 夜雨聆风
夜雨聆风昨天的文章,给大家介绍了Google发布的最新大模型产品Gemma 4。
Gemma 4最大亮点,莫过于手机可以跑2B、4B,单卡可以跑31B,全尺寸覆盖,四款模型同时发布,同时Apache 2.0开源协议,良心到爆。
今天,来带大家在手机或电脑上简单体验本地部署Gemma 4大模型。
一、手机体验,最简单
如果你穿越回2000年前,手里只有一部手机和一台太阳能发电移动电源,那么通过在断网的手机上使用本地AI大模型,就可以实现穿越爽文了。
那么如何在手机上手体验呢?
非常简单!
1. 打开你的应用商店,譬如iPhone的App Store; 2. 搜索Google AI Edge Gallery,安装; 3. 打开软件,点AI Chat,根据手机性能选择Gemma 4 E2B或者E4B下载模型; 4. 下载完成后,开始体验!
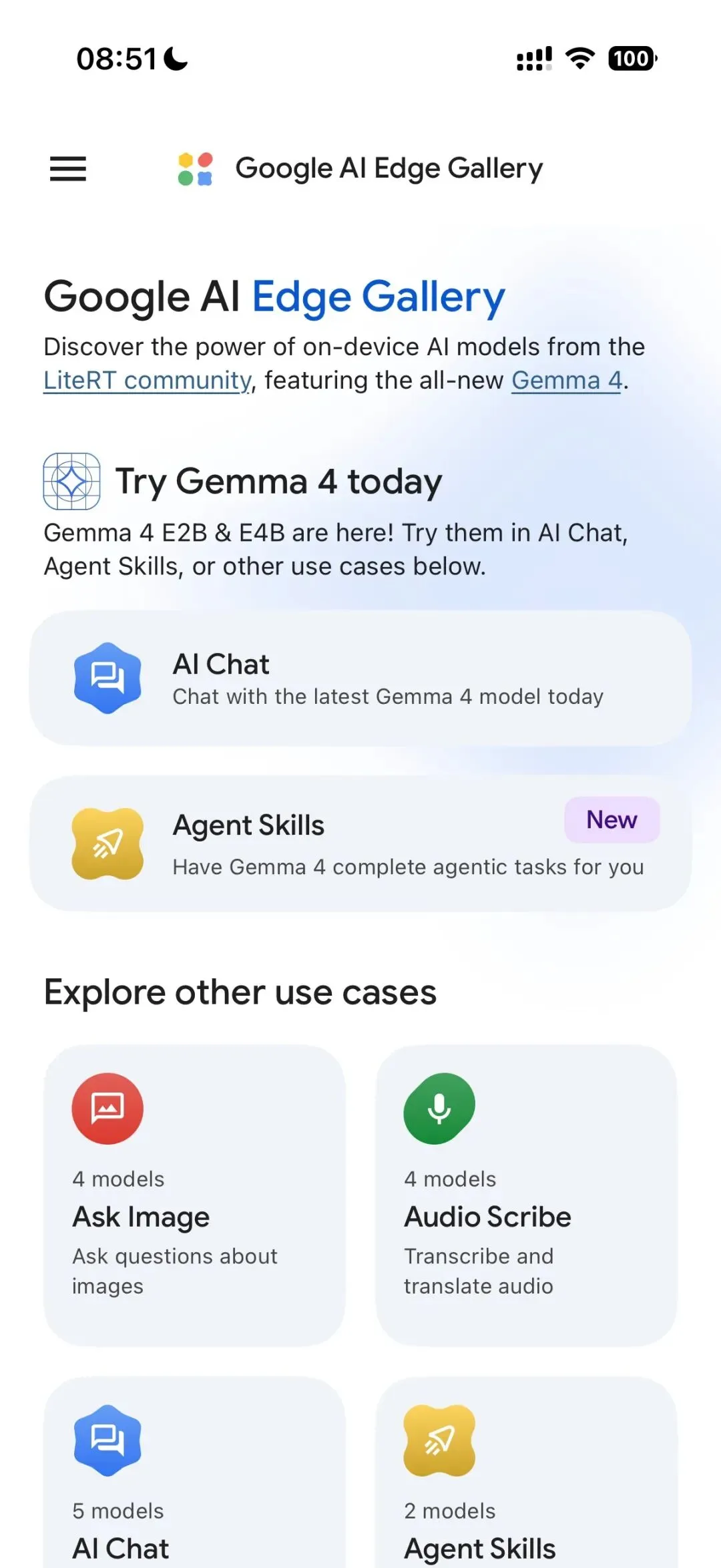 | 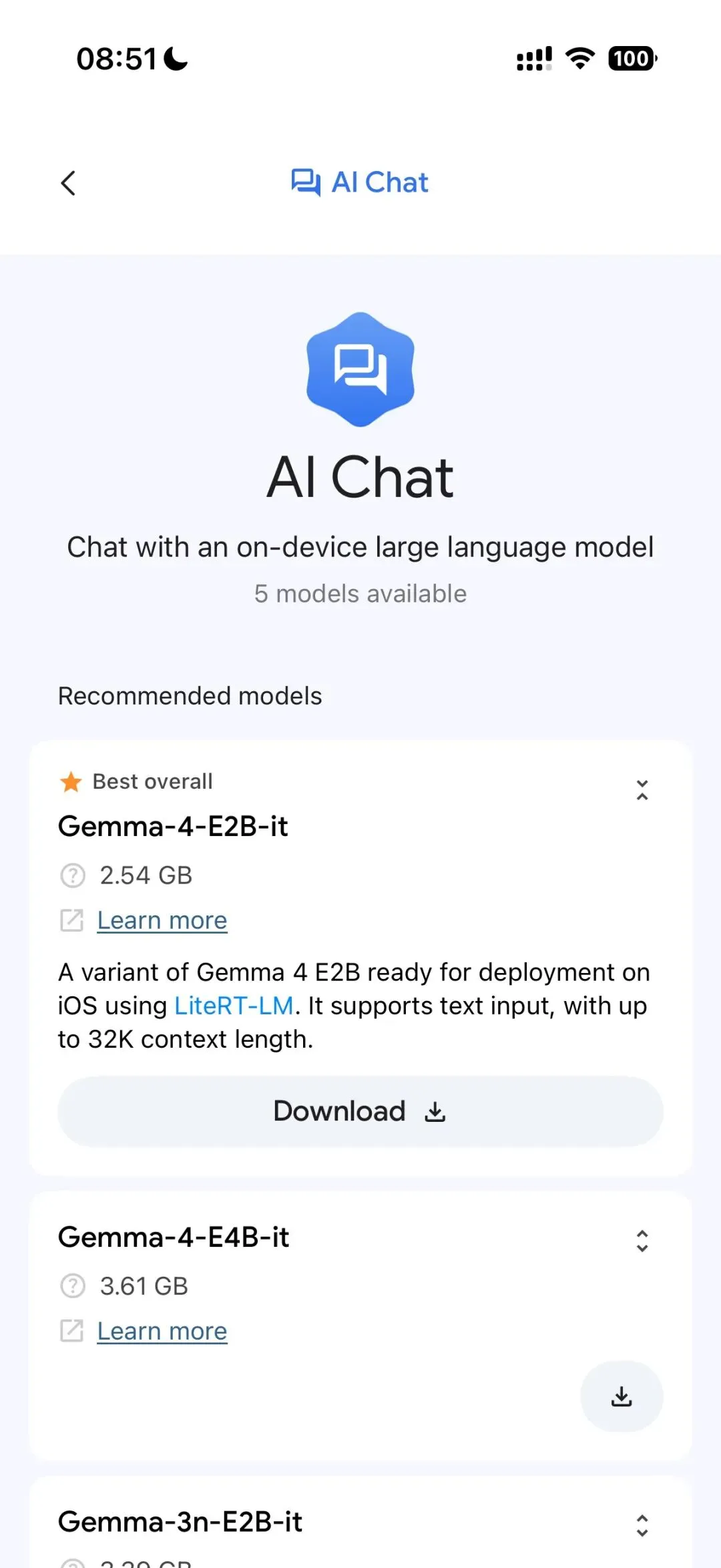 | 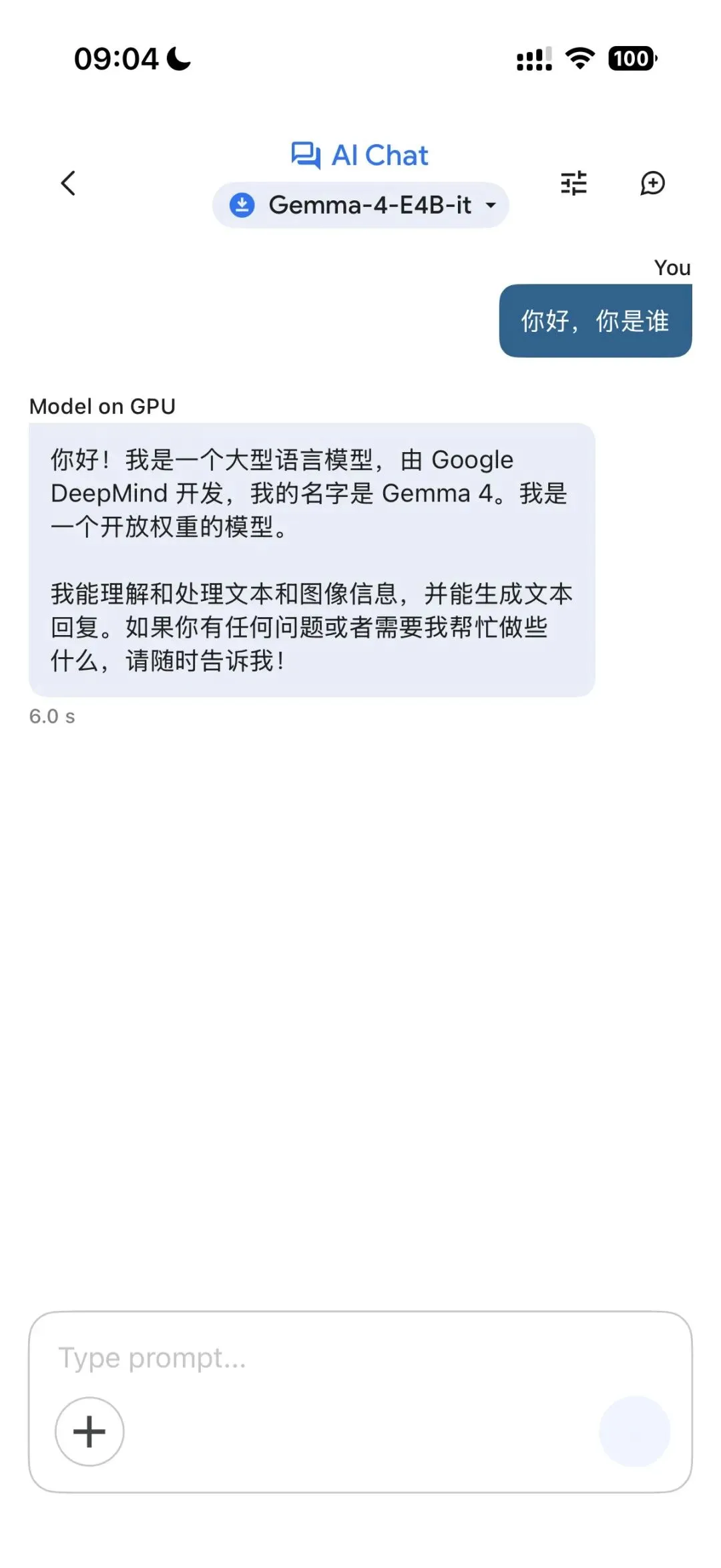 |
手机体验实测:是否支持中文?
很多人关心是否支持中文,其实第一句话只要跟他说「你好」就可以了,实测Gemma 4模型均支持中文对话。
手机体验实测:没有网络能不能用?
由于是调用本地GPU或CPU运算的大模型,实测在没有网络的情况下,可以和它流畅对话。
二、电脑体验,也非常简单
电脑上体验Gemma 4模型,也非常简单,本次以Ollama为例。
1. 打开ollama官网,点击下载按钮Download; 2. 下载对应系统版本,安装,安装后可以在终端输ollama —version验证; 3. 终端输入ollama pull gemma4:e4b(或根据配置选择其他版本)下载模型; 4. 终端输入ollama run gemma4:e4b,就可以对话了!

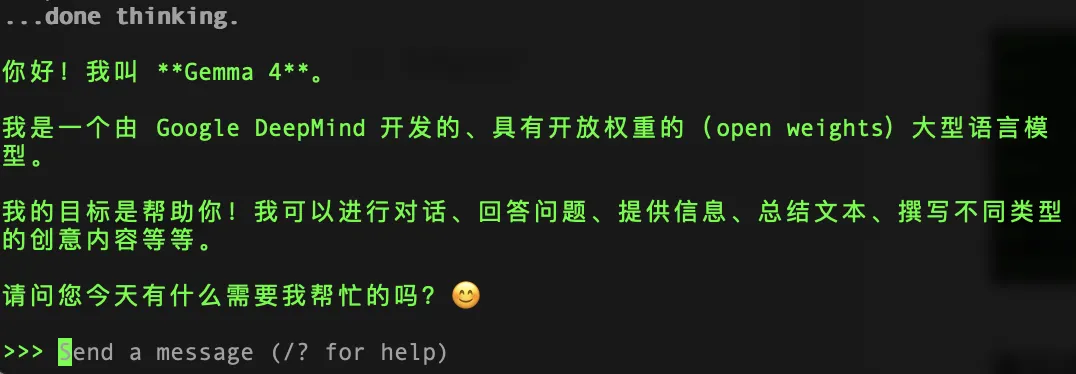
模型怎么选?
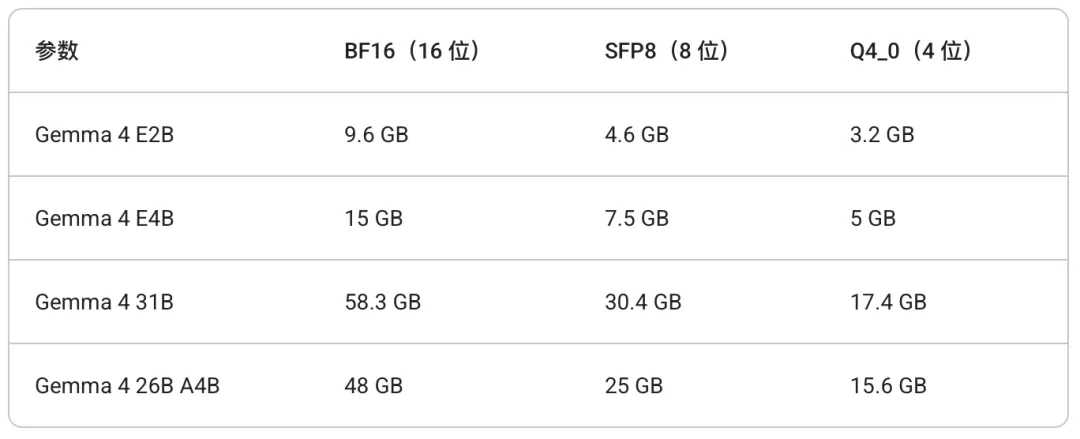
手机端E2B、E4B两个模型怎么选?
我用iPhone 16 Pro实测,可以跑E4B模型。但相较于最小的E2B,E4B模型在点进去的一瞬间,加载时间要稍微长一点,但没有很夸张。
在模型给出较长的回答时,E4B模型输出到后边,会慢慢降低token输出量,同时手机背部摄像头旁边也开始微微发热了。
说明,第一:确实调用的本地SOC运算能力;第二:手机跑E4B会遇到性能瓶颈问题,有些许吃力。
Gemma-4-E2B-it
模型大小:2.54 GB
模型亮点:使用LiteRT-LM部署的轻量版,支持高达32K的上下文长度
选择建议:想尝鲜使用,或者普通玩家可以选择E2B,首先,它体积适中,下载快,对手机的性能压力较小,日常做点文本处理,或者随手问答完全足够。如果在没有网络的公共厕所,或者上飞机前忘了下载电影,可以和他聊聊天解闷^_^。
Gemma-4-E4B-it
模型大小:3.61 GB
模型亮点:相较于Gemma-4-E2B-it,首先是参数量翻倍,那么就说明在逻辑推理、复杂 Agent指令遵循方面,理论上表现更出色。
选择建议:如果你对模型回答的深度有要求,或者手机性能足够,一定要选。
26B和31B
Gemma-4-E2B-it和Gemma-4-E4B-it在手机上都可以跑起来,那么你的电脑如果不是太老的话,基本上不用担心。
26B则是混合专家架构(MoE),总参数252亿,每次推理只激活38亿。量化后占16-18GB内存。256K上下文,支持图片,不支持音频。速度接近小模型,质量接近满血版,性价比最高。24 GB内存的Mac或24 GB显存的显卡就能带得动。
31B则可以称得上是Gemma 4的满血版,307亿参数全激活,256K上下文,17-20GB内存。Arena AI开源排行榜第三,AIME 2026数学推理89.2%,跑分很猛,但24 GB可能还是无法实现最优体验,建议32 GB以上。
太长不看版,简单总结
E2B什么电脑都能跑,老年机可能不行,E4B需要高配手机或平板,但体验可能有些差,建议GPU 8GB以上。
26B的话,Mac mini M4 32GB以上,或者4060级别显卡。31B则需要更高配的Mac Ultra、Max,或者5090 32GB级别显卡。
如果你有一张H100或者A100,甚至DGX Spark,那就都可以跑。
附:Gemma 4模型名称和Ollama其他常用操作命令
1 2 3 4 gemma4:e2b # E2B参数 gemma4:e4b # E4B参数 gemma4:26b # 26B A4B参数 gemma4:31b # 31B 参数
1 2 3 4 5 6 ollama pull gemma4:e4b # 下载某版本模型ollama run gemma4:e4b # 启动对话ollama list # 查看已下载的模型ollama ps # 查看正在运行的模型和内存占用ollama stop gemma4:e4b # 卸载模型释放内存ollama rm gemma4:e4b # 删除模型

