 夜雨聆风
夜雨聆风
这是一篇被迫迁移的踩坑实录,也是一次"被迫重构"带来的意外升级。
故事线:从被迫断供到顺利迁移
第一阶段:自建系统跑了一个月,很爽
我是数据分析师,日常就是写 SQL、跑数仓、做周报、搞 AB 实验。之前我搭了一套叫 openclaw 的 AI 助手系统,底层接 Claude API。
核心思路很简单:给 AI 写一套完整的"灵魂文件"——身份定义、工作原则、工具配置、记忆系统——让它每次醒来都能快速进入状态。
跑了一个多月,积累了 30 个 skill、50+ 张数据字典、100+ 条 SQL 模板。周报从 2 小时压到 20 分钟,AB 实验分析从手动拼 SQL 变成一句话出报告。
系统已经进入了"复利期"——知识越积越多,AI 越来越好用。
第二阶段:Claude 改政策,被迫断供
然后 Anthropic 更新了订阅政策:不再允许第三方 wrapper 直接连接 Claude 的订阅套餐。openclaw 作为第三方工具,一夜之间接不上 Claude 了。
要么走官方 API 按量付费(算了下成本翻好几倍),要么换模型。
第三阶段:换 GPT,发现跑不通
我第一反应是换模型——openclaw 的架构本身是模型无关的,换个 API endpoint 就行。于是接上了 GPT。
结果很糟糕。
之前在 Claude 上跑得好好的周报流程和分析报告流程,GPT 经常在某一步就卡住。比如一个周报 skill 需要连续调用 5-6 个工具(查数据 - 填表 - 截图校验 - 写归因 - 发消息),GPT 跑到第 3 步就开始"偷懒":
"接下来你可以手动完成剩余步骤" "以下是建议的操作方案:1. xxx 2. xxx"——给了方案但就是不执行 说要去干,结果没去干
这不是 prompt 写得不好的问题。同一套 skill、同一套 CLAUDE.md(我当时叫 SOUL.md),Claude 能老老实实从第 1 步跑到第 10 步,GPT 跑到中间就倾向于"总结一下然后交给你"。
对于数据分析这种工具调用密集、步骤多、每步有依赖关系的工作,模型在长链路任务上的执行力差异是决定性的。
第四阶段:迁移到 Claude Code,意外顺利
GPT 跑不通,API 按量付费太贵,那就只剩一条路:迁到 Claude Code。
Claude Code 的 Max 订阅包含足够用量,还原生支持 skills、auto memory、MCP server——这些我之前在 openclaw 里自己造轮子实现的功能,Claude Code 直接就有。
抱着"估计要改一堆东西"的心理预期开始迁移,结果发现:迁移成本极低,大部分资产直接搬过来就能用。
迁移了什么,怎么迁的
资产总览
灵魂文件:三合一
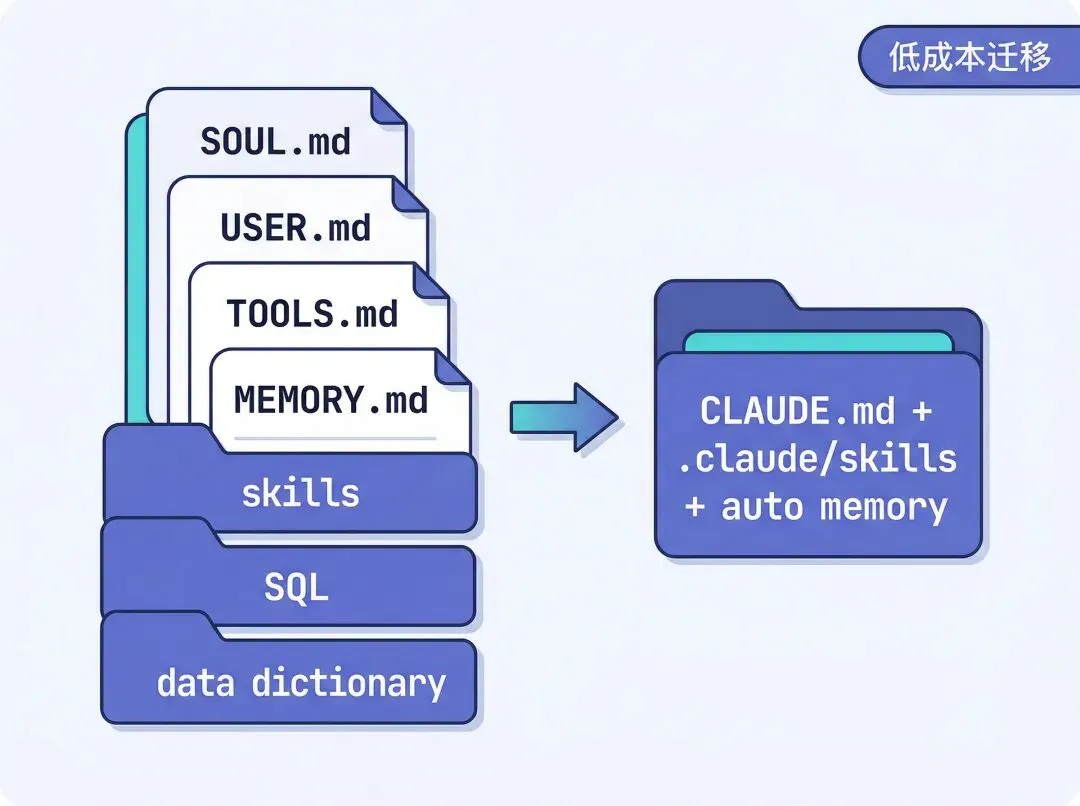
openclaw 里分了好几个文件:
SOUL.md——身份定义、工作原则、安全底线USER.md——用户信息、沟通偏好IDENTITY.md——角色设定TOOLS.md——工具速查表
Claude Code 只认一个 CLAUDE.md。合并过程就是把这几个文件拼在一起,删掉重复内容,调整一下结构。300 多行搞定。
最大的收获是:被迫合并反而逼我审视了哪些内容真的有用。原来散在四个文件里的规则,有不少是重复或过时的,合并时一并清理了。
顺手补一个"业界共识"背书:Karpathy 在讲 LLM Wiki 的时候,把 Schema 文件定义为最关键的一层——对 Claude Code 来说就是
CLAUDE.md。它的作用不是"说明书",而是让 LLM 从"聊天机器人"变成"有纪律的执行者"的控制面。
Skills:直接搬
openclaw 的 skill 就是 markdown 文件,Claude Code 的 skill 也是 markdown 文件,格式几乎一样。把目录从 ~/.openclaw/skills/ 搬到 .claude/skills/,done。
之前在 GPT 上跑不通的 skill,搬到 Claude Code 上直接就能跑通了。同一份 skill 文件,换个运行时就从"卡在第 3 步"变成"一路跑完"。
这再次验证了:问题不在 skill 写得不好,在模型执行力 + 运行时机制。
记忆系统:适配 auto memory
openclaw 的记忆是 MEMORY.md(长期记忆索引)+ memory/*.md(按主题/日期的明细文件),每次 session 手动加载。
Claude Code 有原生的 auto memory,格式是带 frontmatter 的 markdown 文件 + MEMORY.md 索引。我把原来的记忆文件加上 frontmatter(name、description、type),索引格式微调一下就迁完了。
好处是 Claude Code 的 auto memory 每次自动加载索引,不需要在 SOUL.md 里写"启动时先读 MEMORY.md"这种指令了。
工具集成:MCP 替代自定义配置
openclaw 的工具集成是自定义 JSON 配置,每个工具写一段配置告诉 AI 怎么调用。Claude Code 用 MCP server,标准化程度更高。
已有的 MCP server(比如微信公众号发文用的 wenyan-mcp)直接在 .claude/settings.json 里配上就行。内部数据平台这种没有现成 MCP 的,还是走 Chrome CDP + 脚本,但脚本本身不需要改。
Claude Code 连接 IM:cc-connect 方案
迁移到 Claude Code 之后最大的体验降级是:以前在 IM 里直接给 bot 发消息就能驱动 AI 干活,现在必须坐在电脑前开终端。
我找了一个开源方案 cc-connect 解决这个问题。
架构
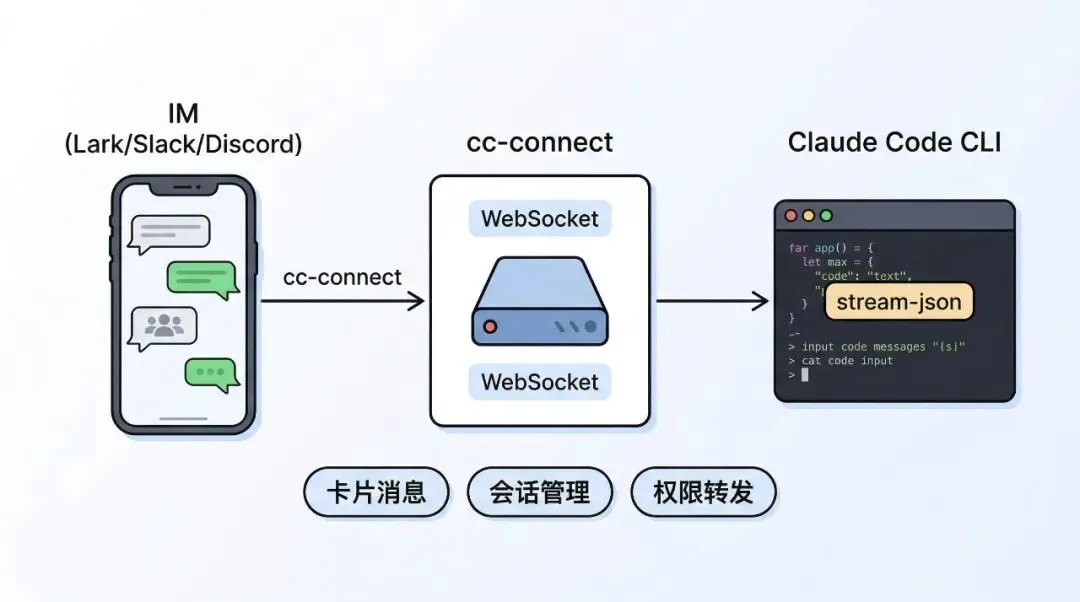
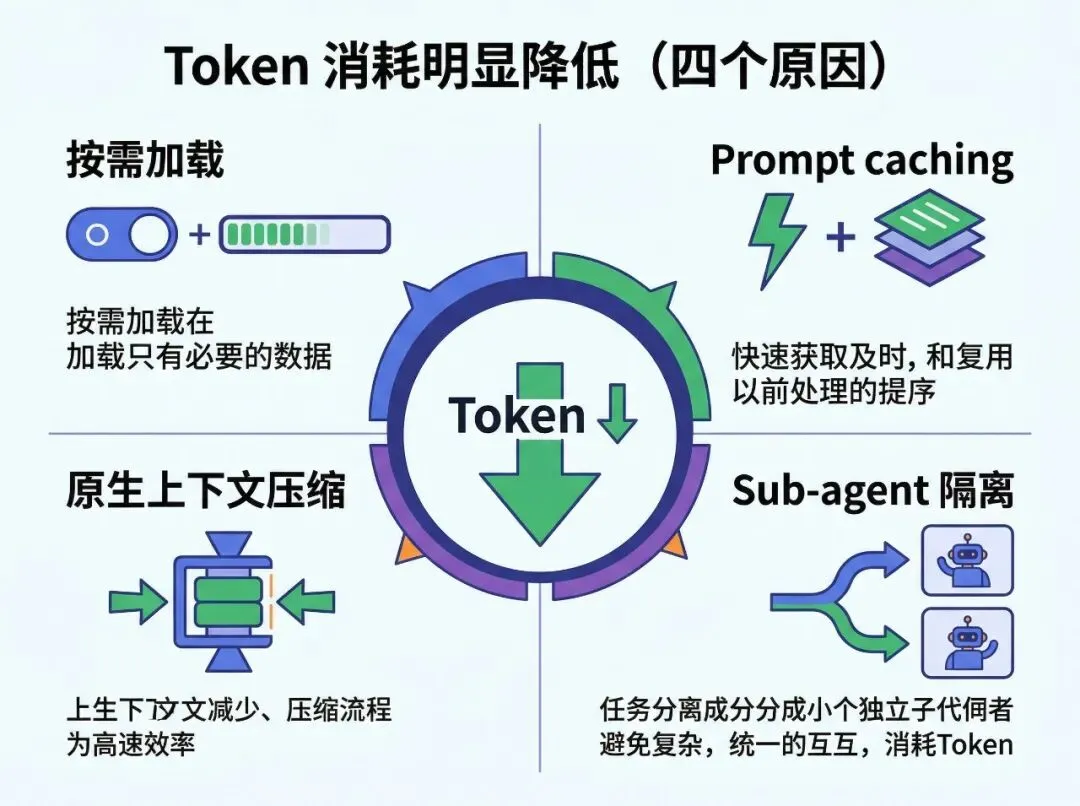
Go 写的桥接服务,把 Claude Code 的 stdin/stdout 接到 IM 平台。不需要公网 IP,不需要 Webhook 服务器——用 WebSocket 长连接。
核心能力:
卡片消息:Claude 的工具调用、权限请求都以交互式卡片展示,可以直接点按钮审批 会话管理:每个用户独立 session,上下文隔离 权限转发:Claude Code 需要审批的操作(执行 Bash、写文件等),转发到 IM 让你点允许/拒绝
配置
安装:
go install github.com/chenhg5/cc-connect@latest在 IM 开放平台创建 bot 应用,拿到 app_id 和 app_secret
写配置
~/.cc-connect/config.toml:
language = "zh"[[projects]]name = "my-workspace"[projects.agent]type = "claudecode"[projects.agent.options]mode = "default"work_dir = "/path/to/your/workspace"[[projects.platforms]]type = "feishu"# 也支持 slack、discord[projects.platforms.options]app_id = "cli_xxx"app_secret = "xxx"enable_feishu_card = trueprogress_style = "card"启动:
cc-connect关键一步:在 IM 开放平台,消息卡片 - 卡片回调设置里选择"使用长连接接收"。不配这一步,点卡片按钮会报错。
踩过的坑
200340 错误:点卡片按钮没反应。根因就是上面说的卡片回调没配长连接。 progress_style 取值:只支持 legacy(纯文本)、compact(紧凑卡片)、card(完整卡片),填别的启动直接报错。权限:bot 应用需要开通消息发送和卡片创建相关权限。
配好之后,手机上给 bot 发消息就能驱动本地 Claude Code。出门在外也能让 AI 跑数据、查信息、写报告。
迁移后的意外收获
Token 消耗明显降低
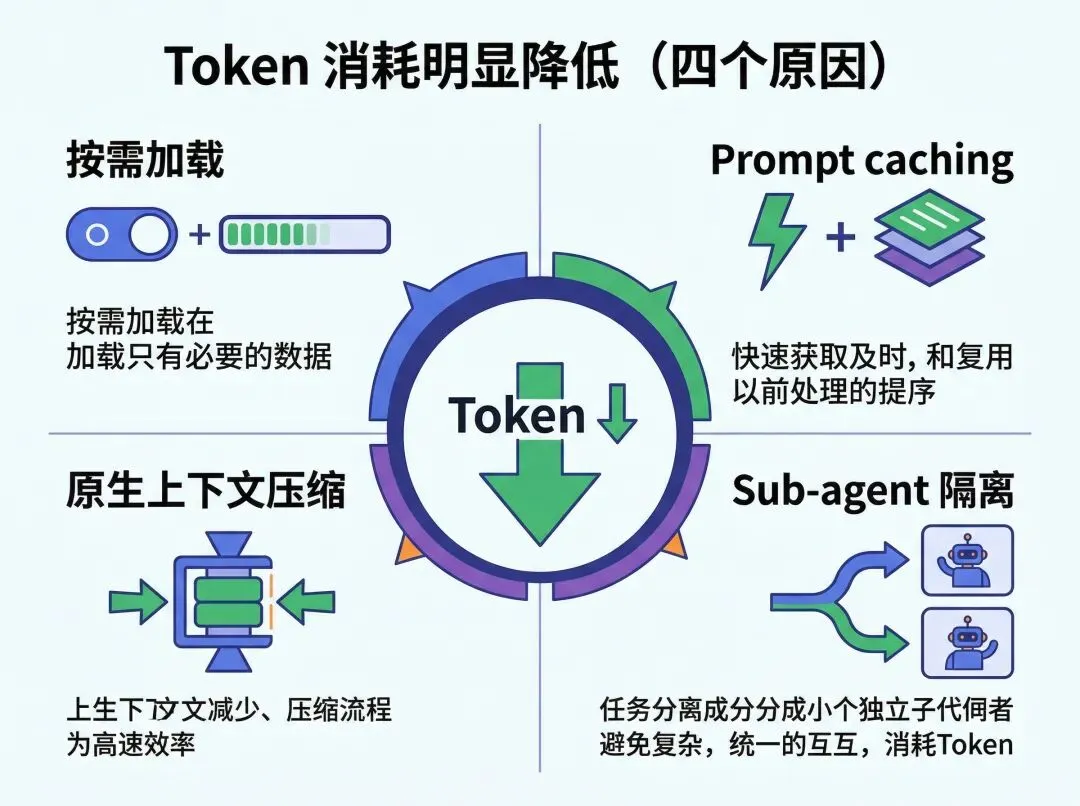
不是幻觉,是真的省了。原因有四:
按需加载 vs 全量加载。openclaw 每次启动把 SOUL.md + USER.md + TOOLS.md + MEMORY.md 全塞进 system prompt,不管用不用得到。Claude Code 只自动加载 CLAUDE.md,skills 和 memory 调用时才读。 Prompt caching。Claude API 原生支持——重复的前缀(每轮都一样的 CLAUDE.md)缓存后 token 费用降 90%。第三方 wrapper 很难用到这个优化。 原生上下文压缩。快到窗口上限时自动压缩早期消息,比自己管 conversation history 精细得多。 Sub-agent 隔离。子任务在独立上下文里执行,干完只返回结果,不污染主 session。
再补一个很现实的旁证:工具也会吃 token。很多人装 MCP server 时以为"工具越多越强",结果一个 server 的 tool description 就能吃掉几千 token(甚至 8000+),上下文还没开始用就先少一大截。所以"按需加载/按需启用工具"不是省钱技巧,是工程常识。
维护成本大幅降低
之前 openclaw 的文件加载逻辑、记忆索引、skill 发现机制都要自己写代码维护。Claude Code 原生支持这些,代码量直接归零。
能力上限更高
Claude Code 的 sub-agent 调度、worktree 隔离(在独立 git 分支里执行任务)、MCP 生态,比自建方案强得多。有些之前做不到的事(比如并行跑多个分析任务),现在可以了。
社区效应
CLAUDE.md、skills 这些概念有了社区统一规范。别人写的 skill 拿来能直接用,不需要适配私有格式。
心得体会
1. CLAUDE.md 是最重要的投资
花在 CLAUDE.md 上的每一分钟都值得。它不是说明文档,是系统的控制面。写得越精确,AI 的行为越可预测。
建议:先写 50 行能跑的版本,然后每次 AI 犯错就加一条规则。不要试图一次写完,让它在实战中长出来。
2. 铁律比原则有用 10 倍
"注意数据质量"是原则,没用。"GROUP BY 必须带 group_id,否则付费数据翻倍"是铁律,管用。
铁律的特征:具体、可验证、有因果关系。每条铁律背后都是一次真实的翻车。
3. 知识库要有回流机制
如果知识只写入不回流,它就是一个只增不减的垃圾堆。我的做法是:每次分析完一个课题,把结论性 insight 回写到对应主题文件。知识是复利的,不回写就浪费了。
4. 行为模式比记忆更值钱
日记型记忆(今天干了什么)保质期很短。但"某个 API 调用会导致不可逆副作用,连续失败 2 次就放弃该路径"这种行为模式,半年后还能救命。
格式很简单:Trigger(什么情况触发)- Behavior(应该怎么做)- Confidence(置信度)。同类错误出现 2 次就提炼成 pattern。
5. Skill 的颗粒度是门手艺
太粗("帮我做周报")AI 不知道具体步骤。太细("在 A1 单元格写入 xxx")失去灵活性。
最佳颗粒度是:每个步骤都有明确的输入/输出,但 AI 可以自主决定怎么执行。
6. 模型执行力 > 模型智力
同一套 skill,Claude 跑得通 GPT 跑不通,不是因为 GPT "不够聪明",而是它在长链路工具调用上倾向于偷懒。选模型不要只看 benchmark,要看它愿不愿意老老实实把 10 步任务跑完。
一个很快的自测方法:
给它一个 5-8 步、每步强依赖的任务 看它会不会从第 3 步开始"给方案不执行/让你手动" 看它能不能把上下文保持干净:子任务只回结果,不把过程垃圾倒回主线程
7. 被迫迁移是最好的重构机会
Anthropic 封掉第三方 wrapper 的订阅通道,短期看是个麻烦。但迁完之后我砍掉了冗余配置、发现了过时的规则、统一了文件格式。有时候"不得不重构"比"想重构"更有效率。
如果你也想搭一套
不需要一步到位:
先写 CLAUDE.md。50 行就够——你是谁、你的工作是什么、最重要的 3 条规则 第一个 skill 选你最频繁的重复任务。比如周报、日报、固定格式的数据查询 犯错就写铁律。不要等攒够 10 条再写,犯一条写一条 知识库从数据字典开始。写 SQL 的人,表结构是最高 ROI 的知识资产 装 cc-connect 连 IM。让 AI 能在手机上用,使用频率会翻倍 行为模式等它自然出现。同类错误出现 2 次,就值得提炼
核心思路只有一个:把你脑子里的隐性知识,变成 AI 能读的显性规则。 你教得越精确,它干得越靠谱。
回头看这次迁移,最大的感受是:你在 AI 上积累的资产(规则、skill、知识库)比你用的哪个模型、哪个平台更重要。
平台会改政策,模型会换代,但你写的 CLAUDE.md、你提炼的铁律、你沉淀的数据字典——这些跟着你走,换到哪里都能用。
与其焦虑"下次又断供怎么办",不如把精力花在积累可迁移的资产上。这才是真正的护城河。
往期精选:
让Openclaw节省20倍token,效率提升2倍(附我的开源skills)
