 夜雨聆风
夜雨聆风What's up, 大家!这是我的第 32 篇原创文章。
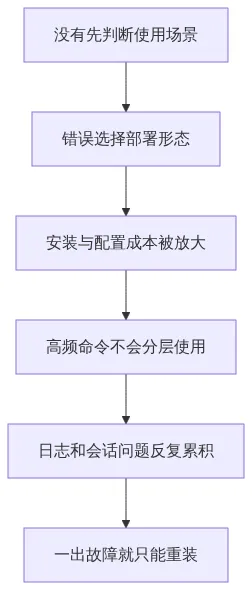
很多人第一次接触 OpenClaw,都会以为自己卡住是因为“不够会写命令”。真到现场才会发现,真正把人拦住的,往往不是能力不够,而是岔路太多。原版、本地桌面、云端托管、企业集成、移动端入口,每一种都像是正确答案,但每一种的代价又完全不同。
更麻烦的是,OpenClaw 不是那种“装完就永远不坏”的工具。你可能上午刚把模型和通道配通,下午就被 gateway、session、cron、授权、日志和版本差异打回原点。于是很多人不是不会用,而是没有一张“先怎么选,再怎么跑,坏了先救哪里”的图。
这篇我想做的,就是把最常见的三个痛点一次讲透:先帮你判断应该选哪种形态,再把高频命令压成最小闭环,最后给你一套出问题时的救援顺序。你不需要先背完整文档,先把这张速查图装进脑子里,实际落地时会轻松很多。
这件事到底卡人到什么程度
OpenClaw 的典型问题不是“有没有功能”,而是“同一个目标有太多实现方式”。如果你一开始没有分清自己属于哪类用户,后面所有配置动作都会被放大成返工成本。
| 场景 | 你以为的问题 | 实际卡点 | 直接后果 |
| 刚准备上手 | 不会命令 | 不知道该选原版、云端还是桌面端 | 一开始就选错形态,后面全部返工 |
| 已经装起来了 | 模型没配好 | gateway、通道、会话、日志之间没有最小排障顺序 | 问题越修越乱 |
| 想稳定长期用 | 只要能跑就行 | 没有 session、cron、日志、配置的维护意识 | 用得越久,越容易积累隐性故障 |
很多人会把这些问题拆开看,但它们其实是一条连续链路。你在第一步选错,第二步就会开始堆补丁;第二步没有最小闭环,第三步就会进入“明明能跑但总不稳”的状态。
再把这个问题放到真实使用节奏里看,会更直观:
| # | 阶段 | 常见动作 | 最容易踩的坑 | 结果 |
| 1 | 选型 | 看到哪个产品热就先装哪个 | 没先看自己是开发者、轻运维还是零折腾用户 | 入口选错 |
| 2 | 上手 | 一口气装环境、连模型、接通道 | 没有最小可运行闭环 | 问题定位困难 |
| 3 | 使用 | 新增会话、加定时、切模型 | 不知道哪些命令是核心,哪些是补充 | 系统越来越重 |
| 4 | 故障 | 看到报错就随意改配置 | 没有固定排障顺序 | 反复救不活 |
这也是为什么很多人觉得 OpenClaw“强是强,但不敢长期依赖”。问题不在于它不值得用,而在于你要先建立一套正确的使用节奏。
为什么大多数人总是卡在第一步
先把最常见的误判说透。
原因1:把“能不能装”当成了“适不适合我”
原版 OpenClaw 的自由度最高,适合愿意折腾、愿意理解系统边界的人;云端方案适合希望 7×24 小时在线、能接受轻运维的人;桌面化产品适合更在意图形界面、隐私和低学习门槛的人。问题在于,很多人只看“哪家现在最火”,不看自己的日常工作方式。
原因2:把“会几条命令”当成了“系统已经跑顺了”
你知道 gateway start 不等于你真的能长期稳定用。真正的闭环至少包括四件事:知道怎么启动、知道怎么看状态、知道怎么查日志、知道怎么清理卡住的 session。少一环,系统就只是“偶尔能跑”。
原因3:把“报错修复”当成了“日常维护”
OpenClaw 这种工具最怕的不是报一个大错,而是很多小问题长期堆着不处理。比如会话超长、定时任务失败、模型 key 失效、通道状态异常、配置被改乱。这些都不是重装就能真正解决的,它需要你有一个固定的排查顺序。
如果把三类人群和三种主要形态对照来看,这件事会更清楚:
| 用户类型 | 更适合的入口 | 为什么 | 不建议一开始选什么 |
| 开发者 / 重度折腾用户 | 原版本地 | 自由度最高,方便深改、接社区能力 | 过度封装的纯托管方案 |
| 轻运维 / 中小团队 | 云端托管或云服务器镜像 | 适合持续在线,稳定性和自由度更平衡 | 从零本地硬啃全部细节 |
| 不想太多折腾的日常办公用户 | 桌面化或入口整合产品 | 安装、配置、连接成本更低 | 直接冲原版并期待零学习成本 |
所以第一步不是“先装哪个”,而是“先承认自己的真实使用方式”。这一步一旦做对,后面的复杂度会直接下降一半。
真正有用的做法:先选对,再跑通,最后学会救
这一部分我只保留最值得反复使用的三组动作。
方法1:先用一张分流图选对形态
**操作流程:**判断场景 → 选部署形态 → 再做安装配置
你可以先问自己三个问题:
- 1. 我愿不愿意自己理解环境、模型和通道配置?
- 2. 我需不需要它长期在线,随时从外部入口调用?
- 3. 我更看重自由度,还是更看重马上能用?
如果你对前两个问题都回答“是”,原版或云端镜像更合适;如果你对第三个问题回答“马上能用”,就优先选桌面化或入口整合产品。不要反过来。
方法2:先建立最小命令闭环,再扩展能力
**操作流程:**安装初始化 → 启动网关 → 查看状态 → 看日志 → 再管理会话和定时任务
你一开始真正需要记住的,不是全部命令,而是下面这几组:
openclaw onboard
openclaw gateway start
openclaw gateway restart
openclaw status
openclaw logs --follow
openclaw sessions
openclaw sessions kill --all-subagents
openclaw cron list
openclaw config validate这段命令背后的逻辑很重要:
- •
onboard解决首次初始化。 - •
gateway start/restart解决运行态。 - •
status解决“它现在到底是不是活着”。 - •
logs --follow解决“它为什么不正常”。 - •
sessions和kill --all-subagents解决“是不是上下文卡死了”。 - •
cron list解决“是不是后台任务在拖系统后腿”。 - •
config validate解决“是不是配置本身就错了”。
方法3:故障时按固定顺序救,不要乱试
**操作流程:**看状态 → 看日志 → 清会话 → 校配置 → 再决定是否重启
真正救系统时,最怕边猜边改。建议把顺序固定成下面这样:
| # | 操作 | 说明 | 验证 |
| 1 | openclaw status | 先确认网关、通道、会话是否在线 | 能看到当前运行状态 |
| 2 | openclaw logs --follow | 找第一条关键报错,不要盲改 | 能定位异常来源 |
| 3 | openclaw sessions | 看是否有异常膨胀或卡住的会话 | 会话数量、状态清晰 |
| 4 | openclaw sessions kill --all-subagents | 清掉卡住的子代理会话 | 子代理状态恢复 |
| 5 | openclaw config validate | 排除配置层错误 | 配置校验通过 |
| 6 | openclaw gateway restart | 最后才重启,不要上来就重启 | 重启后状态恢复 |
如果你愿意把这 6 步做成肌肉记忆,OpenClaw 的“不可控感”会明显下降。很多问题并不是技术上多复杂,而是你每次都是从不同入口开始救,导致每次都像第一次排查。

我更建议你这样建立自己的 OpenClaw 使用习惯
如果你是第一次上手,不要追求一步到位,先完成三个目标就够了:
| 阶段 | 目标 | 标志 |
| 第一步 | 选对形态 | 你能说清自己为什么选原版、云端或桌面端 |
| 第二步 | 建最小闭环 | 你能独立完成启动、查状态、看日志 |
| 第三步 | 会固定救援 | 你知道出问题先查什么、后查什么 |
很多工具看起来难,是因为教程总喜欢从“全量能力”开始讲;但真正能把系统用稳的人,反而是先把最小闭环练熟,再慢慢扩展到更多通道、更多模型、更多自动化任务。
你完全可以把 OpenClaw 理解成一个分层系统:
- • 选型层,决定你走哪条路。
- • 运行层,决定它能不能稳定跑。
- • 维护层,决定它能不能越用越顺。
只盯选型,不会维护,后面一定崩;只会维护,但一开始形态选错,后面也会一直痛苦。真正省时间的方法,从来不是多背几条命令,而是先把顺序排对。
如果你现在就卡在“到底该选哪个版本”这一步,我的建议很简单:先别想着追最全功能,先选那个最接近你日常工作方式的形态。把最小闭环跑通之后,再决定要不要继续往更自由、更复杂的方向升级。
OpenClaw 不是不能学会,只是它不适合用“先乱装,再靠运气修”的方式学。顺序一对,难度会立刻降下来。
