 夜雨聆风
夜雨聆风导读: 你有没有注意到,用AI工具时,总有一个词频繁出现——Token(词元)。它决定了你能问多长的问题、AI能回多长的答案,甚至决定了你的使用费用。今天,我们用最通俗的语言,彻底讲清楚Token究竟是什么。
一、Token 到底是什么?
你跟ChatGPT、DeepSeek或文心一言对话时,你打出去的每一个字,AI都"看不懂"。
这是因为——计算机只认识数字,不认识文字。
当我们输入"你好世界"这样的文本时,模型需要把它转换成数字才能处理。这个转换过程就需要用到 Tokenizer(分词器),它的作用就是把人类的文本转换成模型能理解的数字ID序列:文本输入 → Tokenizer处理 → Token ID序列 → 模型处理。
而这个被拆出来的最小语言单位,就是 Token(词元)。
在人工智能 AIGC 领域,"Token"通常是指"词元",它是语言类模型中用数字来表示单词的最小语义单位。
简单来说,Token 就是AI眼中的"文字乐高块",是AI理解文本的最小单位,就像人类阅读时自动拆分的"信息颗粒",AI不是按字而是按token处理文本。

二、Token 是怎么切分的?
理解了Token是什么,我们再来看看它是怎么被切出来的。
🔹 英文是怎么切的?
Token 是最小单位的"词元",就是不可再拆分的最小语义单位。比如 "waterfall",会被拆成2个 Token:water、fall。另外,标点符号也会被定义为 token,比如"I don't know."可以分解为5个Token,分别是:" I "、"don"、" 't" 、"know"、"."。
一个 token 可能代表是一个单词,也可能是一个词组,或者字符和标点符号。比如 "New York City" 这三个单词可能被当做一个 token,因为它们合在一起具有特定的意思"纽约市";而 "debug" 这个单词可能被看作两个 token,分别为"de"和"bug",这样模型可能知道"de"前缀代表"减少"的意思。
🔹 中文是怎么切的?
中文、日语等语言没有明显的单词边界,需要用一些规则或统计模型来判断哪些字或字组合构成了一个有意义的token。例如,"我爱你"这个句子可以被分割成两个token:"我"和"爱你"。当然,这种方法并不完美,有时候会出现错误或者歧义。
一个直观的数量感知:对于英文文本,1个token大约是4个字符或0.75个单词,也就是1000个Token约等于750个英文单词;对于中文,1000个Token通常等于400~500个汉字。
🔹 主流算法:BPE 是什么?
目前大多数大模型使用的是一种叫 BPE(字节对编码)的算法来切分Token。
GPT系列采用了一种叫做Byte Pair Encoding(BPE)的子词划分方法。BPE是一种基于数据压缩原理的算法,它可以根据语料库中出现频率最高的字节对(byte pair)来合并字节,从而生成新的字节。这个过程可以重复进行,直到达到预设的字节总数或者没有更多的字节对可以合并为止。
三、Token 是如何让 AI"理解"语言的?
光把文字拆成数字ID还不够,AI还需要真正"理解"这些Token之间的关系。这里就要引入一个关键概念:Embedding(嵌入)。
嵌入就是把每个子词用一个特征向量来表示,这个特征向量可以反映出子词的含义、用法、情感等方面的信息。GPT只需要基于互联网上大量的文本资料,统计出两个词语在相邻/句子/文章中共同出现的概率并通过权重来汇总计算,就能分析出某个词语与另外一个词语的亲密度。
通过嵌入,我们可以把每个子词看作是高维空间中的一个点,而这些点之间的距离和方向,就可以表示出子词之间的相似度和差异度。比如,"猫"和"狗"的点因为同为宠物,可能会比较接近,而"猫"和"牛"的点可能会比较远离。
整个流程总结如下:
用户输入文字
↓
Tokenizer 分词(文字 → Token)
↓
Token 转为数字ID
↓
Embedding 转为高维向量
↓
神经网络进行理解与推理
↓
输出Token → 解码为文字 → 你看到的回答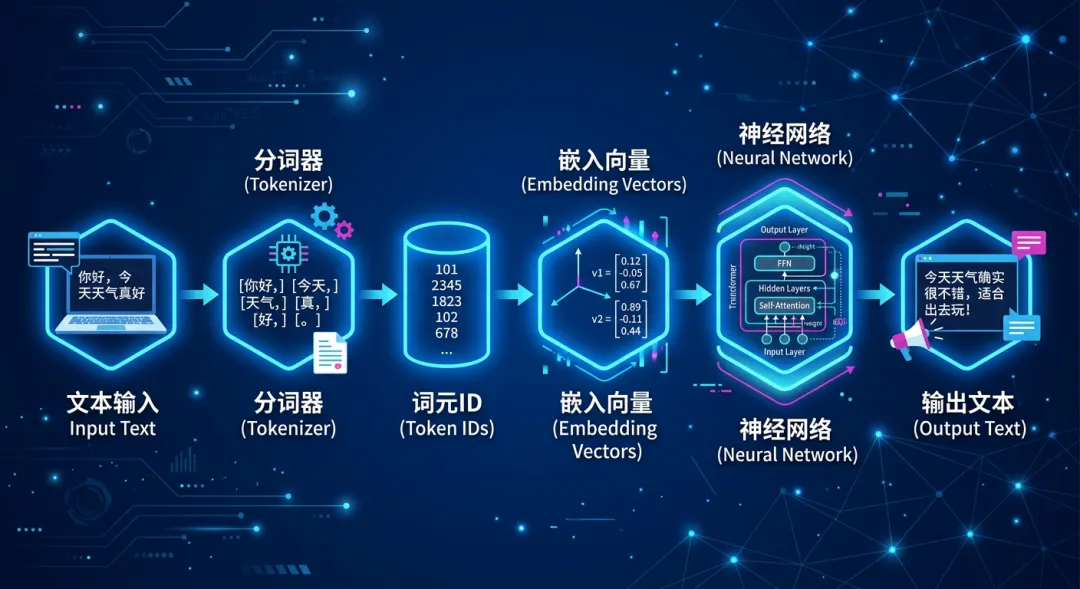
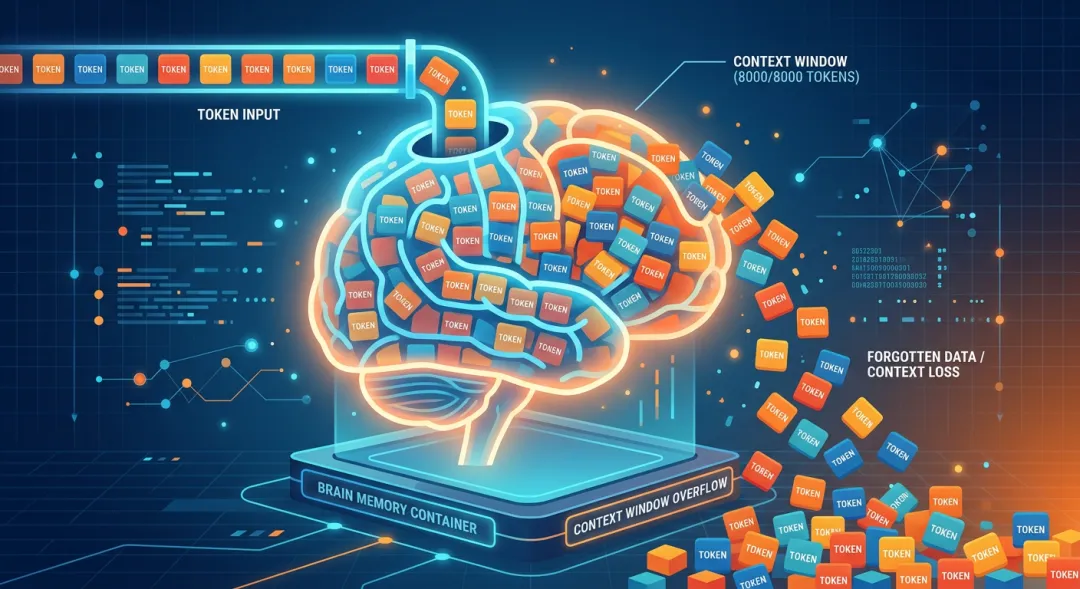
四、Token 与上下文窗口:AI的"记忆容量"
你有没有发现,跟AI聊了很久之后,它会"忘记"前面说过的话?这就跟Token密切相关。
每个大语言模型都有"上下文窗口大小"(Context Window)的限制。常见的上下文窗口例如:4k Tokens(如OpenAI GPT-3.5);8k、32k Tokens(如GPT-4或其他支持长上下文的模型)。超过上下文窗口大小的内容会被截断或需要人工实现"摘要化"。
上下文一般包含:用户的历史输入、模型的历史回复、系统提示(如设定聊天机器人的角色或目标等)。上下文越长,Token数量就越多。
举个例子,随着对话越来越长,Token消耗是这样叠加的:
第1轮:50(输入)+ 100(输出)= 150 Token
第2轮:50(新输入)+ 100(新输出)+ 150(历史)= 300 Token
第3轮:50 + 100 + 300 = 450 Token……以此类推。
这就是为什么长对话后AI会变得"健忘"——它的上下文窗口被填满了!
五、Token 与计费:你的每分钱都花在哪里?
在使用各类AI API时(如GPT-4、Claude、DeepSeek等),Token 就是计费单位。
AI模型对每次处理的Token数量有限制,很多AI平台按Tokens数量收费,比如输入和输出的Tokens总和决定了使用成本。模型通过Tokens来"理解"文本,Token化方式直接影响模型的性能和效果。
通常在API计费时会谈到"百万Token",也就是1M Tokens = 1,000,000 Tokens。如果是中文,每百万Token大约相当于70-100万个汉字;如果是英文,每百万Token大约相当于50-75万个单词。
因此,学会"省Token"既能降低成本,也能让AI回答更精准:
优化Token使用的常规策略包括:精简输入内容,使用简洁的问题或命令,去除多余的背景信息,确保用户输入内容的简洁明了,只包含核心问题或需求,避免包含无关或重复信息。
一句话技巧:把需求说清楚、说短,把重点放在前面,让AI一眼就能抓住关键。
六、Token 的未来:不只是文字
Token 的边界正在快速扩展。跨模态扩展方面,图片、音频正被Token化(如DALL·E将图像转为1024 Token序列)。同时,Google实验证明,统一Token化文本、图像、坐标数据,使AI具备跨任务能力。
未来,万物皆可Token——图像、音频、视频、代码、甚至人类的行为动作,都将被转化为AI可理解的"乐高积木",拼出一个更智能的世界。

🧩 总结:一张图记住Token
| 是什么 | |
| 英文换算 | |
| 中文换算 | |
| 切分方法 | |
| 核心作用 | |
| 上下文窗口 | |
| 计费单位 |
💡 一句话总结:Token,就是AI眼中的世界最小单元。读懂Token,你就读懂了AI的语言逻辑。
