 夜雨聆风
夜雨聆风万万没想到,用了一年的 Mac Mini M4 居然涨价了。
最近我以 3800 元的价格处理掉了手头的 Mac Mini M4。离谱的不是卖机,而是价格——3800元成交。要知道这机子我去年入手时才 3500 元(最低时一度能做到 2900 )。合着我白用了 一 整年,临了不仅没亏,还反向“白嫖”了 300 块?这年头,电子产品居然成了理财产品。
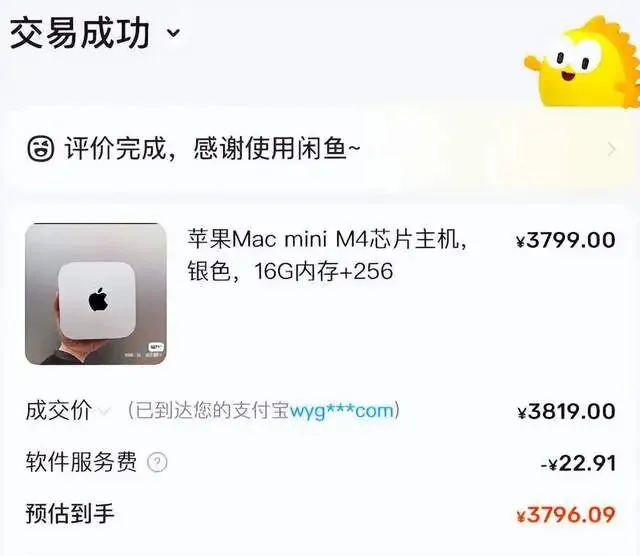
至于这波溢价的“元凶”,懂行的朋友估计都猜到了:小龙虾(OpenClaw) 彻底火出圈了。M4 芯片那恐怖的本地算力,加上巴掌大的体积,简直是 OpenClaw 的天选载体。现在各大平台不仅全面涨价,发货甚至要等上一个半月。

出掉 Mac 后,我本想用手头的迷你主机自己动手搭个环境,结果发现零刻(Beelink)这波动作更快,直接针对 OpenClaw 出了一套全家桶。不仅有红黑配色的定制款主机,还贴心地出了个 OpenClaw 专用 SSD 升级包,插上就能双系统启动。既然有这种“喂到嘴边”的懒人方案,我也就不费劲折腾了,直接入手 SSD,开整!

话说,零刻这次的龙虾红是超级火啊,连 OpenClaw 创始人都在线求机
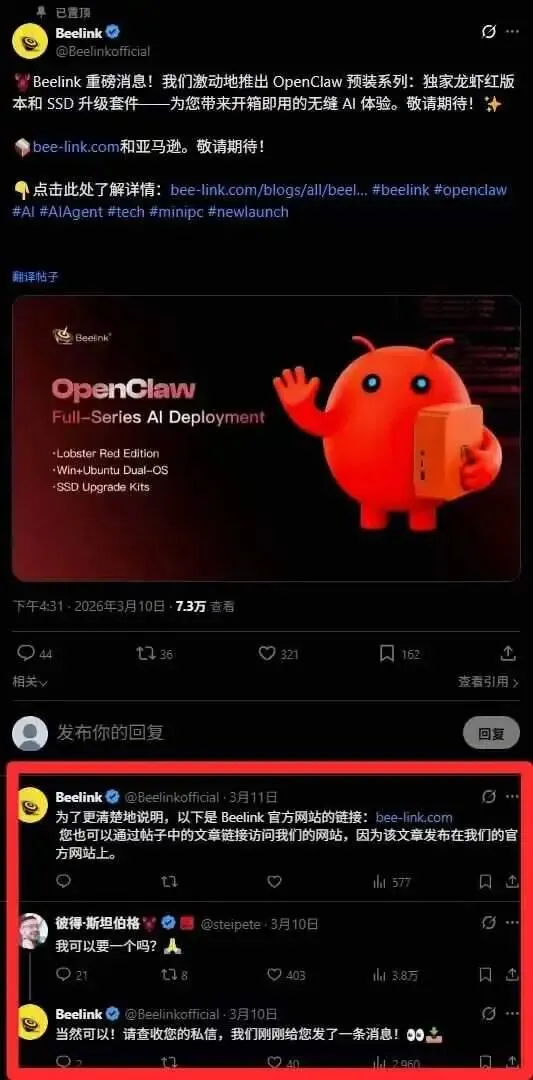
零刻 GTi15 Ultra + OpenClaw固态升级包
▼先来看看这次的设备 零刻 GTi15 Ultra , 处理器是 Intel 酷睿 Ultra 9 285H ,拥有 16 核 16 线程的强大规格,内部集成了独显架构的 Arc 140T 核显与独立 NPU,构成了高达 99 TOPS 的 AI 算力矩阵。
▼这货最强大的地方就是灵活,40Gbps 雷电 4 配合双万兆网口,生产力属性直接拉满。而且这货也支持外接显卡坞。
重点:它走的是物理直连架构,不仅性能损耗极低(<5%),而且不占用宝贵的雷电口。无论是跑本地大型 AI 模型还是 3A 游戏,上限都远超 Mac Mini。

▼零刻 OpenClaw 固态升级包,大红龙虾高高挂,识别度很高。
选它的理由很简单:拒绝折腾。官方预装好的 Ubuntu 环境和 OpenClaw 平台,真正做到了“开箱即用”。即便以后不玩 OpenClaw 了,格式化就是块高性能 SSD。最香的是,我手里零刻主机多,这块盘基本通杀,灵活度极高。

▼看看型号,这次用的是长江存储 PC41Q,基于晶栈®Xtacking®3.0 技术打造的主流级别 PCIe 4.0 SSD 产品,读写都在 5500MB/s 以上。
这货最大的亮点其实是能效比,高达 1.75MB/s/mW。这意味着它在高速运行模型时不仅发热更低,也更稳定,150TBW 的寿命对于模型存储来说也绰绰有余。

▼零刻 GTi15 Ultra 提供了两条 PCIe 4.0 X 4 M.2 SSD,这里直接插上即可,想了解这机器内部架构的话可以参考之前的拆解文章。

OpenClaw 配置、 Ollama 以及微信对接
▼ 插入 SSD 启动主机,只需快速点按键盘上的 F7 键,屏幕就会跳出系统选择界面,这时候直接选中 Ubuntu 即可开整。不过既然是为了 OpenClaw 来的,我建议直接进 Enter Setup 把开机引导默认改到 Ubuntu。这样除了偶尔回 Win 办个公,平时完全可以把它当成一台纯粹的 AI 工作站来用。
▼ 正常进入系统,系统版本 2026.3.10 LTS。

▼系统内置的 OpenClaw 说明书,从初始化都云端配置都给出了详细步骤,建议使用前了解下。
▼先查看下版本号,我这块盘预装的是 2026.2.25 的版本,利用 openclaw updata 指令将其升级到最新稳定版
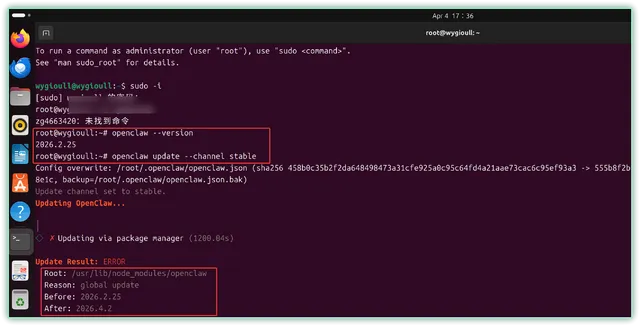
▼接着输入“openclaw onboard --install-daemon”开启交互配置
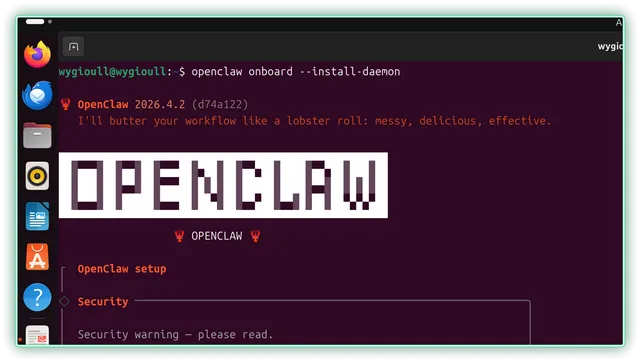
▼具体配置过程跟随向导或者说明书即可
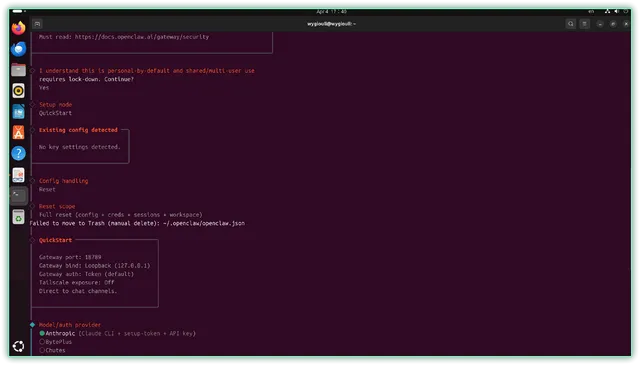
▼大模型选择
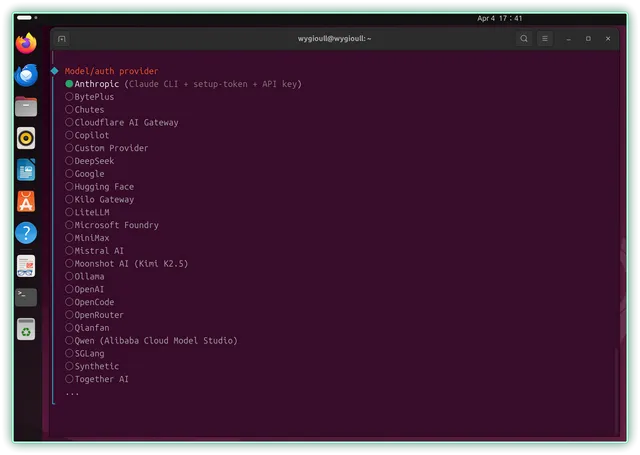
▼技能选择
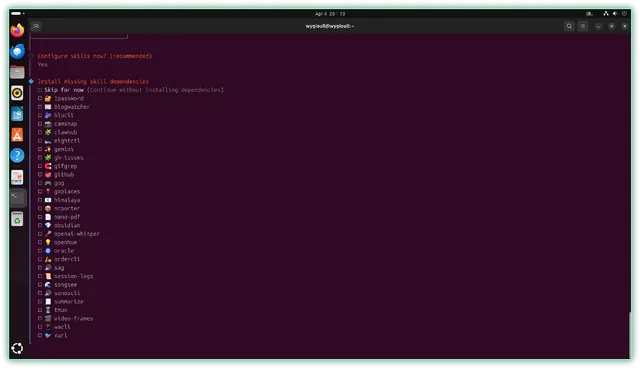
▼最后选择图示链接就能启动 OpenClaw 的 Web UI 界面
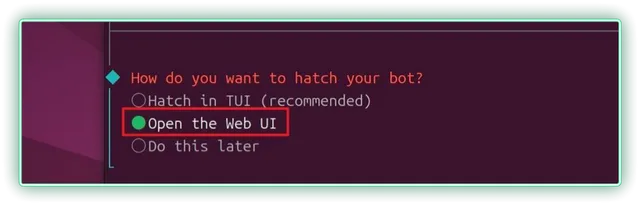
▼直接就能进行对话和操作了
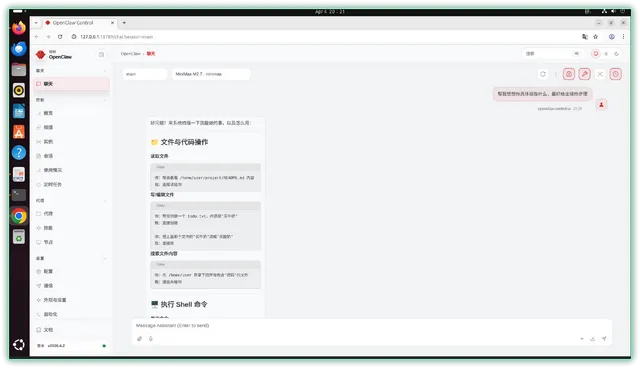
▼玩 OpenClaw 可能最让人抓狂的就是用不起模型,好在 GTi15 Ultra 本身就具备不错的 AI 性能,我也不打算让它干太复杂的内容。所以这里我是直接在本机跑 Ollama ,直接用官网命令进行拉取。
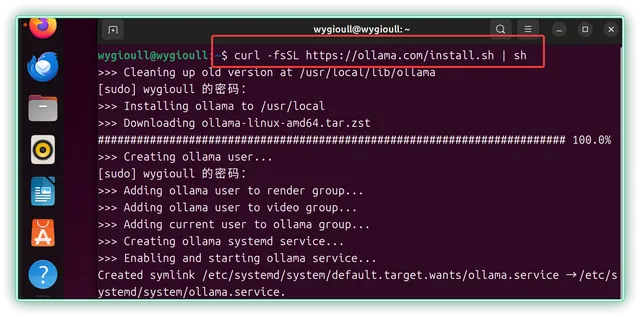
▼看了看,拉取的版本是 0.20.2
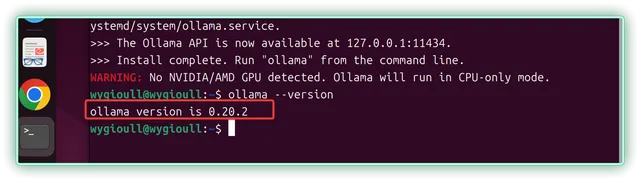
▼模型拉取 Qwen2.5-7b ,这是阿里通义家族首个端到端全模态大模型,基于 Transformer 架构的预训练,模型支持最长 131k tokens 上下文,可处理文本、图像、音频、视频等多模态输入,并实时生成文本与自然语言应答,
PS:零刻 GTi15 Ultra还有个优势,如果需要更高精度的模型,可以外接显卡坞来进行强化。
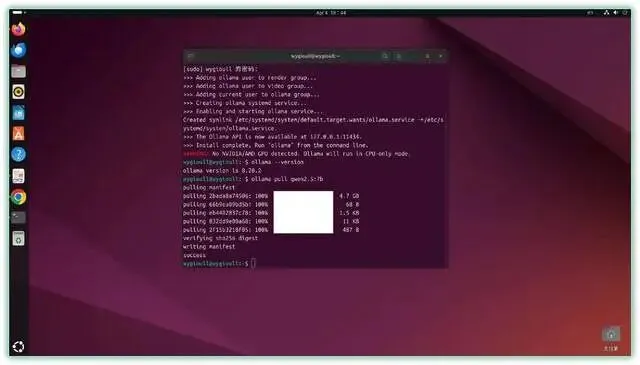
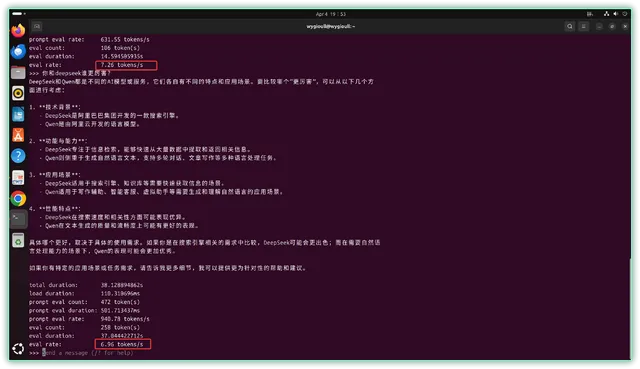
▼部署好之后简单测试下,输出速度 7tokens/s 左右。速度 一 般,胜在本地运行不需要 tokens ,性价比不错。
▼需要注意,零刻只预装了 FireFox 浏览器,有时候会遇到 OpenClaw 在最后步骤弹不出网页的问题,助手也无法浏览网页、截图、搜索信息, 运行 “openclaw browser status ”显示 “false”

▼最简单的方法就是重新安装 Chrome,控制台输入下列命令下载浏览器
wget
https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
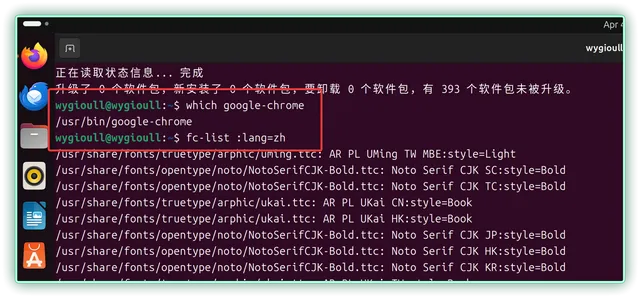
▼验证安装以及中文字体
▼配置 OpenClaw
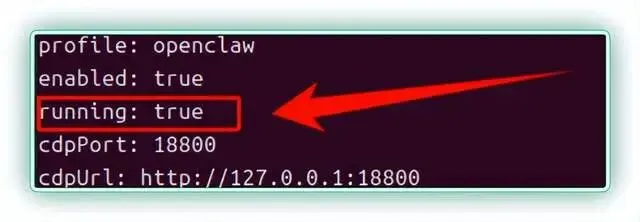
▼最后重启并验证,看到 “running: true” 就代表配置成功
▼想把 OpenClaw 接入微信?操作也很简单,首先把微信升级到最新版本,然后设置 → 插件 → 微信 ClawBot → 点详情,就能看到安装命令了
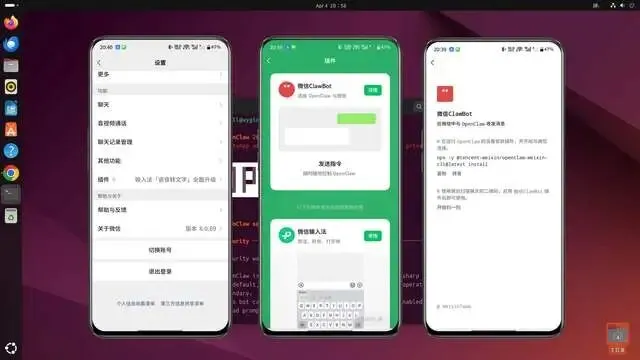
▼这里有个小坑,如果你用的 OpenClaw 是最新版本,直接复制命令会安装失败,原因是微信 ClawBot 插件与新架构不再兼容,不过解决起来也很简单,删掉后面的 latest 即可,见图
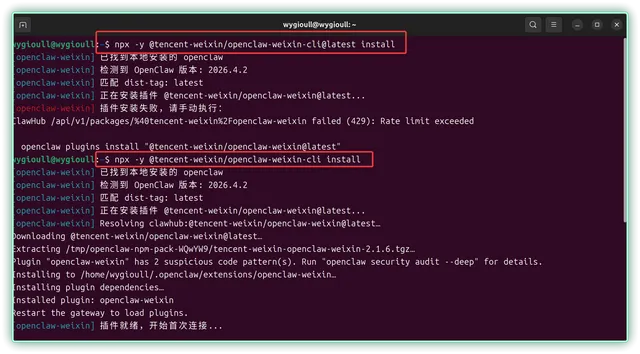
▼安装完成弹出二维码,微信扫码即可。微信端多出机器人,可以和它进行对话和安排任务了。
其他几种预装 OpenClaw 的机型
这一路操作下来,不得不说零刻这套 OpenClaw 预装策略确实“稳准狠”。它解决了玩小龙虾落地最难的一环——环境部署。
众所周知,现在现在网上帮人远程部署 一 次 OpenClaw,服务费动辄就是 500 甚至 1000 大洋。对比之下,零刻这种直接把环境喂到嘴里的做法,不仅是实用,更是实打实地帮咱们省下了一笔巨额“智商税”。
另外,我去官网瞅了一眼,零刻这波考虑得挺周全。除了能让老用户重焕新生的 OpenClaw 预装 SSD,新机器的玩法和配置组合也相当丰富,各种预算都能找到对应的坑位。
像主流价位的 SER9 Pro HX370,它搭载 12 核 24 线程的 AMD AI Max + 370 处理器,搭配 AMD Radeon 890M 核显,整机可以提供 80 TOPS 算力,而高端的 GTR Pro AMD AI MAX+ 395,单机 AI 总算力可以达到 126Tops,核显可以媲美移动版 RTX 4070,在推理 LM Studio Qwen70B Q5 大模型时,速度可达约 4.24 tokens/s,真正的把安全和速度双拿捏。
核心优势: 真正的离线运行。得益于顶级的本地算力,所有对话与推理都在机端完成。不仅彻底免去了云端 Token 费用,更从物理层面杜绝了数据外泄。

如果预算不足可以看看 SER9 Pro 255 这类机型,这类机型主打高性价比,核心优势丰俭由人,预装系统通过 OpenClaw 无缝对接国内外主流模型(如千问、GPT-4o、Gemini 等),通过云端算力快速构建智能工作流。

想玩 Win + Ubuntu 双系统话,可以看看 GTR9 Pro、SER10 MAX 等高性能系列。
这系列堪称鱼和熊掌兼得。开机即可在 Windows 办公环境与 Ubuntu AI 部署环境之间自由切换,一套硬件满足两套截然不同的工作流。

