 夜雨聆风
夜雨聆风
2026年4月9日,深圳福田会展中心,第三届AI算力产业大会如期开幕。华为、百度、阿里、腾讯、浪潮等科技巨头悉数亮相,在众多厂商展示更强算力集群的同时,丰润达更关注另一个问题:如何让算力真正赋能千行百业,尤其是让企业用得起、用得好?

这一次,丰润达展台的主题是“算网融合,互联无界”。这背后是一套从服务器到网络、从硬件到平台的全链路理念——算力与网络不再割裂,而是作为一体化的基础设施,让企业像用水用电一样,按需取用、无缝连接。
算力新拐点:从“买得到”到“用出效果”
2026年,中国AI算力产业迎来关键分水岭。
国产AI芯片市场份额持续攀升,大模型从“训练驱动”转向“训练+推理”双轮驱动,日均Token调用量已突破140万亿。然而,各行各业对算力的需求变得更加务实——不仅要“买得到”,更要“用得好、用得起、用出效果”。
这不是算力过剩,而是算力错配。
大量企业采购算力后,面临利用率不透明、故障定位难、资源调度混乱的真实困境。硬件买回来了,算力却大量闲置——这才是成本居高不下的核心原因。更现实的问题是:很多成长型企业根本负担不起动辄千万级的算力投入。
“企业需要的是能真正支撑业务、快速产生价值的算力资源,而不是一笔高投入、低产出的‘沉默资产’。”

丰润达在本次大会上展示的全链路方案,正是围绕“实效”与“性价比”展开的系统布局。而其核心抓手,正是算网融合——让算力与网络协同调度,消除资源孤岛,从系统层面提升整体效率。
服务器:不做“大而全”,只做“精准适配”,价格更具竞争力
丰润达面向AI训练与推理的主力机型是一款6U机架式AI服务器,支持双路高性能英特尔至强可扩展处理器、32个DDR5内存插槽,以及8张双宽GPU。其最关键的差异化设计是“CPU-GPU直通”:跳过PCIe Switch芯片,每张GPU都走PCIe 5.0 x16直连。
这意味着更低的延迟、更高的数据传输效率,同时也意味着省去了昂贵的PCIe Switch和NVSwitch互联成本。配合12个3.5英寸大盘位,满足海量数据的低成本存储需求。

省下的每一分硬件成本,都直接转化为用户的价格优势。同等算力配置下,丰润达AI服务器的整体方案成本较行业主流水平显著降低——这让许多预算有限但希望拥抱AI的企业,第一次有了“够得着”的选择。
更重要的是,这些服务器从设计之初就与丰润达的网络产品线深度适配——CPU-GPU直通架构不仅降低了单机成本,更在网络侧减少了不必要的交换层级,为“算网融合”奠定了硬件基础。

高速网络:打通算力互联“高速公路”
算力孤岛是另一个被忽视的效率杀手。如果网络带宽成为瓶颈,再强的算力也无法发挥。
丰润达在此次大会上展出了覆盖全速率等级的网络产品矩阵:25G接入交换机填补中低速率场景的精准连接需求;100G核心交换机与400G数据中心核心交换机,面向超大规模集群的高带宽互联;同时配套1.6T ACC 、800G AEC/ACC、400G AEC、100G DAC/AOC等高速互联组件,覆盖从短距离机柜内互联到长距离集群互联的全场景。

这一组合意味着,无论是中小规模的企业算力节点,还是大型智算中心的超大规模集群,丰润达都能提供“按需定制”的网络带宽阶梯。更重要的是,丰润达的高速互联方案在同等带宽下价格更具优势——算力再强,如果“路”修得太贵,依然是门槛。丰润达选择先把路修好,而且修得经济。
在“算网融合”的框架下,网络不再是被动的传输管道,而是主动的算力调度参与者。丰润达的交换机全线支持智能流控、无损网络和遥测技术,能够实时感知算力节点的负载状态,动态调整数据路径,从而实现“算随网动、网随算调”——这正是“互联无界”的技术底气。
智算运维平台:被低估的效率杠杆,也是性价比的隐形功臣
硬件成本降下来了,但如果算力利用率上不去,单位算力的实际成本依然高昂。
丰润达在2025年底发布的智算运维平台,此次也同步亮相。该平台具备三大核心能力:全局可视化、智能预警与诊断、多厂商设备接入。已在多个示范智算中心部署,帮助客户将算力利用率大幅提升,全生命周期运维成本下降30%。

如果换算成单位算力的实际成本,性价比优势进一步拉大。算力利用率低,本质上不是硬件的问题,而是运维和管理的问题。丰润达的智算运维平台,正是要打破这个黑箱,让每一分投入都产出真实价值。
在算网融合的体系下,运维平台承担着“大脑”的角色。它不仅能监控服务器GPU的利用率,还能统一管理交换机端口流量、光模块健康度、电缆链路质量,实现从算力节点到网络链路的端到端可视化。
算网融合:从“单点产品”到“一体化交付”,总拥有成本更低
单点产品的优化终有限度,系统级的效率提升才是真正的护城河。
丰润达的策略是:硬件上做减法降低采购成本,运维上做加法提升利用效率,两端合力拉低算力的总拥有成本(TCO)。但将这一切串联起来的核心,是“算网融合”的一体化交付能力。
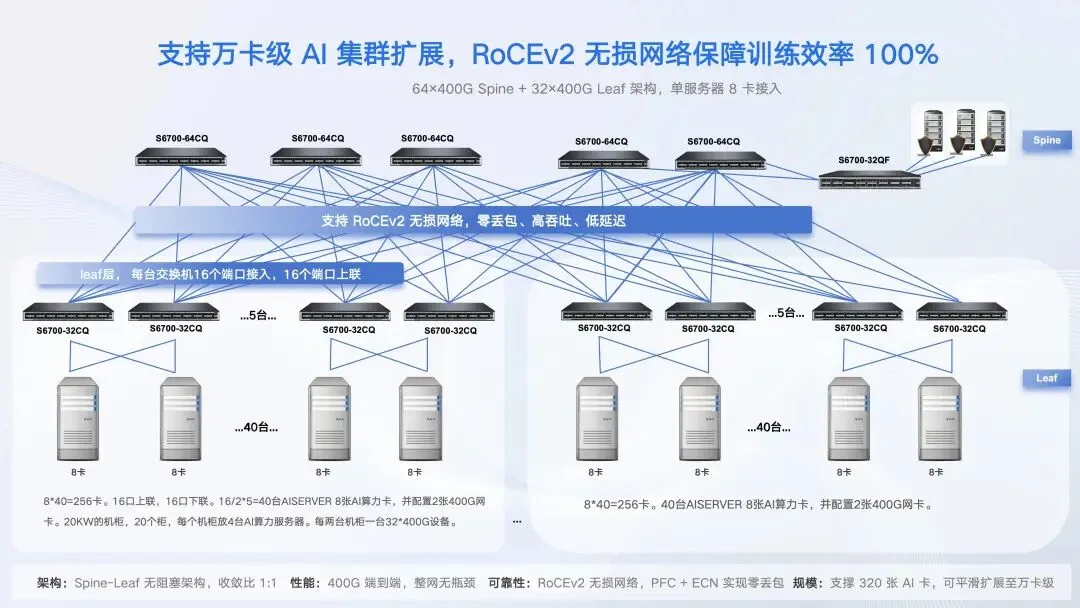
所谓“算网融合”,不是简单地把服务器和交换机打包销售,而是从底层架构开始重新设计算力与网络的协同关系。在本次大会上,丰润达展示了基于Spine-Leaf无阻塞架构的规模化算网融合方案,以实际案例诠释“互联无界”:
架构层面:采用64个400G端口Spine节点与32个400G端口Leaf节点两级组网,单服务器配置2张400G网卡,实现端到端400G无阻塞互联,收敛比达到1:1,整网零瓶颈。
规模与扩展性:单套方案可支撑320张AI卡高效协同训练,覆盖40台AI服务器的集群规模;通过增加Spine-Leaf层级和端口密度,可平滑扩展至万卡级集群,满足超大规模智算中心的需求。
网络可靠性:全链路部署RoCEv2无损网络,集成PFC(优先级流控)与ECN(显式拥塞通知)机制,在保证高吞吐、低延迟的同时实现零丢包,确保分布式训练效率逼近100%。
能效与部署:方案采用20KW高功率机柜,每柜部署4台AI服务器,每两台机柜共享一台400G Leaf交换机,在有限空间内实现超高密度算力堆叠,同时降低互联功耗与布线复杂度。
这一方案并非实验室概念,而是已经具备交付能力的成熟架构。它完整地体现了丰润达“算网融合”的核心思想:服务器提供高效算力,网络提供无损通道,运维平台提供全局调度,三者不再各自为战,而是作为一个整体为企业服务。
从网络交换机起步,丰润达逐步拓展至服务器、云端平台和智算运维平台,形成了“硬件+软件+平台”的全栈能力。正是这种全链路能力,让其能够从企业的实际业务场景出发,提供精准的算网融合解决方案——不做多余配置,不为冗余功能付费。
丰润达的产品与服务覆盖教育、医疗、机器人、智驾、生物医药、半导体、金融等多个领域。无论是需要高性能计算支持的重点行业客户,还是预算有限但希望拥抱AI的成长型企业,都能在其产品矩阵中找到高性价比、高实效、网算一体的路径。
算力普惠:从“奢侈品”到“基础设施”
算力采购回来,谁来帮他们真正跑通?更重要的是,谁能把算力成本降到他们负担得起的水平?
丰润达的展台,提供了一个务实的答案。
丰润达算网融合——让每一单位算力都能被顺畅调度到需要它的地方,不浪费、不等待、不堵车。
丰润达的“减法”逻辑,恰恰切中了这一时代命题:不炫技、不堆料,把每一分成本都花在能产出真实算力的地方。同等算力,价格更具竞争力——这不是营销话术,而是直通架构、精简设计、全链路自研以及算网深度融合带来的结构性成本优势。
国产算力的崛起,离不开每一个务实推进的参与者。在算力从“军备竞赛”回归“商业账本”的2026年,丰润达选择了一条更朴素、也更艰难的路——帮助企业用更低的成本、更高效的算网协同,跑通AI业务闭环。
正如一位现场参观的行业人士所言:“以前看算力展,大家都在比谁的风扇大、谁的卡多。今年在丰润达的展台,我第一次看到有人认真讲‘怎么让算力不浪费、怎么让算力不贵’,还讲清楚了‘算力和网络怎么配合’——这可能才是行业真正需要的。”
深圳的这场算力盛会传递了一个清晰的信号:算力竞赛的下半场,拼的不是谁堆得更高,而是谁能把每一瓦电都变成真实的生产力,同时让算力价格回归理性,让算与网真正融为一体、互联无界。
为什么选择丰润达
Why Choose HORED
国家级背书:国家专精特新“小巨人”企业,广东制造业单项冠军;
技术自主可控:国家知识产权优势单位,拥有400+专利;
自主研发创新:
算力网-- GPU/CPU服务器, 国产信创服务器,CPU信创服务器,100/400G/800G高速交换机、高速铜缆和光模块、智算运维平台;
企业网--商业交换机、工业交换机、无线WiFi-6/7AP ,4G/5G CPE ,AC MESH路由、MIFI等 ;
自主生产:10000平方智能制造工厂,交期可控;
免费云平台:智算运维平台终身0授权费,节省百万级运维成本。
全球布局:服务覆盖中国30+省会城市,业务遍及100+国家和地区,拥有600+国内及海外渠道合作伙伴,深度拓展国内外头部客户及品牌渠道。

END


立即开启升级
扫码获取专属方案
400-168-6065

 戳“阅读原文”,了解丰润达
戳“阅读原文”,了解丰润达
