 夜雨聆风
夜雨聆风
论文题目:OpenClaw-RL: Train Any Agent Simply by Talking arXiv:2603.10165 单位:Princeton https://github.com/Gen-Verse/OpenClaw-RL

TL;DR:
OpenClaw-RL 的核心洞察是:Agent 每次交互产生的"下一步状态信号"(用户回复、工具输出、环境变化等)不仅是下一步的输入,更是包含评估与指令信息的免费监督信号;通过完全解耦的异步架构,系统能够同时从个人对话、终端操作、GUI 交互、软件工程任务等多源异构流中实时学习,实现“越用越聪明”的持续进化。
OpenClaw-RL 利用两种学习信号进行优化:
Binary RL:使用 PRM 从 next-state 中提取出 -1/1/0 这样的标量 reward; 基于 on-policy 蒸馏的 token-level 优势:利用 next 的信息来构建 hint 进而应用 on-policy 蒸馏来计算 token-level 的优势。
Abstract 翻译:
每个 Agent 交互都会产生一个下一状态信号,即用户回复、工具输出、终端或图形界面状态变化等紧随每次行动后的反馈,然而现有 Agent 强化学习系统均未将其作为实时在线学习资源加以利用。我们提出 OpenClaw-RL 框架,其构建于一个简明洞见之上:下一状态信号具有普适性,policy 可以从所有信号中同步学习。私人对话、终端执行、图形界面交互、软件工程任务与工具调用轨迹并非彼此割裂的训练课题——它们皆可作为同个训练循环中培育同一策略的交互资源。下一状态信号编码着双重信息维度:评估性信号通过 PRM 评判器提取为标量奖励,用以衡量行动执行效能;指导性信号则通过后见指导型同策略蒸馏技术,揭示行动应如何调整优化。我们从下一状态提取文本线索,构建增强型教师上下文,并提供比任何标量奖励都更具信息密度的词元级方向优势监督信号。 由于采用异步设计,模型可实时处理请求,PRM(策略奖励模型)可同步评估交互过程,训练器则同时更新策略,三者间实现零协调开销。应用于个人 Agent 时,OpenClaw-RL 使 Agent 仅通过日常使用即可持续优化,从用户的重复查询、修正操作和显式反馈中恢复对话信号。应用于通用 Agent 时,同一基础设施支持终端界面、图形界面、软件工程及工具调用场景下的可扩展强化学习,我们进一步展示了过程奖励机制的实际效用。一、研究背景与动机
现有的 AI Agent 系统存在一个巨大的信号浪费问题:
现象:每当 Agent 执行一个动作(action)后,环境都会返回一个"下一步状态"(next-state signal)——可能是用户的回复、代码执行结果、终端输出、GUI 状态变化或测试报告。这些信号天然地包含了对前一个动作的评价("做得好不好")甚至纠正("应该怎么做")。 问题:当前系统(如 ReAct、各类 Tool-use 框架)仅仅将这些信号当作下一步决策的上下文(context),用完即弃。没有人尝试将这些实时产生的、流式接入的信号转化为训练信号。 动机:作者意识到,个人对话中的用户不满、终端里的错误日志、SWE 任务中的测试失败,都是极其宝贵的过程奖励(Process Reward)。如果能在线回收这些信号,Agent 就能在真实部署中持续改进,而无需昂贵的离线标注或人工干预。
二、研究内容与方法
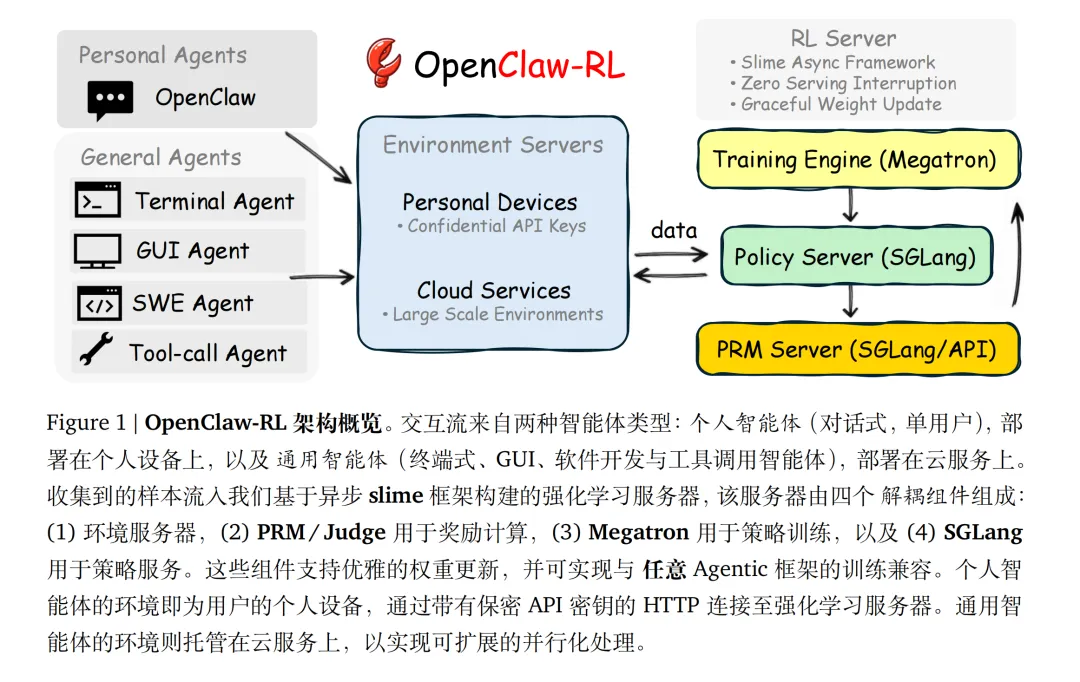
核心架构:四重解耦异步系统
论文设计了一个基于 slime 框架的异步架构,将四个组件完全解耦:
策略服务(SGLang):实时响应用户请求 环境服务器:托管个人设备或云端环境 PRM 评判器:实时评估交互质量 训练引擎(Megatron):持续更新策略
这四个模块以零阻塞方式并行运行:模型在服务当前请求的同时,PRM 在评判上一个交互,训练器在更新更早的权重。
两种互补的学习机制
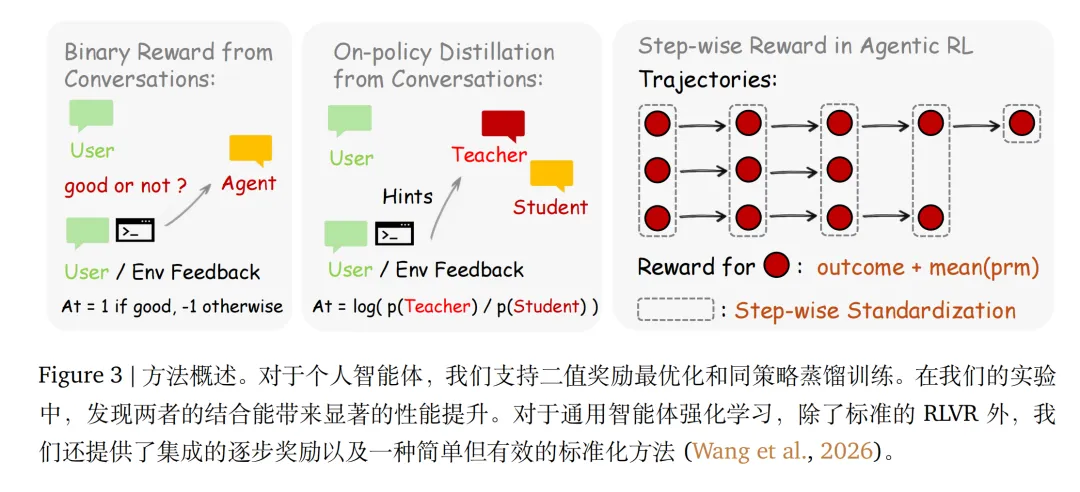
(1)Binary RL:处理评估信号
将评估性的下一状态信号转换为标量过程奖励。
下一状态(next-state)指的是 tool call 结果和用户的下一步响应,这其中可能包含满意或不满意的信号。
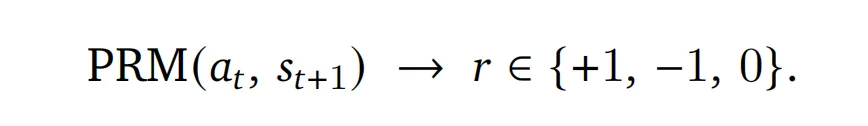
使用过程奖励模型(PRM)将 next-state 转化为标量奖励(+1/-1/0)。这个阶段可能会独立运行 m 次并采用 Majority Voting 来得出 。 采用非对称 clip 的 PPO 算法进行优化,适用于所有类型的交互:

(2)Hindsight-Guided On-Policy Distillation (OPD):处理指令信号
为了提供 token-level 的细粒度 advantage,这里提出了基于 on-policy 蒸馏的 OPD 技术。
关键洞察:用户说"你应该先检查文件"不仅表示"错了",还指示了"具体如何改" 做法: 构建增强的 user msg:从 next-state 中提取出文本提示(hint),然后将其附加到最后一个 user message 的末尾,形成 。 计算 token-level 的优势:将 给 policy model 作为查询,然后以原生响应 作为强制输入,计算每个响应 token 的对数概率,从而得到 on-policy distillation 中的 token-level 优势 :

其中:
:表示 teacher model 为该 token 分配了更高的概率,学生应该提高该概率; :根据提示信息,教师认为该 token 不太合适——学生应降低该概率。
与统一方向推动所有 token 的标量优势不同,这种机制提供了每个 token 的方向性指导:在单个响应中,某些 token 可能被强化,而其他 token 则被抑制。
(3)混合训练
使用来自「Binary RL 的二元奖励」和「OPD 的 token-level 优势」来共同用于计算最终 advantage 并优化模型:
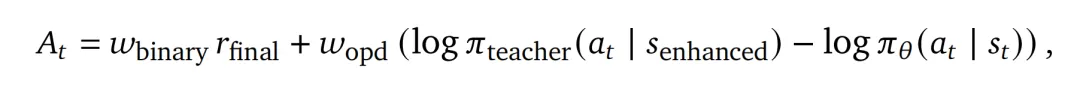
实验证明两者互补,结合后效果显著优于单独使用。
三、实验发现
3.1 个人 Agent 场景
场景:学生使用 OpenClaw 来做作业,完成文件中的作业后,教师也使用 OpenClaw 来批改 AI 撰写的作业。教师希望给学生的评语具体且友好。OpenClaw 的策略模型再次采用 Qwen3-4B,并使用相同的最优化设置。
实验发现,仅需 36 次解题交互或 24 次批改交互,Agent 就能学会“像人一样说话”(学生场景避免 AI 腔,教师场景变得友好具体)。

3.2 通用 Agent 场景
我们分别在终端、GUI、软件工程(SWE)和工具调用情景中使用 Qwen3-8B。
实验发现,在终端、GUI、SWE、工具调用四类任务上均实现稳定提升,验证了过程奖励对长程任务的关键作用。
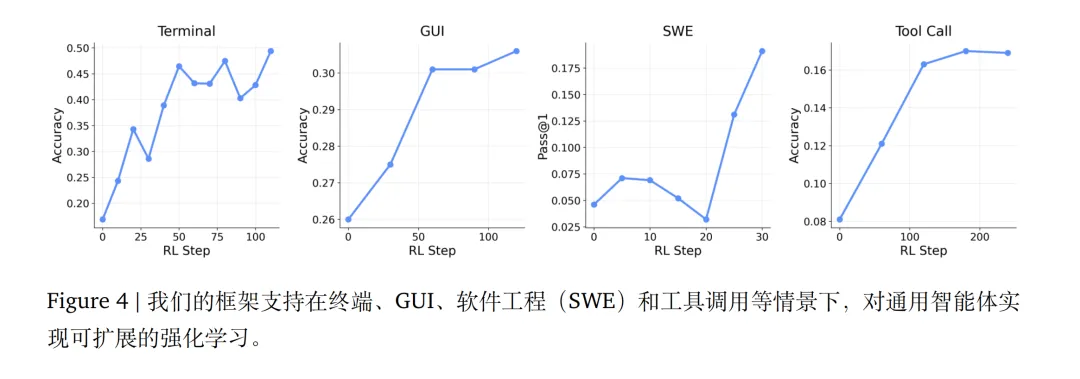
最终论文还发现:将结果奖励与过程奖励相结合,比仅使用结果奖励能带来更强的最优化效果,尽管这需要更多的资源来托管 PRM。
四、总结
理论层面:
统一视角:首次将个人对话代理(Personal Agents)和通用工具代理(General Agents)纳入统一的 RL 框架,证明了 next-state 信号的通用学习价值 信号分层:明确提出并形式化了 next-state 信号中的双重信息——评估性(evaluative)与指令性(directive),为后续研究提供了新的分析维度
实践层面:
持续学习:实现了真正的"在线学习"(online learning),模型在服役期间不间断进化,打破了传统 RL"收集-训练-部署"的批次循环 冷启动友好:个人用户只需正常使用,Agent 就能逐步适应个人风格,无需预先收集偏好数据 基础设施:开源的异步架构为大规模 Agent 训练提供了可扩展的工程范式
