 夜雨聆风
夜雨聆风狐狐/ AI使用 · 第2篇
人类大脑有一个叫前额叶的区域,负责注意力、专注和决策——决定你此刻该关注什么、忽略什么。它是人类认知控制的核心,但它的容量是有限的,这就是为什么我们很难将注意力同时集中在多个事物上。
2017年,Google发了一篇论文,Attention Is All You Need。直译过来就是《注意力就是一切》,它发明了Transformer架构,奠定了今天所有大语言模型的底层架构。[1]
Transformer的核心机制叫"自注意力"。某种意义上说,它就是AI的"前额叶"。它决定了AI此刻该关注输入的哪个部分、忽略哪个部分。
我们每天使用的AI,全部建立在这个东西上面。
对于人类,每天的注意力是有限的。AI也一样。它看起来什么都能处理,但它的也是有限的。你塞给它的每一条信息,都在消耗它的预算。
塞得越多,每一条分到的注意力就越少,这意味着AI所处理的任务的准确率会下降。
这篇讲的就是这件事:AI的注意力是怎么工作的,怎么被浪费的,以及如何最大化地利用AI的注意力。
为什么AI的注意力是有限的
你跟AI的每一轮对话,都在往一个叫上下文窗口(Context Window)的东西里塞内容。发的消息、上传的文件、AI自己的回答,全在里面。AI每次回复你,是看着这个窗口里的所有内容来思考的。
那窗口有多大?目前主流模型的上下文窗口已经达到百万token级别,大约能装下一整部《红楼梦》。听起来十分的多。
但问题是,装得下不等于处理得好。
Chroma Research在2025年测了18个前沿模型(包括GPT-4.1、Claude、Gemini),发现所有模型的表现都随输入长度增加而下降。有些模型能稳定在95%的准确率,一旦输入超过某个长度,直接暴跌到60%。并非缓慢下降,是断崖。[2]
这个现象有个名字:Context Rot(上下文腐化)。不是窗口装满了才出问题,研究发现窗口远未装满时性能就已开始崩塌,比如200万字的窗口,才塞了50万字,降级就已经出现了。换句话说,一部《红楼梦》的窗口,你才塞了半本,它就开始犯糊涂了。
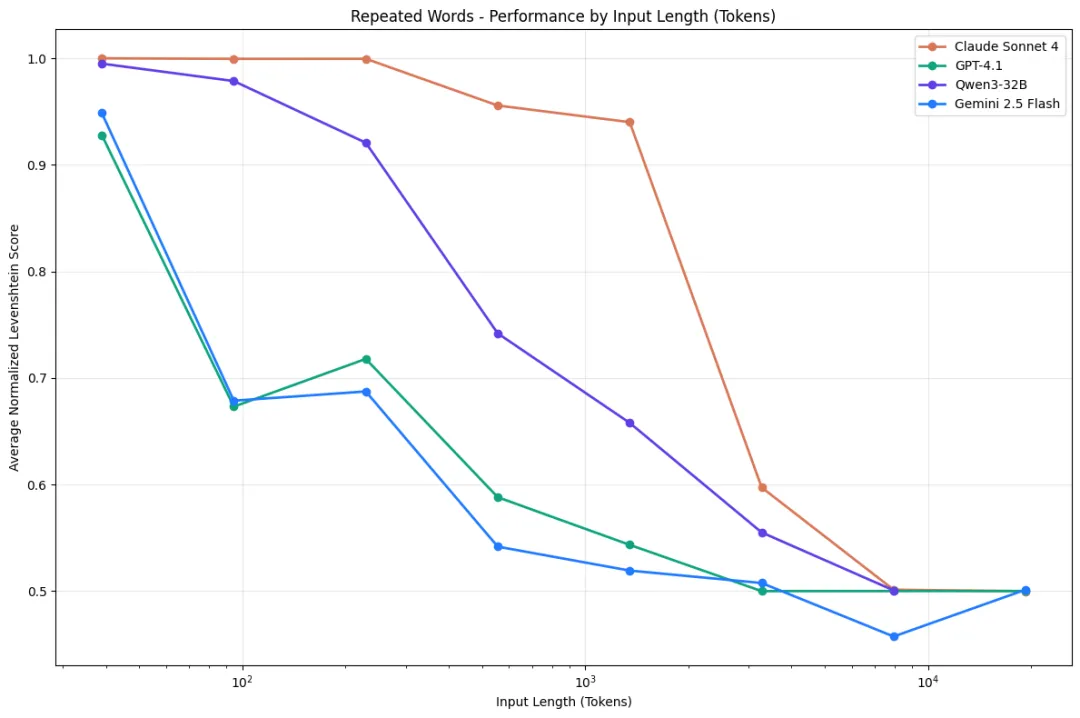
图1:模型随着上下文的长度而性能衰减
犯糊涂是什么意思?假设你真的把整部《红楼梦》喂给AI,然后问"第一回讲了什么",它可能会把前面和中间的情节混在一起说,或者干脆编一段根本不存在的剧情。它不是不知道答案就在里面,是注意力被七十多万字稀释了,找不准了。
关于上下文腐化的具体死法和应对方法,后续的推文会专门拆解。这篇先讲一件事:为什么会腐化?
注意力不是均匀分配的
原因出在所有大语言模型共用的底层架构:Transformer。
Transformer有一个叫"自注意力"的机制:每个token(可以粗略理解为一个词或半个词)需要和窗口里所有其他token计算关联。token数翻倍,计算量翻四倍。这意味着窗口越大,每个token分到的注意力就越薄。
更关键的是,这个注意力不是均匀撒在整个窗口上的。
斯坦福大学2024年发表的研究"Lost in the Middle"发现:AI对开头和结尾的内容注意力最强,对中间的内容注意力最弱,准确率呈一个U型曲线。当关键信息从开头移到中间位置时,准确率下降超过20个百分点。[3]
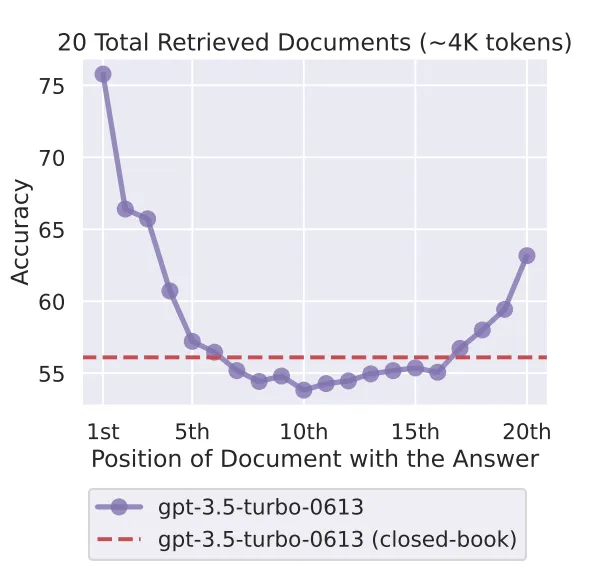
这不是某个模型没做好,是Transformer架构的数学性质。就像你读一封很长的邮件,最容易记住的是开头第一段和最后的结论,中间那些段落?大概率翻过去了。AI也一样。
所以回到开头那句话:Attention Is All You Need(注意力就是一切)。但注意力是有限的,而且分配不均。塞进去的每一条信息,都在稀释AI对其他信息的关注。信息越精准、越少、放的位置越靠前,AI的注意力越集中,答案越好。
所以我们该怎么管理AI的注意力?
2022年底ChatGPT刚出来的时候,大家发现"换个说法问AI,结果完全不一样",于是有了一个词叫提示词工程(Prompt Engineering),就是研究怎么把你发给AI的那句话写好。2023年这个词火到出现了专门的"提示词工程师"岗位。
但随着模型越来越大、上下文窗口越来越长,发现光把一句话写好不够了。那句话写得再漂亮,如果AI的注意力已经被一堆无关信息稀释了,照样白搭。
所以2025年开始,行业里冒出了另一个词:上下文工程(Context Engineering),不只是把一句话写好,而是管理你给AI的整个信息环境:给什么、不给什么、先给什么、后给什么。
简单说:
提示词工程 = 把你说的那句话写好 上下文工程 = 管理AI看到的所有东西
这两个概念到今天都已经是基础共识了。
而上下文工程最直接的一条推论:一次只让AI干一件事。
你让AI同时"改语法+改逻辑结构+调整语气",它会试图全部兼顾,每一项分到的注意力都不够,结果哪个都做得将就。换自己同时干这三件事,你也做不好。
一次一件事。这是性价比最高的使用习惯。
别急着让AI动手
AI有一个你可能没注意到的习惯:信息不足时,它不会来问你,而是用自己的默认假设悄悄填满空白,然后直接开始干。你看到那份不尽如人意的结果,很可能是AI在你没说清楚的地方自己做了五六个判断,只是你没看见。
例如,你正在写一封邮件,你想让AI帮你润色,你直接把邮件发给AI,然后说"帮我润色一下"。它不知道你要怎么润色——你是想要更简洁,还是更正式,还是更有说服力?
然后你说"我觉得你写的不好",那么什么定义了"好"?好在哪里?要好到什么程度?
其实就是,你与AI的“颗粒度”对不上。
解决这个问题有三条路,取决于你"不清楚"到什么程度。
第一种:你大概知道要什么,但说得不够精确。
在发给AI之前,先跟自己对齐一遍"我到底要什么":把模糊的词拆成2-3个具体方向,选一个。
不说"帮我优化这封邮件",改成:
"帮我优化这封邮件,目标是(a)更简洁(删掉废话),(b)更正式(升级措辞),还是(c)更有说服力(加强理由)?选(a)。"
多花10秒,但AI从第一句话开始就不需要猜。
你会发现,这个拆词的动作往往让你自己也更清楚"我到底想要什么"。模糊需求最容易被忽略的副作用,是你以为自己知道要什么,但说出来才发现其实还没想清楚。AI只是帮你提前照了面镜子。
第二种:你知道自己缺信息,但不知道缺在哪。
描述完需求后,加一句:
"在你开始之前,告诉我你还需要哪一个关键信息。"
AI会把它最大的信息缺口暴露出来,你来填。比你事后猜"是不是我说得不够清楚"效率高得多。这也是为什么好的AI使用者越用越顺,他们在用的过程中,一直在让AI主动暴露缺了什么信息。
第三种:你根本不知道该往哪个方向问。
有时候问题不是你说不清楚,是你压根不知道这件事有哪些方向。你想了解A,但不知道A其实有BCDEFG这么多分支,你连该问什么都不知道。这时候可以反过来,让AI先把地图摊开:
"关于A,有哪些常见的场景或方向?帮我列出来,我来选。"
AI的知识库里大概率知道这些分支的存在,它只是不知道你要哪个。让它全摆出来,你一眼就能定位,哪怕你之前根本不知道那个方向叫什么名字。
其实这三种情况,下两图对应了一个很经典的Rumsfeld矩阵认知框架:


大多数人跟AI沟通卡住的时候,不是AI太笨,是卡在了右边那两个格子里。先搞清楚你在哪个格子,再选对应的做法,这比闷头改prompt有用得多。
实战:四种"不清楚",四种解法
场景一:我知道我知道
"把这段中文翻译成英文。"
这种情况不需要任何技巧。输入明确,输出明确,没有歧义空间。
但问题是:真正在这个格子里的任务,少得可怜。
你觉得"帮我用学术论文的正式语气翻译这段话"也在这个格子?不在。"学术"是哪个学科的学术?社科和理工科的写法完全不同。"正式语气"是什么程度的正式?期刊论文和学位论文的措辞习惯也不一样。
只要你的需求里出现了一个形容词,比如"正式"、"简洁"、"专业"、"好看",你大概率已经滑到别的格子去了,只是你还以为自己在这里。
大多数人跟AI沟通不顺利,不是因为AI笨,是因为高估了自己需求的清晰度。你以为你说清楚了,但"清楚"这件事本身就比你想的难得多。
场景二:我知道我不知道
你知道自己缺信息,但不确定具体缺在哪。
❌ 错误版:
"帮我做一个日本7天旅行攻略,我预算1.5万,从上海出发,想去东京和大阪,不想吃生鱼片,同行朋友是素食主义者,我去年去过浅草寺不想重复,想体验当地文化,希望住有温泉的酒店但预算有限,另外想买些动漫周边……"
你知道自己没想全,所以拼命往里塞信息,但预算和温泉酒店冲突了,素食和日本料理推荐打架了,AI试图全部照顾,结果每个需求都蜻蜓点水,没有一个真正解决。
✅ 正确版:
"我从上海去日本玩7天,预算1.5万,去东京+大阪。在你开始规划前,先告诉我:你还需要哪一个关键信息?"
AI可能会问:这次旅行最想要的体验是什么,文化、美食、还是购物?选一个主线。
一个问题锁定了最大缺口。你回答完,AI给出精准的大框架,细节后面一轮一轮追问。区别不是AI变聪明了,是它的注意力终于集中了。
场景三:我不知道我不知道
你根本不知道这件事有哪些方向,你连该问什么都不知道。
❌ 错误版:
"我想学一门新技能提升自己的职场竞争力,有什么推荐?"
AI会给你一份泛泛的列表:学Python、学英语、考PMP、学数据分析……看起来什么都对,但什么都不是为你量身推荐的。因为它不知道你是什么行业、什么阶段、什么短板,你自己也没想过这些维度的存在。
✅ 正确版:
"我想提升职场竞争力,但不确定该往哪个方向。在推荐之前,先帮我列出:对于一个[你的行业/岗位]的人来说,常见的技能提升方向有哪些大类?列出来我来选。"
AI可能会列出:技术深耕、管理能力、跨领域复合、行业认证、软技能沟通……你一看就知道"哦,我现在最缺的是管理能力",哪怕你之前根本没想到"管理能力"是一个选项。
这是最危险的格子,因为你甚至不会意识到自己遗漏了什么。让AI先把地图摊开,你再选路线。
场景四:我不知道我知道
回到场景一的那个例子。你说"帮我用学术论文的正式语气翻译这段话",AI给了你一版。你看完觉得……不对。但说不上来哪不对。
看了两遍,你发现AI用了很多被动句,比如"该方法被广泛应用于……"。你隐隐觉得不舒服,但说不出为什么。又看一遍,反应过来了:你读的那些顶刊论文,其实很少用被动句,你导师也说过"能用主动就不用被动"。你一直知道这个偏好,但刚才发需求时完全没想到要说。
"重新翻译,少用被动句,尽量用主动语态。"
好一些了。但AI把所有术语都翻译成了中文,比如"卷积神经网络"、"长短期记忆"。你们课题组的习惯是术语保留英文缩写。你又一直知道这个规矩,只是这次没想起来。
"专业术语保留英文缩写,比如用CNN而不是'卷积神经网络'。"
接着你发现段落衔接太生硬,全是"此外"、"另外"、"同时"。你读过的好论文不是这样的,段落之间有逻辑递进,不是简单并列。
"段落之间不要用'此外/另外'这类并列连接词,用逻辑递进。"
你看到发生了什么吗?
"学术论文的正式语气" → "少用被动句" → "术语保留英文缩写" → "段落用逻辑递进而非并列"。
每一轮,你都在把一个模糊的大词拆成更小的、没有歧义的具体指令。每一步,都是把一个"你不知道你知道"的隐藏偏好,逼成了一个"你知道你知道"的明确要求。
"学术论文的正式语气"这八个字,看似是一个清晰的指令,其实它包含了近乎无穷的维度,包括语态偏好、术语处理、衔接方式、句子长度、引用格式、语气距离感……每一个维度都可以继续拆,每拆一层就更精确一分。
拆到最后,当每个词都精确到没有歧义时,你就从右下角(我不知道我不知道)收敛到了左上角(我知道我知道)。
所谓"我知道我知道",不是你的起点,是你的终点,是你经过一轮轮拆解之后才能抵达的状态。
而前面讲的三种做法(自己拆模糊词、让AI问关键问题、让AI列出所有方向),本质上都是在加速这个收敛过程。
跟AI沟通的本质,不是写出一个完美的prompt,是不断把"我不知道"收敛成"我知道"。
你跟导师讨论论文方向,跟同事对齐需求,跟朋友商量去哪吃饭,我们都在做同一件事:把模糊的东西收敛成精确的东西。
只是在现实生活中,我们是多模态,神态和动作也在传递信息,收敛过程是隐式的。而AI是单模态,只能通过文本,它不会帮你脑补,所以你的每一个模糊都会被照出来。
总结
AI的注意力是有限的,你的清晰度决定了它的上限。
上一篇我们讲了AI为什么不是在"知道答案",而是在"猜字"。
下一篇,我们聊上下文腐化的四种具体死法:中毒、分心、混淆、冲突。每一种你大概率都踩过,只是不知道它叫什么名字。
写在最后
想写的太多了,以至于实在是不知道该如何压缩。
在写的过程中,我尝试把认识论的框架和AI的实际使用结合在一起。
写这篇文章本身就是一次收敛:想给大家讲AI的上下文,但"上下文"这三个字能拆出来的东西太多了:它是什么、为什么有限、有限了怎么办、怎么办的背后又是什么认知问题……
一层一层拆,拆到最后发现,底层逻辑指向的是"你到底知不知道自己要什么"。
还是那句话:颗粒度对齐。我愈发觉得颗粒度这三个字简直是天才发明。
不管是跟AI对话,跟人沟通,还是跟自己想清楚一件事——本质上都是在做同一个动作:把模糊的东西,收敛成精确的东西。
最后,感谢你能耐着性子看到这里。若觉得写得有意思,不妨留言、点赞、转发。
你的支持就是我前进最大的动力。
本文是「AI使用」系列第2篇。本系列共9篇,教你从"能用AI"变成"会用AI"。
参考文献[1] Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need.NeurIPS, Vol. 30. https://arxiv.org/abs/1706.03762[2] Hong, K., Troynikov, A., & Huber, J. (2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance.Chroma Research. https://www.trychroma.com/research/context-rot[3] Liu, N. F., Lin, K., Hewitt, J., et al. (2024). Lost in the Middle: How Language Models Use Long Contexts.TACL, Vol. 12. https://arxiv.org/abs/2307.03172
