 夜雨聆风
夜雨聆风大家好,我是阿文。
有一段时间没有更新了,在年前写了一篇 OpenClaw 的安装教程,没想到龙虾一直火到现在。
这期间各大模型和云服务厂商都纷纷下场,OpenClaw 的使用门槛已经非常低了,已经赢得开发者社区的广泛认可,被誉为:当前最具使用价值的智能体项目。
我花了不少时间翻 OpenClaw 的源码和各种架构文档,试图搞清楚这个项目到底是怎么把一个 AI 模型变成一个能用的数字员工的,这篇文章是我整理出来的内核拆解笔记。
目前网络上已经有很多非常详尽的部署指南和使用说明,本文不再关注此类基础操作。所以主要聚焦 OpenClaw 的核心技术特性的底层设计思路,旨在和大家共同学习其高效运行的技术逻辑,在使用该工具时,有更加深入的探索,期望能对从事相关工作的朋友有所助益。
先说结论:OpenClaw 到底是个啥
OpenClaw 不是一个 ChatGPT 套壳。它更接近一个 AI Agent 的操作系统,跑在你自己的设备上(笔记本、Mac Mini、云服务器都行),把 AI 模型和你日常用的聊天工具(WhatsApp、Telegram、微信、飞书、钉钉)连起来。
它解决的核心问题:怎么把会聊天的大模型变成能干活的智能体。
这个问题拆开来看其实有三件事:
消息从哪来? 怎么让 AI 理解并行动? 行动结果怎么送回去。
OpenClaw 的整个架构就是围绕这三件事展开的。
整体架构:分层但不僵硬
OpenClaw 采用分层架构,但跟教科书里那种死板的三层不太一样——它的各层之间有明确的契约接口,同时又保留了足够的灵活性。
从上到下大概长这样:
┌─────────────────────────────────────────────────────────────────┐│ 用户交互层 ││ WhatsApp · Telegram · Discord · 微信/飞书/钉钉 · iMessage ││ Web UI · CLI · Mobile App ││ │ ││ ┌─────────────┴─────────────┐ ││ ▼ HTTP Webhook WebSocket ▼ │├─────────────────────────────────────────────────────────────────┤│ Gateway 控制平面 ││ WebSocket 长连接 · HTTP 回调 · 认证与权限 · 配置热重载 ││ 消息分拣与路由 │├──────────────────┬──────────────────┬───────────────────────────┤│ Channel 适配层 │ 路由 / 会话 │ 插件注册表 ││ 格式转换 · ACL │ Session Key 匹配 │ Tool · Hook · Provider ││ 白名单 · 配对 │ peer > guild > │ 冲突检测 · 清单校验 ││ │ account > default│ │├──────────────────┴──────────────────┴───────────────────────────┤│ Agent 执行层 ││ Session 管理 → 上下文组装 → LLM 调用 → 工具执行引擎 ││ Lane 并发控制(串行/并行队列) ││ ┌──────────────────────────┐ ││ │ dispatch → get-reply → │ ││ │ agent-runner → tool loop│ ││ └──────────────────────────┘ │├─────────────────────────────────────────────────────────────────┤│ AI Provider 层 ││ Anthropic(Claude) · OpenAI(GPT) · Ollama(本地) · Bedrock ││ Google Gemini · 自定义 Provider 插件 ││ Auth Profile 轮换 · 故障转移 · 速率控制 │├─────────────────────────────────────────────────────────────────┤│ 持久化 / 基础设施层 ││ 会话存储 · 记忆系统(SQLite+向量) · 凭据管理(0600) ││ 审计日志 · 定时任务(Cron) · 安全沙箱(Docker) │└─────────────────────────────────────────────────────────────────┘我把每一层拎出来讲讲它到底在干什么。
Gateway 层:消息的调度中心
Gateway 是 OpenClaw 的入口和总调度。它基于 Node.js 实现,默认监听 127.0.0.1:18789,同时提供 WebSocket 和 HTTP 两个协议端口。
为什么只绑定本地地址?
安全。
你的 AI 助手不需要暴露在公网上。远程访问走 SSH 隧道或者 Tailscale 就行。
Gateway 内部结构
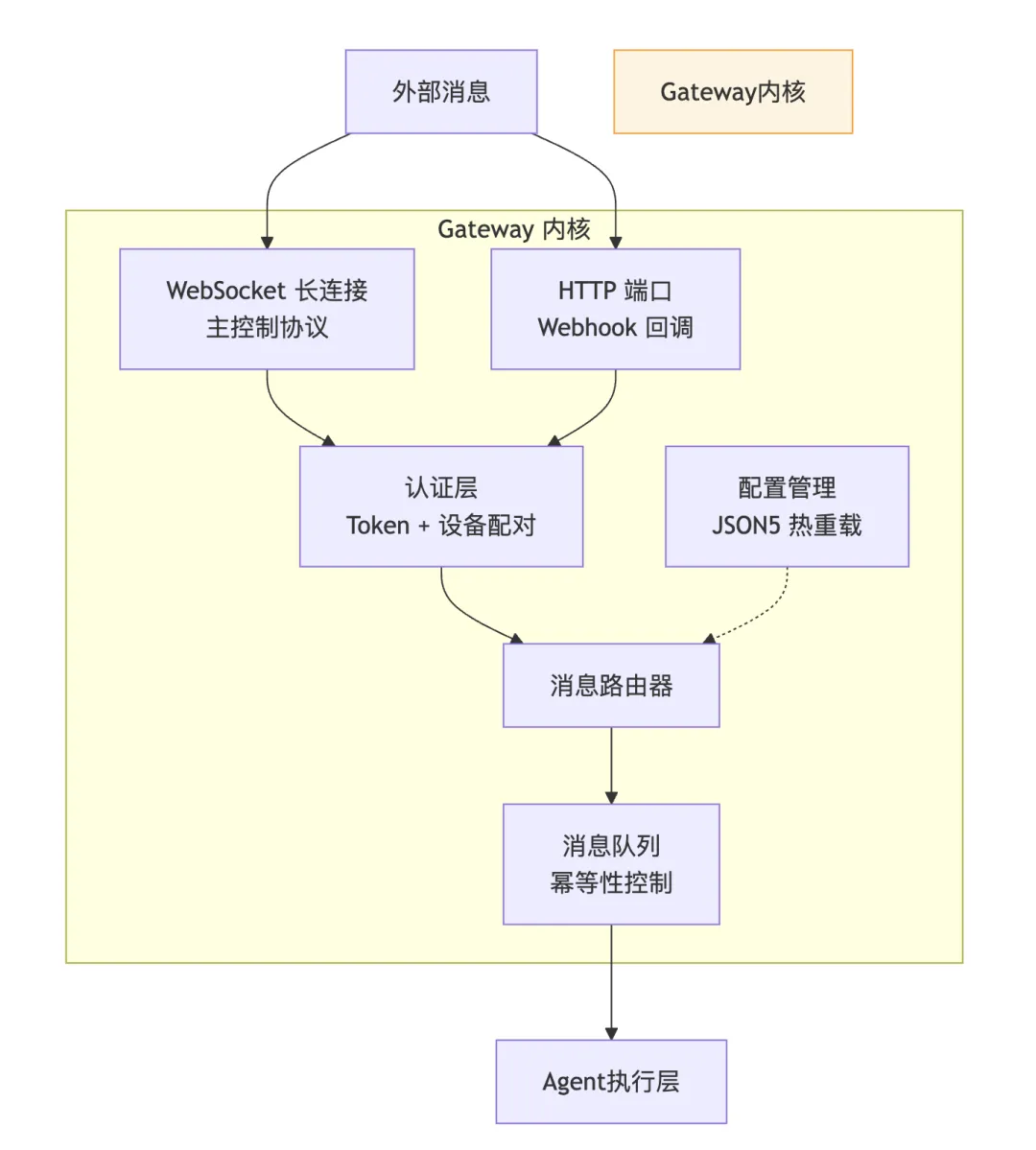
Gateway 的 WebSocket 协议分四层:
连接层——握手认证,Token 校验 协议层——帧结构校验,防止畸形请求 方法层——权限分发,不同角色能调用不同方法 事件层——流式广播,AI 的回复可以一段一段推过来
这里有个我觉得设计得聪明的地方:三道"总闸"机制。连接数限制、权限检查、带宽控制,三层保护叠在一起。不是说你连上了就能随便调,每一步都有门卡。
配置热重载也值得一提。改了 openclaw.json 不需要重启进程,Gateway 会监听文件变化并自动应用。在调试期间这省了不少事。
Channel 层:平台适配器
Channel 是 OpenClaw 对接外部聊天平台的适配层。目前内置支持 Telegram、WhatsApp、Discord、IRC、Google Chat、Slack、Signal,macOS 上还能用 iMessage。
每个 Channel 做的事情很直接:把各平台千奇百怪的消息格式统一成 OpenClaw 内部的 StandardMessage 格式。
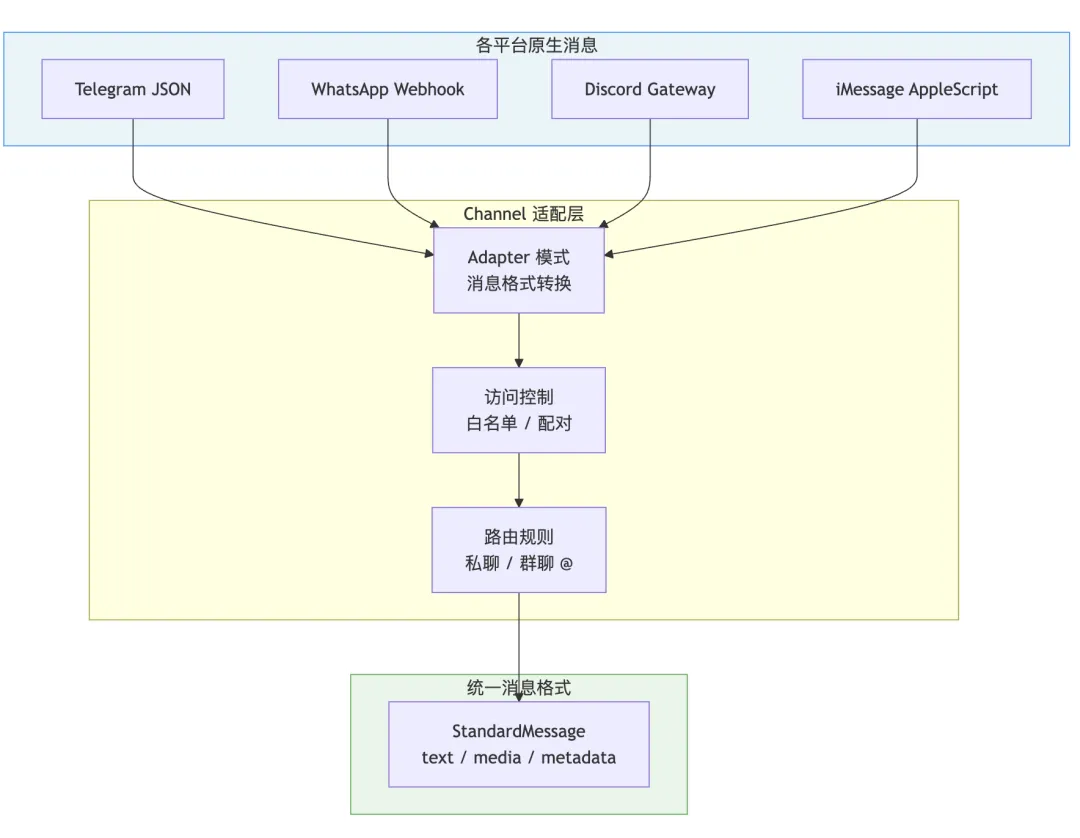
路由规则
消息到了 Channel 层,首先要过访问控制:
私聊:四种模式可选——配对(陌生人需要人工审批)、白名单、公开、关闭 群聊:默认只在被 @ 的时候才响应,不会主动刷屏
路由匹配有优先级,从精确到模糊:
peer 精确匹配 > parent peer > guild+roles > guild > team > account > channel > default同一通道还支持多个 accountId 独立运行。比如你可以在 Telegram 上跑两个机器人账号,各自的状态互不干扰,一个挂了另一个不受影响。
Agent 执行层:真正干活的地方
这是 OpenClaw 最复杂也最有意思的部分。一条消息通过 Gateway 和 Channel 到达 Agent 后,要经过一整条流水线才能变成回复。
消息处理的完整旅程
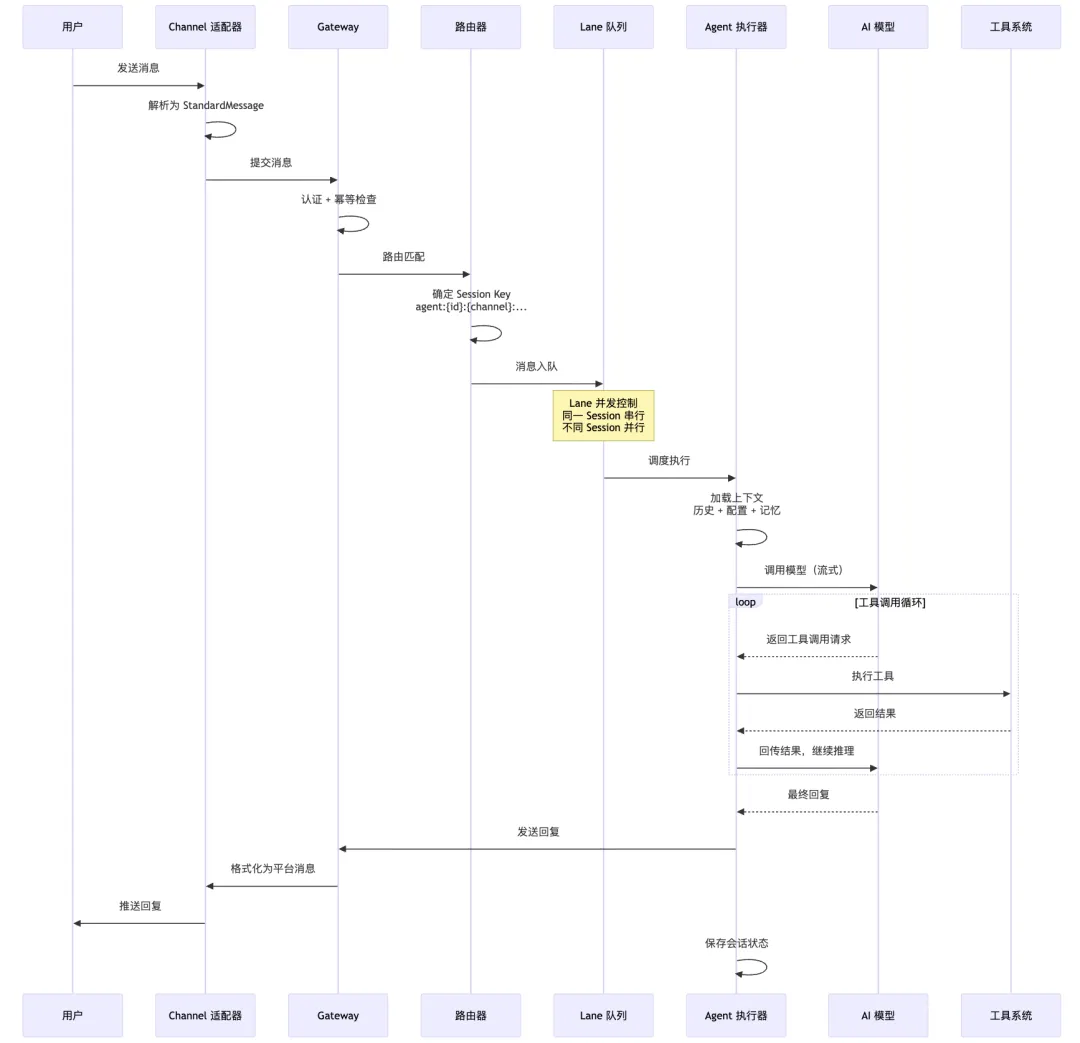
整个流程有 12 个步骤,我把几个关键环节拎出来细说。
Lane 并发模型
这是我觉得 OpenClaw 里最精巧的设计之一。
问题很现实:你在 Telegram 上问了个问题,AI 还在跑,你又发了一条新消息怎么办?10 个用户同时在不同平台发消息呢?
Lane 并发模型的处理策略:
Session Lane:每个会话有自己的队列,同一会话里的消息串行处理(不然上下文会乱) Global Lane:全局并发上限控制,防止同时跑太多请求把 API 额度打爆
队列模式有四种选择:
| 中断 | ||
| 追加 | ||
| 排队 | ||
| 合并 |
上下文组装
Agent 拿到消息后,第一件事是组装上下文。这个上下文不只是对话历史那么简单。
┌─── 系统提示词 ──────┐ ┌─── 动态上下文 ──────┐ ┌─── 会话上下文 ──────┐ │ │ │ │ │ │ │ AGENTS.md 核心指令 │ │ 技能文件(按需加载) │ │ 对话历史(含压缩) │ │ SOUL.md 人格设定 │ │ MEMORY.md 长期记忆 │ │ 会话状态/变量/标记 │ │ TOOLS.md 工具说明 │ │ 向量搜索 语义匹配 │ │ │ │ │ │ │ │ │ └────────┬────────────┘ └────────┬────────────┘ └────────┬────────────┘ │ │ │ └────────────────────────┼────────────────────────┘ ▼ ┌─────────────────────┐ │ 上下文合并 │ │ + Token 预检 │ └──────────┬──────────┘ │ Token 超限? ╱ ╲ 否 是 │ │ ▼ ▼ ┌──────────┐ ┌──────────────┐ │ 完整上下文│ │ 历史压缩 │ └──────────┘ │ 生成摘要替代 │ └──────┬───────┘ ▼ ┌──────────┐ │ 完整上下文│ └──────────┘提示词架构的组成:
AGENTS.md——核心指令,告诉 AI 它能做什么、不能做什么 SOUL.md——人格设定,决定 AI 的说话风格和价值观 TOOLS.md——工具备注,告诉 AI 有哪些工具可用
这三个是静态的。动态部分包括按需加载的技能文件、从 MEMORY.md 拉取的长期记忆,以及通过向量搜索找到的语义相关内容。
有个实际问题:这些东西加在一起很容易超出模型的上下文窗口。OpenClaw 的处理方式是先预检 Token 数量,超了就对历史对话做压缩——生成摘要替代原始记录。这个压缩是渐进的,不是一刀切。
工具调用循环
Agent 调用 LLM 后,模型可能不会直接给出文本回复,而是请求执行某个工具(查天气、读文件、跑命令等)。
这个循环的逻辑:
LLM 返回一个 tool_call 请求 Agent 判断这个工具是否需要人工审批 执行工具,拿到结果 把结果塞回上下文,再调一次 LLM 重复,直到 LLM 给出最终文本回复,或者达到最大迭代次数
最大迭代次数限制是个保险措施。万一模型陷入"调工具→看结果→再调工具"的死循环,到上限就强制停下来。
LLM Provider 层:模型无关的抽象
OpenClaw 不绑定任何特定模型。它定义了一个 LLMProvider 接口,所有模型供应商只要实现这个接口就能接入。
目前支持的模型主要有:Anthropic(Claude)、OpenAI(GPT)、Ollama(本地模型)、AWS Bedrock、Google Gemini 等。
┌──────────────────┐ │ Agent 执行器 │ └────────┬─────────┘ │ ▼ ┌──────────────────────────────┐ │ LLMProvider 统一接口 │ │ chat() / stream() │ │ supportTools() │ └──┬───┬───┬───┬───┬───┬──────┘ │ │ │ │ │ │ ┌──────┐ ┌┴┐ ┌┴┐ ┌┴┐ ┌┴┐ ┌┴┐ ┌┴──────┐ │Claude│ │G│ │O│ │B│ │G│ │自│ │ │ │ │ │P│ │l│ │e│ │e│ │定│ │ ... │ │Anthro│ │T│ │l│ │d│ │m│ │义│ │ │ │pic │ │ │ │a│ │r│ │i│ │ │ │ │ │ │ │4│ │m│ │o│ │n│ │P│ │ │ │ │ │o│ │a│ │c│ │i│ │r│ │ │ │ │ │ │ │ │ │k│ │ │ │o│ │ │ └──────┘ └─┘ └─┘ └─┘ └─┘ └──┘ └───────┘ │ ┌────────────┼────────────────────────┐ │ 容错机制 │ │ │ │ Auth Profile 轮换 ──▶ 故障转移 │ │ (多 Key 自动切换) (主备模型) │ │ │ │ │ 速率控制 │ │ (指数退避重试) │ └─────────────────────────────────────┘这层有个我觉得做得不错的容错设计:Auth Profile 轮换。你可以配多个 API Key,一个被限流了自动切下一个。更进一步,还支持主备模型切换——Claude 挂了自动切 GPT,用户那头感知不到。
2026 年初的重构把模型接入从硬编码改成了插件化。以前要加一个新的模型供应商得改核心代码,现在只需要写一个实现 LLMProvider 接口的插件,注册进去就完事了。
记忆系统:不只是存聊天记录
OpenClaw 的记忆系统分两层。
短期记忆是会话历史,采用追加式事件日志存储。时间长了会自动压缩,生成摘要替代原始记录,省 Token。
长期记忆才是有意思的部分。它基于 SQLite 加向量嵌入实现混合搜索:
记忆写入 记忆检索 ┌──────────────────────┐ ┌──────────────────────────┐ │ │ │ │ │ 新信息 │ │ 查询请求 │ │ ╱ ╲ │ │ ╱ ╲ │ │ ▼ ▼ │ │ ▼ ▼ │ │ ┌────────┐ ┌──────┐ │ │ ┌──────────┐ ┌────────┐ │ │ │向量嵌入│ │关键词│ │ │ │语义搜索 │ │关键词 │ │ │ │Embed │ │提取 │ │ │ │余弦相似度│ │匹配 │ │ │ └───┬────┘ └──┬───┘ │ │ └────┬─────┘ └───┬────┘ │ │ └────┬────┘ │ │ └─────┬─────┘ │ │ ▼ │ │ ▼ │ │ ┌────────────┐ │ │ ┌────────────────┐ │ │ │ SQLite │ │ ──────────────▶ │ │ 结果融合 │ │ │ │ 向量索引 │ │ │ │ 权重排序 │ │ │ └────────────┘ │ │ └───────┬────────┘ │ │ │ │ ▼ │ └─────────────────────┘ │ ┌──────────┐ │ │ │ 取 Top-K │ │ │ └──────────┘ │ └──────────────────────────┘语义搜索和关键词搜索并行跑,结果按权重排序后取 Top-K。这种混合方案比纯向量搜索靠谱——向量搜索对精确关键词(比如人名、项目编号)不太敏感,加上关键词匹配就补上了这个短板。
你也可以手动维护 MEMORY.md 这样的长期记忆文件,Agent 每次组装上下文时会去读取。
插件系统:五种扩展点
OpenClaw 支持在五个方向做扩展:
插件注册时有清单校验和冲突检测。两个插件要注册同名工具?系统会拦住,不会默默覆盖。
安全架构:加了多层防御,没有想象中那么不安全
安全这块 OpenClaw 确实花了心思。不是加个密码就完事,而是分了好几层:
┌─────────────────────────────────────────────────────┐│ 网络层 ││ 默认绑定 127.0.0.1(不暴露公网) ││ 远程访问走 SSH 隧道 / Tailscale │├─────────────────────────────────────────────────────┤│ 认证层 ││ Token 认证 · 设备配对(陌生设备需审批) ││ 角色权限:operator / node │├─────────────────────────────────────────────────────┤│ 执行层安全 ││ 工具审批:自动批准 / 需审批 / 禁止执行 ││ Docker 沙箱隔离 · 权限范围 read / write / admin │├─────────────────────────────────────────────────────┤│ 数据层 ││ 凭据文件权限 0600 · 审计日志(敏感操作留痕) ││ 数据本地存储,不经第三方 │└─────────────────────────────────────────────────────┘几个值得说的点:
工具审批机制有三档策略:自动批准(安全工具)、需要审批(bash 之类的危险操作)、禁止执行。不是所有工具都能直接跑的,用户可以按需配置。
沙箱隔离用 Docker 实现。主会话(通常是你自己在用)可以直接执行命令,但私聊和群聊里的命令默认跑在 Docker 容器里,即使被提示词注入攻击了也出不了沙箱。
凭据管理把 API Key 之类的敏感数据单独存储,文件权限锁死 0600(只有所有者能读写),不进版本控制。
部署:从笔记本到云服务器
OpenClaw 支持几种部署模式:
本地开发: npm start起来就能用,支持热更新,全量日志macOS 生产环境:菜单栏应用常驻,能用 iMessage 和语音唤醒 Linux 服务器:跑成 systemd 服务,通过 SSH 隧道或 Tailscale 连接 Docker 容器:一行命令拉起来,适合云平台部署
不管哪种方式,数据都在你自己的机器上。这个"本地优先"的设计决策贯穿了整个项目。
性能数据
引用一组来自社区的优化测试数据:
使用 Redis 替代内存队列 +
p-limit并发控制后:
100 并发下平均响应时间:8 秒 → 3 秒 失败率:15% → < 1%
数字本身不是重点。重点是 OpenClaw 的架构给优化留了足够的空间——你可以换存储引擎、调并发策略、加缓存层,不需要改核心逻辑。
我的看法
翻完 OpenClaw 的架构,我觉得它做对了几件事:
把 AI 模型和落地逻辑彻底分开了。 模型是模型,调度是调度,对接是对接。三层各管各的,换模型不用改调度,加平台不用碰模型。
安全不是事后补丁。 从网络绑定到沙箱隔离,从设备配对到审计日志,安全考虑渗透在每一层里。对于一个跑在个人设备上、能操作文件和执行命令的 AI 系统来说,这个态度是对的。
"本地优先"的取舍清醒。 放弃了云端的便捷性,换来数据完全可控。这个取舍不一定适合所有人,但至少是个清醒的选择而不是没想清楚。
当然也有不完美的地方。Node.js 单线程在高并发场景下有瓶颈,记忆系统的向量搜索精度还有提升空间,插件生态还在早期。但作为一个开源项目,这个架构底子够扎实,后面加东西不难。
参考资料
OpenClaw 官方中文文档 - 系统架构详解(https://openclaw-docs.dx3n.cn/tutorials/concepts/system-architecture) 一文彻底搞懂 OpenClaw 的架构设计与运行原理 - 博客园(https://www.cnblogs.com/tangshiye/p/19642495) OpenClaw 技术架构深度解析 - CSDN(https://blog.csdn.net/weixin_44262492/article/details/158936332) OpenClaw 架构深度解析:三层设计的技术原理与扩展实践 - 比邻(https://eastondev.com/blog/zh/posts/ai/20260205-openclaw-architecture-guide/) OpenClaw GitHub 源码仓库(https://github.com/nicekid1/OpenClaw)
