ,说到底,就是在给龙虾争取一件事:
不是更聪明,而是更自由。
自由去多跑几轮。
自由去接更多任务。
自由去承担那些本来会被 token 成本压住的动作。
如果你也已经在高频使用 AI ,我真的建议你试一次本地部署。
不是因为它会立刻替代所有云端能力。
而是因为一旦你真的把第一条本地链路跑通,你对 AI 的使用方式,很可能就再也回不去了。

