 夜雨聆风
夜雨聆风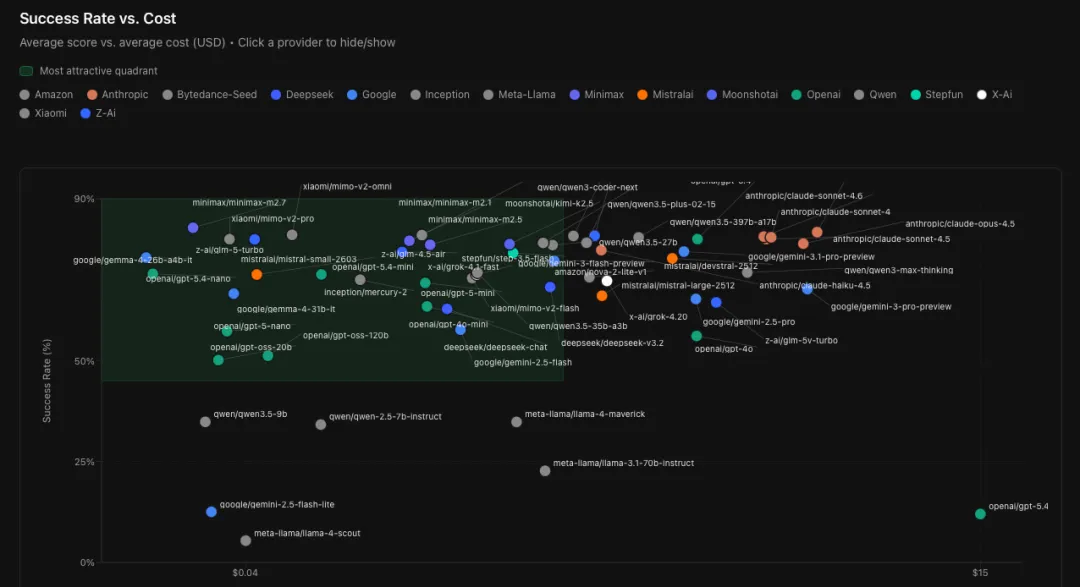
不同于传统基准测试,PinchBench 以 OpenClaw 的真实实操任务为核心开展评测,同厂商同系列的大小版本对比最具参考性:谷歌 Gemini 3 系列中,小参数量的 Flash 版本,任务成功率 95.1%,优于大版本 Pro的 91.7%;Claude 系列里,最大的旗舰 Opus,成功率 90.6%,甚至略低于自家最小的轻量 Haiku 版本的 90.8%。
成本端,旗舰大模型的测试成本是轻量模型的 40 倍,成功率却未实现反超。
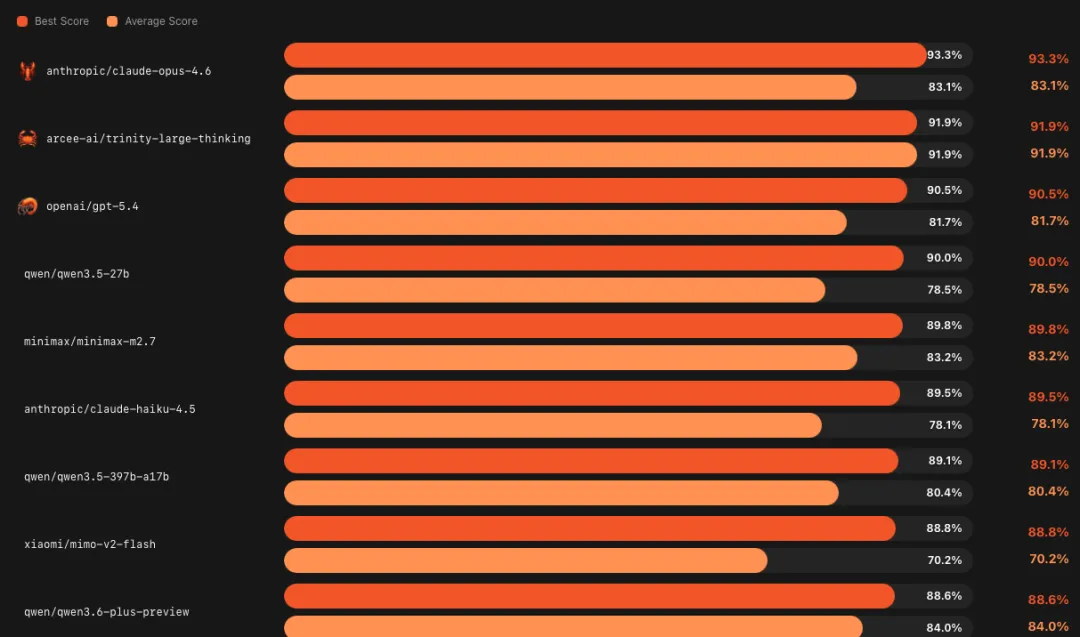
当然,大模型并非没有价值:在通用知识、跨领域复杂推理场景,其参数优势依然不可替代,只是在 OpenClaw 这类实操 Agent 任务中,小模型的适配性更突出 —— 大模型的冗余参数易产生冗余推理,提升出错概率,而轻量模型推理路径更短、执行更聚焦。
这正是数聚红芯的判断:AI 落地,适配才是核心。针对 OpenClaw 需求,我们的龙虾一体机,依托自研液冷技术,实现 AI Agent 本地化部署,告别云端成本顾虑,保障数据安全;同时我们会根据企业场景做模型适配调优,帮企业选对模型。

无论您需要轻量模型的高效落地,还是大模型的部署支撑,我们的多卡 AI 服务器、一体化方案,都能满足需求。
无需为冗余参数支付额外成本,无需为选型盲目试错。数聚红芯,助力企业将 AI Agent 的价值落到业务实处。如需了解更多,欢迎联系我们。
数据来源:pinchbench.com





