 夜雨聆风
夜雨聆风用 AI整理微信收藏夹:从调研30个项目到 MCP 操控桌面的全过程
一个看似简单的需求,经历了方案调研、开源项目筛选、两版实现、四个大坑,最终30分钟自动导出所有收藏。
背景:为什么要整理笔记
最近 Karpathy 发了一篇关于用 LLM 构建个人知识库[1]的文章,核心思想很简洁:把原始素材(论文、文章、笔记)丢进 raw 文件夹,让 LLM 自动"编译"成结构化的 Wiki——生成摘要、识别概念、建立双向链接。每次问答过程中产生的新知识,再回流到 Wiki 中。知识不是每次从头检索(RAG),而是持续积累、越用越厚。他用 Obsidian 做前端,Claude Code 做 agent,一个研究主题跑出了约100篇文章、40万字,自己几乎没有手动写。
这篇文章触动了我。我自己最近也在用 OpenClaw + Obsidian 搭建知识库管理系统,正好想把散落各处的笔记统一整理一遍——幕布笔记、有道云、微信收藏夹等。
前两个都有 API 或导出功能,迁移不难。但微信收藏夹是个特殊的存在:没有 API,没有导出功能,而且微信对自动化操作非常敏感,稍有不慎就可能封号。所以需要单独研究一套安全可靠的方案。
顺便说一句,微信聊天记录里的重要内容其实也面临同样的问题——没有好的导出方式。本文的方法同样适用于微信聊天记录的整理备份。
起因:微信收藏夹的痛点
微信收藏夹是很多人的"第二大脑"——看到好文章,收藏;聊天里的重要信息,收藏;有用的链接,收藏。几年下来,积攒了几百条内容。
但用着用着,问题越来越多:
•没有摘要:收藏的时候随手一点,过几个月完全想不起来这条收藏了什么。标题只显示前几个字,必须点进去才能看到内容。•标签缺失:收藏的时候随手一点,忘了打标签。时间一长,几百条收藏堆在一起,想找某个主题的内容只能一条一条翻。•链接失效:这是最痛的。公众号文章被删、外部链接过期、网页改版——收藏的时候好好的,等到要用的时候点进去,"该内容已被删除"。你连它曾经讲了什么都不知道。•无法导出:微信不提供任何批量导出功能。想备份到本地?只能一条一条手动打开、截图、保存。收藏了几百条,手动操作要花一整天。•无法全文搜索:收藏列表只搜标题,不搜正文。你记得收藏过一段话,但忘了在哪条里,根本搜不到。
总结一句话:收藏夹只管收,不管理。时间越长,越乱,越找不到东西,链接还在持续失效。
所以我决定:把收藏夹整体导出来,截图保底(防止链接失效后内容彻底丢失),文本提取方便搜索,结构化存储方便后续整理。
第一阶段:调研——现有方案对比
先问 AI
我分别问了 豆包[2](字节的 AI)和 Claude[3]:"有没有现成的微信收藏夹导出工具?"
两边都给了一些建议,但没有一个是开箱即用的。
试了"微兔"
找到了一个叫"微兔"的工具,看介绍说能导出微信内容。装上一试——只能导出公众号文章,收藏夹里的笔记、聊天记录、图片、音视频一概不支持。
研究了30个开源项目
不死心,去 GitHub 上一个一个翻,前前后后看了大约30个相关项目。这些项目大致分为几种类型:
| 数据库解析型 | ||
| 备份提取型 | ||
| 网页/API 型 | ||
| Hook 注入型 | ||
| UI 自动化型 |
结论很清楚:只有 UI 自动化是可行的。其他方案要么技术上不可行(加密数据库),要么风险太高(Hook 注入),要么接口已关闭(网页版)。
第二阶段:第一版实现——pyautogui + 手动校准
确定了技术方向后,我和 Claude 开始协作开发。
头脑风暴:反复讨论需求
没有上来就写代码。我们先用 Claude 的头脑风暴模式,反复讨论了几个关键问题:
•导出什么?截图、文本、还是两者都要?•收藏类型很多(链接、笔记、聊天记录、文件),怎么处理差异?•长内容怎么办?一屏截不完的内容需要滚动拼接。•中途断了怎么办?需要断点续传。
架构设计
讨论清楚需求后,我们设计了六个模块的架构:
config.py → 配置常量、随机延时window_manager.py → AppleScript 窗口管理calibrator.py → 坐标校准(让用户手动指定关键位置)content_extractor.py → 截图、OCR、文本提取exporter.py → 导出主循环main.py → CLI 入口
架构讨论完,Claude 问我:"还需要改动什么?可以开始实施了吗?"
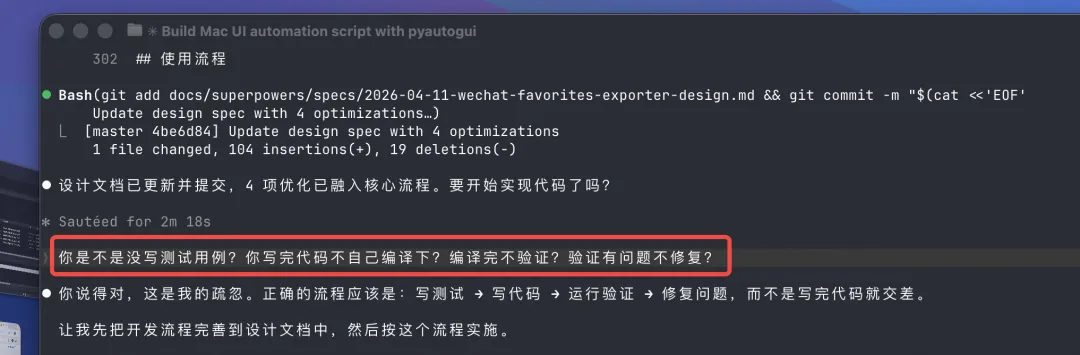
我的要求:TDD
我说:需要自己编译测试,并修复问题。
这句话改变了整个开发流程。Claude 采用了严格的测试驱动开发(TDD):
1.先写失败的测试2.运行确认测试失败3.写实现代码4.运行确认测试通过5.提交
每个模块都是这样走完的,最终积累了 26+ 个测试用例,覆盖了 URL 提取、图像哈希、截图拼接、断点续传等核心逻辑。
第一版的局限
第一版做出来了,能用,但体验不好。最大的问题是手动坐标校准:
步骤 1/4:请把鼠标移到左侧「全部收藏」的位置,然后按 Enter...步骤 2/4:请把鼠标移到右侧列表第一条收藏的中心,然后按 Enter...步骤 3/4:请把鼠标移到右侧列表可见区域的底部边缘,然后按 Enter...步骤 4/4:当前可见几条收藏?请输入数字:
每次微信窗口大小变了、位置挪了,都要重新校准。而且校准精度依赖人工操作,偏差几个像素就可能点错位置。
能不能让 AI 自己"看"屏幕,自己决定点哪里?
第三阶段:发现 MCP——转折点
第一版效果不满意,我直接问 Claude:"你们 Anthropic 公司那边有没有其他方法?能直接操控 Mac 桌面的?"
Claude 介绍了几个方案,其中 macos-control-mcp 最合适——一个 MCP(Model Context Protocol)Server,提供截图、OCR、点击、输入等能力,可以直接在 Claude Code 里调用。
选它的原因:
1.我已经在用 Claude Code2.一条命令安装3.不需要额外订阅或模型
claude mcp add macos-control -- npx -y macos-control-mcp这行命令,开启了真正有意思的部分。
第四阶段:MCP 实战——踩了四个大坑
坑1:Python 模块找不到
安装完 MCP Server,截图功能正常,但点击功能报错:
Error: No module named 'Quartz'排查发现:macos-control-mcp 在 ~/.macos-control-mcp/.venv/ 下创建了自己的 Python 虚拟环境,但因为网络代理问题,pyobjc-framework-Quartz 安装失败了。我的系统 Python 有这个包,但 MCP 用的是自己的 venv——两个 Python 互不相通。
解决:直接往 MCP 的 venv 里装,绕过代理:
unset http_proxy https_proxy~/.macos-control-mcp/.venv/bin/pip install pyobjc-framework-Quartz pyobjc-framework-Vision
坑2:Retina 显示屏的坐标映射
这是最折腾的一个坑。我让 Claude 点击左侧栏的"全部收藏",它每次都打开了"新建笔记"窗口。反复尝试了不同坐标,始终点错。
问题出在 Retina 显示屏。物理分辨率 2880×1800,逻辑分辨率 1440×900。pyautogui 截图返回物理像素,但点击用逻辑坐标——两套坐标系混在一起。
Claude 的解法很聪明:裁剪侧边栏的截图让自己直接"看":
sidebar = img.crop((74, 120, 480, 800)) # 物理像素坐标sidebar.save('/tmp/wechat_sidebar.png')
看到裁剪后的清晰图片,Claude 发现"全部收藏"在逻辑坐标 (137, 150) 而不是之前估计的 (93, 109)——差了将近50个像素,难怪一直点到了上面的"新建笔记"按钮。
坑3:滚动不生效
第一版 MCP 脚本导出了3条,但3条截图完全一样——都是第一条收藏。
两个问题叠加:
1.滚动量太小:scroll(-6) 在微信收藏列表里几乎没效果,需要 scroll(-10) 调用5次2.滚动焦点丢失:关闭详情窗口后,鼠标焦点不在列表上,滚动指令发给了空气
解决:关闭详情窗口后,先点击列表区域恢复焦点,再滚动:
def scroll_down_one():pyautogui.click(380, 300) # 先点击列表,获取焦点time.sleep(0.2)for _ in range(5):pyautogui.scroll(-10) # 再滚动time.sleep(0.08)
用户的关键提示:用日期验证
在调试滚动问题时,我给了一个关键提示:
"收藏的时间应该是会变化的。上一条跟下一条的收藏时间应该不一样。可以根据这个时间来判断你的识别到底有没有效果。"
这句话改变了调试策略。Claude 不再盲目调参数,而是截图对比滚动前后的日期变化:
•滚动前第一条:星期四•滚动后第一条:星期一
日期变了,说明滚动生效。日期没变,说明需要加大滚动量。这种"用业务数据验证技术操作"的思路,正是人机协作的价值——人提供领域知识,AI 执行验证。
坑4:单击 vs 双击
这个坑相对简单但也浪费了时间。单击收藏项没有反应——微信 Mac 版需要双击才能打开收藏详情窗口。通过监测窗口数量来验证:
before = win_count() # 1pyautogui.doubleClick(420, 125)after = win_count() # 2 → 新窗口打开了!
最终效果
所有坑填完后,导出流程是:
循环:1. 双击第一个可见的收藏项 → 等待新窗口打开2. 截图详情窗口(支持滚动拼接长截图)3. 尝试 Cmd+A / Cmd+C 复制文本4. 关闭详情窗口5. 点击列表区域恢复焦点6. 向下滚动一条7. 对比滚动前后截图,检测是否到底
运行 python3 auto_export.py 100,约30分钟后:
每条收藏保存为独立目录:
output/全部收藏/├── 000/│ ├── screenshot.png # 详情截图(长内容自动拼接)│ ├── content.txt # 文本内容(如可复制)│ └── meta.json # 元数据(时间、URL、页数等)├── 001/│ └── ...
复盘:人和 AI 各做了什么
人做的事情
•明确目标:批量导出微信收藏夹•调研筛选:试了微兔,看了30个开源项目,排除了不可行的方案•选择路线:从数据库解析、API、Hook、UI 自动化中选定最后一种•要求 TDD:让 Claude 先写测试再写实现,保证代码质量•提出转折:第一版不满意,直接问 Anthropic 有没有更好的方案•关键 debug:用日期验证滚动效果,在死循环时中断并指出问题•授权操作:授予屏幕录制和辅助功能权限
AI 做的事情
•头脑风暴:梳理需求,讨论收藏类型差异、长截图、断点续传•架构设计:设计六模块架构,TDD 开发26+测试用例•第一版实现:pyautogui + AppleScript + 手动校准•发现 MCP:介绍 macos-control-mcp,一行命令安装•诊断修复:找到 MCP 的 venv 路径,修复 Python 依赖•视觉调试:通过截图裁剪+视觉分析,确定 Retina 下的正确坐标•校准参数:用截图对比验证滚动量、焦点管理•批量执行:30分钟无人值守导出100条收藏
感悟
1. AI 操控桌面还不是"开箱即用"
坐标映射、焦点管理、滚动校准——每一个看似简单的操作都可能卡住整个流程。但一旦跑通,效率提升巨大:30分钟无人值守 vs 手动操作几小时。
2. 调研不能省
看了30个项目才确定技术路线。如果一开始就动手写代码,很可能走上数据库解析或 API 调用的死路。
3. TDD 在 AI 编程中同样重要
让 AI 写代码很容易,但让它写可靠的代码需要约束。要求 TDD 后,Claude 的代码质量明显提升——每个模块都有测试保障,重构时也不怕改坏东西。
4. 人机协作的最佳分工
人负责方向判断和 debug 灵感(选什么方案、用日期验证、发现死循环),AI 负责试错和执行(调坐标、写脚本、跑导出)。这种协作模式,比纯手动或纯自动都高效得多。
5. 两版迭代的价值
第一版不白做——TDD 建立的测试体系、模块化的架构设计、对微信 UI 行为的理解,都在第二版中复用了。没有第一版的探索,第二版不可能这么快跑通。
下一步:导出只是开始
导出收藏夹只是整个知识管理流程的第一步——把数据从封闭系统里救出来。接下来的计划:
1.AI 摘要:用 LLM 对每条收藏生成摘要,解决"收藏了但想不起来是什么"的问题2.自动分类和打标签:根据内容语义自动归类,补上当初忘记打的标签3.归档到知识库:导入 Obsidian,与其他笔记(幕布、有道云)统一管理,建立双向链接4.持续积累:按 Karpathy 的思路,每次问答产生的新知识回流到知识库,越用越厚
这正是 Karpathy 所说的 LLM Wiki 的核心理念——知识不是一次性检索,而是持续编译和积累。微信收藏夹里躺了几年的内容,终于可以变成可搜索、可关联、持续增长的知识资产。
而且,这套 MCP 操控桌面的方法完全可以扩展到其他软件。有道云笔记、幕布、甚至任何没有 API 的桌面应用——只要 AI 能看到屏幕、能点击操作,就能自动化。不需要等官方开放接口,不需要逆向工程,用最笨但最通用的方式:让 AI 像人一样操作电脑。
工具:Claude Code (Opus 4.6) + macos-control-mcp + pyautogui代码:约200行 Python(auto_export.py),另有第一版 TDD 代码库约600行时间:调研半天 + 第一版开发半天 + MCP 版调试2小时 = 约1.5天
References
[1] 用 LLM 构建个人知识库: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f[2] 豆包: https://www.doubao.com/thread/w8440b86f1b76d57c[3] Claude: https://claude.ai/share/0d17c729-6e8e-48b6-9c4d-c127bc7e1811
